关于情感分类(Sentiment Classification)的文献整理
最近对NLP中情感分类子方向的研究有些兴趣,在此整理下个人阅读的笔记(持续更新中):
1. Thumbs up? Sentiment classification using machine learning techniques
年份:2002;关键词:ML;引用量:9674;推荐指数(1-5):2
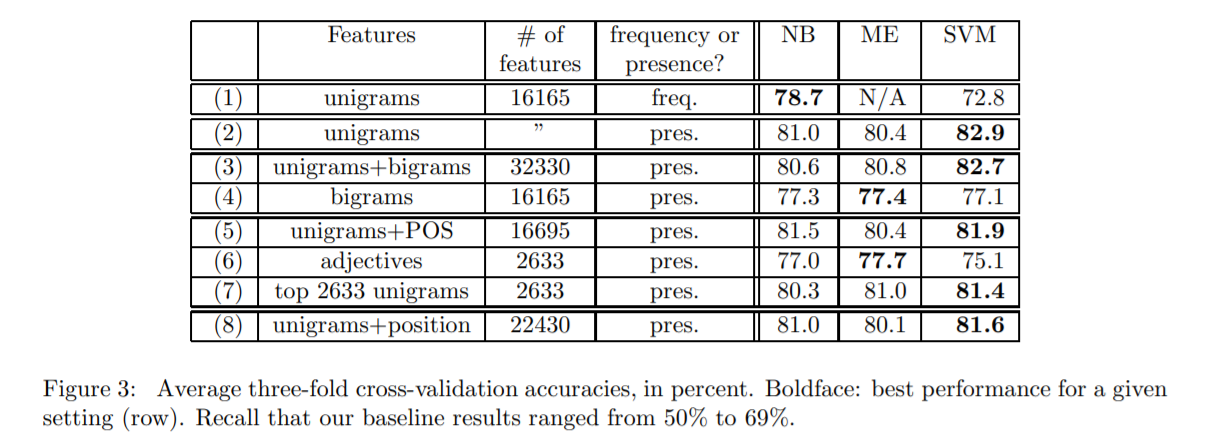
描述:基于电影评价,使用传统ML模型(Navie Bayes, maximum entropy classification和SVM)做情感分析。
心得:
(1)主题分类(Topic Classification)≈情感分类(Sentiment Classification),但后者更难,因为前者更关注于找到识别性强的关键词,而后者更微妙些,比如:电影评价中会有“thwarted expectations”期待受挫败的评价(即用户说了一堆自己原本对电影的正面期待,但最后就说了一句表示不满意的话),这样常误导分类器认为该类评论是正面的,实际上不对。因此“the whole is not necessarily the sum of the parts”是当时研究的一个瓶颈。
(2)简单来说作者的做法是:BOW(基于frequency或presence)+ unigram/bigrams + POS/adjectives/position + NB/ME/SVM。依次讨论下做法各模块:
- BOW:情感分类使用presence的词袋模型更好,主题分类用frequency更好;
- unigram/bigrams:bigrams加入并没有带来提升(原因不明)。作者在选取特征时,全语料库中至少出现4次的unigrams和至少出现7次的bigrams抽出来当特征。另外前者给unigrams考虑了否定标签(not, isn't, didn't等)成"NOT_unigram"。
- POS/adjectives/position: 加入它们效果都没提升(原因不明)。POS是Part of Speech词(例如:名词动词这些,可用Oliver Mason's Qtag标注软件进行标注),考虑到形容词对情感分类重要性,作者才加的。此外,由于用户评论电影可能是按照一定顺序,比如总体情感表达->剧情描述->观点总结,所以才加上位置。
- 模型:SVM表现最好。NB模型有对‘特征相互独立’的前提假设,所以使用bigrams效果会变差,SVM和ME不受bigrams影响。
2. Opinion mining and sentiment analysis
年份:2016;关键词:Survey;引用量:10188;推荐指数(1-5):1
描述:该篇文献综述也是由Bo Pang写的,内容多为理论描述,极少给出具体技术上的描述,有助于了解背景但实用性不太高。我就选读了Classification and extraction这一章节。
心得:我就罗列些值得注意的零散知识点如下:
(1)情感评分预测是一个顺序回归任务(即ordinal regression),因为分数为类似0-5的顺序型数据;
(2)中评不一定客观,有可能是评论者避免被卖家报复而打中评。因此评论的主客观分类是个研究点,主观评论更能对情感分类有帮助。有时单次出现的词可能更具主观性。
(3)对情感分类可能有帮助的点:
- 分词位置;
- 更为复杂的特征;
- 歧义词;
- POS:解决词义模糊;
- 形容词:绑定主观性评论;
- 语法:Dependency-tree-based特征可能优于BOW特征;
- 否定标签Negation;
- 讽刺鉴别;
- 加入topic信息:例如:‘目标研究的党派’和‘候选党派’在文本中被替换为'PARTY'和‘OTHER’;
- Domain Adaption:相同词在不同领域可能有不同含义,例如“go read book”在书评和影评中分别为好评和差评;
- Cross-lingual Adaption:使用机器翻译在情感分析预处理中,可以处理跨语种的情感分类。
3. Deep Learning for Sentiment Analysis: A Survey
年份:2018;关键词:Survey;引用量:422;推荐指数(1-5):4
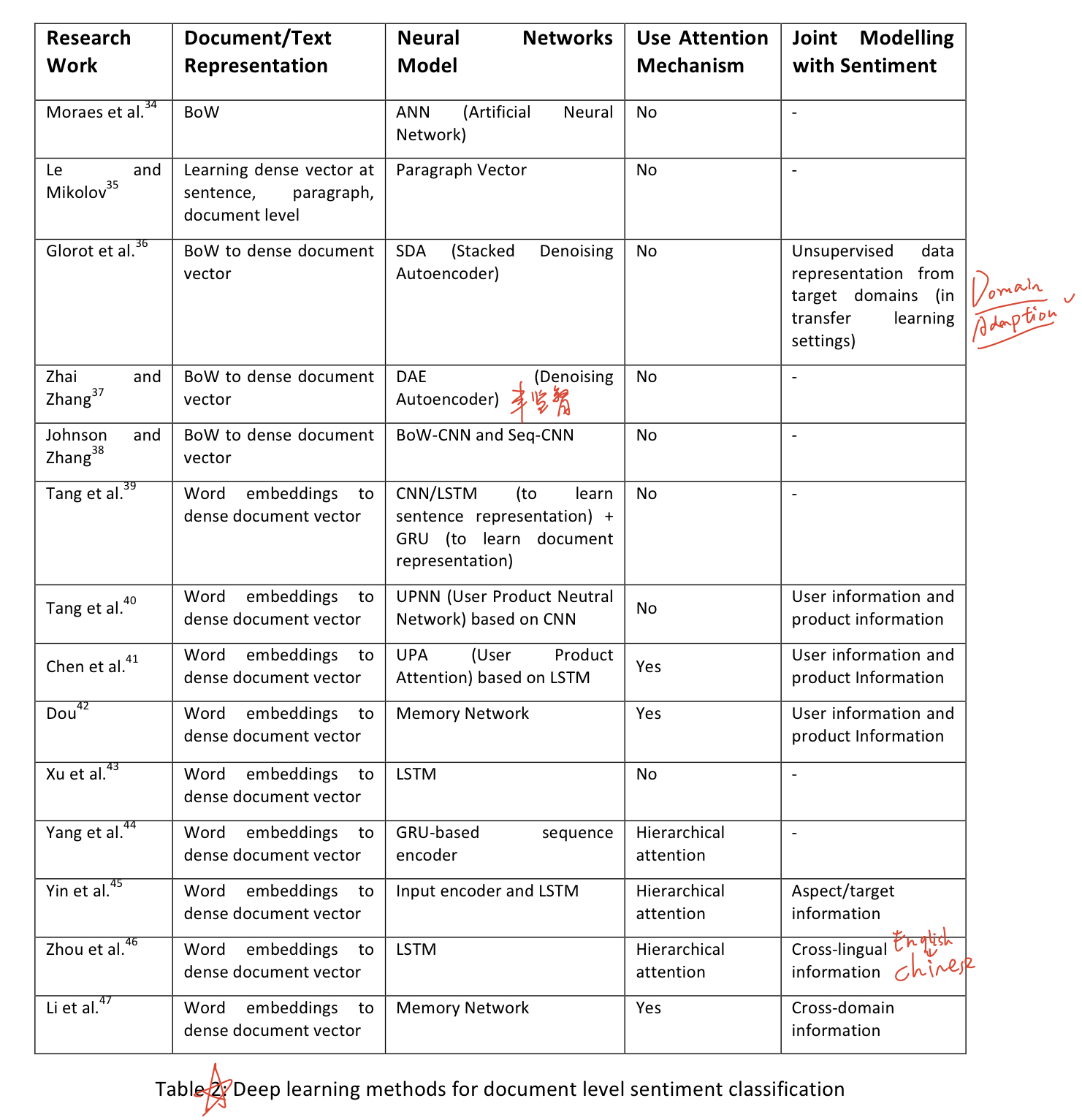
描述:该篇文献综述总结了用深度学习做情感分析的相关研究,大部分都是罗列了各种技术上的研究描述,总体来说是不错的,推荐看下。
心得:情感分析有三种levels:文档级(Document-level)、句子级(Sentence-level)和立场级(Aspect-level)。Document通过客观性分类(subjectivity classification)知道哪些句子客观性强,再对这些句子进行情感极性分析(polarity classification)得到句子的情感极性(积极/消极),而句子能使用立场抽取(Aspect Extraction)和实体抽取(Entity Extraction)分别抽取出立场(例如:“声音质量”)和实体目标(例如:iPhone)进行情感关联。
(1)文本表征:文本表征有三种做法:BoW,embedding和BoW+embedding。但使用BoW有三种缺点:稀疏性、忽略词顺序、没考虑语义信息。而且在文本表征过程中,有些人会考虑引入其他特征,例如商品评论的文本表征中,会考虑加入用户信息(反映用户个人偏好)和商品信息(商品质量)。很早以前会用parse tree做文本表征,但是CNN、RNN和embedding的出现,逐渐取代了它。
(2)立场情感分类的三大重要任务:对目标target的上下文进行表征;生成target的表征;对具体的target识别它重要的情感上下文(words)。
(3)因为文档包含长依赖关系,所以文档级情感分类常用关注机制。
4. Transformers: State-of-the-Art Natural Language Processing
年份:2018;关键词:开源代码库Transformers;引用量:15;推荐指数(1-5):3
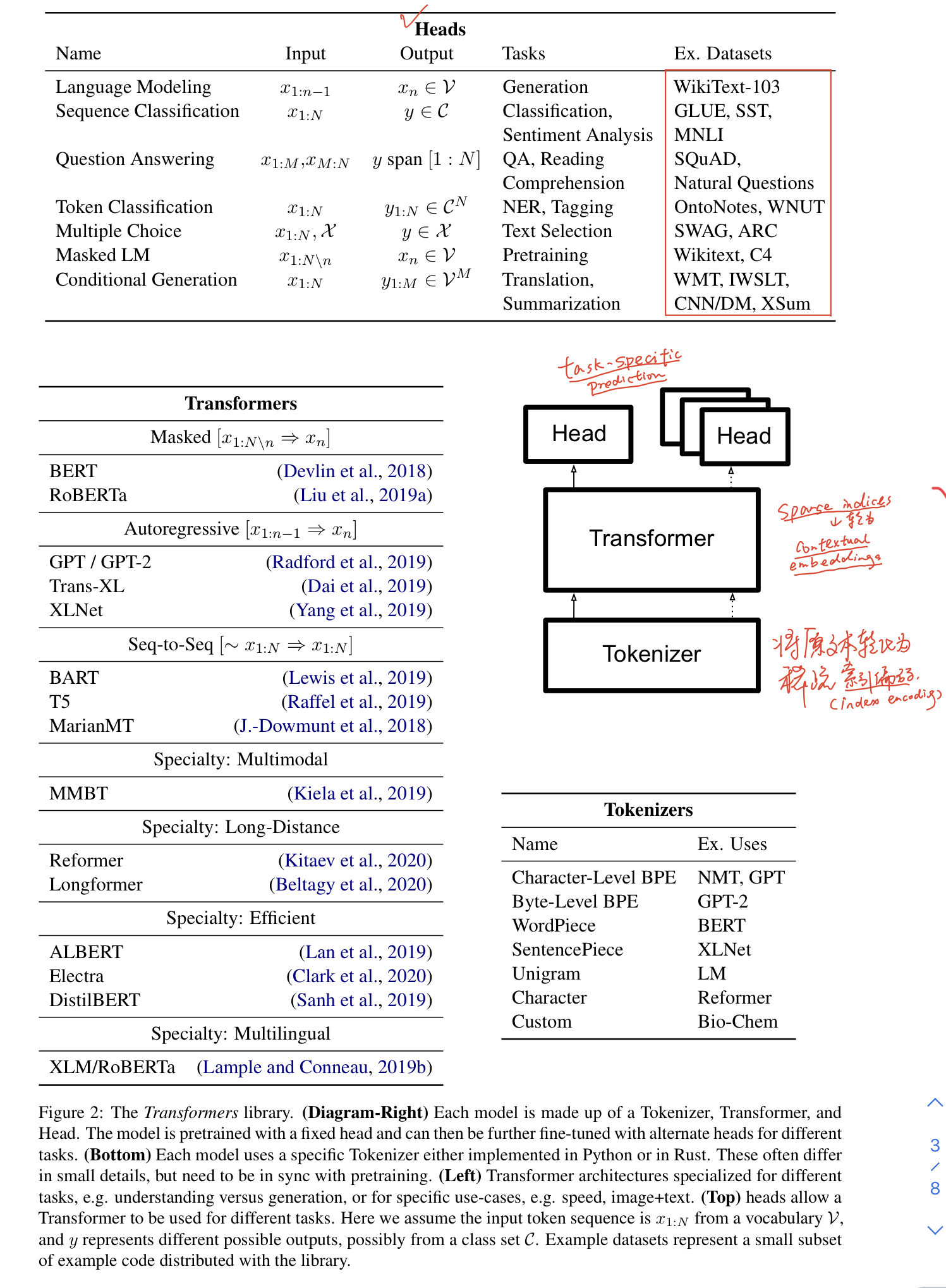
描述:介绍了Transformers库,内含各类基于Transformer的前沿模型和预训练模型权重,可拿来做不同的NLP任务。代码已开源:https://github.com/huggingface/transformers。
心得:很不错的开源代码库,设计的pipeline是:预处理数据、模型应用和预测。主要对应的三个代码模块是:
- tokenizer:将原文本转化为稀疏的索引编码(index encodings);
- transformer:将稀疏索引转化为上下文编码(contextual embeddings);
- head:使用上下文编码做特定任务的预测(task-specific prediction)。
5. RoBERTa: A Robustly Optimized BERT Pretraining Approach
年份:2019;关键词:RoBERTa;引用量:421;推荐指数(1-5):5
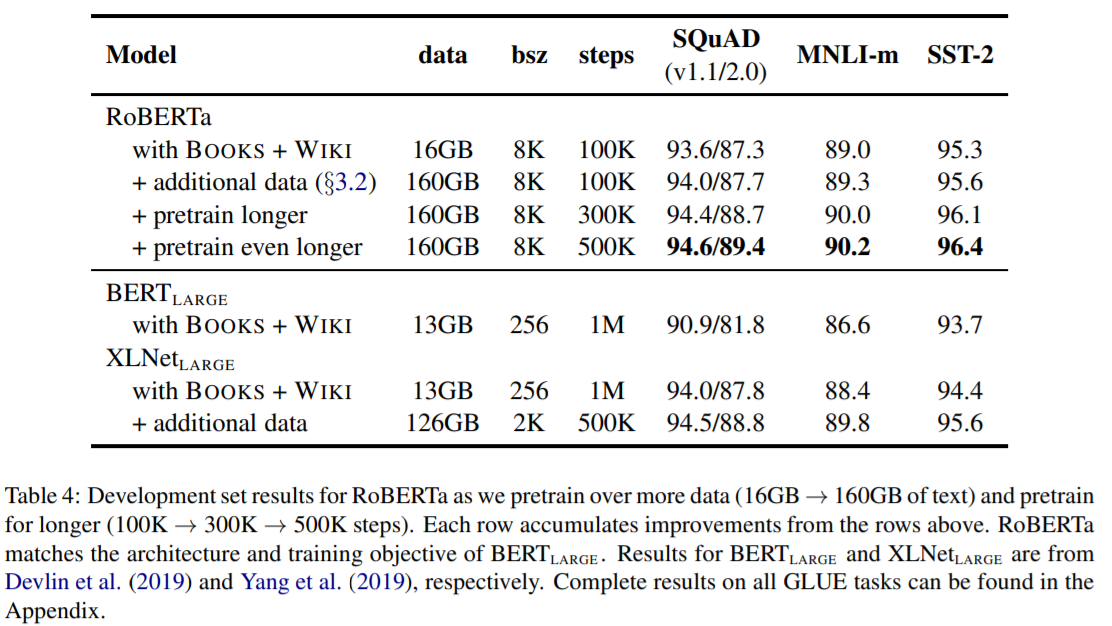
描述:作者对BERT进行预训练优化后使得模型表现提高。优化点有4个:
- 更多数据,训练更久。原BERT使用BOOKCORPUS和English WIKIPEDIA共16G数据训练,而RoBERTa还加入了CC-News,OPENWEBTEXT和STORIES数据集(共计160G数据);此外,通过梯度累计,增大batch size也能提高模型表现。
- 去掉“预测下一句”目标。在BERT预训练时,有两个目标:Masked Language Model(MLM)和Next Sentence Prediction(NSP),NSP是个二分类任务,为了预测是否两个segments片段在原文本里是连续的。该论文作者实验后发现去掉NSP损失会亲为提高下游任务的表现。
- 使用更大的Byte-Pair Encoding(BPE)。BPE是介于字符和单词级别的混合文本表征编码,相比于整个字,它更依赖于subwords单元。
- 采用动态掩码(Dynamic Masking)。原BERT是静态掩码(即在预训练前就进行一次掩码预处理),而动态掩码是每次都想模型输入不同的掩码序列。
心得:RoBERTa现在比较主流的优化预训练BERT的方法了。
6. Pre-Training with Whole Word Masking for Chinese BERT
年份:2019;关键词:WWM;引用量:71;推荐指数(1-5):5
描述:Whole Word Masking(WWM)是BERT一个升级操作。它会将属于一个word的token合并起来。如下图所示:

作者实验发现RoBERT-wwm-ext-large(wwm:Whole Word Masking; ext:extended data; large:网络结构更大,BERT_base是12层,768隐藏层维度,12个关注头,110M的参数量(12×768×12),而BERT_large是24层,1024隐藏层维度,16个关注头,340M的参数量(12*1024*16))表现最好。
心得:作者在最后给了一些建议:
- 起始学习率的设置最重要。BERT和BERT-wwm的学习率近乎相同,可共用。但ERINE(Sun等人提出的Enhanced Representation through kNowledge IntEgration)一定要调lr。
- BERT和BERT-wwm是在维基百科上训练的,所以在正式文本上表现较好。而ERINE有在博客文本上训练,所以在非正式文本上会表现好些。
- 在阅读理解和文本分类上,建议使用BERT/BERT-wwm。
- 做含繁体中文的任务用BERT/BERT-wwm,因为ERINE预处理会清除繁体字。
- 在做新的domain任务前,建议再用新domain数据去预训练下。如果不想再预训练,那就选择相近domain预训练过的模型。
关于情感分类(Sentiment Classification)的文献整理的更多相关文章
- 基于Bert的文本情感分类
详细代码已上传到github: click me Abstract: Sentiment classification is the process of analyzing and reaso ...
- [DeeplearningAI笔记]序列模型2.9情感分类
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.9 Sentiment classification 情感分类 情感分类任务简单来说是看一段文本,然后分辨这个人是否喜欢 ...
- NLP(十九) 双向LSTM情感分类模型
使用IMDB情绪数据来比较CNN和RNN两种方法,预处理与上节相同 from __future__ import print_function import numpy as np import pa ...
- 使用bert进行情感分类
2018年google推出了bert模型,这个模型的性能要远超于以前所使用的模型,总的来说就是很牛.但是训练bert模型是异常昂贵的,对于一般人来说并不需要自己单独训练bert,只需要加载预训练模型, ...
- kaggle之电影评论文本情感分类
电影文本情感分类 Github地址 Kaggle地址 这个任务主要是对电影评论文本进行情感分类,主要分为正面评论和负面评论,所以是一个二分类问题,二分类模型我们可以选取一些常见的模型比如贝叶斯.逻辑回 ...
- PaddlePaddle︱开发文档中学习情感分类(CNN、LSTM、双向LSTM)、语义角色标注
PaddlePaddle出教程啦,教程一部分写的很详细,值得学习. 一期涉及新手入门.识别数字.图像分类.词向量.情感分析.语义角色标注.机器翻译.个性化推荐. 二期会有更多的图像内容. 随便,帮国产 ...
- 基于机器学习和TFIDF的情感分类算法,详解自然语言处理
摘要:这篇文章将详细讲解自然语言处理过程,基于机器学习和TFIDF的情感分类算法,并进行了各种分类算法(SVM.RF.LR.Boosting)对比 本文分享自华为云社区<[Python人工智能] ...
- NLP文本情感分类传统模型+深度学习(demo)
文本情感分类: 文本情感分类(一):传统模型 摘自:http://spaces.ac.cn/index.php/archives/3360/ 测试句子:工信处女干事每月经过下属科室都要亲口交代24口交 ...
- 文本情感分类:分词 OR 不分词(3)
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型.所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特 ...
随机推荐
- RDS 事务型数据库sql
-- 替换json中数据 select SUBSTRING_INDEX(SUBSTRING_INDEX('[{"channelCode":"MOBIL",&qu ...
- python知识点整理一
1.数组元素之和 解法一 from functools import reduce list=[1,3,5,7,9,34] print(reduce(lambda x,y:x+y,list)) 解法二 ...
- HCIA——应用层常用协议
DNS协议 1.什么是DNS协议呢? DNS协议简单来说就是为IP取一个别名的系统(叫域名如www.baidu.com),最终目的是便于我们记忆. 一个域名可能有多个IP,同样一个IP可能也会有多个域 ...
- 我是先学C语言还是先学C++,实不相瞒,鱼和熊掌可兼得!
这是最近一周时间几个读者小伙伴所提的问题,我顺手截了两个图. 实不相瞒,这类问题之前也经常看到. 每次遇到这种问题,看起来很简单,但是打字一时半会还真说不清,想想今天周末了,写一篇文章来统一聊 ...
- 【Azure Redis 缓存 Azure Cache For Redis】在创建高级层Redis(P1)集成虚拟网络(VNET)后,如何测试VNET中资源如何成功访问及配置白名单的效果
当使用Azure Redis高级版时候,为了能更好的保护Redis的安全,启用了虚拟网路,把Redis集成在Azure中的虚拟网络,只能通过虚拟网络VENT中的资源进行访问,而公网是不可以访问的.但是 ...
- Chimm.Excel —— 使用Java 操作 excel 模板文件生成 excel 文档
Chimm.Excel -- 设置模板,填充数据,就完事儿了~ _____ _ _ _____ _ / __ \ | (_) | ___| | | | / \/ |__ _ _ __ ___ _ __ ...
- docker启动redis并设置密码
docker启动redis并设置密码: docker run -d --name redis -p 6379:6379 redis --requirepass "password" ...
- Bitmap缩放(二)
先得到位图宽高不用加载位图,然后按ImageView比例缩放,得到缩放的尺寸进行压缩并加载位图.inSampleSize是缩放多少倍,小于1默认是1,通过调节其inSampleSize参数,比如调节为 ...
- vue响应式原理整理
vue是数据响应性,这是很酷的一个地方.本文只为理清逻辑.详细请看官方文档 https://cn.vuejs.org/v2/guide/reactivity.html vue的data在处理数据时候, ...
- windows.h和WinSock2.h出现重定义API
有两种常用的解决方法:1.把WinSock2.h写在windows.h之前 2.使用宏定义#define WIN32_LEAN_AND_MEAN