Hadoop学习之TextInputFormat分片逻辑探究
期望
顺着上一篇文章《Hadoop学习之第一个MapReduce程序》中遗留的分片疑惑,探究TextInputFormat的分片逻辑。
第一步
上Apache官网下载实验所使用的Hadoop3.2.0版本源码,导入IntelliJ Idea中,不赘述了。下载链接:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.0/hadoop-3.2.0-src.tar.gz
第二步
TextInputFormat
定位到我们疑惑的起端TextInputFormat类,可以看到他的代码非常简单,只有两个方法,且都是重载/实现的父类/接口中的方法,其中有一个与分片有关系,叫isSplitable,他根据一个输入的路径,判断该文件是否可以切分。做法也比较浅显,根据文件后缀名得出其对应的压缩方式,若其压缩编码类实现了SplittableCompressionCodec接口,即认为文件时可切分的。代码如下:
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
FileInputFormat
TextInputFormat中比没有看到最关键的代码,只得接着往他的父类中寻找。打开父类FileInputFormat,看到跟分片有关的方法有如下图所示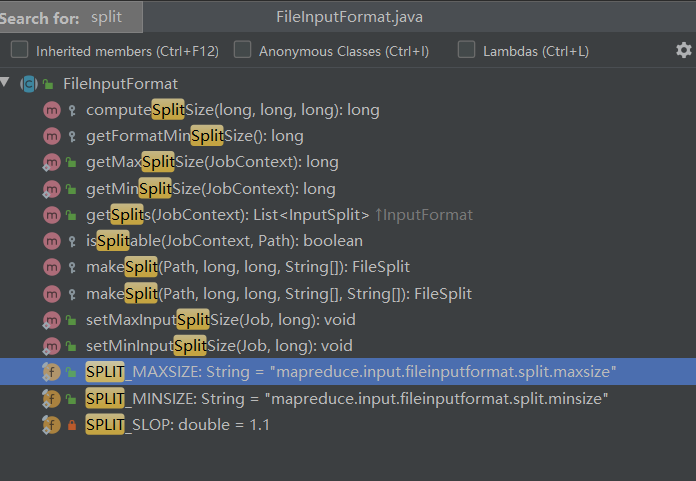
通过方法名、输入输出类型,可以很自然的发现,最接近我们想法的就是 getSplits方法了,返回一个输入分片的集合,我们直接找到该方法,其代码如下:
/**
* Generate the list of files and make them into FileSplits.
* @param job the job context
* @throws IOException
*/
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job); // generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job); boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
for (FileStatus file: files) {
if (ignoreDirs && file.isDirectory()) {
continue;
}
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize); long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
} if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
(emmm,方法注释更加证实了他就是要找的东西!)
研读以上代码,可以发现,分片逻辑的关键在于得到blockSize、splitSize,得到这两个值后,做的事就是循环“切割”文件了,要弄清的关键点有以下几个:
- blockSize是多少?
- splitSize是多少?
- “切割”判断依据
Q1很明了,由于我们的实验环境并未在配置中指定块大小,所以blockSize为默认值128M。
Q2可以看到splitSize由computeSplitSize方法计算得出,为了方便观看,我把computeSplitSize方法及相关的几个值获取的方法放到一起,如下所示:
public static final String SPLIT_MAXSIZE = "mapreduce.input.fileinputformat.split.maxsize";
public static final String SPLIT_MINSIZE = "mapreduce.input.fileinputformat.split.minsize"; public static long getMinSplitSize(JobContext job) {
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
} protected long getFormatMinSplitSize() {
return 1;
} public static long getMaxSplitSize(JobContext context) {
return context.getConfiguration().getLong(SPLIT_MAXSIZE,
Long.MAX_VALUE);
} protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
由于我并未配置mapreduce.input.fileinputformat.split.maxsize和mapreduce.input.fileinputformat.split.minsize,Configuration中他俩的值即为默认值空和0,所以getMinSplitSize值为1,getMaxSplitSize值为Long.MAX_VALUE,故
splitSize=Math.max(minSize, Math.min(maxSize, blockSize))
=Math.max(, Math.min(Long.MAX_VALUE, * * ))
=Math.max(, * * )
= * *
=blockSize
Q3 “切割”依据即getSplits方法中的循环判断 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) ,可知常量SPLIT_SLOP值为1.1。
结论
综上所述,TextInputFormat的分片逻辑为:
将文件按块切割,直到文件剩余大小 小于等于 块大小的1.1倍时,将剩余部分(理论上时2个块的数据)作为一个输入分片。
回过头来看《Hadoop学习之第一个MapReduce程序》中的分片问题,文件数为44、块数为61,但是分片数为58,就是因为有三个文件的分块有“小尾巴”,这三个小于等于1.1倍块大小的块与对应文件的上一个块共同组成了一个输入分片。
Hadoop学习之TextInputFormat分片逻辑探究的更多相关文章
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
- shuffle机制和TextInputFormat分片和读取分片数据(九)
shuffle机制 1:每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线 ...
- Hadoop学习之常用输入输出格式总结
目的 总结一下常用的输入输出格式. 输入格式 Hadoop可以处理很多不同种类的输入格式,从一般的文本文件到数据库. 开局一张UML类图,涵盖常用InputFormat类的继承关系与各自的重要方法(已 ...
- [Hadoop] Hadoop学习历程 [持续更新中…]
1. Hadoop FS Shell Hadoop之所以可以实现分布式计算,主要的原因之一是因为其背后的分布式文件系统(HDFS).所以,对于Hadoop的文件操作需要有一套全新的shell指令来完成 ...
- Hadoop学习(5)-- Hadoop2
在Hadoop1(版本<=0.22)中,由于NameNode和JobTracker存在单点中,这制约了hadoop的发展,当集群规模超过2000台时,NameNode和JobTracker已经不 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 【Hadoop学习之四】HDFS HA搭建(QJM)
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 由于NameNode对于整个HDF ...
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
随机推荐
- OldTrafford after 102 days
THE RED GO MARCHING ON One Team One Love Through the highs and the lows One hundred and two long ...
- JAVA基础笔记10-11-12-13-14
十.今日内容介绍 1.继承 2.抽象类 3.综合案例---员工类系列定义 01继承的概述 *A:继承的概念 *a:继承描述的是事物之间的所属关系,通过继承可以使多种事物之间形成一种关系体系 *b:在J ...
- SpringBoot + Vue + ElementUI 实现后台管理系统模板 -- 后端篇(一): 搭建基本环境、整合 Swagger、MyBatisPlus、JSR303 以及国际化操作
相关 (1) 相关博文地址: SpringBoot + Vue + ElementUI 实现后台管理系统模板 -- 前端篇(一):搭建基本环境:https://www.cnblogs.com/l-y- ...
- day59 pip安装django出错解决方案
在虚拟环境下,输入 pipinstall django ==2.2,安装django,可能会出现超时问题 这里的报错是网络问题,解决方案有如下三种 (1)多试几次,网络好就装上了 (2)Cmd输入 ...
- Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- Quartz.Net系列(十四):详解Job中两大特性(DisallowConcurrentExecution、PersistJobDataAfterExecution)
1.DisallowConcurrentExceution 从字面意思来看也就是不允许并发执行 简单的演示一下 [DisallowConcurrentExecution] public class T ...
- 一文读懂Java中的动态代理
从代理模式说起 回顾前文: 设计模式系列之代理模式(Proxy Pattern) 要读懂动态代理,应从代理模式说起.而实现代理模式,常见有下面两种实现: (1) 代理类关联目标对象,实现目标对象实现的 ...
- SSRF漏洞简单分析
什么是SSRF漏洞 SSRF(服务器端请求伪造)是一种由攻击者构造请求,服务器端发起请求的安全漏洞,所以,一般情况下,SSRF攻击的目标是外网无法访问的内部系统. SSRF漏洞形成原理. SSRF的形 ...
- JSON.stringify和JSON.parse的用法
用法概述 所有的现代浏览器都支持 JSON 对象,有两个非常有用的方法来处理 JSON 格式的内容: JSON.parse(string) 接受一个 JSON 字符串并将其转换成一个 JavaScri ...
- LeetCode 85 | 如何从矩阵当中找到数字围成的最大矩形的面积?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode专题53篇文章,我们一起来看看LeetCode中的85题,Maximal Rectangle(最大面积矩形). 今天的 ...