华为云FusionInsight湖仓一体解决方案的前世今生
摘要:华为云发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念,那我们就来看看湖仓一体的来世今生。
伴随5G、大数据、AI、IoT的飞速发展,数据呈现大规模、多样性的极速增长,为了应对多变的业务诉求,政企客户对数据处理分析的实时性和融合性提出了更高的要求,“湖仓一体”的概念应运而生,它打破数据湖与数仓间的壁垒,使得割裂数据融合统一,减少数据分析中的搬迁,实现统一的数据管理。
早在2020年5月份的华为全球分析师大会上,华为云CTO张宇昕提出了“湖仓一体”概念,在随后的华为云与计算城市峰会上,“湖仓一体”理念跟随华为云FusionInsight智能数据湖在南京、深圳、西安、重庆等地均有呈现,在刚结束的HC2020上,张宇昕在发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念。那我们就来看看湖仓一体的来世今生。
数据湖和数据仓库的发展历程和挑战
早在1990年,比尔·恩门(Bill Inmon)提出了数据仓库,主要是将组织内信息系统联机事务处理(OLTP)常年累积的大量资料,按数据仓库特有的资料储存架构进行联机分析处理(OLAP)、数据挖掘(Data Mining)等分析,帮助决策者快速有效地从大量资料中分析出有价值的资讯,以利决策制定及快速响应外在环境变化,帮助构建商业智能(BI)。
大约十年前,企业开始构建数据湖来应对大数据时代,它通常把所有的企业数据统一存储,既包括源系统中的原始副本,也包括转换后的数据,比如那些用于报表, 可视化, 数据分析和机器学习的数据。
纵观数据湖与数据仓库的技术发展,不难发现两者有着各自的优劣,具体表现如下:
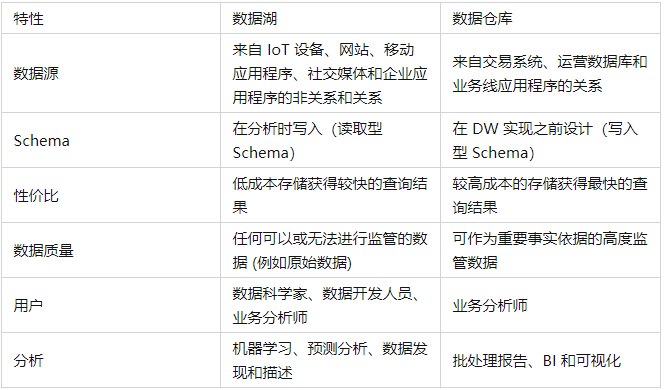
表1 湖仓对比, 各有千秋
企业在进行系统架构设计选型时,需要从具体的分析场景出发,单一的模式已经无法满足企业发展的业务诉求,集中表现在以下两个痛点:
- 数据湖主要以离线批量计算为主,因为不支持数据仓库的数据管理能力,难以提高数据质量;数据入湖时效差不支持实时更新,数据无法强一致性;主题建模不友好,无法直接历史拉链建模;同时交互分析通常将数据搬迁到数据仓库平台,造成分析链路长,数据冗余存储;批&流等场景融合不够,无法满足企业的海量数据处理诉求。
- 数据仓库满足不了非结构化数据的分析需求,性价比不高;同时仓&湖间难以互联互通,数据协同效率较低,无法支持跨平台透明访问,形成了事实上的数据孤岛,找数困难;缺乏全局数据视图,不同平台接口差异和不同开发管理工具,造成用户开发使用复杂,数据分别管理维护代价高体验差。
数据湖和数据仓库正在从两条技术演进路线走向融合
综上,数据湖和数据仓库在企业数据分析场景分别承担一湖一仓的重要角色,形成了完整的数据分析生态系统,上述企业场景面临的2个关键痛点也在驱动数据湖和数据仓库在技术演进上走向融合:
第一个融合方向是基于Hadoop体系的数据湖向数据仓库能力扩展,湖中建仓,从DataLake进化到LakeHouse。LakeHouse结合了数据湖和数据仓库特点,直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能。目前业界已经涌现了一些LakeHouse产品,如NexFlix开源Iceberg、Uber开源Hudi、Databricks的 DeltaLake。
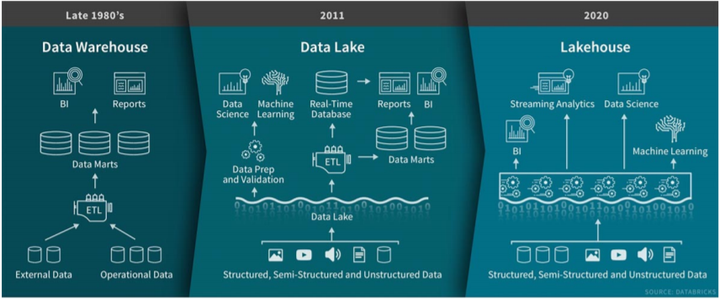
图2从DataLake进化到LakeHouse,数据湖扩展数仓能力
以目前生态发展迅速的Apache Hudi为例:统一数据存储,分布式存储不同应用所需的各种类型数据;数仓模式执行和治理,实现事务&更新机制,保证数据完整性和一致性,具有健壮的治理&审计机制;支持各种分析引擎,统一数据存储通过开放和标准化的存储格式(如Parquet),提供API以便各类工具和引擎(包括机器学习和Python / R库)直接有效地访问数据。
虽然LakeHouse并不能完全替代数据仓库,但通过增强性能,支持实时入湖、建模、交互分析等场景,将在企业分析环境中发挥更大作用。
第二个融合方向是数据湖和数据仓库协同起来向湖仓一体的融合分析架构发展,随着企业数据量快速增长,不仅是结构化数据,也有非结构化数据,同时提出了对搜索/机器学习更多的能力要求,使得原来数仓技术不能够有效的处理复杂场景,为此需扩展原有系统,引入Hadoop大数据平台实现新类型数据、新业务场景的支持。在这个背景下由Gartner在2011年提出逻辑数据仓库的概念,预测企业数据分析倾向于转向一种更加逻辑化的架构,利用分布式处理、数据虚拟化以及元数据管理等技术,实现逻辑统一物理分开的协同体系。
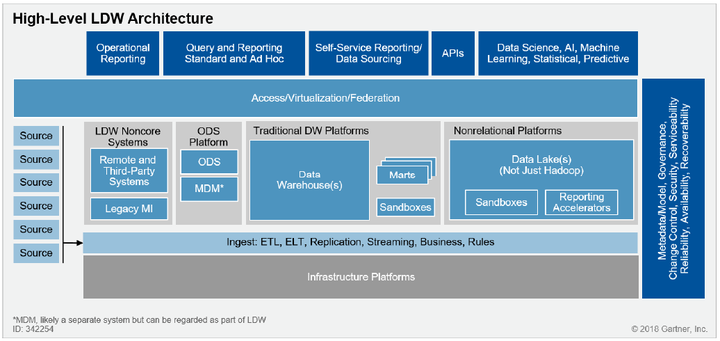
图2 逻辑数仓的高阶架构
湖仓一体可以认为是逻辑数据仓库架构理念下针对Hadoop数据湖和MPPDB数据仓库的融合架构的最好诠释,数据对用户将完全实现虚拟化,以逻辑统一的数据分析系统为企业提供数据分析服务:
用户使用层面提供统一元数据管理和数据视图,实现全局数据可见可查,支持标准统一访问接口简化用户开发,提供统一开发和治理的工具体系。
平台层面Hadoop与MPPDB具备数据共享和跨库分析能力,支持互联互通、计算下推、协同计算,实现数据多平台之间透明流动。
华为云FusionInsight湖仓一体解决方案参考架构
华为云FusionInsight智能数据湖涵盖了分布式存储、大数据、数据仓库、数据治理等,融合了上述两个技术演进方向,为企业用户提供云原生湖仓一体解决方案,整体的参考架构如下:
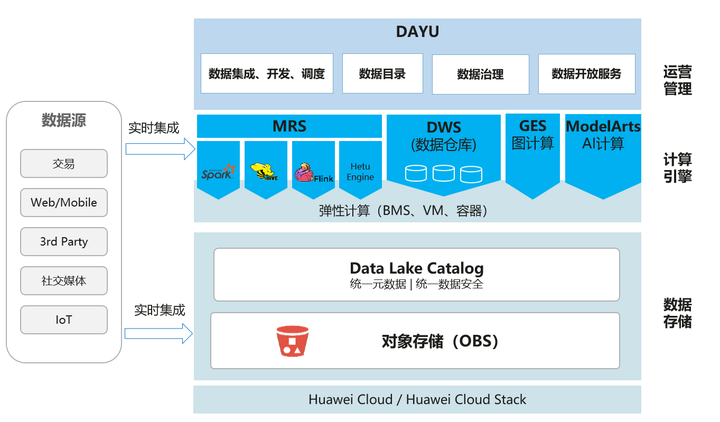
图4 华为云FusionInsight湖仓一体解决方案参考架构
下面一起来看看:
数据存储层:通过OBS统一管理湖&仓的存储底座,将存储在EC(Erasure Code纠错码)、可靠性方面的优势融入进了大数据生态:
- 云原生架构领先:基于云原生架构的OBS存储,具有高带宽,大并发,分布式元数据等特征,因此相同成本的华为存算分离的湖仓一体化集群,数据读写性能领先业界30%。
- 存储计算分离有效降低TCO:支持大比例EC, 副本数从3最低可降低至1.09,TCO下降20%+。
- 统一元数据管理实现湖仓共享存储资源池:通过独立的Data Lake Catalog提供统一元数据管理,兼容Hive Metastore接口,可以无缝对接各类大数据组件。实现针对同一份元数据定义支持各类场景、对象、文件、大数据等不同协议间的数据共享,让数据仓库、数据湖、图引擎、AI等多种计算引擎共享统一的数据存储池。此方案不仅消除了孤立系统中的数据副本,还使得客户可以按照业务按需使用计算存储资源,不仅降低了CAPEX,还简化了运维,从而达成最佳TCO。同时,Data Lake Catalog开放接口,支持和第三方的计算引擎层、数据治理层对接。
计算引擎层:把事务能力引入数据湖,通过HetuEngine标准SQL实现跨域多源统一访问,湖&仓数据互通协同计算,数据免搬迁:
- CarbonData & Hudi数据实时入湖,实现数据湖事务能力:企业内部许多数据管道通常会并发读写数据,我们通过CarbonData& Hudi数据存储引擎实现数据实时、增量更新,数据T+0实时入湖,大幅缩短传统T+1、T+2时延;引入的增量处理框架,实现了数据湖事务能力,支持入湖过程中的Update/Delete等。
- HetuEngine支持跨源跨域统一SQL访问,简单易用:用户层基于统一的标准SQL接口,对接多个数据源(HDFS, HBase, DWS等),提供秒级交互式访问,满足各种统计分析、多表Join关联等,让分析建模人员数据分析更容易,降低访问门槛。
- HetuEngine & DWS-Express打破数据墙,数据免搬迁创新更敏捷:支持数据湖与数据仓库间的数据互联互通、跨平台协同计算,数据免搬迁。HetuEngine在湖内基于统一数据目录,实现高并发,高性能的交互式查询,基于一份数据进行批、流、交互式融合分析,贴源加工、整合关联、主题加工等都在湖内,数据不出湖,分析链路短,加速业务创新;用户可使用DWS-Express提供由成百上千节点组成的加速集群,对存储在OBS上的海量数据进行在线分析,相比本地托管集群,效率提升数百倍。
- 自研Superior调度器支持单集群2万+节点规模,业界最佳:在一个集群内,通过华为自研的Superior调度器支持各种工作负载统一调度,包括数据科学、机器学习以及SQL和分析,调度速率达35万Container/s,资源利用率达90%+,大幅降低企业投入成本。
- 数据冷热分级存储实现更高效的全生命周期管理:DWS具备与OBS的双向互通的能力,既能直接读取OBS上的海量历史数据,也能够直接写入数据到OBS。通过这个特性,我们可以对企业中的海量数据进行更加高效的全生命周期管理,分析中经常使用到的热/温数据存放在DWS中,较少使用的冷数据存放到OBS中,兼顾企业对分析性能和存储经济性的诉求。
- 无缝衔接AI挖掘更多数据价值:深度优化一站式开发平台ModelArts&分布式图计算引擎GES提高开发效率。提供基于数据湖的AI训练推理能力,减少数据搬迁次数,基于100+机器学习算子和NLP算法,实现海量数据快速价值挖掘,满足场景预测、自然语言处理及企业知识图谱等应用; 让GES更快捷地为金融等场景提供关系网络分析等服务。
运营管理层:通过DAYU实现了湖&仓统一的数据集成、开发、目录、治理、开放服务等的运营管理:
- 数据集成:实现多源异构数据高效入湖,支持批/流/实时数据多种方式接入。其中,批量数据迁移基于分布式计算框架,利用并行化处理技术,支持用户稳定高效地对海量数据进行移动,实现不停服数据迁移,快速构建所需的数据架构;流和实时数据接入每小时可从数十万种数据源(例如日志和定位追踪事件、网站点击流、社交媒体源等)中连续捕获、传送和存储数TB数据。
- 数据开发:提供一站式敏捷数据开发平台,提供可视化的图形开发界面、丰富的数据开发类型(脚本开发和作业开发)、全托管的作业调度和运维监控能力,内置行业数据处理pipeline,一键式开发,全流程可视化,支持多人在线协同开发,支持管理多种大数据云服务,极大地降低了用户使用大数据的门槛,帮助用户快速构建数据湖数据处理中心。
- 数据治理:为企业提供数据体系标准和数据规范定义的方法论,统一数据语言和数据建模;为普通业务人员提供高效、准确的数据搜索工具,高效找到数据;提供技术元数据与业务元数据的关联,业务人员快速读懂数据;为数据提供有效的质量管控和评估手段,数据可信质量高。
- 数据开放:为数据湖搭建统一的数据服务总线,帮助企业统一管理对内对外的API服务,支撑业务主题/画像/指标的访问、查询和检索,提升数据消费体验和效率;支持100+开放API,拥有10+行业模板,使能行业ISV快速集成,助力客户数据标准资产沉淀。
综上所述,正是在三层架构都打通了湖仓的技术壁垒,我们才看到了真正的湖仓一体:
数据存储层基于云原生领先架构,存算分离有效降低TCO,统一元数据管理实现湖仓共享存储资源池,针对同一份元数据定义支持各种场景,提供API方便各类工具和引擎(包括机器学习、Python、R等)直接有效地访问数据,这是实现湖仓一体的一个关键点;
计算引擎层为数据湖增加了事务能力提升了数据质量;利用HetuEngine通过标准SQL访问跨域多源数据,实现湖&仓数据关联分析协同计算,简单易用; 打破数据墙,在湖内基于统一数据目录,可基于数据湖实现融合分析&AI训练推理,减少数据搬迁,实现海量数据快速价值挖掘。
运营管理层则提供统一的数据开发和治理环境,具备安全管理功能,支持多引擎任务统一开发和编排,数据统一建模和质量监测,实现湖仓一致的开发治理体验。
未来展望
华为云FusionInsight智能数据湖基于客户需求和技术演进趋势持续创新,为企业客户提供湖仓一体解决方案,致力于打造业界最佳的数据底座,让企业业务的创新更敏捷,业务洞察更准确,加速释放数据价值,和数据使能协同更好地服务千行万业!
华为云FusionInsight湖仓一体解决方案的前世今生的更多相关文章
- 华为云FusionInsight MRS:助力企业构建“一企一湖,一城一湖”
摘要:华为云FusionInsight MRS新一代的数据湖,让大数据越用越快.越用越易.越用越稳.越用越省!让数据价值近在眼前! 10月30日,以"携手共赢·数创未来"为主题的第 ...
- “3+3”看华为云FusionInsight如何引领“数据新基建”持续发展
摘要:一个统一的现代化的数据基建需要三类架构来实践三种不同的应用场景. 近期,美国知名科技企业风投机构A16Z总结出一套通用的技术架构服务,分为以下三种场景. 一.数据基建架构全景 数据流向显示,左侧 ...
- 解密华为云FusionInsight MRS新特性:一架构三湖
摘要:华为云安全网关产品总监郭冕在"华为云TechWave云原生2.0专题日"上发表<华为云FusionInsight MRS,一个架构实现三种数据湖>的主题演讲,分享 ...
- 李呈祥:bilibili在湖仓一体查询加速上的实践与探索
导读: 本文主要介绍哔哩哔哩在数据湖与数据仓库一体架构下,探索查询加速以及索引增强的一些实践.主要内容包括: 什么是湖仓一体架构 哔哩哔哩目前的湖仓一体架构 湖仓一体架构下,数据的排序组织优化 湖仓一 ...
- 划重点!AWS的湖仓一体使用哪种数据湖格式进行衔接?
此前Apache Hudi社区一直有小伙伴询问能否使用Amazon Redshift查询Hudi表,现在它终于来了. 现在您可以使用Amazon Redshift查询Amazon S3 数据湖中Apa ...
- 【技术干货】华为云FusionInsight MRS的自研超级调度器Superior Scheduler
Superior Scheduler是一个专门为Hadoop YARN分布式资源管理系统设计的调度引擎,是针对企业客户融合资源池,多租户的业务诉求而设计的高性能企业级调度器. Superior Sch ...
- 华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
背景 湖仓一体(LakeHouse)是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素,是当下大数据领域的重要发展方向. 华为云早在2020年就开始着手相关技术的预研,并落地在华为云 Fusio ...
- 技术揭秘:华为云DLI背后的核心计算引擎
摘要:介绍隐藏在华为云数据湖探索服务背后的核心计算引擎Spark,玩转DLI,,轻松完成大数据的分析处理. 本文主要给大家介绍隐藏在华为云数据湖探索服务(后文简称DLI)背后的核心计算引擎——Spar ...
- 当MySQL执行XA事务时遭遇崩溃,且看华为云如何保障数据一致性
摘要:当前MySQL所有版本不支持分布式事务的崩溃恢复安全,这严重影响了分布式事务的高可用保障. 华为云数据库内核高级技术专家,拥有十多年MySQL内核研发经验,目前在华为云数据库团队研发华为云数据库 ...
随机推荐
- Java集合-07Map接口及其抽象类
简介 前面把List基本记录完了,对于集合List,Map,Set,因为Set基于Map,故先记录Map. 这一篇主要记录Map接口及其抽象类(java version:1.8) 整体架构 参考上图, ...
- Harmony OS 开发避坑指南——DevEco Device Tool 安装配置
Harmony OS 开发指南--DevEco Device Tool 安装配置 本文介绍如何在Windows主机上安装DevEco Device Tool工具. 坑点总结: 国内部分网络环境下,安装 ...
- sort函数居然能改变元素值?记一次有趣的Bug——四数之和
坐标leetcode: 我想都不想直接深度优先搜索暴力求解: class Solution { public: vector<vector<int>> res; //答案 in ...
- DM8数据库备份还原的原理及应用
(本文部分内容摘自DM产品技术支持培训文档,如需要更详细的文档,请查询官方操作手册,谢谢) 一.原理 1.DM8备份还原简介 1.1.基本概念 (1)表空间与数据文件 ▷ DM8表空间类型: ▷ SY ...
- 加快ASP。NET Core WEB API应用程序。第2部分
下载source from GitHub 使用各种方法来增加ASP.NET Core WEB API应用程序的生产力 介绍 第1部分.创建测试RESTful WEB API应用程序第2部分.增加了AS ...
- C#实例(经典):四路光电开关&激光雷达数据采集和波形图绘制
前言:本文全部纯手工打造,如有疏漏之处,还请谅解! 如果需要查看更多文章,请微信搜索公众号 csharp编程大全,需要进C#交流群群请加微信z438679770,备注进群, 我邀请你进群! ! ! 这 ...
- 获取Jetbrain全家桶激活码
支持正版,本KEY仅用于体验软件 激活码 激活码一: 2GCA2ZHNKP-eyJsaWNlbnNlSWQiOiIyR0NBMlpITktQIiwibGljZW5zZWVOYW1lIjoi5r+A5r ...
- fastadmin 增加批量操作字段 提示无权限
是这样的找了权限节点的问题,始终找不到,后来 在社区传世人回答别人问题是提及到 $multiFields 就全局搜了下 在基类 Backend 里找到了这个.然后拿到 控制器中添加需要的参数 再次尝 ...
- vue 组件的封装
封装的原因 首先封装组件的需求肯定是多个地方要用到同一个东西,他们都有公共的地方,vue的封装 简单来说就是将公共参数封装起来 然后在需要的地方引入 //子组件封装 <template> ...
- Nuxt+Vue聊天室|nuxt仿微信App界面|nuxt.js聊天实例
一.项目简述 nuxt-chatroom 基于Nuxt.js+Vue.js+Vuex+Vant+VPopup等技术构建开发的仿微信|探探App界面社交聊天室项目.实现了卡片式翻牌滑动.消息发送/emo ...