二、Fast-R-CNN
一、概括
Fast R-cnn的主要亮点有:Fast R-CNN将借助多任务损失函数,将物体识别和位置修正合成到一个网络中,不再对网络进行分步训练,不需要大量内存来存储训练过程中特征的数据;用RoI层代替SPP层,可以使用BP算法更高效的训练更新整个网络。现在,这些方法已经很少使用了,但是经典的网络中涉及到的框架结构搭建,训练与优化等技巧还是值得我们去学习。
Fast R-CNN框架与R-CNN有两处不同:
① 最后一个卷积层后加了一个ROI pooling layer;
② 损失函数使用了multi-task loss(多任务损失)函数,将边框回归直接加到CNN网络中训练。分类Fast R-CNN直接用softmax替代R-CNN用的SVM进行分类。
Fast R-CNN是端到端(end-to-end)的。
解决了R-CNN方法的三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。
将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
问题二:训练时速度慢
原因同上。
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。
本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
二、框架
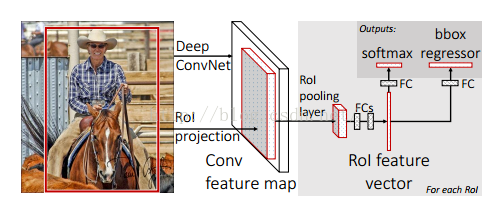
一张包含多个RoI(regions of interest)的图片(上图便于说明只显示一个RoI,灰色部分)输入一个多层的卷积网络中,获得Conv feature map;
然后每一个RoI被池化成一个固定大小的feature map,feature map被全连接层拉伸成一个特征向量;
对于每一个RoI,经过FC层后得到的feature vector最终被分享:
一个进行全连接之后用来做softmax回归,用来对RoI区域做物体识别,
另一个经过全连接之后用来做b-box regression做修正定位,使得定位框更加精准。
主要内容
1、ROI(regions of interest)
RoI指的是在一张图片上完成Selective Search后得到的“候选框”在特征图上的一个映射,RoI层的作用主要有两点:
1、考虑到感兴趣区域(RoI)尺寸不一,但是输入图中后面FC层的大小是一个统一的固定值,因为ROI池化层的作用类似于SPP-net中的SPP层,即将不同尺寸的RoI feature map池化成一个固定大小的feature map。
具体操作:假设经过RoI池化后的固定大小为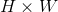 是一个超参数,因为输入的RoI feature map大小不一样,假设为
是一个超参数,因为输入的RoI feature map大小不一样,假设为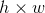 ,需要对这个feature map进行池化来减小尺寸,那么可以计算出池化窗口的尺寸为:
,需要对这个feature map进行池化来减小尺寸,那么可以计算出池化窗口的尺寸为: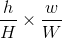 ,即用这个计算出的窗口对RoI feature map做max pooling,Pooling对每一个feature map通道都是独立的。
,即用这个计算出的窗口对RoI feature map做max pooling,Pooling对每一个feature map通道都是独立的。
其次RoI有四个参数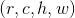 除了尺寸参数
除了尺寸参数 、
、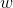 外,还有两个位置参数
外,还有两个位置参数 、
、 表示RoI的左上角在整个图片中的坐标。
表示RoI的左上角在整个图片中的坐标。
2、从预训练网络中初始化
作者使用有5个最大池化层和5到13个不等的卷积层的三种网络进行预训练:CaffeNet,VGG_CNN_M_1024,VGG-16,使用这些网络初始化Fast R-CNN前,需要以下修改:
①用RoI pooling layer取代网络的最后一个池化层
②最后一个FC层和softmax被替换成fast R-CNN框架图介绍的两个并列层
③输入两组数据到网络:一组图片和每一个图片的一组RoIs
3、微调网络用来检测
不同于SPP-net,Fast R-CNN整个网络可以被使用BP算法训练是一个极大的优点,论文中作者提到SPP层中的感受野非常大,使用BP算法训练时效率低。
作者利用特征分享的优势,提出一个更加有效的训练方法:SGD mini_batch分层采样方法。
首先随机取样N张图片,然后每张图片取样R(R个候选框)/N(N张图片)个RoIs 。除此之外,网络在一次微调中将softmax分类器和bbox回归一起优化,区别于R-CNN的softmax回归,SVM,bbox回归的三步分开优化。
一步优化中涉及到:多任务损失(multi-task loss)、小批量取样(mini-batch sampling)、RoI pooling层的反向传播(back-propagation through RoI pooling layers)、SGD超参数(SGD hyperparameters),其中multi-task loss在论文里对应着分类任务和定位任务的结合,back-propagation through RoI pooling layers在论文里作者详细讲解了如何使用BP算法对RoI层训练,这两个小部分比较重要,也是论文的核心亮点,以后有机会单独拿出来学习一下。
4、尺度不变性
作者测试了两种方法来实现目标检测的尺度不变性:“强制”学习和图像金字塔方法。
在“强制”方法中,在训练和测试过程中,每个图像都按照预先定义的像素大小进行处理。网络直接从训练数据中学习尺度不变性检测。
相比之下,多尺度方法通过图像金字塔为网络提供了近似的尺度不变性。在测试时,使用图像金字塔方法对each object proposal进行标准化。
训练过程和测试过程
训练过程
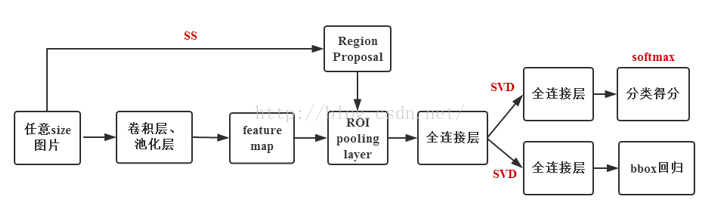
对训练集中的图片,用selective search提取出每一个图片对应的一些proposal,保存图片路径和bounding box信息;
对每张图片,根据图片中bounding box的ground truth信息,给该图片的每一个proposal标记类标签,并保存。具体操作:对于每一个proposal,如果和ground truth中的proposal的IOU值超过了阈值(IOU>=0.5),则把ground truth中的proposal对应的类标签给原始产生的这个proposal,其余的proposal都标为背景;
使用mini-batch=128,25%来自非背景标签的proposal,其余来自标记为背景的proposal;
训练CNN,最后一层的结果包含分类信息和位置修正信息,用多任务的loss,一个是分类的损失函数,一个是位置的损失函数。
测试过程
用selective search方法提取图片的2000个proposal,并保存到文件;
将图片输入到已经训好的多层全卷积网络,对每一个proposal,获得对应的RoI Conv featrue map;
对每一个RoI Conv featrue map,按照3.1中的方法进行池化,得到固定大小的feture map,并将其输入到后续的FC层,最后一层输出类别相关信息和4个boundinf box的修正偏移量;
对bounding box 按照上述得到的位置偏移量进行修正,再根据nms对所有的proposal进行筛选,即可得到对该张图片的bounding box预测值以及每个bounding box对应的类和score。
roi_pool层的测试(forward)
roi_pool层将每个候选区域均匀分成M×N块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
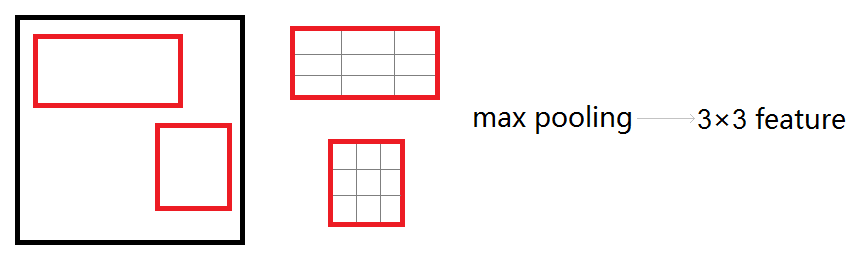
roi_pool层的训练(backward)
先考虑普通max pooling层。设xi为输入层的节点,yj为输出层的节点。
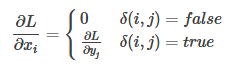
其中判决函数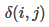 表示i节点是否被j节点选为最大值输出。不被选中有两种可能:
表示i节点是否被j节点选为最大值输出。不被选中有两种可能: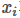 不在
不在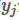 范围内,或者不是最大值。
范围内,或者不是最大值。
对于roi max pooling,一个输入节点可能和多个输出节点相连。设为输入层的节点,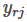 为第r个候选区域的第j个输出节点。
为第r个候选区域的第j个输出节点。
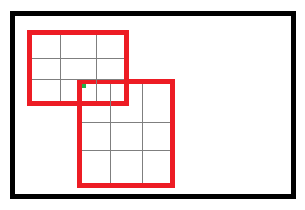
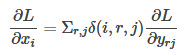
判决函数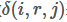 表示i节点是否被候选区域r的第j个节点选为最大值输出。代价对于的梯度等于所有相关的后一层梯度之和。
表示i节点是否被候选区域r的第j个节点选为最大值输出。代价对于的梯度等于所有相关的后一层梯度之和。
网络训练参数
参数初始化
网络除去末尾部分如下图,在ImageNet上训练1000类分类器。结果参数作为相应层的初始化参数。其余参数随机初始化。
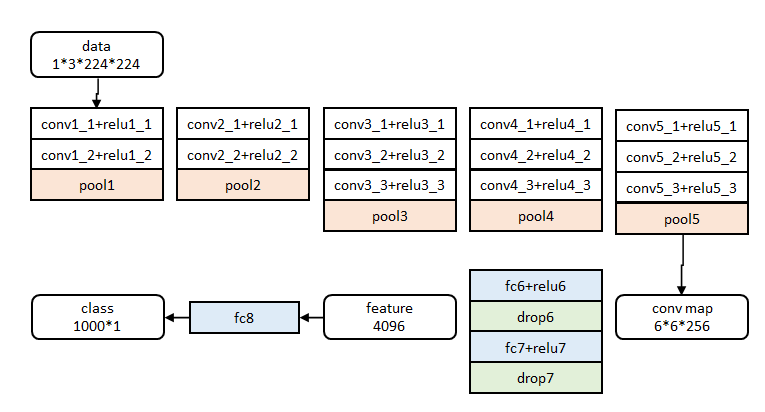
分层数据
在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征。
实际选择N=2, R=128。
训练数据构成
N张完整图片以50%概率水平翻转。
R个候选框的构成方式如下:

分类与位置调整
代价函数
Fast R-CNN网络有两个同级输出层(cls score和bbox_prdict层),都是全连接层,称为multi-task。
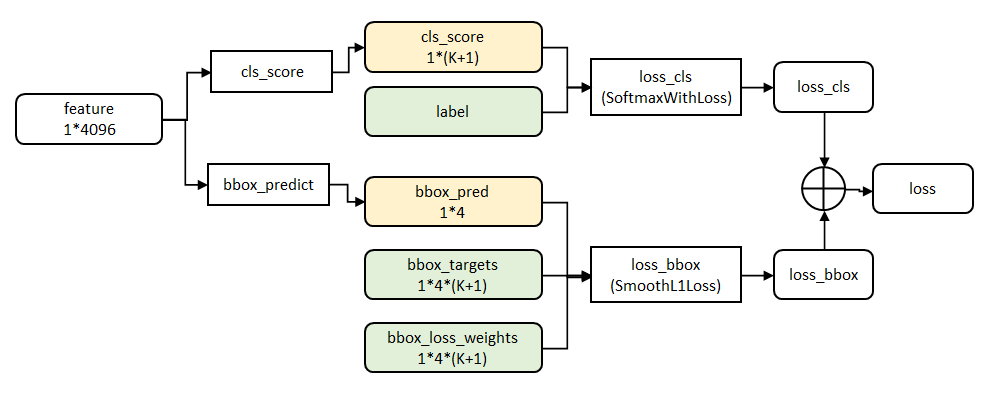
cls_score层用于分类,输出K+1维数组P,表示属于K类和背景的概率。对每个ROI(region of interesting)输出离散型概率分布:
通常,p由k+1类的全连接层利用softmax计算得出。
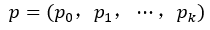
bbox_prdict层用于调整候选区域位置,输出bounding box回归的位移,输出4*K维数组t,分别表示属于K类时,应该平移缩放的参数。
k表示类别的索引,
是指相对于object proposal尺度不变的平移,
是指对数空间中相对于object proposal的高与宽。
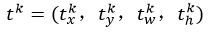
loss_cls层评估分类代价。由真实分类u对应的概率决定(类似于softmax,可以看做是概率):
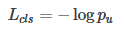
loss_bbox评估检测框定位代价。比较真实分类对应的预测参数
和真实平移缩放参数为
的差别:
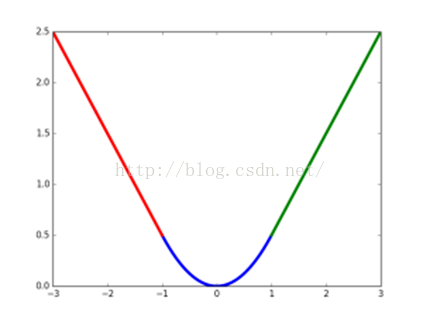
其中,smooth L1损失函数为:
相比于L2损失函数,smooth对离群点、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。
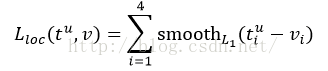

最后总损失为(两者加权和,如果分类为背景则不考虑定位损失):
规定u=0为背景类(也就是负标签),那么艾弗森括号指数函数[u≥1]表示背景候选区域即负样本不参与回归损失,不需要对候选区域进行回归操作。λ控制分类损失和回归损失的平衡。Fast R-CNN论文中,所有实验λ=1。
艾弗森括号指数函数为:
源码中bbox_loss_weights用于标记每一个bbox是否属于某一个类
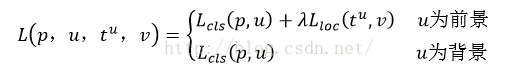
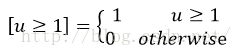
全连接层提速
分类和位置调整都是通过全连接层(fc)实现的,设前一级数据为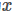 后一级为
后一级为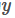 ,全连接层参数为
,全连接层参数为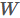 ,尺寸
,尺寸 ,一次前向传播(forward)即为:
,一次前向传播(forward)即为:

计算复杂度为
将进行SVD分解,并用前t个特征值近似:
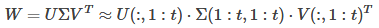
原来的前向传播分解成两步:
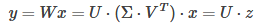
计算复杂度变为 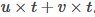
在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。
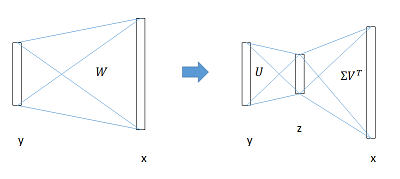
实验结论
实验过程不再详述,只记录结论
- 网络末端同步训练的分类和位置调整,提升准确度
- 使用多尺度的图像金字塔,性能几乎没有提高
- 倍增训练数据,能够有2%-3%的准确度提升
- 网络直接输出各类概率(softmax),比SVM分类器性能略好
- 更多候选窗不能提升性能
二、Fast-R-CNN的更多相关文章
- RCNN--对象检测的又一伟大跨越 2(包括SPPnet、Fast RCNN)(持续更新)
继续上次的学习笔记,在RCNN之后是Fast RCNN,但是在Fast RCNN之前,我们先来看一个叫做SPP-net的网络架构. 一,SPP(空间金字塔池化,Spatial Pyramid Pool ...
- 第十四节、FAST角点检测(附源码)
在前面我们已经陆续介绍了许多特征检测算子,我们可以根据图像局部的自相关函数求得Harris角点,后面又提到了两种十分优秀的特征点以及他们的描述方法SIFT特征和SURF特征.SURF特征是为了提高运算 ...
- 目标检测算法的总结(R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD、FNP、ALEXnet、RetianNet、VGG Net-16)
目标检测解决的是计算机视觉任务的基本问题:即What objects are where?图像中有什么目标,在哪里?这意味着,我们不仅要用算法判断图片中是不是要检测的目标, 还要在图片中标记出它的位置 ...
- Android动画学习(二)——Tween Animation
前两天写过一篇Android动画学习的概述,大致的划分了下Android Animation的主要分类,没有看过的同学请移步:Android动画学习(一)——Android动画系统框架简介.今天接着来 ...
- R语言-用R眼看琅琊榜小说的正确姿势
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html 目录: 零:写在前面的一些废话 一.R眼看琅琊榜的基本原理 1.导入数据 2.筛选数据 3.多条 ...
- R语言基础
一.扩展包的基本操作语句R安装好之后,默认自带了"stats" "graphics" "grDevices" "utils&qu ...
- R语言简单入门
一.运行R语言可以做哪些事? 1.探索性数据分析(将数据绘制图表) 2.统计推断(根据数据进行预测) 3.回归分析(对数据进行拟合分析) 4.机器学习(对数据集进行训练和预测) 5.数据产品开发 二. ...
- R中逻辑运算
一.是否相等的判断的方法 (1)判断字符串是否相等is.null(x) (2)判断x的每个元素是否在y中出现: x %in% y (3)判断判断每个相对应的元素是否相等: x == y (4)判断近似 ...
- 数据分析与R语言-概念点(一)
一.数据分析 1.数据分析的多层模型 常用的统计量 常用的算法 常用的数据分析工具 常见的报表 二.R语言 1.什么是R语言? R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个 ...
- R语言分析(一)-----基本语法
一, R语言所处理的工作层: 解释一下: 最下面的一层为数据源,往上是数据仓库层,往上是数据探索层,包括统计分析,统计查询,还有就是报告 再往上的三层,分别是数据挖掘,数据展现和数据决策. 由上图 ...
随机推荐
- android drawable资源调用使用心得
1. 调用顺序 android 调用应用图片资源时,会优先选择当前手机屏幕dpi对应的的文件夹(如drawable-ldpi, drawable-mdpi, drawable-hdpi, drawab ...
- nyoj--586--疯牛(二分&&枚举)
疯牛 时间限制:1000 ms | 内存限制:65535 KB 难度:4 描述 农夫 John 建造了一座很长的畜栏,它包括N (2 <= N <= 100,000)个隔间,这些小隔间 ...
- Binary Indexed Tree
我借鉴了这个视频中的讲解的填坑法,我认为非常易于理解.有FQ能力和基本英语听力能力请直接去看视频,并不需要继续阅读. naive 算法 考虑一个这样的场景: 给定一个int数组, 我们想知道它的连续子 ...
- 移动端 input 获取焦点后弹出带enter(类似于搜索,确定,前往)键盘,以及隐藏系统键盘
一:调出系统带回车键的键盘 在项目中经常有输入框,当输入完成后点击确定执行相应的动作.但是有些设计没有确定或者搜索按钮,这就需要调用系统键盘,点击系统键盘的确定后执行相应动作. 但是单纯的input是 ...
- 终于意识到BIM确实火了
碰巧遇到一个BIM会议.一大帮国内的老师桠桠叉叉坐了一大屋.听了半天感觉都是在吹BIM如何火.第一次听到这个概念感觉这个能火吗. 昨天雄安新区用BIM建设的新闻出来后,一下子惊了.看来BIM进入计算机 ...
- (转载) Android-Spinner的使用以及两种适配器
目录视图 摘要视图 订阅 赠书 | 异步2周年,技术图书免费选 程序员8月书讯 项目管理+代码托管+文档协作,开发更流畅 Android-Spinner的使用以及两种适配器 201 ...
- (转载)Android之三种网络请求解析数据(最佳案例)
[置顶] Android之三种网络请求解析数据(最佳案例) 2016-07-25 18:02 4725人阅读 评论(0) 收藏 举报 分类: Gson.Gson解析(1) 版权声明:本文为博主原创 ...
- LR编写get请求
LR编写简单Get接口 接口必备信息:接口功能.URL.支持格式.http请求方式.请求参数.返回参数 请求地址 http://api.k780.com:88/?app=life.time 请求方式 ...
- S-T表学习笔记
$O(nlogn)$构造$O(1)$查询真是太强辣 然而不支持修改= = ShØut! #include<iostream> #include<cstring> #includ ...
- 将页面的内容导出使用html2canvas+jsPDF
第一首先是要引用 import jsPDF from 'jspdf' import html2canvas from 'html2canvas' import PDFJS from 'pdfjs-di ...