Databricks 第5篇:Databricks文件系统(DBFS)
Databricks 文件系统 (DBFS,Databricks File System) 是一个装载到 Azure Databricks 工作区的分布式文件系统,可以在 Azure Databricks 群集上使用。 一个存储对象是一个具有特定格式的文件,不同的格式具有不同的读取和写入的机制。
DBFS 是基于可缩放对象存储的抽象,可以根据用户的需要动态增加和较少存储空间的使用量,Azure Databricks中装载的DBFS具有以下优势:
- 装载(mount)存储对象,无需凭据即可无缝访问数据。
- 使用目录和文件语义(而不是存储 URL)与对象存储进行交互。
- 将文件保存到对象存储,因此在终止群集后不会丢失数据。
一,DBFS根
DBFS 中默认的存储位置称为 DBFS 根(root),以下 DBFS 根位置中存储了几种类型的数据:
- /FileStore:导入的数据文件、生成的绘图以及上传的库
- /databricks-datasets:示例公共数据集,用于学习Spark或者测试算法。
- /databricks-results:通过下载查询的完整结果生成的文件。
- /tmp:存储临时数据的目录
- /user:存储各个用户的文件
- /mnt:(默认是不可见的)装载(挂载)到DBFS的文件,写入装载点路径(/mnt)中的数据存储在DBFS根目录之外。
在新的工作区中,DBFS 根具有以下默认文件夹:
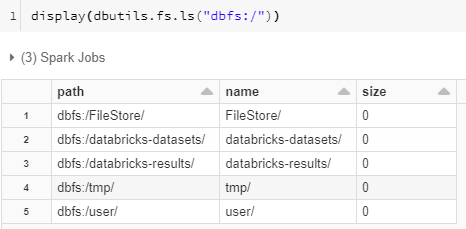
DBFS 根还包含不可见且无法直接访问的数据,包括装入点元数据(mount point metadata)和凭据(credentials )以及某些类型的日志。
DBFS还有两个特殊根位置是:FileStore 和 Azure Databricks Dataset。
- FileStore是一个用于存储文件的存储空间,可以存储的文件有多种格式,主要包括csv、parquet、orc和delta等格式。
- Dataset是一个示例数据集,用户可以通过该示例数据集来测试算法和Spark。
访问DBFS,通常是通过pysaprk.sql 模块、dbutils和SQL。
二,使用pyspark.sql模块访问DBFS
使用pyspark.sql模块时,通过相对路径"/temp/file" 引用parquet文件,以下示例将parquet文件foo写入 DBFS /tmp 目录。
#df.write.format("parquet").save("/tmp/foo",mode="overwrite")
df.write.parquet("/tmp/foo",mode="overwrite")
并通过Spark API读取文件中的内容:
#df = spark.read.format("parquet").load("/tmp/foo")
df = spark.read.parquet("/tmp/foo")
三,使用SQL 访问DBFS
对于delta格式和parquet格式的文件,可以在SQL中通过 delta.`file_path` 或 parquet.`file_path`来访问DBFS:
select *
from delta.`/tmp/delta_file` select *
from parquet.`/tmp/parquet_file`
注意,文件的格式必须跟扩展的命令相同,否则报错;文件的路径不是通过单引号括起来的,而是通过 `` 来实现的。
四,使用dbutils访问DBFS
dbutils.fs 提供与文件系统类似的命令来访问 DBFS 中的文件。 本部分提供几个示例,说明如何使用 dbutils.fs 命令在 DBFS 中写入和读取文件。
1,查看DBFS的目录
在python环境中,可以通过dbutils.fs来查看路径下的文件:
display(dbutils.fs.ls("dbfs:/foobar"))
2,读写数据
在 DBFS 根中写入和读取文件,就像它是本地文件系统一样。
# create folder
dbutils.fs.mkdirs("/foobar/") # write data
dbutils.fs.put("/foobar/baz.txt", "Hello, World!") # view head
dbutils.fs.head("/foobar/baz.txt") # remove file
dbutils.fs.rm("/foobar/baz.txt") # copy file
dbutils.fs.cp("/foobar/a.txt","/foobar/b.txt")
3,命令的帮助文档
dbutils.fs.help()
dbutils.fs 主要包括两跟模块:操作文件的fsutils和装载文件的mount
fsutils
cp(from: String, to: String, recurse: boolean = false): boolean -> Copies a file or directory, possibly across FileSystems
head(file: String, maxBytes: int = 65536): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
ls(dir: String): Seq -> Lists the contents of a directory
mkdirs(dir: String): boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
mv(from: String, to: String, recurse: boolean = false): boolean -> Moves a file or directory, possibly across FileSystems
put(file: String, contents: String, overwrite: boolean = false): boolean -> Writes the given String out to a file, encoded in UTF-8
rm(dir: String, recurse: boolean = false): boolean -> Removes a file or directorymount
mount(source: String, mountPoint: String, encryptionType: String = "", owner: String = null, extraConfigs: Map = Map.empty[String, String]): boolean -> Mounts the given source directory into DBFS at the given mount point
mounts: Seq -> Displays information about what is mounted within DBFS
refreshMounts: boolean -> Forces all machines in this cluster to refresh their mount cache, ensuring they receive the most recent information
unmount(mountPoint: String): boolean -> Deletes a DBFS mount point
参考文档:
Databricks 第5篇:Databricks文件系统(DBFS)的更多相关文章
- 鸿蒙内核源码分析(挂载目录篇) | 为何文件系统需要挂载 | 百篇博客分析OpenHarmony源码 | v65.01
百篇博客系列篇.本篇为: v65.xx 鸿蒙内核源码分析(挂载目录篇) | 为何文件系统需要挂载 | 51.c.h.o 文件系统相关篇为: v62.xx 鸿蒙内核源码分析(文件概念篇) | 为什么说一 ...
- 鸿蒙内核源码分析(索引节点篇) | 谁是文件系统最重要的概念 | 百篇博客分析OpenHarmony源码 | v64.01
百篇博客系列篇.本篇为: v64.xx 鸿蒙内核源码分析(索引节点篇) | 谁是文件系统最重要的概念 | 51.c.h.o 文件系统相关篇为: v62.xx 鸿蒙内核源码分析(文件概念篇) | 为什么 ...
- Databricks 第8篇:把Azure Data Lake Storage Gen2 (ADLS Gen 2)挂载到DBFS
DBFS使用dbutils实现存储服务的装载(mount.挂载),用户可以把Azure Data Lake Storage Gen2和Azure Blob Storage 账户装载到DBFS中.mou ...
- Databricks 第6篇:Spark SQL 维护数据库和表
Spark SQL 表的命名方式是db_name.table_name,只有数据库名称和数据表名称.如果没有指定db_name而直接引用table_name,实际上是引用default 数据库下的表. ...
- Databricks 第7篇:管理Secret
有时,访问数据要求您通过JDBC对外部数据源进行身份验证,可以使用Azure Databricks Secret来存储凭据,并在notebook和job中引用它们,而不是直接在notebook中输入凭 ...
- Databricks 第9篇:Spark SQL 基础(数据类型、NULL语义)
Spark SQL 支持多种数据类型,并兼容Python.Scala等语言的数据类型. 一,Spark SQL支持的数据类型 整数系列: BYTE, TINYINT:表示1B的有符号整数 SHORT, ...
- Databricks 第10篇:Job
Job是立即运行或按计划运行notebook或JAR的一种方法,运行notebook的另一种方法是在Notebook UI中以交互方式运行. 一,使用UI来创建Job 点击"Jobs&quo ...
- Databricks 第11篇:Spark SQL 查询(行转列、列转行、Lateral View、排序)
本文分享在Azure Databricks中如何实现行转列和列转行. 一,行转列 在分组中,把每个分组中的某一列的数据连接在一起: collect_list:把一个分组中的列合成为数组,数据不去重,格 ...
- Databricks 第四篇:分组统计和窗口
对数据分析时,通常需要对数据进行分组,并对每个分组进行聚合运算.在一定意义上,窗口也是一种分组统计的方法. 分组数据 DataFrame.groupBy()返回的是GroupedData类,可以对分组 ...
随机推荐
- 关于EF框架EntityState的几种状态
在使用EF框架时,我们通常都是通过调用SaveChanges方法把增加/修改/删除的数据提交到数据库,但是上下文是如何知道实体对象是增加.修改还是删除呢?答案是通过EntityState的枚举值来判断 ...
- LZZ磁力资源搜索4.2.2,整合多个站点,大部分资源都能搜到
资源搜索 4.2.2.20200310网友提出的功能已完成1:新增 时间日期排序,单击表头或右键菜单选择,即可自动排序2:新增 搜索完毕 音效开启或关闭 选项3:资源站点 Sunyaa 由聚合站点改为 ...
- Codeforces Edu Round 60 A-E
A. Best Subsegment 显然,选择数列中的最大值当做区间(长度为\(1\)).只要尝试最大值这个区间是否能扩展(左右两边值是否跟它一样就行了) #include <cstdio&g ...
- 题解-The Number of Good Intervals
题面 The Number of Good Intervals 给定 \(n\) 和 \(a_i(1\le i\le n)\),\(m\) 和 \(b_j(1\le j\le m)\),求对于每个 \ ...
- mybatis逆向工程运行
命令: mvn mybatis-generator:generate 项目结构: generatorConfig.xml内容示例 <?xml version="1.0" en ...
- docker 添加Portainer容器图形化管理工具
主要参照了这边博客,但还是有些问题https://www.cnblogs.com/Bug-Hunter/p/12023130.html 比如端口9000得开启,docker端口映射得开启,得开启ip4 ...
- jsp+servlet实现美妆店铺开发
一般的商城都有用户端和商城端两个部分,用户端就是给普通用户使用的,像我们在淘宝购物,我们就是使用的用户端:然而淘宝还分了很多个店铺,每个店铺的商品都是店老板安排人员去管理,那店老板管理自己的店铺用到的 ...
- 【PY从0到1】第一节 安装与界面介绍
本系列是介绍如何用Python进行股票量化交易的课程. 课程内容以记录Python零基础学员从最简单的Python下载及安装开始,到最后能熟练运用Python进行量化交易的专业人员的成长历程.旨在打造 ...
- 用burp爆破tomcat的过程
首先burp抓包,将抓到的包放到intruder中 通过burp中自带的解码得知账号密码中有个":"号 所以我们选择的数据类型为Custom iterator 第二条输入" ...
- gcc编译阶段打印宏定义的内容
背景 总所周知,代码量稍微大一点的C/C++项目的一些宏定义都会比较复杂,有时候会嵌套多个#if/#else判断分支和一堆#ifdef/#undef让你单看代码的话很难判断出宏定义的具体内容. 如果有 ...