Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置)。
使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的。
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
urllib.request 中通过ProxyHandler来设置使用代理服务器,下面代码说明如何使用自定义 opener 来使用代理:
import urllib.request # 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"https": "27.191.234.69:9999"})
nullproxy_handler = urllib.request.ProxyHandler({}) # 定义一个代理开关
proxySwitch = True # 通过 urllib.request.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler) request = urllib.request.Request("http://www.baidu.com/") # 1. 如果这么写,只有使用opener.open()方法发送请求才使用自定义的代理,而urlopen()则不使用自定义代理。
response = opener.open(request) # 2. 如果这么写,就是将opener应用到全局,之后所有的,不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urllib.request.urlopen(request) # 获取服务器响应内容
html = response.read().decode("utf-8") # 打印字符串
print(html)
最终结果如下:
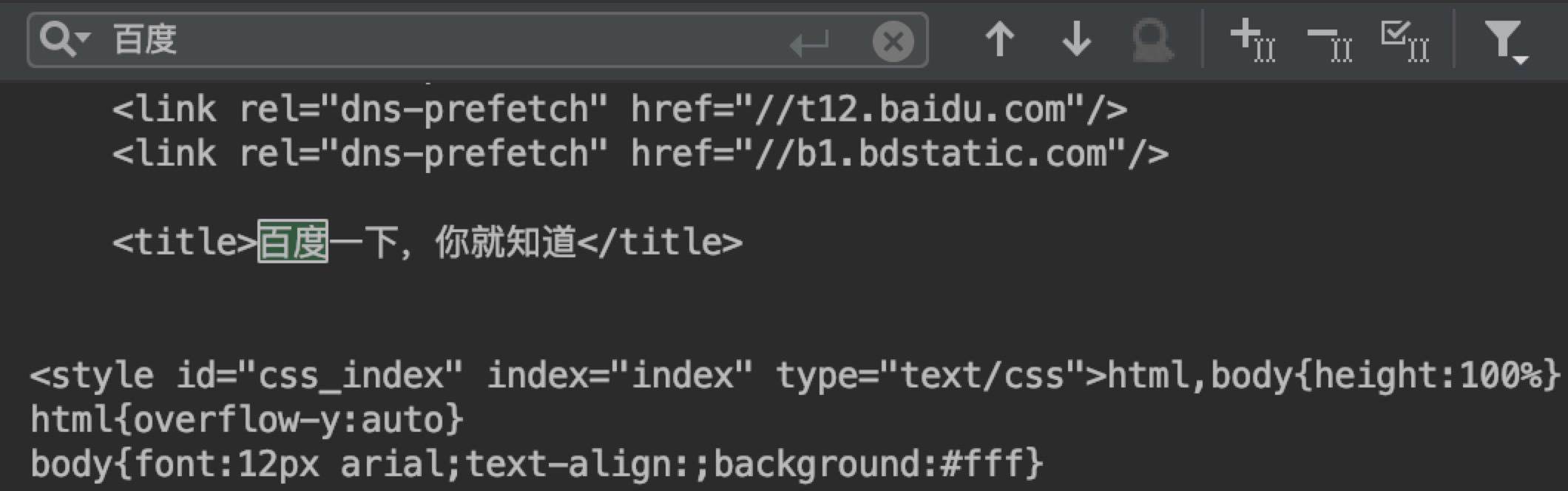
在上面的代码第 4 行,我们使用了一个免费的代理 IP,国内有很多免费的代理 IP 地址,如下:
但是上面的免费代理只支持短期的,就是说在我们在短期爬取信息或者自己做测试可以去上面找可以使用的,但是如果要是长期的话我们需要自己购买代理 IP 比较稳妥。
为了避免我们的代理 IP 被封后爬取失败,我们可以使用多个代理 Ip,然后不定时切换就可以了,如下:
import urllib.request
import random # 代理列表
proxy_list = [
{"http": "27.191.234.69:9999"},
{"http": "27.191.234.69:9999"},
{"http": "27.191.234.69:9999"},
{"http": "27.191.234.69:9999"},
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy) # 通过 urllib.request.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
opener = urllib.request.build_opener(httpproxy_handler) request = urllib.request.Request("http://www.baidu.com/")
response = opener.open(request)
html = response.read().decode("utf-8")
print(html)
接下来我们看一下自己购买的私密 IP 该如何使用代理。
import urllib.request # 私密代理授权的账户
user = "user"
# 私密代理授权的密码
passwd = "passwd"
# 私密代理 IP
proxyserver = "62.151.164.138:12816" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的 ProxyBasicAuthHandler 处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通 ProxyHandler 类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理 Handler 对象,创建自定义 opener 对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求
request = urllib.request.Request("http://www.baidu.com/") # 6. 使用自定义opener发送请求
response = opener.open(request) # 7. 打印响应内容
html = response.read().decode("utf-8")
print(html)
免费开放代理一般会有很多人都在使用,而且代理有寿命短,速度慢,匿名度不高,HTTP/HTTPS支持不稳定等缺点(免费没好货)。
专业爬虫工程师或爬虫公司会使用高品质的私密代理,这些代理通常需要找专门的代理供应商购买,再通过用户名/密码授权使用(舍不得孩子套不到狼)。
Python 爬虫从入门到进阶之路(五)的更多相关文章
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- vue1
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- .Net中常用的几种ActionResult
1.ViewResult 表示一个视图结果,它根据视图模板产生应答内容.对应得Controller方法为View. 2.PartialViewResult 表示一个部分视图结果,与ViewResult ...
- 用C#调用Lua脚本
用C#调用Lua脚本 一.引言 学习Redis也有一段时间了,感触还是颇多的,但是自己很清楚,路还很长,还要继续.上一篇文章简要的介绍了如何在Linux环境下安装Lua,并介绍了在Linux环境下如何 ...
- Elasticsearch之源码分析(shard分片规则)
前期博客是 Elasticsearch之源码编译 (1)elasticsearch在建立索引时,根据id或(id,类型)进行hash,得到hash值之后再与该索引的分片数量取模,取模的值即为存入的分片 ...
- 一款开源Office软件---Lotus Symphony在Linux系统下的应用
点击下载观看试用录像 Linux系统下的办公软件有OpenOffice.永中Office.红旗Red Office.金山Wps Office及StarOffice等,今天我为大家介绍IBM推进军O ...
- angularjs之ui-bootstrap的Datepicker Popup不使用JS实现双日期选择控件
最开始使用ui-bootstrap的Datepicker Popup日期选择插件实现双日期选择时间范围时,在网上搜了一些通过JS去实现的方法,不过后来发现可以不必通过JS去处理,只需要使用其自身的属性 ...
- 今日SGU 5.8
SGU 109 题意:一个n*n的矩形,起点在1,1然后每次给你一个操作,走ki步,然后你可以删除任意一个点这次步走不到的,删了就不能再走了,然后问构造这种操作,使得最后删除n*n-1个点 剩下一个点 ...
- dp之多重背包(未用二进制优化)
hdu 2191: #include <iostream>#include <stdio.h>#include <string.h>using namespace ...
- 【hdu 4289】Control
[Link]:http://acm.hdu.edu.cn/showproblem.php?pid=4289 [Description] 给出一个又n个点,m条边组成的无向图.给出两个点s,t.对于图中 ...
- IIS下配置SilverLight
在Windows 2003 IIS 6.0环境下 在Silverlight中需要使用xap.XAML文件类型,如果您想在IIS服务器上使用Silverlight 4.0程序,所以必须在IIS中注册 ...