时间序列数据的定义,读取与指数平滑(Java)
应上头的要求,需要实现以下指数平滑进行资源调度负载的预测,那就是用我最喜欢的Java做一下吧。
引用《计量经济学导论》的一句话:时间序列数据区别于横截面数据的一个明显特点是,时间序列数据集是按照时间顺序排列的。
显然,横截面数据被视为随机的结果,也就是说在总体中随机抽取样本。时间序列数据和横截面数据区别较为微妙,虽然它也满足随机性,但是这个序列标有时间脚标,依照时间有序,而不可以让时间随机排列导致错乱,我们不能让时间逆转重新开始这个过程。对于这样的序列我们称之为随机过程,或者时间序列过程。
对于时间序列,经常研究的一个问题就是预测,而指数平滑法是非常常见也常用的方法之一。这里对于二次指数平滑进行Java的实现(一次指数平滑包含在二次指数平滑之内)。其原理参照: https://cloud.tencent.com/developer/article/1058557 。这里就不再赘述。
数据也是参照我国1981年至1983年度平板玻璃月产量数据,以下文件保存为data2.txt
我国1981年至1983年度平板玻璃月产量数据
1,240.3
2,222.8
3,243.1
4,222.2
5,222.6
6,218.7
7,234.5
8,248.6
9,261
10,275.3
11,269.4
12,291.2
13,301.9
14,285.5
15,286.6
16,260.5
17,298.5
18,291.8
19,267.3
20,277.9
21,303.5
22,313.3
23,327.6
24,338.3
25,340.37
26,318.51
27,336.85
28,326.64
29,342.9
30,337.53
31,320.09
32,332.17
33,344.01
34,335.79
35,350.67
36,367.37
对于以上数据,时间是int类型,而产量是double类型,为了便于读取,对于以上数据定义行数据类
package timeSeries;
public class RowData {
private int time;
private double value;
public RowData() {
// TODO Auto-generated constructor stub
}
public RowData(int time, double value) {
super();
this.time = time;
this.value = value;
}
public int getTime() {
return time;
}
public void setTime(int time) {
this.time = time;
}
public double getValue() {
return value;
}
public void setValue(double value) {
this.value = value;
}
}
然后定义文件读取类,读取所得数据为RowData数组
package utilFile; import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList; import timeSeries.RowData; public class FileOpts { public static ArrayList<RowData> loadTxt(String dataPath, boolean ishead) {
File file = new File(dataPath);
FileReader fr;
ArrayList<RowData> datas = new ArrayList<RowData>();
try {
fr = new FileReader(file);
BufferedReader br = new BufferedReader(fr);
String line = "";
String[] splitdata;
if (ishead) {
br.readLine();
}
while ((line = br.readLine()) != null) {
splitdata = line.split(",");
datas.add(new RowData(Integer.parseInt(splitdata[0]), Double.parseDouble(splitdata[1])));
}
br.close();
fr.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} return datas;
} }
然后定义时间序列分析类,其实就是一个函数
package timeSeries;
import java.util.ArrayList;
import java.util.Iterator;
public class ExponentialSmoothing2 {
public static double[][] expSmoothOrder2(int[] time, double[] values, double alpha, int preNum) {
int len = time.length;
// 返回一个汇总表
double[][] result = new double[len + preNum][7];
// 第一列时间,第二列实际观察值
for (int i = 0; i < len; i++) {
result[i][0] = time[i];
result[i][1] = values[i];
}
result[0][2] = values[0];
result[0][3] = result[0][2];
// 第三列一次指数平滑值,第四列二次指数平滑值
// S1, S2 2, 3
for (int i = 1; i < len; i++) {
result[i][2] = alpha*values[i] + (1-alpha)*result[i-1][2];
result[i][3] = alpha*result[i][2] + (1-alpha)*result[i-1][3];
}
// 第五列a,第六列b
// a, b 4, 5
for (int i = 1; i < len; i++) {
result[i][4] = 2*result[i][2] - result[i][3];
result[i][5] = alpha/(1-alpha) * (result[i][2] - result[i][3]);
}
// 第七列预测值F
// F 6
for (int i = 1; i < len; i++) {
result[i+preNum][6] = result[i][4] + result[i][5] * preNum;
}
return result;
}
public static void main(String[] args) {
// 获取数据
ArrayList<RowData> data = utilFile.FileOpts.loadTxt("src/timeSeries/data2.txt", true);
int len = data.size();
int[] time = new int[len];
double[] values = new double[len];
Iterator<RowData> it = data.iterator();
int index = 0;
while (it.hasNext()) {
RowData rowData = (RowData) it.next();
time[index] = rowData.getTime();
values[index] = rowData.getValue();
index++;
}
// -------------------数据准备完毕---------------
// System.out.println(Arrays.toString(time));
// System.out.println(Arrays.toString(values));
// ------------------二次指数平滑---------------------
double[][] pre2= expSmoothOrder2(time, values, 0.5, 1);
System.out.printf("%6s, %6s, %6s, %6s, %6s, %6s, %6s\n", "time", "y", "s1", "s2", "a", "b", "F");
for (int i = 0; i < values.length; i++) {
System.out.printf("%6.2f, %6.2f, %6.2f, %6.2f, %6.2f, %6.2f, %6.2f \n", pre2[i][0], pre2[i][1], pre2[i][2],
pre2[i][3], pre2[i][4], pre2[i][5], pre2[i][6]);
}
// System.out.printf("%6d, %6d, %6d, %6d, %6d, %6d, %6.2f \n", 37, 0, 0, 0, 0, 0, pre2[values.length][3]);
// System.out.printf("%6d, %6d, %6d, %6d, %6d, %6d, %6.2f \n", 38, 0, 0, 0, 0, 0, pre2[35][1] + pre2[35][2] * 2);
// 误差分析
double MSE = 0;
double MAPE = 0;
double temp;
// System.out.println("pre2.length = "+pre2.length);
for (int i = 2; i < pre2.length-1; i++) {
MSE += (pre2[i][1]-pre2[i][6])*(pre2[i][1]-pre2[i][6])/(pre2.length-2);
temp = (pre2[i][1]-pre2[i][6])/pre2[i][1];
if (temp < 0) {
MAPE -= temp/(pre2.length-2);
}else {
MAPE += temp/(pre2.length-2);
}
// System.out.printf("iter: %d, y = %6.2f, F = %6.2f, MSE = %6.2f, MAPE = %6.5f\n", i, pre2[i][1], pre2[i][6], MSE, MAPE);
}
System.out.printf("MSE = %6.2f, MAPE = %6.5f\n", MSE, MAPE);
if (MAPE < 0.05) {
System.out.println("百分误差小于0.05,预测精度较高");
}else {
System.out.println("预测误差超过了0.05");
}
}
}
执行结果:
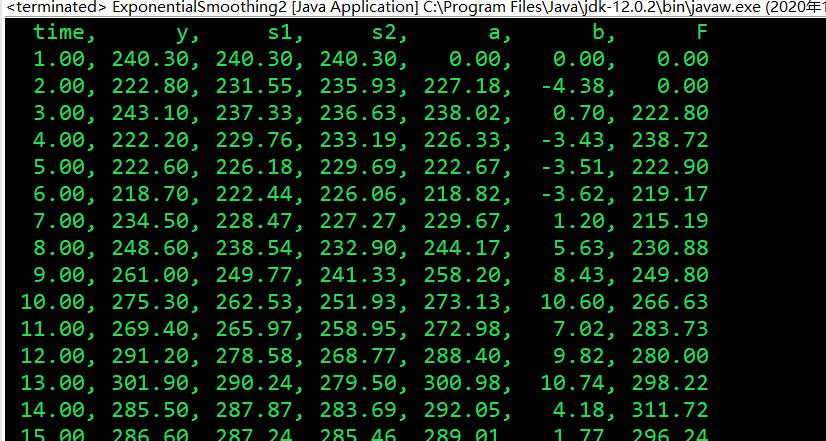
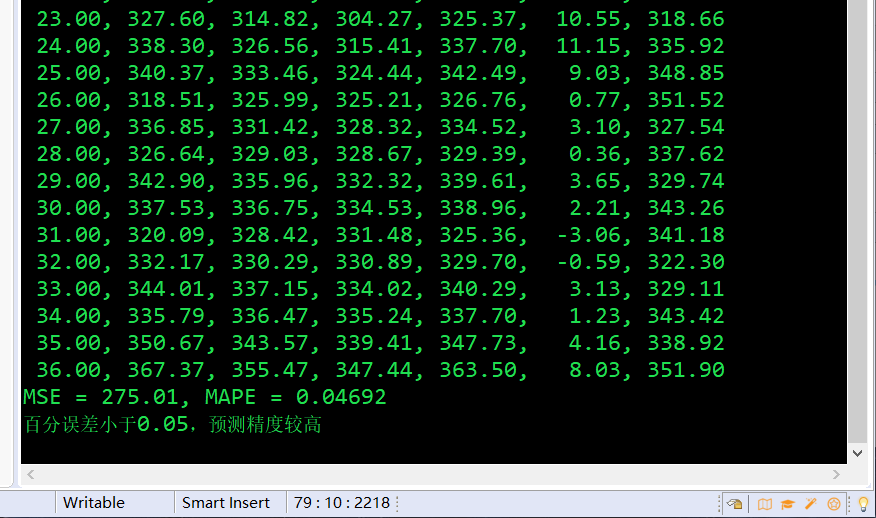
事实上还可以使用Java进行时间序列图像绘制,毕竟Java跑完python或matlab绘图还挺麻烦,Java也是可以实现的,只不过为了方便需要写一个庞大的API,日后闲下来再写一篇博客细说。
时间序列数据的定义,读取与指数平滑(Java)的更多相关文章
- 时间序列挖掘-预测算法-三次指数平滑法(Holt-Winters)——三次指数平滑算法可以很好的保存时间序列数据的趋势和季节性信息
from:http://www.cnblogs.com/kemaswill/archive/2013/04/01/2993583.html 在时间序列中,我们需要基于该时间序列当前已有的数据来预测其在 ...
- Holt Winter 指数平滑模型
1 指数平滑法 移动平均模型在解决时间序列问题上简单有效,但它们的计算比较难,因为不能通过之前的计算结果推算出加权移动平均值.此外,移动平均法不能很好的处理数据集边缘的数据变化,也不能应用于现有数据集 ...
- OpenStack/Gnocchi简介——时间序列数据聚合操作提前计算并存储起来,先算后取的理念
先看下 http://www.cnblogs.com/bonelee/p/6236962.html 这里对于环形数据库的介绍,便于理解归档这个操作! 转自:http://blog.sina.com.c ...
- R语言与数据分析之九:时间内序列--HoltWinters指数平滑法
今天继续就指数平滑法中最复杂的一种时间序列:有增长或者减少趋势而且存在季节性波动的时间序列的预測算法即Holt-Winters和大家分享.这样的序列能够被分解为水平趋势部分.季节波动部分,因此这两个因 ...
- geotrellis使用(二十三)动态加载时间序列数据
目录 前言 实现方法 总结 一.前言 今天要介绍的绝对是华丽的干货.比如我们从互联网上下载到了一系列(每天或者月平均等)的MODIS数据,我们怎么能够对比同一区域不同时间的数据情况,采用 ...
- 使用excel计算指数平滑和移动平均
指数平滑法 原数数据如下: 点击数据——数据分析 选择指数平滑 最一次平滑 由于我们选择的区域是B1:B22,第一个单元格“钢产量”,被当做标志,所以我们应该勾选标志.当我们勾选了标志后,列中的第 ...
- Unity3D学习(二):使用JSON进行对象数据的存储读取
前言 前段时间完成了自己的小游戏Konster的制作,今天重新又看了下代码.原先对关卡解锁数据的存储时用了Unity自带的PlayerPref(字典式存储数据). 读取关卡数据的代码: void Aw ...
- mysql 生成时间序列数据 - 存储过程
由于时间自动转换为int值, 做一步转化,也可在调用时处理 use `test`; CREATE table test.test1 as SELECT state, id, `规格条码`, `色号条码 ...
- C# 结构体和List<T>类型数据转Json数据保存和读取
C# 结构体和List<T>类型数据转Json数据保存和读取 一.结构体转Json public struct FaceLibrary { public string face_name ...
随机推荐
- Tensorflow学习笔记No.3
使用tf.data加载数据 tf.data是tensorflow2.0中加入的数据加载模块,是一个非常便捷的处理数据的模块. 这里简单介绍一些tf.data的使用方法. 1.加载tensorflow中 ...
- 十一、模拟扫码登录微信(用Django简单的布置了下页面)发送接收消息
为了能够模拟登陆QQ,并获取信息.对扫码登录微信进行了分析.简单的用了一下Django将获取的信息映射到页面上.(python3+pycharm) 主要过程就是: 1.获取二维码 2.扫码登录(有三种 ...
- 解决VMware无法共享ubuntu虚拟机文件
1.错误信息:无法更新运行时文件夹共享状态:在客户机操作系统内装载共享文件夹文件系统时出错 2.检查vmware tool是否正确安装 lsmod | grep vmhgfs modprobe vmh ...
- MySQL 8 新特性之Clone Plugin
Clone Plugin是MySQL 8.0.17引入的一个重大特性,为什么要实现这个特性呢?个人感觉,主要还是为Group Replication服务.在Group Replication中,添加一 ...
- xuexi0.2
1.数据结构就是研究数据如何排布和如何加工. 2.数组的目的是为了管理程序中类型相同,意义相关的变量. 3.数组的优势是比较简单,可以通过访问下标来进行随机访问.数组的限制:元素类型必须相同,数组的大 ...
- EfCore3的OwnedType会导致Sql效率问题
最近主导了旗下某核心项目升级到EfCore3 由于之前Core2升级时候也踩过不少的坑很多东西都有规划和准备,整体上还是没出太大问题 但是最近突然发现efcore对于使用了ownedType的生成语句 ...
- VS code开发工具的使用教程
前言 工欲善其事必先利其器,提高程序员的开发效率必须要有一个好的开发工具,当前最好的前端开发工具主要有VS code.sublime Text.Atom.Webstorm.Notepad++. VS ...
- ffmpeg实现视频转gif及gif缩放(ffmpeg4.2.2)
一,为什么选择ffmpeg处理gif? 1,ffmpeg可以从视频中截取gif 2,ffmpeg在缩放gif时出错的机率较低, 而imagemagick在缩放gif时容易出错 我们在后面的例子中可以看 ...
- centos8平台使用journalctl管理systemd-journald日志
一,systemd-journald的作用 1,什么是systemd-journald? systemd-journald 是 systemd 自带的日志系统,是一个收集并存储各类日志数据的系统服务. ...
- PHP SPL标准库-接口
PHP SPL标准库有一下接口: Countable OuterIterator RecursiveIterator SeekableIterator SplObserver SplSubject A ...