Reinforcement learning in artificial and biological systems
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
在生物和人工系统的学习研究之间,已经有富有成果的概念和想法流。Bush and Mosteller,Rescorla and Wagner首先在生物中开发的学习规则启发了许多早期的工作,从而导致了针对人工系统的强化学习(RL)算法的开发。最近,为在人工智能体中学习而开发的时序差分RL为解释多巴胺神经元的活动提供了基础框架。
在本综述中,我们描述了有关生物和人工智能体中RL的最新技术。我们专注于这些学科之间的联系点,并确定可以从这些领域之间的信息流中受益的未来研究领域。生物系统中的大多数工作都集中在简单的学习问题上,这些问题通常嵌入在动态环境中,在这种环境中灵活性和持续学习非常重要,类似于生物系统面临的现实世界学习问题。相反,大多数人工智能体的工作都集中在学习静态环境中的单个复杂问题。展望未来,各个领域的工作将受益于代表各学科优势的一系列想法。
生物和人工智能体必须达到生存和有用的目标。这种以目标为导向或享乐主义的行为是强化学习(RL)的基础1,强化学习是学习选择使奖励最大化,惩罚或损失最小的动作。强化学习基于智能体与其环境之间的相互作用(图1a,b)。智能体必须基于感官输入选择动作,其中感官输入定义环境状态。智能体试图优化的是这些行为随着时间的推移所产生的结果,无论是奖励还是惩罚。该公式对于生物系统中的行为而言是自然的,但也已证明对人工智能体非常有用。
生物系统必须寻找食物,避免伤害和繁殖2。它们所处的环境是动态的,关键过程在多个时间尺度上展开(图1c)。尽管其中一些变化可能是缓慢而持久的(例如,季节性),但其他变化却可能是突然而短暂的(例如,掠食者的出现),甚至是快速而持久的(例如,栖息地的破坏)。为了应对这些变化,生物系统必须在多个时间尺度上不断适应和学习。对生物系统的研究通常侧重于理解生物如何处理学习问题,其中选择和奖励之间的联系是直接的,但是是动态的3-5。这些类似于生态问题,例如学习吃哪种食物以及特定品种是否友好。在这些情况下,可以通过经验快速更新分配给选择的价值,因为责任分配问题(选择和结果之间的联系)很简单。更具体地讲,在通常用于研究动物学习的两臂赌博机范式中,与选择选项相关的奖励可以快速学习,并在改变时得到更新6,7。
另一方面,人工智能体是通过数学模型构建的,通常经过训练以解决静态环境中的单个问题8,9,这意味着奖励突发事件和环境响应在统计上是固定的。近年来,最成功的人工系统(包括神经网络)通常通过统计优化以数据驱动的方式进行训练10。对这些问题的训练需要大量的试验(图1d)。由于对优化的特定要求,训练阶段通常与执行阶段分开(图1f)。训练和执行的分离阻止了人工智能体从不断的经验中受益或适应环境的变化。正如我们稍后讨论的那样,将这两个阶段合并为一个“终身学习者”可能会导致不稳定,从而挑战统计学习中的假设。研究人员现在正在尝试使用多任务强化学习11,12之类的方法来解决这些问题(例如DARPA的生命学习机(L2M)程序和DeepMind)。但是,如何在动态环境中实现生物智能体的数据效率和适应性仍然是一项重大挑战。
尽管在生物智能体与人工智能体上的学习工作之间存在差异,或者可能是由于这些差异,但这些领域之间的想法交流空间很大。系统神经科学已使用人工智能体中RL的研究中使用的许多理论概念来提出有关生物系统的问题。无模型和有模型的理论RL算法正在为生物中基于奖励的学习过程提供新颖的见解13,14。从生物转向理论,ANN学习的许多工作都是由生物学习的想法驱动的,包括perceptron15和wake-sleep算法16,这些想法为当今深度网络的有效训练奠定了基础。
越来越多的工作探索了人工和生物系统中学习的交集。这项工作一方面试图建立一个人工大脑,另一方面试图了解生物大脑。在本综述中,我们重点描述了人工系统学习研究的想法流导致人们对生物系统学习增进了解的领域,反之亦然。我们还指出了将来可能会利用这种想法流的领域,以便更好地了解生物学习系统并建立能够解决日益复杂的现实问题的人工智能体。最后,我们考虑这些桥梁如何构成脑启发的神经形态技术工程的最新进展。
本文是通过首先考虑生物系统中的RL来组织的。我们首先讨论计算简单的无模型学习问题,其中关于神经回路和行为的知识很多,而在人工智能体中学习的想法产生了深远的影响。然后,我们转向更复杂的有模型RL,其中在人工智能体中学习的想法为理解行为提供了工具,而神经系统的研究才刚刚开始。本文的后半部分重点介绍人工系统中的学习。我们首先概述了最近在训练人工RL系统以解决复杂问题方面取得的成功,这些复杂问题依赖于深度神经网络的发展,而深度神经网络是受生物系统网络启发的。然后,我们讨论分层RL,这是为在人工智能体中学习而开发的框架。将来可能会被证明对理解生物系统很有用,因为对于构成生物智能体分层学习基础的神经回路知之甚少。最后,我们考虑神经形态工程,这是一个研究领域,明确地从生物中吸取了解决现实世界中的工程问题的机会。
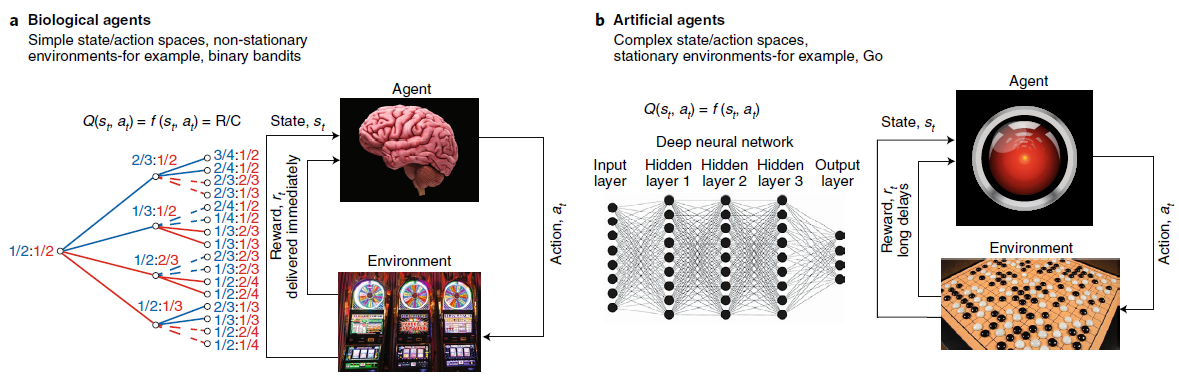
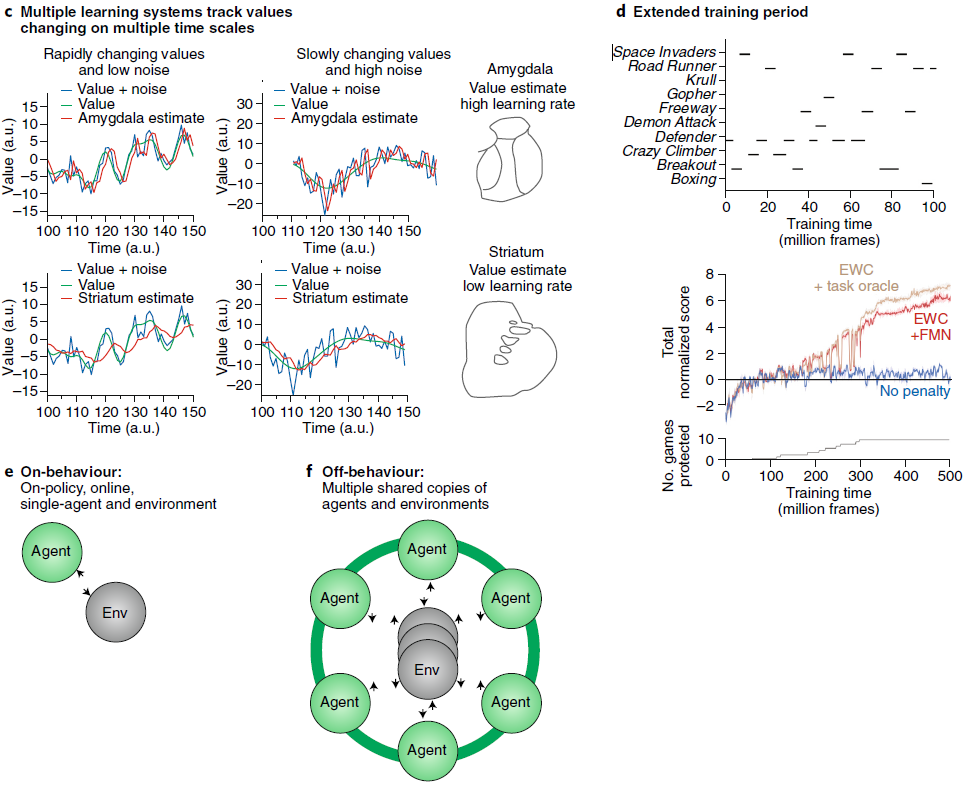
图1 | 生物和人工智能体学习方法概述。a,RL基于智能体与其环境之间的交互。智能体选择动作at,这导致状态st和奖励rt的变化,这些变化由环境返回。智能体的目标是在定义的时间范围内最大化回报。在生物中用于研究RL的实验中的动作价值Q(st, at)通常是选择与奖励的频率的简单函数(对于赌博机任务的一个小数量的选择,即奖励数量R除以选择数量C)。b,在人工系统中,相同的智能体与环境之间的区别很重要。在最先进的人工RL系统中,通过训练深度网络来估算动作价值。它们通常是感觉输入的复杂函数。c,生物智能体(例如大脑)采用多种学习系统,它们以不同的速率学习。杏仁核和纹状体是大脑中两个可以支持RL学习的核。杏仁核(也参见图3)学习速度很快,因此可以跟踪环境的快速变化,但要以对噪声的敏感性为代价。另一方面,纹状体学习较慢。虽然它无法跟踪环境价值的快速变化,但对噪声更鲁棒。d,通常对人工智能体进行复杂的,统计上稳定的问题的训练。训练试验的数量巨大,因此这些系统无法快速适应环境变化。人工智能体通常只接受一项任务训练,而无法在顺序的多任务设置中学习。分层RL,结构可塑性和加强可以使人工智能体在多个时间尺度上学习。e,生物智能体以“on-behaviour”的方式与环境互动,也就是说,学习是在线的,并且环境只有一个副本。f,尽管许多针对人工智能体的RL方法都遵循这些原则,但最新的成功策略包括一种智能体并行,其中智能体在环境副本上学习以稳定学习(例如,参见A3C和IMPALA)。受海马体或更多辅助学习系统启发的经验回放可以为on-behaviour智能体提供必要的属性,从而在人工和生物RL之间形成接触点。图片来源:Sebastian Kaulitzki / Alamy Stock Photo(大脑图像);Moritz Wolf / imageBROKER / Alamy Stock Photo(赌博机图像)。
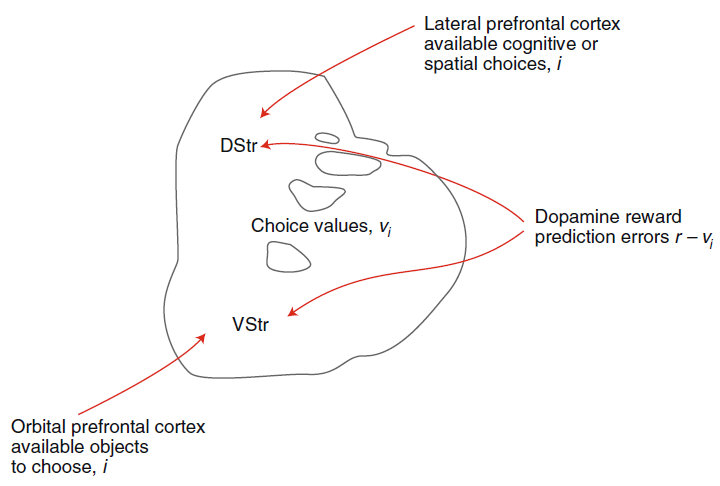
图2 | 恒河猴纹状体示意图上显示的强化学习模型的解剖结构。该模型集中于多巴胺及其在纹状体中的作用。DStr:背侧纹状体。VStr:腹侧纹状体。红线表示从指示的神经群体到纹状体的解剖输入。皮质输入是兴奋性的。多巴胺输入出现在中脑多巴胺神经元中。
Biological systems underlying RL
无模型和有模型强化学习的理论构造被开发,以解决人工系统中的学习问题。但是,它们已被用来从行为和神经两个层面理解生物系统中的学习问题。哺乳动物系统中RL的神经基础,尤其是无模型RL,可以说是系统神经科学领域中最能被理解的方法之一17-21。这是由于时序差分RL18和Rescorla-Wagner理论成功地预测了多巴胺神经元的活动,以及在行为上激活多巴胺神经元的影响。无模型RL的理论强调了额叶纹状体系统的作用20,21,这是将额叶前额叶皮层与纹状体连接起来的解剖学定义的网络,以及这些回路中多巴胺驱动的可塑性(图2)。根据一个模型,皮质代表了可用选择的集合23。纹状体细胞上皮质突触的强度编码有关每个选择的价值信息。较强的突触驱动纹状细胞中活动的增加。因此,纹状体细胞的活动代表由皮层表示的选项的价值24,25。纹状体活动驱动选择活动,既可以通过基底节的下游电路,也可以通过丘脑到皮层返回回路,也可以通过向下投影到脑干运动输出区域。在做出选择并经历结果之后,多巴胺会编码奖励预测误差RPE = r – vi。RPE是纹状体编码的选定选项的期望价值vi与实际结果r之差。如果RPE为正,则结果要好于预期,并且多巴胺会逐渐增加。如果RPE为负,则结果比预期要差,并且多巴胺会逐渐减少。多巴胺浓度的这种变化驱动了代表所选选项的额叶纹状体的突触可塑性。多巴胺驱动的增加使突触强度增加,而多巴胺驱动的减少使突触强度降低(忽略简化的直接和间接途径)。下次遇到这些选择选项时,纹状体神经元的活动将反映这种更新的突触功效,在先前的试验中,RPE为正的选项发放更多,RPE为负的选项发放更少。最简单形式的此过程由Rescorla-Wagner方程捕获,该方程是无状态RL更新模型17,26:
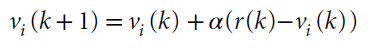
该方程总结了三个大脑区域中神经活动的相互作用——大脑皮层,代表它们的选项(i);纹状体,代表它们的价值(vi);以及中脑多巴胺神经元,它们编码RPE。该方程在形式上进一步描述了在学习过程中改变作为行为基础的价值表示的过程,其中更新的大小由学习率参数α控制。(请注意,最初的Rescorla-Wagner方程是在Pavlovian信号条件而不是选择的情况下开发的。)
时序差分(TD)学习,首先是为人工系统开发的27,将Rescorla-Wagner模型扩展到以下情况:动作价值取决于状态。状态由与选择选项有关的信息定义,例如,可以是时间。动作 i 的TD更新规则由下式定义:
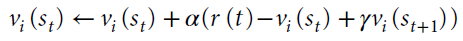
在这种情况下,我们使用赋值运算符←表示事件后的更新。变量st是时间t的状态,而γ是折扣未来状态价值的折扣因子。TD的RPE由下式定义:
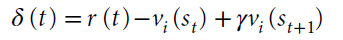
这个通用理论非常成功,它可以预测许多行为和神经数据。例如,大量工作表明,多巴胺神经元在不同条件下编码TD的RPE28,就学习而言,激活多巴胺神经元相当于经历RPE29-31。
但是,此模型保留了许多未指定的细节。例如,现在很明显,在RL下方是较大的一组互连区域(图3)。这些网络围绕一组重叠但隔离的皮质-基底神经节-丘脑-皮质系统组织。广义上讲,有一个与背侧纹状体互连的系统可以介导关于奖励空间认知过程的学习,例如,空间定向的眼球运动32-34,而另一个与腹侧纹状体互连的系统可以介导关于奖励性刺激的学习,特别是灵长类动物的刺激35,36。腹侧系统也有来自杏仁核的强大输入,杏仁核在了解环境中刺激的价值(正和负)方面起着重要作用26,37。
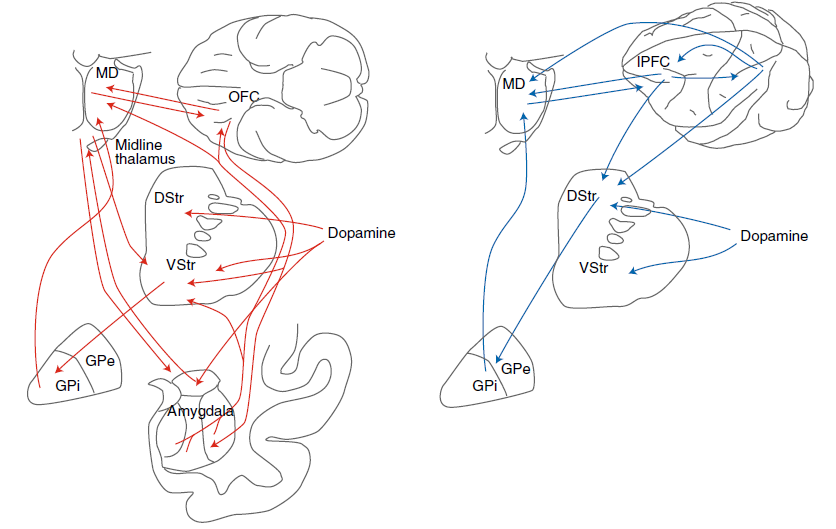
图3 | 强化学习基础的神经回路的扩展概念。示例系统取自恒河猴。线表示所指示区域之间的解剖连接。左侧的网络,红色专用于将价值与由感官信息定义的目标相关联。该网络将大部分腹侧结构互连,包括眶额皮质和腹侧纹状体。右侧的网络,蓝色专门用于将值与认知和空间过程相关联。该网络与背侧系统相交,包括背侧前额叶皮层和背侧纹状体。这些系统具有并行的组织,因此从皮质到基底神经节(纹状体和GPi)和丘脑,再回到皮质也以相似的方式组织。然而,杏仁核仅参与左侧所示的感觉网络。OFC:眶前额叶皮层。lPFC:外侧前额叶皮层。MD:内侧背丘脑。GPe/GPi:苍白球外部和内部部分。
背侧电路似乎没有相应的结构。例如,此处未包括的海马体突出到腹侧纹状体,而不是背侧纹状体37。同样重要的是要指出,虽然我们将背侧和腹侧系统呈现为独立的回路,但存在一个将前额叶皮层的所有部分连接到纹状体中相应区域的回路的梯度35,38。背侧和腹侧电路代表系统中的两个极点。此外,背侧系统在眼球运动中的作用和腹侧系统在视力中的作用在某种程度上取决于研究它们的任务。
Multiple timescales of learning
生物智能体必须解决多个时间尺度上的学习问题,而生物智能体中RL背后的神经系统反映了这一需求。在腹侧系统(图3,红线)中,杏仁核和纹状体存在相互作用和并行的组织。研究了这两个系统对RL的相对贡献的工作表明,杏仁核内的可塑性通过活动依赖性机制以较快的时间尺度运行,而纹状体中的多巴胺依赖性机制以较慢的时间尺度运行7,26。拥有以不同速率学习的并行神经系统,可以使生物智能体高效学习并跟踪在不同时间尺度上具有非平稳性的环境中变化的价值39。当选择的价值在较慢的时间尺度上演变时,较慢的纹状体/多巴胺依赖性系统会在嘈杂的环境中更有效地学习(图1c)。另一方面,当环境和选择的基础价值发展更快时,杏仁核/依赖于活动的系统将更有效地学习。但是,杏仁核系统更容易受到噪声的影响。杏仁核由于其快速的依赖于活动的可塑性机制,会错误地跟踪价值的嘈杂波动,如果噪声相对于信号而言较大,则可能导致不正确的价值估计。纹状体,因为它缓慢地更新价值,因此趋于整合出这种噪声。由于这两个系统都跟踪价值,因此下游系统必须在它们之间进行调解,并根据正在进行的可靠估计组合每个系统的价值估计。这种调解过程被称为机器学习领域的专家混合,该概念最早是在该领域开发的。如果其中一个系统提供了更准确的价值估计,则相对于另一个系统,应增加其对行为的贡献。目前尚不清楚该下游系统在哪里,尽管它可能位于皮层运动结构中,因此特定于效应器。但是,总体而言,该组织反映了解决RL问题的生物方法的基本原则。具体来说,大脑使用多个相互连接的系统来解决RL问题(图3)。它将问题分解为子问题,并使用多个并行但交互的系统灵活地解决学习问题。
在计算神经科学中,对突触可塑性的研究表明,学习的时间尺度与神经元和突触的动态过程直接相关41。具体而言,这些研究发现,脉冲时序依赖可塑性学习窗口,这决定权重更新的幅度(即突触可塑性),是突触后电位的直接反映。这通常在1-100ms内,依赖于神经元和突触类型。更普遍地,该理论暗示可塑性过程的时间尺度与神经活动的时间尺度相匹配。此外,理论和模型研究表明,同时具有慢速和快速时间尺度可实现扩展的存储容量42,43,提高性能44并加快学习速度45。因此,即使在单个神经元的水平上,以多个时间尺度进行学习也是有利的。时间尺度的多样性也是某些人工循环神经网络(例如由LSTM单元46组成)的主要特征。LSTM最初旨在通过引入一种记忆元件来改进学习的时间范围,该记忆元件的衰减时间常数是动态的,且与数据相关,这是受到生物学研究的工作记忆过程启发的。有趣的是,使用工作内存或多个时钟频率的模型已显示出可以重现LSTM的某些计算能力44,47。
与传统的机器学习和人工智能体中的RL相比,大脑中神经动态的连续运行需要进行大脑中的学习。在连续学习中,参数会在每个数据样本之后(即机器学习意义上的“在线”)进行顺序更新(即可塑性)48。相比之下,机器学习中常用的批量更新涉及在连接权重更新之前处理许多事件或“试验”。这需要存储这些试验。统计学习理论表明,在基于梯度的学习中,以连续的方式进行操作49在存储和计算复杂性方面都是有利的,前提是数据独立同分布(iid)。当违反iid情况时,数据采样中的相关性可能导致灾难性的干扰50,51,也就是说,旧知识往往被新知识覆盖。在RL中,这尤其成问题,因为数据是固有相关的,并且智能体通过选择动作来修改数据采样过程。有两个主要途径可以解决此问题:互补的学习和回放机制。通过回放机制,较旧的回放会再次呈现给网络51-54。通过补充学习,突触特定学习率会根据过去任务的相关性而变化12,55,56。在这种情况下,网络机制会估计任务中神经元和突触的重要性,并有选择地增强其参数。这两种机制都是受大脑启发的。
Learning to learn and model-based RL
除了上面讨论的无模型学习系统外,哺乳动物系统还可以使用更复杂的有模型推断策略来学习。附带说明一下,有模型术语最初专门指的是已知状态转换函数的RL学习问题,它允许Bellman更新57。但是,该术语更笼统地表示任何依赖于环境统计知识的学习过程,因此使用统计(通常是贝叶斯)模型。该领域的工作广泛借鉴了最初为解决人工智能体中的学习问题而开发的概念。对于有模型推断策略,有大量的行为证据58-61,但是相对于无模型学习59,62,目前对神经回路的了解还很少。有模型RL用于生物智能体的原始理论将有模型学习置于前额叶皮层57。这与前额叶皮层驱动的有关认知计划过程的一般想法是一致的63。但是,大多数随后的工作,以及最初的习惯和目标导向系统的大鼠实验都启发了这一理论64,这并不支持这种区别。一些研究表明,有模型学习和无模型学习都依赖于纹状体依赖的过程62,65,尽管一些研究表明前额叶皮层是有模型学习的基础60。因此,很明显,生物系统可以使用有模型方法进行学习,但是目前尚不了解这种学习形式基础的神经系统。
有模型学习的行为证据至少有三种形式。首先,哺乳动物可以学会学习66。这意味着,随着人们从该类别中接触到更多的示例,可以从对一类具有经验的问题中汲取的新问题的学习率提高。因此,随着时间的推移,将了解基础推断过程或生成数据的模型的统计信息。例如,在逆向学习实验中,在两个选项之间给动物一个选择,可以是位置随机化的两个目标62,67,68。选择其中一个选项会导致奖励,而选择另一个选项则不会导致奖励。一旦动物学会了选择更好的选择,就切换选择-结果映射,以便不再奖励先前奖励的选项,而奖励先前未奖励的选项。(在此问题的概率版本中,选择的奖励频率有所不同,并且这些频率在反转时切换。)当动物遭受一系列此类反转时,它们切换偏好的速率会随着经验提高。因此,可能需要五到十次尝试才能在意外情况第一次反转时切换偏好。但是,有了足够的经验,这些动物可能仅在一项或两项试验中就可以逆转偏好。这个过程可以由一个模型来捕获,该模型假定贝叶斯先验优于发生逆转的可能性68。先验开始时较低,因为动物大多受到稳定的,不会逆转的刺激结果的影响。由于先验水平低,因此动物在推断已经发生逆转之前需要大量证据。当他们未能获得先前奖励过的选择的奖励时,他们认为这是奖励交付过程中的噪声,而不是选择-结果映射中的实际逆转。但是,根据任务的经验,先验逆转会增加,并且动物在推断发生逆转之前需要较少的证据,因此它们会更快地逆转其选择偏好。
在人工智能体中,学会学习已作为迁移学习的一种原则方法而提出,因为能够跨一类相关任务进行概括的能力意味着用于解决一项任务的信息已迁移到另一项任务上。这个想法是最近的元强化学习方法的基础69,在该方法中,由多巴胺驱动的突触可塑性在前额叶皮层建立了基于活动的学习。有趣的是,在一类相关问题之间成功地迁移知识等同于统计机器学习意义上的泛化,并且暗含了上述灾难性遗忘问题的原则性解决方案。
其次,与第一种有模型学习有关,当动物具有足够的统计问题经验时,他们可以使用概率推断或潜伏状态推断来解决学习问题70,71。有了足够的经验,动物可以了解到特定的统计模型对于解决实验问题是最优的。这些模型可以比无模型学习方法更有效地解决学习问题。如果哺乳动物系统能够学习正确的模型,则概率推断可以保证是最优的72。在随机逆向学习中,在动物获悉发生逆转之后,可以使用贝叶斯推断有效地完成统计逆转的检测。这是状态推断,因为奖励环境处于两种状态之一(即,选择一或选择二的频率更高)。与执行无模型价值更新相比,此过程可以更快且更高效。为了通过无模型价值更新来解决此问题,动物必须在每次试验中使用反馈来更新所选选项的价值。除了贝叶斯状态推断的效率外,还显示出动物可以在逆转点上学习先验,在逆转往往发生在可预测的时间点的任务中58。这比上面讨论的先验更为复杂,后者是发生逆转的先验。逆转时间的先验反映了人们对逆转倾向于在特定时间点发生的认识,因此隐含地假设发生了这种情况。当随机选择-结果映射使推断变得困难时,这些先验将起重要作用。例如,如果两臂赌博机任务中的最优选择在60%的时间内提供了奖励,次优选择在40%的时间内提供了奖励,那么根据接收到的奖励很难检测到选择结果映射中的逆转,先验可以提高性能。然而,将快速的无模型学习与有模型学习相分离并不总是那么容易,因此,需要仔细的任务设计和模型拟合来证明生物系统中有模型学习。这些推断过程的许多工作表明它们发生在皮层中70,71,73,74。这就提出了一个问题,即这些过程是否需要可塑性,或者它们是否依赖于更快的计算机制,例如吸引子动态。例如,推断过程可能将皮层网络中的活动推到吸引池中,类似于工作记忆的基础75,76。
快速学习的第三种也是最后一种形式是有模型Bellman RL,更准确地说它被称为动态编程。在这种有模型学习形式中,人们具有环境统计知识9,77。这些统计信息包括状态动作奖励函数r(st, a),状态价值函数ut(st)和状态转换函数p(j | st, a)。一旦知道了这些函数,就可以使用Bellman方程来到达快速但有计算需求的问题解决方案。
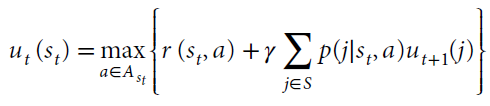
该方程表明,当前状态的价值st等于动作a的即时奖励r(st, a)的可能动作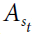 的最大值,加上该状态前向的折扣最大期望奖励 ,这是可到达状态集合S中对未来状态 j 的期望价值。在计算工作中以及相应地在生物系统中,人们很少访问求解Bellman方程所需的所有信息,因此无模型方法通常是学习状态或动作价值函数所必需的。然而,在某些条件下,生物系统可以学习状态转换函数,并且这些状态转换函数可以使学习更有效59,60,78,79。但是,无模型和有模型的学习方法往往会收敛到相同的结果。因此,已将这些解决方案针对具有固有非平稳性的问题进行了比较。然后,有模型系统可以提高对非平稳性的跟踪能力,从而可以更快地学习有模型系统。
的最大值,加上该状态前向的折扣最大期望奖励 ,这是可到达状态集合S中对未来状态 j 的期望价值。在计算工作中以及相应地在生物系统中,人们很少访问求解Bellman方程所需的所有信息,因此无模型方法通常是学习状态或动作价值函数所必需的。然而,在某些条件下,生物系统可以学习状态转换函数,并且这些状态转换函数可以使学习更有效59,60,78,79。但是,无模型和有模型的学习方法往往会收敛到相同的结果。因此,已将这些解决方案针对具有固有非平稳性的问题进行了比较。然后,有模型系统可以提高对非平稳性的跟踪能力,从而可以更快地学习有模型系统。
Artificial connectionist RL agents
机器学习和RL技术在人工系统中的最新成功激发了人们对解决人工智能实际问题的广泛兴趣,例如自然语言处理,语音生成,图像识别,自动驾驶和游戏。这种新的兴趣在很大程度上是由于深度神经网络的突破以及支持它们的技术的进步。实际上,在人工智能体中,必须从高维感官数据(例如,来自摄像机的像素强度值)推断出与任务相关的环境特征(状态)。人类观察者可以立即在视觉数据中识别目标及其相对位置,并为这些目标指定含义。要在人工系统中解决这些问题并获得最先进的性能,就需要专门的结构和大量的训练数据53。早期的模式识别模型使用手工创建的特征或线性模型从高维感官刺激中提取状态。这些方法需要特定领域的知识,并且学习仅限于所选领域。得益于庞大的数据集和改进的计算技术,深度学习在将高维感官刺激映射到任务相关输出方面取得了令人惊讶的成功,在RL的情况下,从传感器数据到选定的动作价值的映射也取得了成功。由于这些神经网络是通用函数逼近器,因此它们几乎不需要特定领域的假设即可学习与环境相关的任务表示。早期实施成功解决了诸如backgammon82和自动驾驶汽车控制83之类的复杂任务。借助改进的硬件和算法来防止学习不稳定,这些早期方法逐渐发展为可以在各种领域(甚至在游戏和电机控制)中达到或超过人类能力的算法53,84-86。
能否利用深度网络和深度RL的成功来更好地了解生物智能体?有趣的是,人工循环神经网络的数学框架可以充分描述生物神经网络的简单模型(例如,LIF神经元)的离散时间近似值。确实,生物神经网络是循环的(即它们是有状态的并且具有循环连接),二值的(即它们通过动作电位进行通信)并连续运行(神经元可以在任何时间点发出动作电位)87,并且通常在ANN中研究此类属性。生物和主流人工学习系统之间最大的差异之一是体系结构:内部状态(例如神经递质浓度,突触状态和膜电位)是局部的。广义上讲,局部性是由处理元素(例如,神经元和突触)的一组可用变量来表征的。机器学习中的许多关键计算都需要非局部的信息,例如,以解决责任分配问题。使得非局部信息可用于神经过程需要专门的通道来传达此信息88。多巴胺途径就是这样的一个例子。但是,多巴胺系统提供的信息仅是评估性的。因此,桥接神经科学和机器学习的一个重要挑战是要了解可塑性过程如何有效地利用这种评估反馈进行学习。有趣的是,越来越多的工作表明,与生物神经网络兼容的梯度反向传播的近似形式自然会包含这种反馈,并且使用它们进行训练的模型在经典分类基准上可获得接近最新的结果89-91。突触可塑性规则可以从梯度下降中得出,从而导致“三因素”规则,这与误差调节的Hebbian学习相一致(图4)。此外,学习的规范推导显示出可塑性动态与之前讨论的神经和突触时间常数(大约1-100ms)相匹配,从而可以有效地学习脉冲的时空模式。
尽管这些结果尚未扩展到深度RL,但已证明生物和人工神经网络之间的等效性88暗示了机器学习算法与神经科学之间存在多个直接接触点。通过这种联系,出现了两个关键挑战。首先,即使是在简单的经典视觉基准和控制下(后者很容易需要数百万个样本——例如,玩游戏53或用机器人控制装置抓握92),实时深度神经网络学习也需要不切实际的经验才能达到人类级别的分类精度(图1d)。快速学习很重要,因为从行为上讲,智能体必须适应其内部表征,至少与环境变化的时间尺度一样快。出现的第二个挑战是生物智能体学习“行为”,这意味着对环境或数据集进行非固定采样,如前所述(请参阅“学习的多时间尺度”部分)。
深度学习的缓慢可以部分归因于训练算法的基于梯度下降的特性,该特性需要以小增量进行多次更新才能稳定地接近局部最小值。因此,在模型中内置的特定领域知识的数量与学习潜在问题所需的试验次数之间,存在学习速度的根本权衡。这也是有模型RL比无模型RL具有更高数据效率的相同原因。系统中内置的领域知识越多,数据效率就越高。通过设计,使用很少或没有领域特定知识即可初始化深度RL,因此梯度下降无法基于单次经验显著改进深度RL模型。相比之下,有模型RL结合了特定问题的知识和其他不依赖于梯度下降的相关方法,例如表格法和episodic控制1,93,94,通常可以提高数据效率。无模型和有模型的RL的互补功能表明,成功的人工智能体很可能包括这两个组件(可能以分层方式)。元学习技术可以在一类相关任务上“预训练”神经网络95(本着先前讨论的贝叶斯先验的精神),层次结构(模块化)和有效的模型学习96,97有望在解决数据效率问题中发挥关键作用。
RL问题的各个组成部分以不同的方式面临挑战,因此,生物智能体已经发展了针对该单独问题进行了优化的多个系统。例如,在变化的环境中灵活地更新状态价值需要解决不同于状态推断的问题(例如,目标及其位置的标识)98。目标识别具有挑战性,因为视网膜输出(在生物系统中)或像素值(在相机中)与对象类别之间的映射是高度非线性的99。灵活地更新状态价值具有挑战性,因为必须在一段时间内记住或存储更新价值所必需的信息,并且必须将奖励结果归因于适当的先前决策才能解决责任分配问题101。贝叶斯推断模型也很复杂。例如,它们通常要求跨层次级别的变量进行非线性交互102。因此,基于这些模型的学习需要高复杂度的计算。除了将RL问题分解为状态推断,价值更新和动作选择问题外,生物智能体还使用经过优化以在不同条件下学习的多个神经系统。这种分工导致了生物湿件(大脑)的有效解决方案。
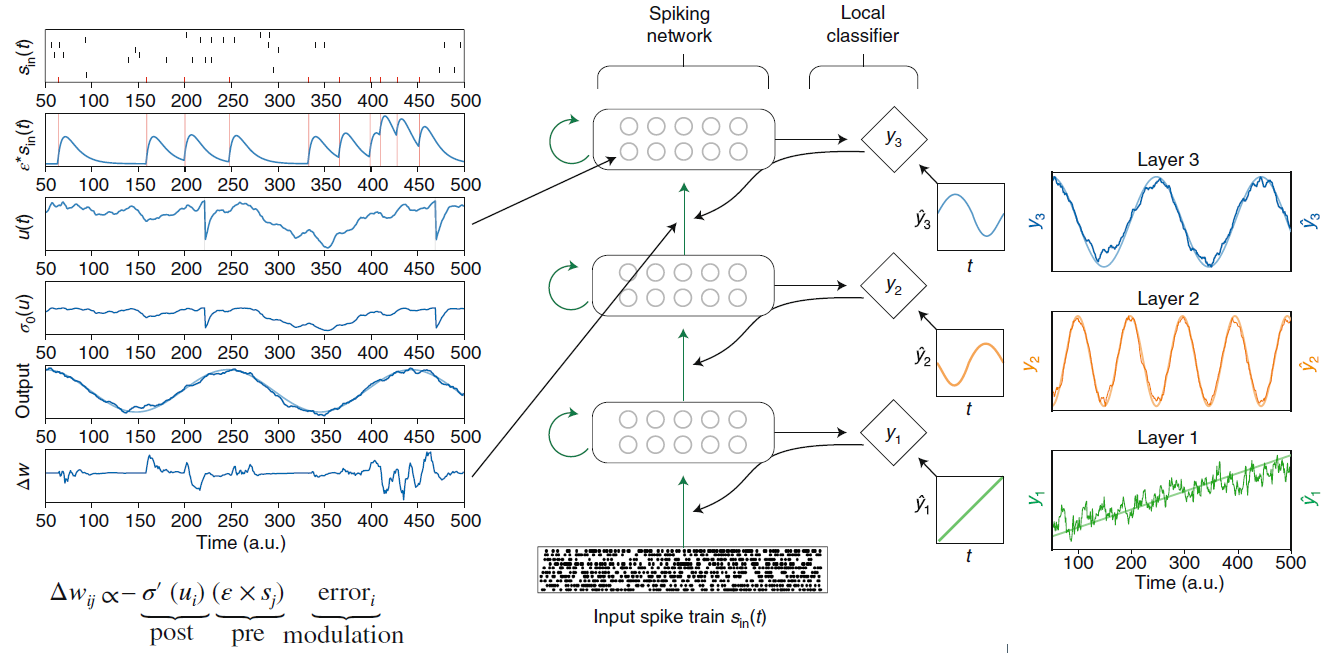
图4 | 基于脉冲的深度连续局部学习(DCLL)模型。在前馈网络中,脉冲神经元的每一层还通过固定的随机连接另外送入局部分类器(菱形)。训练局部分类器以产生辅助对象ŷ。在该学习方案中,局部分类器中的误差通过随机连接传播,以训练进入脉冲层的权重,但不能继续传播(弯曲,虚线),因此该学习仅限于该层。这里的突触可塑性规则是从梯度下降中得出的。结果规则由突触前项(突触前轨迹线),突触后项(神经激活概率的导数)和误差组成,并且与调节的Hebbian方案一致。左面板显示了顶层学习过程中神经状态的快照,其中u(t)是膜电位,ε是突触后电位响应。在此示例中,训练网络以生成三个随时间变化的辅助对象(对象,ŷ;预测,y)。这种学习架构和动态在时空模式上实现了近乎最新的分类。改编自参考89(预印本)。
Hierarchical RL
尽管已经在生物系统中研究的大多数学习问题都很简单,但是许多行为,尤其是人类行为,是复杂且具有层次性的103-109。例如,当我们开车去杂货店时,我们并没有想到首先走到桌子上,然后拿起车钥匙,走到门口等所有必要的肌肉激活。大多数低级行为是自动化的,然后对这些低级组件进行高级别排序。这些想法中的几个已经被并入最新的分层RL算法中。分层强化学习(HRL)致力于将相关的低级动作序列分组为按层次组织的子目标。将任务抽象为子目标时,可以更有效地学习它们110,111。这是将知识构建到学习算法中以提高数据效率以及相应地提高学习率的另一个示例。为了充分利用抽象,习惯上层次结构的每个级别都独立运行于其他级别和奖励。然后,问题转移到定义有意义的子目标,层次结构的每一层都应解决这些目标。由于有意义的子目标简化了学习过程中的责任分配问题,因此了解子目标的学习方式可以提供对生物系统的见解。当前,在这个重要领域,人工系统的工作领先于生物系统。具体而言,已经开发了几种模型来使用分层方法训练人工系统。但是,了解生物系统如何解决这些问题的工作很少。为解决人工系统中的学习问题而开发的模型可能被证明有助于理解生物系统中的这些问题。
Sutton et al.[111]提出了最早的HRL算法之一,称为选项框架。选项是行为的人工构建基块,因此包含了大量特定领域的知识。例如,在机器人中,名为“充电”的选项可能包含一个策略,该策略用于搜索充电站,导航至充电站并启动对接序列。更高级别的抽象隐藏了诸如详细导航之类的低级别操作,并提供了简洁的构建块来实现目标导向的行为。在一个称为封建RL的相关算法中,系统由管理者组成,他们学习为其子管理者设置任务,并且子管理者在学习如何实现任务的同时监督这些任务。这种学习在分布式场景中很有趣,因为子管理者只需使用分配给他们的粒度级别上的信息就可以在其局部环境中最大化回报110。尽管层次结构在选项框架中是固定的,但其他较新的模型(包括封建网络和选项评论者)则专注于学习此层次结构。这些模型旨在自动学习分层任务结构,例如子策略或子目标87,112。HRL的主要挑战是设定中间对象或子目标。一种选项是使用一种内在的动机(例如好奇心)来寻求有关环境的新颖性86,或者使用诸如预测视觉特征之类的辅助任务113来促进探索和预测环境的未来状态114。另一个相关方法是提供监督信号,例如在模仿学习中115,116,在可用时使用专家指令。
虽然刚刚开始研究构成生物智能体中HRL的神经系统,但研究表明,构成无模型RL的相同额叶网络是相关的107,117。例如,这些研究表明前额叶皮层,特别是背侧前额叶皮层包含一个梯度,使得尾部区域实现了行为的低级方面,而鼻部区域实现了行为的抽象方面,从而进一步扩展了层次103,117,118。如同人工智能体的情况一样,生物系统中的层次控制的一个主要悬而未决的问题是如何学习它们如何将行为分组为子目标。除行为描述外,对该过程知之甚少119。但是,人工系统的最新进展为在生物系统中更有效地研究这些问题提供了一个概念框架。例如,深度连续局部学习(DCLL)中的辅助对象(图4)提供了这样一种框架,其中可以包含中间对象和目标。
Neuromorphic approaches
尽管机器学习和神经网络与脑科学有着共同的历史,但是最近的许多发展却偏离了这些根源。进行此分支的一个关键原因是,我们使用的计算机在许多方面与大脑不同。当现代冯·诺依曼计算机体系结构所施加的某些约束放宽时,推断和学习性能将得到提高。例如,与批处理学习相比,引入连续时间和在线逐样本参数更新(类似于大脑中的突触可塑性)90,所需的基本操作更少。但是,在主流计算机上,神经网络计算通常以批处理方式进行以利用硬件并行性,并且参数更新会导致内存开销,从而使近连续时间更新次优。另一个例子是胶囊网络120,最好在大规模并行(类似于大脑)的硬件上实现。这些观察结果表明,在传统计算机上禁止计算的方法易于处理,有时甚至在像大脑这样的大规模并行计算系统中也很有用。
神经形态工程学通过从大脑构建模块(例如SNN)中获得灵感来努力将设备物理与行为联系起来。具有片上自适应能力121-123的神经形态硬件和加速器的最新发展为设计和评估脑启发的处理和学习算法提供了一个平台。示例系统被证明为可编程的通用感觉运动处理器124和强化学习125。
该硬件致力于在数字或模拟技术中模拟大脑的动态和结构特性。它们由大量生物学合理的模型神经元组成,通常配备突触可塑性以支持在线学习。这些学习动态与计算神经科学中的建模工作兼容,例如图4中绘制的三因素学习规则。
尽管可以研究甚至实施强化学习的更高级别的实施方法126,但这些方法并不能直接解决物理机器的实际情况,例如设备之间的差异,噪声和非局部性如何影响动物的推断和学习策略。神经形态计算与其物理基底密切相关的事实提出了计算难题,而使用常规数字硬件进行建模时通常会忽略这些难题。这些挑战来自共同定位处理和存储器的工程和通信挑战,此类存储器的能源和硬件成本(这会导致参数和状态量化),以及在新兴设备或模拟技术的情况下基底的不可靠性。如果解决了责任分配问题,神经元的脉冲特性对性能的影响很小(图4),但是在学习过程中突触权重参数低于8比特精度的量化开始影响分类性能127,128,这仍然是一个公开挑战。这些挑战也存在于大脑中,因此人工和生物智能体界面上的计算模型在解决这些问题中起着关键作用。
捕捉生物视网膜特征的神经形态视觉传感器129已经在工业和学术界改变了计算机视觉的格局。尽管目前作为通用或RL处理器的神经形态设备仍处于研究阶段,但新存储设备的发现以及摩尔定律迫在眉睫的结束要求这种替代计算策略。展望未来,借助这样的硬件系统,人工学习与生物学习之间的桥梁可以直接转化为有益于医疗,运输和嵌入式计算的智能自适应技术。
Conclusions
可以开发人工智能体来执行人们当前执行的许多任务。无人驾驶汽车只是目前正在开发的一个例子。为了使这些智能体成功,他们必须能够适应各种条件并不断学习。从生物智能体的持续学习研究中获得的见解,包括使用多个并行运行的学习系统,这些系统针对不同环境中的学习进行了优化,对于开发更有效的人工智能体可能有用。此外,生物系统已将RL问题分解为感觉处理,价值更新和动作输出组件。这使大脑可以将处理过程优化到每个系统所需的可塑性时间尺度。
生物系统中的大多数工作都基于简单的巴甫洛夫条件范式(不需要明显的行为响应)或双臂赌博机任务,其中动物必须学习哪种动作最有价值,并随着时间的推移更新这些动作价值。尽管巴甫洛夫式条件和赌博机学习是生物系统学习的基础,但自然环境中的实际行为要复杂得多。这些问题正在使用分层强化学习的人工系统中得到解决。为研究人工系统中的这些问题而开发的许多算法在生物系统中可能很有用。另外,HRL的难题之一是学习如何将复杂的问题分解为子目标。在行为级别,生物系统会常规执行此操作,因此,从对生物系统行为的研究中获得的见识可能会转化为人工系统中的算法。相应地,为人工系统开发的算法可以帮助解决生物学实验中的问题。
理解大脑中的多个神经系统如何在不同的环境中进行不断学习,已经以新颖的算法和可实现大型神经网络的脑启发神经形态硬件的形式,为复杂的工程问题提供了启发性的解决方案。神经形态硬件在与大脑相似的动态和架构约束下运行,因此提供了一个吸引人的平台来评估神经科学启发的解决方案。最近开发的神经形态硬件工具由于其持续的推断和学习而成为了在移动平台上进行实际任务的理想候选者,而这种推断和学习是在非常紧张的能源预算下进行的。
RL的大多数最新算法采用领域通用或广义函数逼近方法,并且需要大量数据和训练时间。就像在大脑中所做的那样,将问题分解为状态推断,价值更新和动作选择组件,可以允许更有效的学习,并能够在快速的时间尺度上跟踪环境的变化,这类似于生物系统。能够加强学习的生物和人工智能体界面上正在进行的工作将为大脑提供更深入的见识,并为解决现实问题提供更有效的人工智能体。
Reinforcement learning in artificial and biological systems的更多相关文章
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- (转) Reinforcement Learning for Profit
Reinforcement Learning for Profit July 17, 2016 Is RL being used in revenue generating systems today ...
- (转)Applications of Reinforcement Learning in Real World
Applications of Reinforcement Learning in Real World 2018-08-05 18:58:04 This blog is copied from: h ...
- (zhuan) Paper Collection of Multi-Agent Reinforcement Learning (MARL)
this blog from: https://github.com/LantaoYu/MARL-Papers Paper Collection of Multi-Agent Reinforcemen ...
- (转) Deep Learning in a Nutshell: Reinforcement Learning
Deep Learning in a Nutshell: Reinforcement Learning Share: Posted on September 8, 2016by Tim Dettm ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- (zhuan) Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Evolution Strategies as a Scalable Alternative to Reinforcement Learning this blog from: https://blo ...
- Reinforcement Learning for Self Organization and Power Control of Two-Tier Heterogeneous Networks
R. Amiri, M. A. Almasi, J. G. Andrews and H. Mehrpouyan, "Reinforcement Learning for Self Organ ...
- Machine Learning Algorithms Study Notes(5)—Reinforcement Learning
Reinforcement Learning 对于控制决策问题的解决思路:设计一个回报函数(reward function),如果learning agent(如上面的四足机器人.象棋AI程序)在决定 ...
随机推荐
- DOM事件操作
DOM事件:对事件做出反应 当事件发生时,可以执行 JavaScript,比如:点击时 onClick="" 例:当用户点击时,会改变 <h1> 元素的内容: < ...
- 不使用字体图标和图片,只使用css如何做出展开收起的效果
<i class="iconArrow" :class="[ littleNavState === item.meta.id ? 'arrowOpen' : '' ...
- map 函数基本写法
map(需要对对象使用的函数,要操作的对象) 函数可以是自定义的,也可以是内置函数的,或者 lambda 匿名函数 操作的对象多为 可迭代对象可以是函数名的列表集合 2020-05-04
- luogu 3158 [CQOI2011]放棋子
时隔多日 我又来挑战这道dp. 几个月前给写自闭了.几个月后再来. 首先一个我们能列出来的状态 是以行为转移的 f[i]表示前i行...但是会发现此时列我们控制不了 且棋子的颜色,个数我们也要放到状态 ...
- Fragment为什么须要无参构造方法
日前在项目代码里遇到偷懒使用重写Fragment带参构造方法来传参的做法,顿生好奇,继承android.support.v4.app.Fragment而又不写无参构造方法不是会出现lint错误编译不通 ...
- day10.函数基础及函数参数
一.函数 功能:包裹一部分代码 实现某一个功能 达成某一个目的 特点: """ 特点:可以反复调用,提高代码的复用性,提高开发效率,便于维护管理 函数基本格式 函数的定义 ...
- MPI运行时间测量
转载自:https://blog.csdn.net/silent56_th/article/details/80419314 翻译自:https://stackoverflow.com/questio ...
- 眼见为实 — CSS的overflow属性
1. overflow属性 CSS的overflow属性指定当内容溢出一个元素的框,会发生什么.举个栗子: <!DOCTYPE html> <html> <head> ...
- JVM系列之:再谈java中的safepoint
目录 safepoint是什么 safepoint的例子 线程什么时候会进入safepoint safepoint是怎么工作的 总结 safepoint是什么 java程序里面有很多很多的java线程 ...
- 性能分析(4)- iowait 使用率过高案例
性能分析小案例系列,可以通过下面链接查看哦 https://www.cnblogs.com/poloyy/category/1814570.html 前言 前面两个案例讲的都是上下文切换导致的 CPU ...