推荐系统---深度兴趣网络DIN&DIEN
深度学习在推荐系统、CTR预估领域已经有了广泛应用,如wide&deep、deepFM模型等,今天介绍一下由阿里算法团队提出的深度兴趣网络DIN和DIEN两种模型
paper
DIN:https://arxiv.org/abs/1706.06978
DIEN:https://arxiv.org/abs/1809.03672
code
DIN:https://github.com/zhougr1993/DeepInterestNetwork
DIEN:https://github.com/mouna99/dien
DIN
常见的深度学习网络用于推荐或者CTR预估的模式如下:
Sparse Features -> Embedding Vector -> MLPs -> Sigmoid -> Output.
这种方法主要通过DNN网络抽取特征的高阶特征,减少人工特征组合,如wide&deep、deepFM的DNN部分均是采用这种模式,然而阿里的小组经过研究认为还有以下两种特性在线上数据中十分重要的,而当前的模型无法去挖掘
Diversity:用户在浏览电商网站的兴趣多样性。
Local activation: 由于用户兴趣的多样性,只有部分历史数据会影响到当次推荐的物品是否被点击,而不是所有的历史记录。
为了充分挖掘这些特性,联系到attention机制在nlp等领域的大获成功,阿里团队将attention机制引入推荐系统,在向量进入MLP之前先通过attention机制计算用户行为权重,让每个用户预测关注的兴趣点(行为向量)不同。
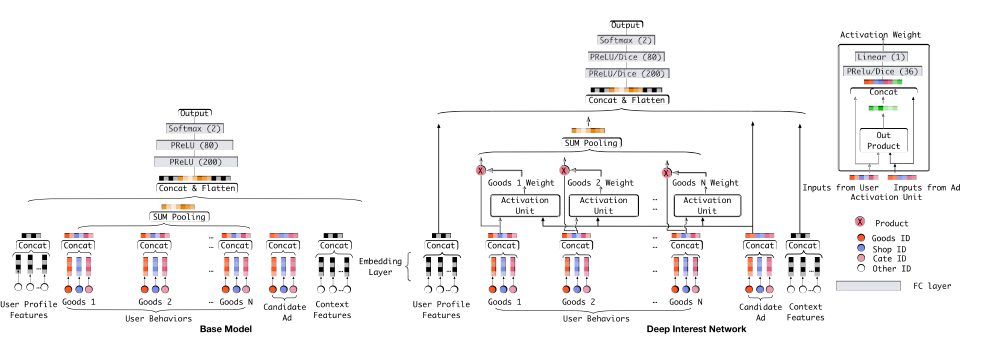
网络基本结构如上图,Base Model有一个很大的问题,它对用户的历史行为是同等对待的,没有做任何处理,这显然是不合理的。一个很显然的例子,离现在越近的行为,越能反映你当前的兴趣。因此,DIN模型对用户历史行为基于Attention机制进行一个加权
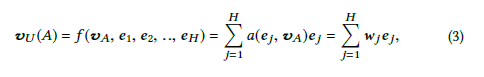

···
def din_fcn_attention(query, facts, attention_size, mask, stag='null', mode='SUM', softmax_stag=1, time_major=False, return_alphas=False, forCnn=False):
if isinstance(facts, tuple):
# In case of Bi-RNN, concatenate the forward and the backward RNN outputs.
facts = tf.concat(facts, 2)
if len(facts.get_shape().as_list()) == 2:
facts = tf.expand_dims(facts, 1)
if time_major:
# (T,B,D) => (B,T,D)
facts = tf.array_ops.transpose(facts, [1, 0, 2])
mask = tf.equal(mask,tf.ones_like(mask))
facts_size = facts.get_shape().as_list()[-1] # Hidden size for rnn layer
query = tf.layers.dense(query,facts_size,activation=None,name='f1'+stag)
query = prelu(query)
queries = tf.tile(query,[1,tf.shape(facts)[1]]) # Batch * Time * Hidden size
queries = tf.reshape(queries,tf.shape(facts))
din_all = tf.concat([queries,facts,queries-facts,queries*facts],axis=-1) # Batch * Time * (4 * Hidden size)
d_layer_1_all = tf.layers.dense(din_all, 80, activation=tf.nn.sigmoid, name='f1_att' + stag)
d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=tf.nn.sigmoid, name='f2_att' + stag)
d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att' + stag) # Batch * Time * 1
d_layer_3_all = tf.reshape(d_layer_3_all,[-1,1,tf.shape(facts)[1]]) # Batch * 1 * time
scores = d_layer_3_all
key_masks = tf.expand_dims(mask,1) # Batch * 1 * Time
paddings = tf.ones_like(scores) * (-2 ** 32 + 1)
if not forCnn:
scores = tf.where(key_masks, scores, paddings) # [B, 1, T] ,没有的地方用paddings填充
# Activation
if softmax_stag:
scores = tf.nn.softmax(scores) # [B, 1, T]
# Weighted sum
if mode == 'SUM':
output = tf.matmul(scores,facts) # Batch * 1 * Hidden Size
else:
scores = tf.reshape(scores,[-1,tf.shape(facts)[1]]) # Batch * Time
output = facts * tf.expand_dims(scores,-1) # Batch * Time * Hidden Size
output = tf.reshape(output,tf.shape(facts))
if return_alphas:
return output,scores
else:
return output
···
以上是其中attention的核心代码
DIEN
在用DIN解决了用户的兴趣不同的问题后,模型还存在以下问题
1)用户的兴趣是不断进化的,而DIN抽取的用户兴趣之间是独立无关联的,没有捕获到兴趣的动态进化性
2)通过用户的显式的行为来表达用户隐含的兴趣,这一准确性无法得到保证。
为了解决以上两个问题,阿里算法又提出了DIEN模型
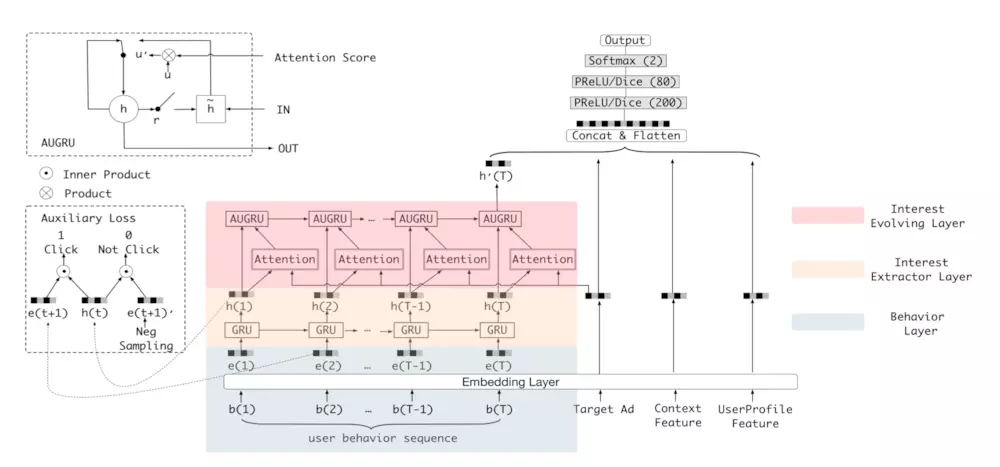
对比DIN的结构,主要区别在于增加了兴趣抽取层和兴趣进化层(RNN)
作者将用户行为表示为序列,利用GRU来抽取兴趣状态

在此之后,为了进一步保证兴趣抽取的准确,作者设计了一个二分类网络,用下一刻的真实行为加GRU的状态拼接作为正例,抽取的假行为拼接GRU状态作为负例,输入二分类网络
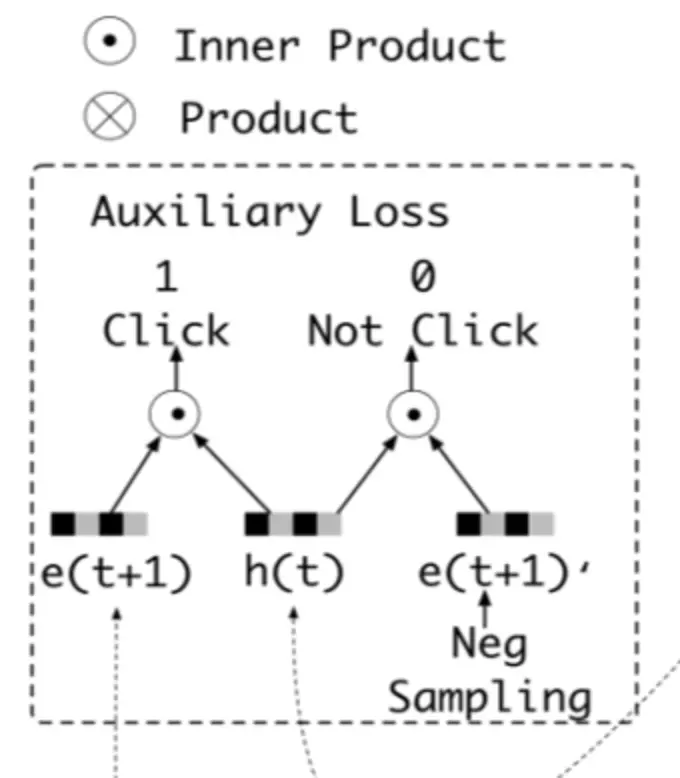
同时设计损失函数
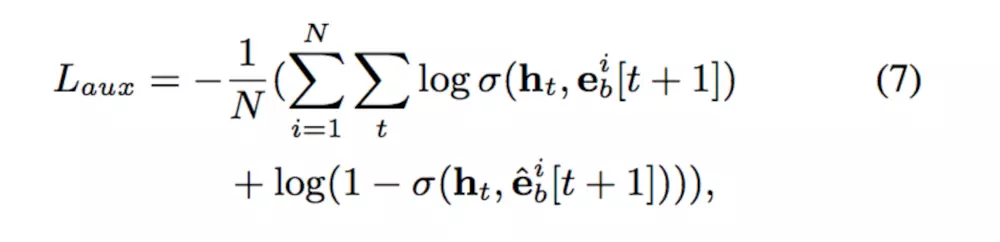
然后,抽取完兴趣的状态送入兴趣进化网络,为了让用户兴趣也能追着时间变化,采用RNN设计,同时继承与DIN的attention机制,结合后采用了GRU with attentional update gate (AUGRU)的方法,修改了GRU的结构
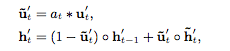
此处有多种GRU结合attention的方法。
最终DIEN的实验结果表现很好
推荐系统---深度兴趣网络DIN&DIEN的更多相关文章
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
- [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构
[阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 目录 [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x0 ...
- [阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列
[阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列 目录 [阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列 0x00 摘要 0x01 DIN 需要什么数据 0x02 如何产生数据 2 ...
- 推荐系统中的注意力机制——阿里深度兴趣网络(DIN)
参考: https://zhuanlan.zhihu.com/p/51623339 https://arxiv.org/abs/1706.06978 注意力机制顾名思义,就是模型在预测的时候,对用户不 ...
- 深度兴趣网络DIN-SIEN-DSIN
看看阿里如何在淘宝做推荐,实现"一人千物千面"的用户多样化兴趣推荐,首先总结下DIN.DIEN.DSIN: 传统深度学习在推荐就是稀疏到embedding编码,变成稠密向量,喂给N ...
- 阿里深度兴趣网络模型paper学习
论文地址:Deep Interest Network for Click-Through Rate ... 这篇论文来自阿里妈妈的精准定向检索及基础算法团队.文章提出的Deep Interest Ne ...
- [论文阅读]阿里DIEN深度兴趣进化网络之总体解读
[论文阅读]阿里DIEN深度兴趣进化网络之总体解读 目录 [论文阅读]阿里DIEN深度兴趣进化网络之总体解读 0x00 摘要 0x01论文概要 1.1 文章信息 1.2 基本观点 1.2.1 DIN的 ...
- [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本
[阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 目录 [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 0x00 摘要 0x01 背景 1.1 代码进化 1.2 Deep ...
- Spark MLlib Deep Learning Deep Belief Network (深度学习-深度信念网络)2.3
Spark MLlib Deep Learning Deep Belief Network (深度学习-深度信念网络)2.3 http://blog.csdn.net/sunbow0 第二章Deep ...
随机推荐
- windows10 + docker利用文件映射进行编程开发
0. 以安装swoole框架"easyswoole"举例,建议使用powershell或者cmder输入命令 1. 首先准备好window10专业版开启Hyper-V,然后下载 ...
- Java知识系统回顾整理01基础04操作符02关系操作符
一.关系操作符 关系操作符:比较两个变量之间的关系 > 大于 >= 大于或等于 < 小于 <= 小于或等于 == 是否相等 != 是否不等 public class Hell ...
- 使用 .NET 进行游戏开发
微软是一家综合性的网络公司,相信这点来说不用过多的赘述,没有人不知道微软这个公司,这些年因为游戏市场的回报,微软收购了很多的游戏公司还有独立工作室,MC我的世界就是最成功的的案例,现在市值是排在全世界 ...
- VUE 安装项目
注意:在cmd中执行的命令 1,前提是安装了node.js 查看 npm 版本号 2,创建项目路径 mkdir vue cd vue 3,安装vue-cli (脚手架) npm install -个v ...
- JAVA基础 随机点名器案例
1.1 案例介绍 随机点名器,即在全班同学中随机的找出一名同学,打印这名同学的个人信息. 此案例在我们昨天课程学习中,已经介绍,现在我们要做的是对原有的案例进行升级,使用新的技术来实现. 我 ...
- go-zero 如何应对海量定时/延迟任务?
一个系统中存在着大量的调度任务,同时调度任务存在时间的滞后性,而大量的调度任务如果每一个都使用自己的调度器来管理任务的生命周期的话,浪费cpu的资源而且很低效. 本文来介绍 go-zero 中 延迟操 ...
- php查看进程
index.php <?php /** * Created by PhpStorm. * User: mac * Date: 2020/4/23 * Time: 21:57 */ echo ...
- xpath取末尾
from lxml import etree html = ''' <!DOCTYPE html> <html lang="en"> <head> ...
- Linux运维学习第四周记
古木阴中系短篷 杖藜扶我过桥东 沾衣欲湿杏花雨 吹面不寒杨柳风 *不要辜负绵绵春意 第四周学记 第四周主要学习了文件查找和打包压缩的相关工具,以及软件包管理工具 文件查找相关命令 1.locate 在 ...
- CUDA和cuDNN的安装
CUDA软件 Windows 打开NVIDIA CUDA网站,选择需要下载的版本,依次选择Windows平台,x86_64架构,10系统,exe(local)本地安装包,再选择Download即可下载 ...