整理的网上的MySQL优化文章总结
MySQL优化
Linux优化
IO优化
调整Linux默认的IO调度算法.
IO调度器的总体目标是希望让磁头能够总是往一个方向移动,移动到底了再往反方向走,这恰恰就是现实生活中的电梯模型,所以IO调度器也被叫做电梯 (elevator),而相应的算法也就被叫做电梯算法.而Linux中IO调度的电梯算法有好几种,一个叫做as(Anticipatory),一个叫做 cfq(Complete Fairness Queueing),一个叫做deadline,还有一个叫做noop(No Operation).
IO对数据库的影响较大,linux默认的IO调度算法为cfq,需要修改为deadline,如果是SSD或者PCIe-SSD设备,需要修改为noop,可以使用下面两种修改方式。
- 查看默认的IO算法
dmesg | grep -i scheduler
- 在线动态修改,重启失效。
echo "deadline" > /sys/block/vda/queue/scheduler
- 修改/etc/grub.conf,永久生效。
修改/etc/grub.conf配置文件,在kernel那行增加一个配置,例如:
elevator=deadline
IO调度算法详解
NOOP
NOOP算法的全写为No Operation。该算法实现了最最简单的FIFO队列,所有IO请求大致按照先来后到的顺序进行操作。之所以说“大致”,原因是NOOP在FIFO的基础上还做了相邻IO请求的合并,并不是完完全全按照先进先出的规则满足IO请求。
假设有如下的io请求序列:
100,500,101,10,56,1000
NOOP将会按照如下顺序满足:
100(101),500,10,56,1000
CFQ
CFQ算法的全写为Completely Fair Queuing。该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。
假设有如下的io请求序列:
100,500,101,10,56,1000
CFQ将会按照如下顺序满足:
100,101,500,1000,10,56
在传统的SAS盘上,磁盘寻道花去了绝大多数的IO响应时间。CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是,先来的IO请求并不一定能被满足,可能会出现饿死的情况。
DEADLINE
DEADLINE在CFQ的基础上,解决了IO请求饿死的极端情况。除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提供了FIFO队列。读FIFO队列的最大等待时间为500ms,写FIFO队列的最大等待时间为5s。FIFO队列内的IO请求优先级要比CFQ队列中的高,,而读FIFO队列的优先级又比写FIFO队列的优先级高。优先级可以表示如下:
FIFO(Read) > FIFO(Write) > CFQ
ANTICIPATORY
CFQ和DEADLINE考虑的焦点在于满足零散IO请求上。对于连续的IO请求,比如顺序读,并没有做优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。ANTICIPATORY的在DEADLINE的基础上,为每个读IO都设置了6ms的等待时间窗口。如果在这6ms内OS收到了相邻位置的读IO请求,就可以立即满足。
总结
noop:一般用于ssd,因为SSD速度本身已经够快不需要再进行调度。
deadline:一般用于数据库
cfq:为所有进程分配等量的带宽,适合于桌面多任务及多媒体应用,默认IO调度器
内存优化
numa
非一致存储访问结构 (NUMA : Non-Uniform Memory Access)它和对称多处理器结构 (SMP : Symmetric Multi-Processor) 是对应的。简单的队别如下:

SMP访问内存的都是代价都是一样的;但是在NUMA架构下,本地内存的访问和非本地内存的访问代价是不一样的。
你可以指定内存在本地分配,在某几个CPU节点分配或者轮询分配。除非是设置为--interleave=nodes轮询分配方式,即内存可以在任意NUMA节点上分配这种方式以外。其他的方式就算其他NUMA节点上还有内存剩余,Linux也不会把剩余的内存分配给这个进程,而是采用SWAP的方式来获得内存。有经验的系统管理员或者DBA都知道SWAP导致的数据库性能 下降有多么坑爹,所以最简单的方法,还是关闭掉这个特性。
关闭特性的方法,分别有:
- 可以从BIOS,操作系统,启动进程时临时关闭这个特性。由于各种BIOS类型的区别,如何关闭NUMA千差万别,我们这里就不具体展示怎么设置了。
- 在操作系统中关闭,可以直接在/etc/grub.conf的kernel行最后添加numa=off,如下所示:
kernel /vmlinuz-2.6.32-220.el6.x86_64 ... numa=off
- 启动MySQL的时候,关闭NUMA特性:
numactl --interleave=all mysqld 或者numactl –cpunodebind=node –localalloc mysqld
另外可以设置 vm.zone_reclaim_mode=0尽量回收内存。
MySQL5.7提供了MUMA的支持,--innodb-numa-interleave参数,如果没有该参数,则可以
swappiness
vm.swappiness是操作系统控制物理内存交换出去的策略。它允许的值是一个百分比的值,最小为0,最大运行100,该值默认为60。vm.swappiness设置为0表示尽量少swap,100表示尽量将inactive的内存页交换出去。
具体的说:当内存基本用满的时候,系统会根据这个参数来判断是把内存中很少用到的inactive内存交换出去,还是释放数据的cache。cache中缓存着从磁盘读出来的数据,根据程序的局部性原理,这些数据有可能在接下来又要被读 取;inactive内存顾名思义,就是那些被应用程序映射着,但是长时间不用的内存。
我们可以利用vmstat看到inactive的内存的数量:
vmstat -an 1
#通过/proc/meminfo 你可以看到更详细的信息:
cat /proc/meminfo | grep -i inact
Linux中,内存可能处于三种状态:free,active和inactive。Linux Kernel在内部维护了很多LRU列表用来管理内存,比如LRU_INACTIVE_ANON, LRU_ACTIVE_ANON, LRU_INACTIVE_FILE , LRU_ACTIVE_FILE, LRU_UNEVICTABLE。其中LRU_INACTIVE_ANON, LRU_ACTIVE_ANON用来管理匿名页,LRU_INACTIVE_FILE , LRU_ACTIVE_FILE用来管理page caches页缓存。系统内核会根据内存页的访问情况,不定时的将活跃active内存被移到inactive列表中,这些inactive的内存可以被交换到swap中去。
一般来说,MySQL,特别是InnoDB管理内存缓存,它占用的内存比较多,不经常访问的内存也会不少,这些内存如果被Linux错误的交换出去了,将浪费很多CPU和IO资源。 InnoDB自己管理缓存,cache的文件数据来说占用了内存,对InnoDB几乎没有任何好处。所以,我们在MySQL的服务器上最好设置vm.swappiness=0。
设置vm.swappiness:
echo vm.swappiness = 0 >> /etc/sysctl.conf
#使其保存生效
sysctl -p
文件系统优化
文件描述符
内核利用文件描述符来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件,高并发场景需要把文件描述符调大
临时调整:
ulimit -SHn 65536
永久调整
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
优化文件系统挂载参数
文件系统挂载参数是在/etc/fstab文件中修改,重启时候生效,noatime不记录访问时间,nodiratime不记录目录的访问时间。
对于ext3, ext4和 reiserfs文件系统可以在mount时指定barrier=0;对于xfs可以指定nobarrier选项。
很多文件系统会在数据提交时强制底层设备刷新cache,避免数据丢失,称之为write barriers。但是,其实我们数据库服务器底层存储设备要么采用RAID卡,RAID卡本身的电池可以掉电保护;要么采用Flash卡,它也有自我保 护机制,保证数据不会丢失。所以我们可以安全的使用nobarrier挂载文件系统。
如果业务量很大的话,使用xfs文件系统,在CentOS6.4之后的系统xfs性能比ext4好;
配置参数优化
query_cache_size
query cache是一个众所周知的瓶颈,甚至在并发并不多时也如此。 最好是一开始就停用,设置query_cache_size = 0,并利用其他方法加速查询:优化索引、增加拷贝分散负载或者启用额外的缓存(比如memcache或redis)。如果已经启用了query cache并且还没有发现任何问题,query cache可能有用。如果想停用它,那就得小心了。
innodb_buffer_pool_size
缓冲池是数据和索引缓存的地方:这个值越大越好,这能保证你在大多数的读取操作时使用的是内存而不是硬盘。典型的值是5-6GB(8GB内存),20-25GB(32GB内存),100-120GB(128GB内存)。
innodb_log_file_size
这是redo日志的大小。redo日志被用于确保写操作快速而可靠并且在崩溃时恢复。一直到MySQL 5.1,它都难于调整,因为一方面你想让它更大来提高性能,另一方面你想让它更小来使得崩溃后更快恢复。幸运的是从MySQL 5.5之后,崩溃恢复的性能的到了很大提升,这样你就可以同时拥有较高的写入性能和崩溃恢复性能了。一直到MySQL 5.5,redo日志的总尺寸被限定在4GB(默认可以有2个log文件)。这在MySQL 5.6里被提高。
max_connections
max_connection值被设高了(例如1000或更高)之后一个主要缺陷是当服务器运行1000个或更高的活动事务时会变的没有响应。在应用程序里使用连接池或者在MySQL里使用进程池有助于解决这一问题。
back_log
要求 mysql 能有的连接数量。当主要mysql线程在一个很短时间内得到非常多的连接请求,这就起作用,然后主线程花些时间检查连接并且启动一个新线程。back_log指明在mysql暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。只有如果期望在一个短时间内有很多连接,需要增加它,换句话说,该值对到来的tcp/ip连接的侦听队列的大小。
Innodb配置
innodb_file_per_table
这项设置告知InnoDB是否需要将所有表的数据和索引存放在共享表空间里(innodb_file_per_table = OFF)或者为每张表的数据单独放在一个.ibd文件(innodb_file_per_table = ON)。每张表一个文件允许你在drop、truncate或者rebuild表时回收磁盘空间。这对于一些高级特性也是有必要的,比如数据压缩。但是它不会带来任何性能收益。MySQL 5.6中,这个属性默认值是ON。
innodb_flush_log_at_trx_commit
默认值为1,表示InnoDB完全支持ACID特性。当关注点是数据安全的时候这个值是最合适的,比如在一个主节点上。但是对于磁盘(读写)速度较慢的系统,它会带来很巨大的开销,因为每次将改变flush到redo日志都需要额外的fsyncs。如果值为0速度就更快了,但在系统崩溃时可能丢失一些数据, 所以一遍只适用于备份节点。
innodb_flush_method
这项配置决定了数据和日志写入硬盘的方式。一般来说,如果你有硬件RAID控制器,并且其独立缓存采用write-back机制,并有着电池断电保护,那么应该设置配置为O_DIRECT;否则,大多数情况下应将其设为fdatasync(默认值)。sysbench是一个可以帮助你决定这个选项的好工具。
innodb_log_buffer_size
这项配置决定了为尚未执行的事务分配的缓存。但是如果事务中包含有二进制大对象或者大文本字段的话,看Innodb_log_waits状态变量,如果它不是0,增加innodb_log_buffer_size。
其他设置
log_bin
如果你想让数据库服务器充当主节点的备份节点,那么开启二进制日志是必须的。如果这么做了之后,还别忘了设置server_id为一个唯一的值。就算只有一个服务器,如果你想做基于时间点的数据恢复,这(开启二进制日志)也是很有用的:从你最近的备份中恢复(全量备份),并应用二进制日志中的修改(增量备份)。二进制日志一旦创建就将永久保存。所以如果你不想让磁盘空间耗尽,你可以用 PURGE BINARY LOGS 来清除旧文件,或者设置 expire_logs_days 来指定过多少天日志将被自动清除。
记录二进制日志不是没有开销的,所以如果你在一个非主节点的复制节点上不需要它的话,那么建议关闭这个选项。
skip_name_resolve
当客户端连接数据库服务器时,服务器会进行主机名解析,并且当DNS很慢时,建立连接也会很慢。因此建议在启动服务器时关闭skip_name_resolve选项而不进行DNS查找。唯一的局限是之后GRANT语句中只能使用IP地址了,因此在添加这项设置到一个已有系统中必须格外小心。
max_allowed_packet
接受的数据包大小;增加该变量的值十分安全,这是因为仅当需要时才会分配额外内存。例如,仅当你发出长查询或MySQLd必须返回大的结果行时MySQLd才会分配更多内存。该变量之所以取较小默认值是一种预防措施,以捕获客户端和服务器之间的错误信息包,并确保不会因偶然使用大的信息包而导致内存溢出
table_open_cache
MySQL每打开一个表,都会读入一些数据到table_open_cache缓存中,当MySQL在这个缓存中找不到相应信息时,才会去磁盘上读取。假定系统有200个并发连接,则需将此参数设置为200*N(N为每个连接所需的文件描述符数目);当把table_open_cache设置为很大时,如果系统处理不了那么多文件描述符,那么就会出现客户端失效,连接不上。
character-set
如果是单一语言使用简单的character set例如latin1。尽量少用Utf-8,utf-8占用空间较多
存储引擎优化
MyISAM
MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。
MyISAM特性:
- 不支持事务,宕机会破坏表
- 使用较小的内存和磁盘空间
- 基于表的锁,并发更新数据会出现严重性能问题
- MySQL只缓存Index,数据由OS缓存
使用场景:
- 日志系统
- 只读或者绝大部分是读操作的应用
- 全表扫描
- 批量导入数据
- 没有事务的低并发读/写
MyISAM优化要点:
- 声明列为
NOT NULL,可以减少磁盘存储。 - 使用
optimize table做碎片整理,回收空闲空间。注意仅仅在非常大的数据变化后运行。 - 删除/更新/插入大量数据的时候禁止使用index。使用ALTER TABLE t DISABLE KEYS。
- 设置
myisam_max_[extra]_sort_file_size足够大,可以显著提高repair table的速度。
InnoDB
InnoDB给MySQL提供了具有提交,回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎。InnoDB提供行级锁,并且也在SELECT语句提供一个Oracle风格一致的非锁定读。这些特色增加了多用户部署和性能。没有在InnoDB中扩大锁定的需要,因为在InnoDB中行锁,适合非常小的空间。InnoDB也支持FOREIGN KEY约束。在SQL查询中,你可以自由地将InnoDB类型的表与其它MySQL的表的类型混合起来,甚至在同一个查询中也可以混合。
InnoDB是为在处理巨大数据量时获得最大性能而设计的。它的CPU使用效率非常高。
InnoDB存储引擎已经完全与MySQL服务器整合,InnoDB存储引擎为在内存中缓存数据和索引而维持它自己的缓冲池。 InnoDB存储它的表&索引在一个表空间中,表空间可以包含数个文件(或原始磁盘分区)。这与MyISAM表不同,比如在MyISAM表中每个表被存在分离的文件中。InnoDB 表可以是任何大小,即使在文件尺寸被限制为2GB的操作系统上。
InnoDB特性:
- 支持事务,ACID,外键。
- Row level locks。
- 支持不同的隔离级别。
- 和MyISAM相比需要较多的内存和磁盘空间。
- 没有键压缩。
- 数据和索引都缓存在内存hash表中。
使用场景:
- 需要事务的应用。
- 高并发的应用。
- 自动恢复。
- 较快速的基于主键的操作。
InnoDB优化要点:
- 尽量使用short,integer的主键。
- Load/Insert数据时按主键顺序。如果数据没有按主键排序,先排序然后再进行数据库操作。
- 在Load数据是为设置SET UNIQUE_CHECKS=0,SET FOREIGN_KEY_CHECKS=0,可以避免外键和唯一性约束检查的开销。
- 使用prefix keys。因为InnoDB没有key压缩功能
MySQL性能优化的最佳实践
以下地址为原文:http://www.searchdatabase.com.cn/showcontent_38045.htm
1. 为查询缓存优化你的查询
大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的。因为,我们某些查询语句会让MySQL不使用缓存。请看下面的示例:
// 查询缓存不开启
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// 开启查询缓存
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
上面两条SQL语句的差别就是 CURDATE() ,MySQL的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而开启缓存。
2. EXPLAIN 你的 SELECT 查询
使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。
EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
挑一个你的SELECT语句(推荐挑选那个最复杂的,有多表联接的),把关键字EXPLAIN加到前面。你可以使用phpmyadmin来做这个事。然后,你会看到一张表格。下面的这个示例中,我们忘记加上了group_id索引,并且有表联接:

当我们为 group_id 字段加上索引后:

我们可以看到,前一个结果显示搜索了 7883 行,而后一个只是搜索了两个表的 9 和 16 行。查看rows列可以让我们找到潜在的性能问题。
3. 当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1)
// 没有效率的:
$r = mysql_query("SELECT * FROM user WHERE country = 'China'");
if (mysql_num_rows($r) > 0) {
// ...
}
// 有效率的:
$r = mysql_query("SELECT 1 FROM user WHERE country = 'China' LIMIT 1");
if (mysql_num_rows($r) > 0) {
// ...
}
4. 为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。
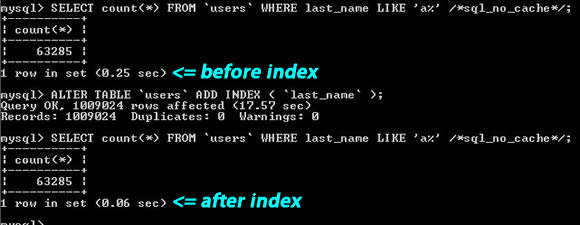
从上图你可以看到那个搜索字串 “last_name LIKE ‘a%’”,一个是建了索引,一个是没有索引,性能差了4倍左右。
另外,你应该也需要知道什么样的搜索是不能使用正常的索引的。例如,当你需要在一篇大的文章中搜索一个词时,如: “WHERE post_content LIKE ‘%apple%’”,索引可能是没有意义的。你可能需要使用MySQL全文索引 或是自己做一个索引(比如说:搜索关键词或是Tag什么的)
** 5. 在Join表的时候使用相当类型的例,并将其索引**
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)
// 在state中查找company
$r = mysql_query("SELECT company_name FROM users
LEFT JOIN companies ON (users.state = companies.state)
WHERE users.id = $user_id");
// 两个 state 字段应该是被建过索引的,而且应该是相当的类型,相同的字符集。
** 6. 千万不要 ORDER BY RAND()**
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你确不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
下面的示例是随机挑一条记录
// 千万不要这样做:
$r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1");
// 这要会更好:
$r = mysql_query("SELECT count(*) FROM user");
$d = mysql_fetch_row($r);
$rand = mt_rand(0,$d[0] - 1);
$r = mysql_query("SELECT username FROM user LIMIT $rand, 1");
**7. 避免 SELECT ***
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。所以,你应该养成一个需要什么就取什么的好的习惯。
// 不推荐
$r = mysql_query("SELECT * FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
// 推荐
$r = mysql_query("SELECT username FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
8. 永远为每张表设置一个ID
我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的ID来构造你的数据结构。
而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区……
在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比如:有一个“学生表”有学生的ID,有一个“课程表”有课程ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生ID和课程ID叫“外键”其共同组成主键。
9. 使用 ENUM 而不是 VARCHAR
ENUM类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
MySQL也有一个“建议”(见第十条)告诉你怎么去重新组织你的表结构。当你有一个 VARCHAR 字段时,这个建议会告诉你把其改成 ENUM 类型。使用 PROCEDURE ANALYSE() 你可以得到相关的建议。
10. 从 PROCEDURE ANALYSE() 取得建议
PROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。
例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成 MEDIUMINT 。或是你使用了一个 VARCHAR 字段,因为数据不多,你可能会得到一个让你把它改成 ENUM 的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。
一定要注意,这些只是建议,只有当你的表里的数据越来越多时,这些建议才会变得准确。一定要记住,你才是最终做决定的人。
11. 尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!)
不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
12. 无缓冲的查询
正常的情况下,当你在当你在你的脚本中执行一个SQL语句的时候,你的程序会停在那里直到没这个SQL语句返回,然后你的程序再往下继续执行。你可以使用无缓冲查询来改变这个行为。
mysql_unbuffered_query() 发送一个SQL语句到MySQL而并不像mysql_query()一样去自动fethch和缓存结果。这会相当节约很多可观的内存,尤其是那些会产生大量结果的查询语句,并且,你不需要等到所有的结果都返回,只需要第一行数据返回的时候,你就可以开始马上开始工作于查询结果了。
然而,这会有一些限制。因为你要么把所有行都读走,或是你要在进行下一次的查询前调用 mysql_free_result() 清除结果。而且, mysql_num_rows() 或 mysql_data_seek() 将无法使用。所以,是否使用无缓冲的查询你需要仔细考虑。
13. 把IP地址存成 UNSIGNED INT
很多程序员都会创建一个 VARCHAR(15) 字段来存放字符串形式的IP而不是整形的IP。如果你用整形来存放,只需要4个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当你需要使用这样的WHERE条件:IP between ip1 and ip2。
我们必需要使用UNSIGNED INT,因为 IP地址会使用整个32位的无符号整形。
而你的查询,你可以使用 INET_ATON() 来把一个字符串IP转成一个整形,并使用 INET_NTOA() 把一个整形转成一个字符串IP。在PHP中,也有这样的函数 ip2long() 和 long2ip()。
$r = "UPDATE users SET ip = INET_ATON('{$_SERVER['REMOTE_ADDR']}') WHERE user_id = $user_id";
14. 固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
使用“垂直分割”技术(见下一条),你可以分割你的表成为两个一个是定长的,一个则是不定长的。
15. 垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。(以前,在银行做过项目,见过一张表有100多个字段,很恐怖)
示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改写这个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有好的性能。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。
16. 拆分大的 DELETE 或 INSERT 语句
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊WEB服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。下面是一个示例:
while (1) {
//每次只做1000条
mysql_query("DELETE FROM logs WHERE log_date <= '2009-11-01' LIMIT 1000");
if (mysql_affected_rows() == 0) {
// 没得可删了,退出!
break;
}
// 每次都要休息一会儿
usleep(50000);
}
17. 越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009年11月06日),一个简单的ALTER TABLE语句花了3个多小时,因为里面有一千六百万条数据。
整理的网上的MySQL优化文章总结的更多相关文章
- MySQL优化篇系列文章(二)——MyISAM表锁与InnoDB锁问题
我可以和面试官多聊几句吗?只是想... MySQL优化篇系列文章(基于MySQL8.0测试验证),上部分:优化SQL语句.数据库对象,MyISAM表锁和InnoDB锁问题. 面试官:咦,小伙子,又来啦 ...
- MYSQL优化之碎片整理
MYSQL优化之碎片整理 在MySQL中,我们经常会使用VARCHAR.TEXT.BLOB等可变长度的文本数据类型.不过,当我们使用这些数据类型之后,我们就不得不做一些额外的工作--MySQL数据 ...
- MySQL优化整理
一.SQL优化 1.show status查看各种sql的执行频率 SHOW STATUS 可以根据需要显示 session 级别的统计结果和 global级别的统计结果. 显示当前sessi ...
- 「mysql优化专题」这大概是一篇最好的mysql优化入门文章(1)
优化,一直是面试最常问的一个问题.因为从优化的角度,优化的思路,完全可以看出一个人的技术积累.那么,关于系统优化,假设这么个场景,用户反映系统太卡(其实就是高并发),那么我们怎么优化? 如果请求过多, ...
- 单表60亿记录等大数据场景的MySQL优化和运维之道
此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美图公司数据库高级DBA,负责美图后端数据 ...
- 【转】单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美图公司数据库高级DBA,负责美图后端数据 ...
- [转载] 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
原文: http://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=209406532&idx=1&sn=2e9b0cc02bdd ...
- MySQL优化技巧总结
MySQL优化的几个大方向 ① 硬件优化 ② 对MySQL配置参数进行优化(my.cnf)此优化需要进行压力测试来进行参数调整 ③ SQL语句方面的优化 ④ 表方面的优化 硬件优化 cpu,内存, ...
- 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
015-08-09 杨尚刚 高可用架构 此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美 ...
随机推荐
- 阿里云体验实验室 教你如何《快速搭建LNMP环境》
## 体验平台简介 面向开发者和中小企业打造的一站式.全云端的开发平台,打开浏览器就可以开发.调试.上线,所测即所得,并结合无服务器的模式,重新定义云原生时代的研发工作方法论.旨在降低开发者上手成本和 ...
- hdfs学习(三)
HDFS 的 API 操作 使用url方式访问数据(了解) @Test public void urlHdfs() throws IOException { //1.注册url URL.setURLS ...
- Java中同步的基本概念监视器–最简单粗暴的理解方法
大学有一门课程叫操作系统,学习过的同学应该都记得,监视器是操作系统实现同步的重要基础概念,同样它也用在JAVA的线程同步中,这篇文章用一种类推的思想解释监视器"monitor". ...
- 初识ABP vNext(3):vue对接ABP基本思路
目录 前言 开始 登录 权限 本地化 创建项目 ABP vue-element-admin 最后 前言 上一篇介绍了ABP的启动模板以及AbpHelper工具的基本使用,这一篇将进入项目实战部分.因为 ...
- Linked server的一个问题
好久没有写新的博客,主要是很久没有什么动力和需求来写程序.虽然也不是一点没写,但都缺乏技术含量,没什么可说的. 前两天碰到一个关于linked server的问题.本地的sql server里,通过l ...
- node.js 模拟自动发送邮件验证码
node.js 模拟自动发送邮件验证码 引言 正文 1. QQ邮箱设置 2. 安装nodemailer 3.配置信息 4.综合 5.讲解 结束语 引言 先点赞,再看博客,顺手可以点个关注. 微信公众号 ...
- ethtool 设置网卡接收哈希
检查 [root@localhost]# ethtool -n eth1 rx-flow-hash tcp4 TCP over IPV4 flows use these fields for comp ...
- git提交限制后提交出错的暴力解决 (使用小乌龟)
1.右键-> TortoiseGit-> 显示日志 2.右键->重置到哪个版本 3. 重新修改提交信息提交
- 创建VUE+Element-UI项目
创建项目步骤 安装node.js后,使用管理员角色在cmd中依次运行下列步骤 vue init webpack hello-vue 创建项目文件 cd hello-vue 进入项目 npm insta ...
- py_二分查找
''' 查找:在一些数据元素中,通过一定的方法找出与关键字相同元素的过程, 列表查找:从列表中查找指定元素 输入:列表.待查找元素 输出:元素下标(未找到元素时一般返回None或-1) 内置列表查找函 ...