Lucene学习总结之四:Lucene索引过程分析 2014-06-25 14:18 884人阅读 评论(0) 收藏
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后的文章中进行分析。
Lucene的索引过程,很多的博客,文章都有介绍,推荐大家上网搜一篇文章:《Annotated Lucene》,好像中文名称叫《Lucene源码剖析》是很不错的。
想要真正了解Lucene索引文件过程,最好的办法是跟进代码调试,对着文章看代码,这样不但能够最详细准确的掌握索引过程(描述都是有偏差的,而代码是不会骗你的),而且还能够学习Lucene的一些优秀的实现,能够在以后的工作中为我所用,毕竟Lucene是比较优秀的开源项目之一。
由于Lucene已经升级到3.0.0了,本索引过程为Lucene 3.0.0的索引过程。
一、索引过程体系结构
Lucene 3.0的搜索要经历一个十分复杂的过程,各种信息分散在不同的对象中分析,处理,写入,为了支持多线程,每个线程都创建了一系列类似结构的对象集,为了提高效率,要复用一些对象集,这使得索引过程更加复杂。
其实索引过程,就是经历下图中所示的索引链的过程,索引链中的每个节点,负责索引文档的不同部分的信息 ,当经历完所有的索引链的时候,文档就处理完毕了。最初的索引链,我们称之基本索引链 。
为了支持多线程,使得多个线程能够并发处理文档,因而每个线程都要建立自己的索引链体系,使得每个线程能够独立工作,在基本索引链基础上建立起来的每个线程独立的索引链体系,我们称之线程索引链 。线程索引链的每个节点是由基本索引链中的相应的节点调用函数addThreads创建的。
为了提高效率,考虑到对相同域的处理有相似的过程,应用的缓存也大致相当,因而不必每个线程在处理每一篇文档的时候都重新创建一系列对象,而是复用这些对象。所以对每个域也建立了自己的索引链体系,我们称之域索引链 。域索引链的每个节点是由线程索引链中的相应的节点调用addFields创建的。
当完成对文档的处理后,各部分信息都要写到索引文件中,写入索引文件的过程是同步的,不是多线程的,也是沿着基本索引链将各部分信息依次写入索引文件的。
下面详细分析这一过程。
二、详细索引过程
1、创建IndexWriter对象
代码:
| IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); |
IndexWriter对象主要包含以下几方面的信息:
- 用于索引文档
- Directory directory; 指向索引文件夹
- Analyzer analyzer; 分词器
- Similarity similarity = Similarity.getDefault(); 影响打分的标准化因子(normalization factor)部分,对文档的打分分两个部分,一部分是索引阶段计算的,与查询语句无关,一部分是搜索阶段计算的,与查询语句相关。
- SegmentInfos segmentInfos = new SegmentInfos(); 保存段信息,大家会发现,和segments_N中的信息几乎一一对应。
- IndexFileDeleter deleter; 此对象不是用来删除文档的,而是用来管理索引文件的。
- Lock writeLock; 每一个索引文件夹只能打开一个IndexWriter,所以需要锁。
- Set segmentsToOptimize = new HashSet(); 保存正在最优化(optimize)的段信息。当调用optimize的时候,当前所有的段信息加入此Set,此后新生成的段并不参与此次最优化。
- 用于合并段,在合并段的文章中将详细描述
- SegmentInfos localRollbackSegmentInfos;
- HashSet mergingSegments = new HashSet();
- MergePolicy mergePolicy = new LogByteSizeMergePolicy(this);
- MergeScheduler mergeScheduler = new ConcurrentMergeScheduler();
- LinkedList pendingMerges = new LinkedList();
- Set runningMerges = new HashSet();
- List mergeExceptions = new ArrayList();
- long mergeGen;
- 为保持索引完整性,一致性和事务性
- SegmentInfos rollbackSegmentInfos; 当IndexWriter对索引进行了添加,删除文档操作后,可以调用commit将修改提交到文件中去,也可以调用rollback取消从上次commit到此时的修改。
- SegmentInfos localRollbackSegmentInfos; 此段信息主要用于将其他的索引文件夹合并到此索引文件夹的时候,为防止合并到一半出错可回滚所保存的原来的段信息。
- 一些配置
- long writeLockTimeout; 获得锁的时间超时。当超时的时候,说明此索引文件夹已经被另一个IndexWriter打开了。
- int termIndexInterval; 同tii和tis文件中的indexInterval。
有关SegmentInfos对象所保存的信息:
- 当索引文件夹如下的时候,SegmentInfos对象如下表
|
segmentInfos SegmentInfos (id=37) |
有关IndexFileDeleter:
- 其不是用来删除文档的,而是用来管理索引文件的。
- 在对文档的添加,删除,对段的合并的处理过程中,会生成很多新的文件,并需要删除老的文件,因而需要管理。
- 然而要被删除的文件又可能在被用,因而要保存一个引用计数,仅仅当引用计数为零的时候,才执行删除。
- 下面这个例子能很好的说明IndexFileDeleter如何对文件引用计数并进行添加和删除的。
|
(1) 创建IndexWriter时 IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); 索引文件夹如下:
引用计数如下: refCounts HashMap (id=101) (2) 添加第一个段时 indexDocs(writer, docDir); 首先生成的不是compound文件
因而引用计数如下: refCounts HashMap (id=101) 然后会合并成compound文件,并加入引用计数
refCounts HashMap (id=101) 然后会用IndexFileDeleter.decRef()来删除[_0.nrm, _0.tis, _0.fnm, _0.tii, _0.frq, _0.fdx, _0.prx, _0.fdt]文件
refCounts HashMap (id=101) 然后为建立新的segments_2
refCounts HashMap (id=77) 然后IndexFileDeleter.decRef() 删除segments_1文件
refCounts HashMap (id=77) (3) 添加第二个段 indexDocs(writer, docDir);
(4) 添加第三个段,由于MergeFactor为3,则会进行一次段合并。 indexDocs(writer, docDir); 首先和其他的段一样,生成_2.cfs以及segments_4
同时创建了一个线程来进行背后进行段合并(ConcurrentMergeScheduler$MergeThread.run())
这时候的引用计数如下 refCounts HashMap (id=84) (5) 关闭writer writer.close(); 通过IndexFileDeleter.decRef()删除被合并的段
|


有关SimpleFSLock进行JVM之间的同步:
- 有时候,我们写java程序的时候,也需要不同的JVM之间进行同步,来保护一个整个系统中唯一的资源。
- 如果唯一的资源仅仅在一个进程中,则可以使用线程同步的机制
- 然而如果唯一的资源要被多个进程进行访问,则需要进程间同步的机制,无论是Windows和Linux在操作系统层面都有很多的进程间同步的机制。
- 但进程间的同步却不是Java的特长,Lucene的SimpleFSLock给我们提供了一种方式。
| Lock的抽象类 public abstract class Lock { public static long LOCK_POLL_INTERVAL = 1000; public static final long LOCK_OBTAIN_WAIT_FOREVER = -1; public abstract boolean obtain() throws IOException; public boolean obtain(long lockWaitTimeout) throws LockObtainFailedException, IOException { boolean locked = obtain(); if (lockWaitTimeout < 0 && lockWaitTimeout != LOCK_OBTAIN_WAIT_FOREVER) long maxSleepCount = lockWaitTimeout / LOCK_POLL_INTERVAL; long sleepCount = 0; while (!locked) { if (lockWaitTimeout != LOCK_OBTAIN_WAIT_FOREVER && sleepCount++ >= maxSleepCount) { public abstract void release() throws IOException; public abstract boolean isLocked() throws IOException; } LockFactory的抽象类 public abstract class LockFactory { public abstract Lock makeLock(String lockName); abstract public void clearLock(String lockName) throws IOException; SimpleFSLock的实现类 class SimpleFSLock extends Lock { File lockFile; public SimpleFSLock(File lockDir, String lockFileName) { @Override if (!lockDir.exists()) { if (!lockDir.mkdirs()) } else if (!lockDir.isDirectory()) { throw new IOException("Found regular file where directory expected: " + lockDir.getAbsolutePath()); return lockFile.createNewFile(); } @Override if (lockFile.exists() && !lockFile.delete()) } @Override return lockFile.exists(); } } SimpleFSLockFactory的实现类 public class SimpleFSLockFactory extends FSLockFactory { public SimpleFSLockFactory(String lockDirName) throws IOException { setLockDir(new File(lockDirName)); } @Override if (lockPrefix != null) { lockName = lockPrefix + "-" + lockName; } return new SimpleFSLock(lockDir, lockName); } @Override if (lockDir.exists()) { if (lockPrefix != null) { lockName = lockPrefix + "-" + lockName; } File lockFile = new File(lockDir, lockName); if (lockFile.exists() && !lockFile.delete()) { throw new IOException("Cannot delete " + lockFile); } } } }; |
2、创建文档Document对象,并加入域(Field)
代码:
|
Document doc = new Document(); doc.add(new Field("path", f.getPath(), Field.Store.YES, Field.Index.NOT_ANALYZED)); doc.add(new Field("modified",DateTools.timeToString(f.lastModified(), DateTools.Resolution.MINUTE), Field.Store.YES, Field.Index.NOT_ANALYZED)); doc.add(new Field("contents", new FileReader(f))); |
Document对象主要包括以下部分:
- 此文档的boost,默认为1,大于一说明比一般的文档更加重要,小于一说明更不重要。
- 一个ArrayList保存此文档所有的域
- 每一个域包括域名,域值,和一些标志位,和fnm,fdx,fdt中的描述相对应。
|
doc Document (id=42) |
3、将文档加入IndexWriter
代码:
| writer.addDocument(doc); -->IndexWriter.addDocument(Document doc, Analyzer analyzer) -->doFlush = docWriter.addDocument(doc, analyzer); --> DocumentsWriter.updateDocument(Document, Analyzer, Term) 注:--> 代表一级函数调用 |
IndexWriter继而调用DocumentsWriter.addDocument,其又调用DocumentsWriter.updateDocument。
4、将文档加入DocumentsWriter
代码:
| DocumentsWriter.updateDocument(Document doc, Analyzer analyzer, Term delTerm) -->(1) DocumentsWriterThreadState state = getThreadState(doc, delTerm); -->(2) DocWriter perDoc = state.consumer.processDocument(); -->(3) finishDocument(state, perDoc); |
DocumentsWriter对象主要包含以下几部分:
- 用于写索引文件
- IndexWriter writer;
- Directory directory;
- Similarity similarity:分词器
- String segment:当前的段名,每当flush的时候,将索引写入以此为名称的段。
| IndexWriter.doFlushInternal() --> String segment = docWriter.getSegment();//return segment --> newSegment = new SegmentInfo(segment,……); --> docWriter.createCompoundFile(segment);//根据segment创建cfs文件。 |
- String docStoreSegment:存储域所要写入的目标段。(在索引文件格式一文中已经详细描述)
- int docStoreOffset:存储域在目标段中的偏移量。
- int nextDocID:下一篇添加到此索引的文档ID号,对于同一个索引文件夹,此变量唯一,且同步访问。
- DocConsumer consumer; 这是整个索引过程的核心,是IndexChain整个索引链的源头。
|
基本索引链: 对于一篇文档的索引过程,不是由一个对象来完成的,而是用对象组合的方式形成的一个处理链,链上的每个对象仅仅处理索引过程的一部分,称为索引链,由于后面还有其他的索引链,所以此处的索引链我称为基本索引链。 DocConsumer consumer 类型为DocFieldProcessor,是整个索引链的源头,包含如下部分:
|
- 删除文档
- BufferedDeletes deletesInRAM = new BufferedDeletes();
- BufferedDeletes deletesFlushed = new BufferedDeletes();
|
类BufferedDeletes包含了一下的成员变量:
由此可见,文档的删除主要有三种方式:
删除文档既可以用reader进行删除,也可以用writer进行删除,不同的是,reader进行删除后,此reader马上能够生效,而用writer删除后,会被缓存在deletesInRAM及deletesFlushed中,只有写入到索引文件中,当reader再次打开的时候,才能够看到。 那deletesInRAM和deletesFlushed各有什么用处呢? 此版本的Lucene对文档的删除是支持多线程的,当用IndexWriter删除文档的时候,都是缓存在deletesInRAM中的,直到flush,才将删除的文档写入到索引文件中去,我们知道flush是需要一段时间的,那么在flush的过程中,另一个线程又有文档删除怎么办呢? 一般过程是这个样子的,当flush的时候,首先在同步(synchornized)的方法pushDeletes中,将deletesInRAM全部加到deletesFlushed中,然后将deletesInRAM清空,退出同步方法,于是flush的线程程就向索引文件写deletesFlushed中的删除文档的过程,而与此同时其他线程新删除的文档则添加到新的deletesInRAM中去,直到下次flush才写入索引文件。 |
- 缓存管理
- 为了提高索引的速度,Lucene对很多的数据进行了缓存,使一起写入磁盘,然而缓存需要进行管理,何时分配,何时回收,何时写入磁盘都需要考虑。
- ArrayList freeCharBlocks = new ArrayList();将用于缓存词(Term)信息的空闲块
- ArrayList freeByteBlocks = new ArrayList();将用于缓存文档号(doc id)及词频(freq),位置(prox)信息的空闲块。
- ArrayList freeIntBlocks = new ArrayList();将存储某词的词频(freq)和位置(prox)分别在byteBlocks中的偏移量
- boolean bufferIsFull;用来判断缓存是否满了,如果满了,则应该写入磁盘
- long numBytesAlloc;分配的内存数量
- long numBytesUsed;使用的内存数量
- long freeTrigger;应该开始回收内存时的内存用量。
- long freeLevel;回收内存应该回收到的内存用量。
- long ramBufferSize;用户设定的内存用量。
| 缓存用量之间的关系如下: DocumentsWriter.setRAMBufferSizeMB(double mb){ ramBufferSize = (long) (mb*1024*1024);//用户设定的内存用量,当使用内存大于此时,开始写入磁盘 } //释放free blocks byteBlockAllocator.freeByteBlocks.remove(byteBlockAllocator.freeByteBlocks.size()-1); freeCharBlocks.remove(freeCharBlocks.size()-1); freeIntBlocks.remove(freeIntBlocks.size()-1); if (numBytesUsed+deletesRAMUsed > ramBufferSize){ //当使用的内存加删除文档占有的内存大于用户指定的内存时,可以写入磁盘 bufferIsFull = true; } } 当判断是否应该写入磁盘时:
DocumentsWriter.timeToFlushDeletes(){ return (bufferIsFull || deletesFull()) && setFlushPending(); } DocumentsWriter.deletesFull(){ return (ramBufferSize != IndexWriter.DISABLE_AUTO_FLUSH && } |
- 多线程并发索引
- 为了支持多线程并发索引,对每一个线程都有一个DocumentsWriterThreadState,其为每一个线程根据DocConsumer consumer的索引链来创建每个线程的索引链(XXXPerThread),来进行对文档的并发处理。
- DocumentsWriterThreadState[] threadStates = new DocumentsWriterThreadState[0];
- HashMap threadBindings = new HashMap();
- 虽然对文档的处理过程可以并行,但是将文档写入索引文件却必须串行进行,串行写入的代码在DocumentsWriter.finishDocument中
- WaitQueue waitQueue = new WaitQueue()
- long waitQueuePauseBytes
- long waitQueueResumeBytes
|
在Lucene中,文档是按添加的顺序编号的,DocumentsWriter中的nextDocID就是记录下一个添加的文档id。 当Lucene支持多线程的时候,就必须要有一个synchornized方法来付给文档id并且将nextDocID加一,这些是在DocumentsWriter.getThreadState这个函数里面做的。 虽然给文档付ID没有问题了。但是由Lucene索引文件格式我们知道,文档是要按照ID的顺序从小到大写到索引文件中去的,然而不同的文档处理速度不同,当一个先来的线程一处理一篇需要很长时间的大文档时,另一个后来的线程二可能已经处理了很多小的文档了,但是这些后来小文档的ID号都大于第一个线程所处理的大文档,因而不能马上写到索引文件中去,而是放到waitQueue中,仅仅当大文档处理完了之后才写入索引文件。 waitQueue中有一个变量nextWriteDocID表示下一个可以写入文件的ID,当付给大文档ID=4时,则nextWriteDocID也设为4,虽然后来的小文档5,6,7,8等都已处理结束,但是如下代码, WaitQueue.add(){ if (doc.docID == nextWriteDocID){ doPause() } 则把5, 6, 7, 8放入waiting队列,并且记录当前等待的文档所占用的内存大小waitingBytes。 当大文档4处理完毕后,不但写入文档4,把原来等待的文档5, 6, 7, 8也一起写入。 WaitQueue.add(){ if (doc.docID == nextWriteDocID) { writeDocument(doc); while(true) { doc = waiting[nextWriteLoc]; writeDocument(doc); } } else { ………… } doPause() } 但是这存在一个问题:当大文档很大很大,处理的很慢很慢的时候,后来的线程二可能已经处理了很多的小文档了,这些文档都是在waitQueue中,则占有了越来越多的内存,长此以往,有内存不够的危险。 因而在finishDocuments里面,在WaitQueue.add最后调用了doPause()函数 DocumentsWriter.finishDocument(){ doPause = waitQueue.add(docWriter); if (doPause) notifyAll(); } WaitQueue.doPause() { 当waitingBytes足够大的时候(为用户指定的内存使用量的10%),doPause返回true,于是后来的线程二会进入wait状态,不再处理另外的文档,而是等待线程一处理大文档结束。 当线程一处理大文档结束的时候,调用notifyAll唤醒等待他的线程。 DocumentsWriter.waitForWaitQueue() { WaitQueue.doResume() { 当waitingBytes足够小的时候,doResume返回true, 则线程二不用再wait了,可以继续处理另外的文档。 |
- 一些标志位
- int maxFieldLength:一篇文档中,一个域内可索引的最大的词(Term)数。
- int maxBufferedDeleteTerms:可缓存的最大的删除词(Term)数。当大于这个数的时候,就要写到文件中了。
此过程又包含如下三个子过程:
4.1、得到当前线程对应的文档集处理对象(DocumentsWriterThreadState)
代码为:
| DocumentsWriterThreadState state = getThreadState(doc, delTerm); |
在Lucene中,对于同一个索引文件夹,只能够有一个IndexWriter打开它,在打开后,在文件夹中,生成文件write.lock,当其他IndexWriter再试图打开此索引文件夹的时候,则会报org.apache.lucene.store.LockObtainFailedException错误。
这样就出现了这样一个问题,在同一个进程中,对同一个索引文件夹,只能有一个IndexWriter打开它,因而如果想多线程向此索引文件夹中添加文档,则必须共享一个IndexWriter,而且在以往的实现中,addDocument函数是同步的(synchronized),也即多线程的索引并不能起到提高性能的效果。
于是为了支持多线程索引,不使IndexWriter成为瓶颈,对于每一个线程都有一个相应的文档集处理对象(DocumentsWriterThreadState),这样对文档的索引过程可以多线程并行进行,从而增加索引的速度。
getThreadState函数是同步的(synchronized),DocumentsWriter有一个成员变量threadBindings,它是一个HashMap,键为线程对象(Thread.currentThread()),值为此线程对应的DocumentsWriterThreadState对象。
DocumentsWriterThreadState DocumentsWriter.getThreadState(Document doc, Term delTerm)包含如下几个过程:
- 根据当前线程对象,从HashMap中查找相应的DocumentsWriterThreadState对象,如果没找到,则生成一个新对象,并添加到HashMap中
| DocumentsWriterThreadState state = (DocumentsWriterThreadState) threadBindings.get(Thread.currentThread()); if (state == null) { …… state = new DocumentsWriterThreadState(this); …… threadBindings.put(Thread.currentThread(), state); } |
- 如果此线程对象正在用于处理上一篇文档,则等待,直到此线程的上一篇文档处理完。
| DocumentsWriter.getThreadState() { waitReady(state); state.isIdle = false; } waitReady(state) { while (!state.isIdle) {wait();} } 显然如果state.isIdle为false,则此线程等待。 在一篇文档处理之前,state.isIdle = false会被设定,而在一篇文档处理完毕之后,DocumentsWriter.finishDocument(DocumentsWriterThreadState perThread, DocWriter docWriter)中,会首先设定perThread.isIdle = true; 然后notifyAll()来唤醒等待此文档完成的线程,从而处理下一篇文档。 |
- 如果IndexWriter刚刚commit过,则新添加的文档要加入到新的段中(segment),则首先要生成新的段名。
| initSegmentName(false); --> if (segment == null) segment = writer.newSegmentName(); |
- 将此线程的文档处理对象设为忙碌:state.isIdle = false;
4.2、用得到的文档集处理对象(DocumentsWriterThreadState)处理文档
代码为:
|
DocWriter perDoc = state.consumer.processDocument(); |
每一个文档集处理对象DocumentsWriterThreadState都有一个文档及域处理对象DocFieldProcessorPerThread,它的成员函数processDocument()被调用来对文档及域进行处理。
| 线程索引链(XXXPerThread):
由于要多线程进行索引,因而每个线程都要有自己的索引链,称为线程索引链。 线程索引链同基本索引链有相似的树形结构,由基本索引链中每个层次的对象调用addThreads进行创建的,负责每个线程的对文档的处理。 DocFieldProcessorPerThread是线程索引链的源头,由DocFieldProcessor.addThreads(…)创建 DocFieldProcessorPerThread对象结构如下:
|
DocumentsWriter.DocWriter DocFieldProcessorPerThread.processDocument()包含以下几个过程:
4.2.1、开始处理当前文档
|
consumer(DocInverterPerThread).startDocument(); |
在此版的Lucene中,几乎所有的XXXPerThread的类,都有startDocument和finishDocument两个函数,因为对同一个线程,这些对象都是复用的,而非对每一篇新来的文档都创建一套,这样也提高了效率,也牵扯到数据的清理问题。一般在startDocument函数中,清理处理上篇文档遗留的数据,在finishDocument中,收集本次处理的结果数据,并返回,一直返回到DocumentsWriter.updateDocument(Document, Analyzer, Term) 然后根据条件判断是否将数据刷新到硬盘上。
4.2.2、逐个处理文档的每一个域
由于一个线程可以连续处理多个文档,而在普通的应用中,几乎每篇文档的域都是大致相同的,为每篇文档的每个域都创建一个处理对象非常低效,因而考虑到复用域处理对象DocFieldProcessorPerField,对于每一个域都有一个此对象。
那当来到一个新的域的时候,如何更快的找到此域的处理对象呢?Lucene创建了一个DocFieldProcessorPerField[] fieldHash哈希表来方便更快查找域对应的处理对象。
当处理各个域的时候,按什么顺序呢?其实是按照域名的字典顺序。因而Lucene创建了DocFieldProcessorPerField[] fields的数组来方便按顺序处理域。
因而一个域的处理对象被放在了两个地方。
对于域的处理过程如下:
4.2.2.1、首先:对于每一个域,按照域名,在fieldHash中查找域处理对象DocFieldProcessorPerField,代码如下:
|
final int hashPos = fieldName.hashCode() & hashMask;//计算哈希值 |
如果能够找到,则更新DocFieldProcessorPerField中的域信息fp.fieldInfo.update(field.isIndexed()…)
如果没有找到,则添加域到DocFieldProcessorPerThread.fieldInfos中,并创建新的DocFieldProcessorPerField,且将其加入哈希表。代码如下:
|
fp = new DocFieldProcessorPerField(this, fi); |
如果是一个新的field,则将其加入fields数组fields[fieldCount++] = fp;
并且如果是存储域的话,用StoredFieldsWriterPerThread将其写到索引中:
|
if (field.isStored()) { |
4.2.2.1.1、处理存储域的过程如下:
| StoredFieldsWriterPerThread.addField(Fieldable field, FieldInfo fieldInfo) --> localFieldsWriter.writeField(fieldInfo, field); |
FieldsWriter.writeField(FieldInfo fi, Fieldable field)代码如下:
|
请参照fdt文件的格式,则一目了然: fieldsStream.writeVInt(fi.number);//文档号 fieldsStream.writeByte(bits); //域的属性位 if (field.isCompressed()) {//对于压缩域 fieldsStream.writeVInt(len);//写长度 |
4.2.2.2、然后:对fields数组进行排序,是域按照名称排序。quickSort(fields, 0, fieldCount-1);
4.2.2.3、最后:按照排序号的顺序,对域逐个处理,此处处理的仅仅是索引域,代码如下:
|
for(int i=0;i fields[i].consumer.processFields(fields[i].fields, fields[i].fieldCount); |
域处理对象(DocFieldProcessorPerField)结构如下:
|
域索引链: 每个域也有自己的索引链,称为域索引链,每个域的索引链也有同线程索引链有相似的树形结构,由线程索引链中每个层次的每个层次的对象调用addField进行创建,负责对此域的处理。 和基本索引链及线程索引链不同的是,域索引链仅仅负责处理索引域,而不负责存储域的处理。 DocFieldProcessorPerField是域索引链的源头,对象结构如下:
|
4.2.2.3.1、处理索引域的过程如下:
DocInverterPerField.processFields(Fieldable[], int) 过程如下:
- 判断是否要形成倒排表,代码如下:
| boolean doInvert = consumer.start(fields, count); --> TermsHashPerField.start(Fieldable[], int) --> for(int i=0;i if (fields[i].isIndexed()) return true; return false; |
读到这里,大家可能会发生困惑,既然XXXPerField是对于每一个域有一个处理对象的,那为什么参数传进来的是Fieldable[]数组, 并且还有域的数目count呢?
其实这不经常用到,但必须得提一下,由上面的fieldHash的实现我们可以看到,是根据域名进行哈希的,所以准确的讲,XXXPerField并非对于每一个域有一个处理对象,而是对每一组相同名字的域有相同的处理对象。
对于同一篇文档,相同名称的域可以添加多个,代码如下:
|
doc.add(new Field("contents", "the content of the file.", Field.Store.NO, Field.Index.NOT_ANALYZED)); |
则传进来的名为"contents"的域如下:
|
fields Fieldable[2] (id=52) |
- 对传进来的同名域逐一处理,代码如下
|
for(int i=0;i final Fieldable field = fields[i]; if (field.isIndexed() && doInvert) { //仅仅对索引域进行处理 if (!field.isTokenized()) { //如果此域不分词,见(1)对不分词的域的处理 } else { //如果此域分词,见(2)对分词的域的处理 } } } |
(1) 对不分词的域的处理
(1-1) 得到域的内容,并构建单个Token形成的SingleTokenAttributeSource。因为不进行分词,因而整个域的内容算做一个Token.
String stringValue = field.stringValue(); //stringValue "200910240957"
final int valueLength = stringValue.length();
perThread.singleToken.reinit(stringValue, 0, valueLength);
对于此域唯一的一个Token有以下的属性:
- Term:文字信息。在处理过程中,此值将保存在TermAttribute的实现类实例化的对象TermAttributeImp里面。
- Offset:偏移量信息,是按字或字母的起始偏移量和终止偏移量,表明此Token在文章中的位置,多用于加亮。在处理过程中,此值将保存在OffsetAttribute的实现类实例化的对象OffsetAttributeImp里面。
在SingleTokenAttributeSource里面,有一个HashMap来保存可能用于保存属性的类名(Key,准确的讲是接口)以及保存属性信息的对象(Value):
|
singleToken DocInverterPerThread$SingleTokenAttributeSource (id=150) |
(1-2) 得到Token的各种属性信息,为索引做准备。
consumer.start(field)做的主要事情就是根据各种属性的类型来构造保存属性的对象(HashMap中有则取出,无则构造),为索引做准备。
|
consumer(TermsHashPerField).start(…) --> termAtt = fieldState.attributeSource.addAttribute(TermAttribute.class);得到的就是上述HashMap中的TermAttributeImpl --> consumer(FreqProxTermsWriterPerField).start(f); --> if (fieldState.attributeSource.hasAttribute(PayloadAttribute.class)) { payloadAttribute = fieldState.attributeSource.getAttribute(PayloadAttribute.class); --> nextPerField(TermsHashPerField).start(f); --> termAtt = fieldState.attributeSource.addAttribute(TermAttribute.class);得到的还是上述HashMap中的TermAttributeImpl --> consumer(TermVectorsTermsWriterPerField).start(f); --> if (doVectorOffsets) { offsetAttribute = fieldState.attributeSource.addAttribute(OffsetAttribute.class); |
(1-3) 将Token加入倒排表
consumer(TermsHashPerField).add();
加入倒排表的过程,无论对于分词的域和不分词的域,过程是一样的,因而放到对分词的域的解析中一起说明。
(2) 对分词的域的处理
(2-1) 构建域的TokenStream
|
final TokenStream streamValue = field.tokenStreamValue(); //用户可以在添加域的时候,应用构造函数public Field(String name, TokenStream tokenStream) 直接传进一个TokenStream过来,这样就不用另外构建一个TokenStream了。 if (streamValue != null) …… stream = docState.analyzer.reusableTokenStream(fieldInfo.name, reader); } |
此时TokenStream的各项属性值还都是空的,等待一个一个被分词后得到,此时的TokenStream对象如下:
|
stream StopFilter (id=112) |
(2-2) 得到第一个Token,并初始化此Token的各项属性信息,并为索引做准备(start)。
boolean hasMoreTokens = stream.incrementToken();//得到第一个Token
OffsetAttribute offsetAttribute = fieldState.attributeSource.addAttribute(OffsetAttribute.class);//得到偏移量属性
|
offsetAttribute OffsetAttributeImpl (id=164) |
PositionIncrementAttribute posIncrAttribute = fieldState.attributeSource.addAttribute(PositionIncrementAttribute.class);//得到位置属性
|
posIncrAttribute PositionIncrementAttributeImpl (id=129) |
consumer.start(field);//其中得到了TermAttribute属性,如果存储payload则得到PayloadAttribute属性,如果存储词向量则得到OffsetAttribute属性。
(2-3) 进行循环,不断的取下一个Token,并添加到倒排表
|
for(;;) { if (!hasMoreTokens) break; …… …… |
(2-4) 添加Token到倒排表的过程consumer(TermsHashPerField).add()
TermsHashPerField对象主要包括以下部分:
- CharBlockPool charPool; 用于存储Token的文本信息,如果不足时,从DocumentsWriter中的freeCharBlocks分配
- ByteBlockPool bytePool;用于存储freq, prox信息,如果不足时,从DocumentsWriter中的freeByteBlocks分配
- IntBlockPool intPool; 用于存储分别指向每个Token在bytePool中freq和prox信息的偏移量。如果不足时,从DocumentsWriter的freeIntBlocks分配
- TermsHashConsumerPerField consumer类型为FreqProxTermsWriterPerField,用于写freq, prox信息到缓存中。
- RawPostingList[] postingsHash = new RawPostingList[postingsHashSize];存储倒排表,每一个Term都有一个RawPostingList (PostingList),其中包含了int textStart,也即文本在charPool中的偏移量,int byteStart,即此Term的freq和prox信息在bytePool中的起始偏移量,int intStart,即此term的在intPool中的起始偏移量。
形成倒排表的过程如下:
|
//得到token的文本及文本长度 final char[] tokenText = termAtt.termBuffer();//[s, t, u, d, e, n, t, s] final int tokenTextLen = termAtt.termLength();//tokenTextLen 8 //按照token的文本计算哈希值,以便在postingsHash中找到此token对应的倒排表 int downto = tokenTextLen; int hashPos = code & postingsHashMask; //在倒排表哈希表中查找此Token,如果找到相应的位置,但是不是此Token,说明此位置存在哈希冲突,采取重新哈希rehash的方法。 p = postingsHash[hashPos]; if (p != null && !postingEquals(tokenText, tokenTextLen)) { //如果此Token之前从未出现过 if (p == null) { if (textLen1 + charPool.charUpto > DocumentsWriter.CHAR_BLOCK_SIZE) { //当charPool不足的时候,在freeCharBlocks中分配新的buffer charPool.nextBuffer(); } //从空闲的倒排表中分配新的倒排表 p = perThread.freePostings[--perThread.freePostingsCount]; //将文本复制到charPool中 final char[] text = charPool.buffer; //将倒排表放入哈希表中 postingsHash[hashPos] = p; if (numPostingInt + intPool.intUpto > DocumentsWriter.INT_BLOCK_SIZE) intPool.nextBuffer(); //当intPool不足的时候,在freeIntBlocks中分配新的buffer。 if (DocumentsWriter.BYTE_BLOCK_SIZE - bytePool.byteUpto < numPostingInt*ByteBlockPool.FIRST_LEVEL_SIZE) bytePool.nextBuffer(); //当bytePool不足的时候,在freeByteBlocks中分配新的buffer。 //此处streamCount为2,表明在intPool中,每两项表示一个词,一个是指向bytePool中freq信息偏移量的,一个是指向bytePool中prox信息偏移量的。 intUptos = intPool.buffer; p.intStart = intUptoStart + intPool.intOffset; //在bytePool中分配两个空间,一个放freq信息,一个放prox信息的。 final int upto = bytePool.newSlice(ByteBlockPool.FIRST_LEVEL_SIZE); //当Term原来没有出现过的时候,调用newTerm consumer(FreqProxTermsWriterPerField).newTerm(p); } //如果此Token之前曾经出现过,则调用addTerm。 else { intUptos = intPool.buffers[p.intStart >> DocumentsWriter.INT_BLOCK_SHIFT]; } |
(2-5) 添加新Term的过程,consumer(FreqProxTermsWriterPerField).newTerm
|
final void newTerm(RawPostingList p0) { writeProx(FreqProxTermsWriter.PostingList p, int proxCode) { termsHashPerField.writeVInt(1, proxCode<<1);//第一个参数所谓1,也就是写入此文档在intPool中的第1项——prox信息。为什么左移一位呢?是因为后面可能跟着payload信息,参照索引文件格式(1)中或然跟随规则。 } |
(2-6) 添加已有Term的过程
|
final void addTerm(RawPostingList p0) { FreqProxTermsWriter.PostingList p = (FreqProxTermsWriter.PostingList) p0; if (docState.docID != p.lastDocID) { //当文档ID变了的时候,说明上一篇文档已经处理完毕,可以写入freq信息了。 //第一个参数所谓0,也就是写入上一篇文档在intPool中的第0项——freq信息。至于信息为何这样写,参照索引文件格式(1)中的或然跟随规则,及tis文件格式。 if (1 == p.docFreq) //当文档ID不变的时候,说明此文档中这个词又出现了一次,从而freq加一,写入再次出现的位置信息,用差值。 |
(2-7) 结束处理当前域
|
consumer(TermsHashPerField).finish(); --> FreqProxTermsWriterPerField.finish() --> TermVectorsTermsWriterPerField.finish() endConsumer(NormsWriterPerField).finish(); --> norms[upto] = Similarity.encodeNorm(norm);//计算标准化因子的值。 --> docIDs[upto] = docState.docID; |
4.2.3、结束处理当前文档
final DocumentsWriter.DocWriter one = fieldsWriter(StoredFieldsWriterPerThread).finishDocument();
存储域返回结果:一个写成了二进制的存储域缓存。
|
one StoredFieldsWriter$PerDoc (id=322) |
final DocumentsWriter.DocWriter two = consumer(DocInverterPerThread).finishDocument();
--> NormsWriterPerThread.finishDocument()
--> TermsHashPerThread.finishDocument()
索引域的返回结果为null
4.3、用DocumentsWriter.finishDocument结束本次文档添加
代码:
|
DocumentsWriter.updateDocument(Document, Analyzer, Term) --> DocumentsWriter.finishDocument(DocumentsWriterThreadState, DocumentsWriter$DocWriter) --> doPause = waitQueue.add(docWriter);//有关waitQueue,在DocumentsWriter的缓存管理中已作解释 --> DocumentsWriter$WaitQueue.writeDocument(DocumentsWriter$DocWriter) --> StoredFieldsWriter$PerDoc.finish() --> fieldsWriter.flushDocument(perDoc.numStoredFields, perDoc.fdt);将存储域信息真正写入文件。 |
5、DocumentsWriter对CharBlockPool,ByteBlockPool,IntBlockPool的缓存管理
- 在索引的过程中,DocumentsWriter将词信息(term)存储在CharBlockPool中,将文档号(doc ID),词频(freq)和位置(prox)信息存储在ByteBlockPool中。
- 在ByteBlockPool中,缓存是分块(slice)分配的,块(slice)是分层次的,层次越高,此层的块越大,每一层的块大小事相同的。
- nextLevelArray表示的是当前层的下一层是第几层,可见第9层的下一层还是第9层,也就是说最高有9层。
- levelSizeArray表示每一层的块大小,第一层是5个byte,第二层是14个byte以此类推。
|
ByteBlockPool类中有以下静态变量: final static int[] nextLevelArray = {1, 2, 3, 4, 5, 6, 7, 8, 9, 9}; |
- 在ByteBlockPool中分配一个块的代码如下:
|
//此函数仅仅在upto已经是当前块的结尾的时候方才调用来分配新块。 public int allocSlice(final byte[] slice, final int upto) { //可根据块的结束符来得到块所在的层次。从而我们可以推断,每个层次的块都有不同的结束符,第1层为16,第2层位17,第3层18,依次类推。 final int level = slice[upto] & 15; //从数组总得到下一个层次及下一层块的大小。 final int newLevel = nextLevelArray[level]; final int newSize = levelSizeArray[newLevel]; // 如果当前缓存总量不够大,则从DocumentsWriter的freeByteBlocks中分配。 if (byteUpto > DocumentsWriter.BYTE_BLOCK_SIZE-newSize) nextBuffer(); final int newUpto = byteUpto; final int offset = newUpto + byteOffset; byteUpto += newSize; //当分配了新的块的时候,需要有一个指针从本块指向下一个块,使得读取此信息的时候,能够在此块读取结束后,到下一个块继续读取。 //这个指针需要4个byte,在本块中,除了结束符所占用的一个byte之外,之前的三个byte的数据都应该移到新的块中,从而四个byte连起来形成一个指针。 buffer[newUpto] = slice[upto-3]; buffer[newUpto+1] = slice[upto-2]; buffer[newUpto+2] = slice[upto-1]; // 将偏移量(也即指针)写入到连同结束符在内的四个byte slice[upto-3] = (byte) (offset >>> 24); slice[upto-2] = (byte) (offset >>> 16); slice[upto-1] = (byte) (offset >>> 8); slice[upto] = (byte) offset; // 在新的块的结尾写入新的结束符,结束符和层次的关系就是(endbyte = 16 | level) buffer[byteUpto-1] = (byte) (16|newLevel); return newUpto+3; } |
- 在ByteBlockPool中,文档号和词频(freq)信息是应用或然跟随原则写到一个块中去的,而位置信息(prox)是写入到另一个块中去的,对于同一个词,这两块的偏移量保存在IntBlockPool中。因而在IntBlockPool中,每一个词都有两个int,第0个表示docid + freq在ByteBlockPool中的偏移量,第1个表示prox在ByteBlockPool中的偏移量。
- 在写入docid + freq信息的时候,调用termsHashPerField.writeVInt(0, p.lastDocCode),第一个参数表示向此词的第0个偏移量写入;在写入prox信息的时候,调用termsHashPerField.writeVInt(1, (proxCode<<1)|1),第一个参数表示向此词的第1个偏移量写入。
- CharBlockPool是按照出现的先后顺序保存词(term)
- 在TermsHashPerField中,有一个成员变量RawPostingList[] postingsHash,为每一个term分配了一个RawPostingList,将上述三个缓存关联起来。
|
abstract class RawPostingList { final static int BYTES_SIZE = DocumentsWriter.OBJECT_HEADER_BYTES + 3*DocumentsWriter.INT_NUM_BYTE; int textStart; //此词在CharBlockPool中的偏移量,由此可以知道是哪个词。 int intStart; //此词在IntBlockPool中的偏移量,在指向的位置有两个int,一个是docid + freq信息的偏移量,一个是prox信息的偏移量。 int byteStart; //此词在ByteBlockPool中的起始偏移量 } static final class PostingList extends RawPostingList { int docFreq; // 此词在此文档中出现的次数 int lastDocID; // 上次处理完的包含此词的文档号。 int lastDocCode; // 文档号和词频按照或然跟随原则形成的编码 int lastPosition; // 上次处理完的此词的位置 } 这里需要说明的是,在IntBlockPool中保存了两个在ByteBlockPool中的偏移量,而在RawPostingList的byteStart又保存了在ByteBlockPool中的偏移量,这两者有什么区别呢? 在IntBlockPool中保存的分别指向docid+freq及prox信息在ByteBlockPool中的偏移量是主要用来写入信息的,它记录的偏移量是下一个要写入的docid+freq或者prox在ByteBlockPool中的位置,随着信息的不断写入,IntBlockPool中的两个偏移量是不断改变的,始终指向下一个可以写入的位置。 RawPostingList中byteStart主要是用来读取docid及prox信息的,当索引过程基本结束,所有的信息都写入在缓存中了,那么如何找到此词对应的文档号偏移量及位置信息,然后写到索引文件中去呢?自然是通过RawPostingList找到byteStart,然后根据byteStart在ByteBlockPool中找到docid+freq及prox信息的起始位置,从起始位置开始的两个大小为5的块,第一个就是docid+freq信息的源头,第二个就是prox信息的源头,如果源头的块中包含了所有的信息,读出来就可以了,如果源头的块中有指针,则沿着指针寻找到下一个块,从而可以找到所有的信息。 |
- 下面举一个实例来表明如果进行缓存管理的:
|
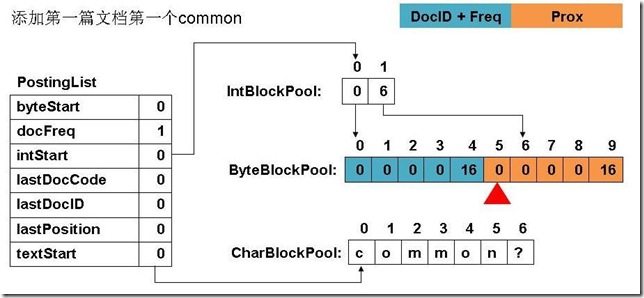
此例子中,准备添加三个文件: file01: common common common common common term file02: common common common common common term term file03: term term term common common common common common file04: term (1) 添加第一篇文档第一个common
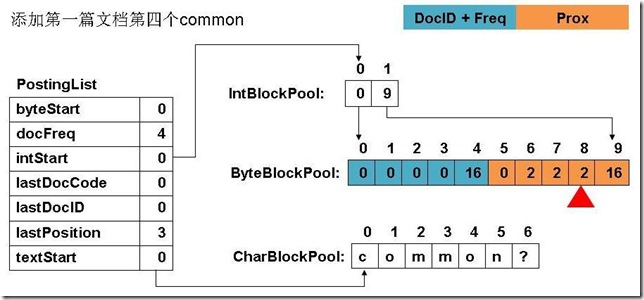
(2) 添加第四个common
(3) 添加第五个common
(4) 添加第一篇文档,第一个term
(5) 添加第二篇文档第一个common
(6) 添加第二篇文档第一个term
(7) 添加第三篇文档的第一个term
(8) 添加第三篇文档第二个term
(9) 添加第三篇文档第四个common
(10) 添加第三篇文档的第五个common
(11) 添加第四篇文档的第一个term
(12) 最终PostingList, CharBlockPool, IntBlockPool,ByteBlockPool的关系如下图:
|
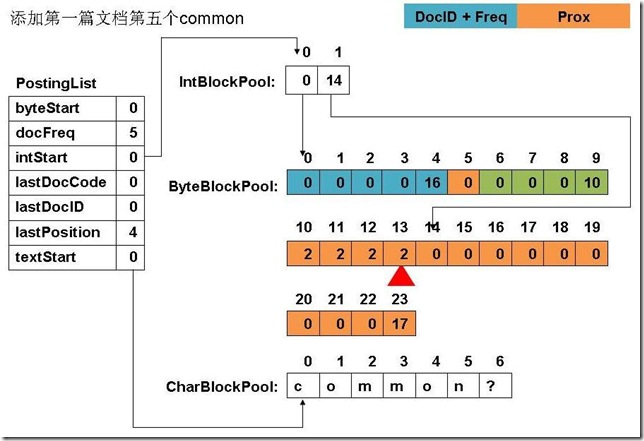
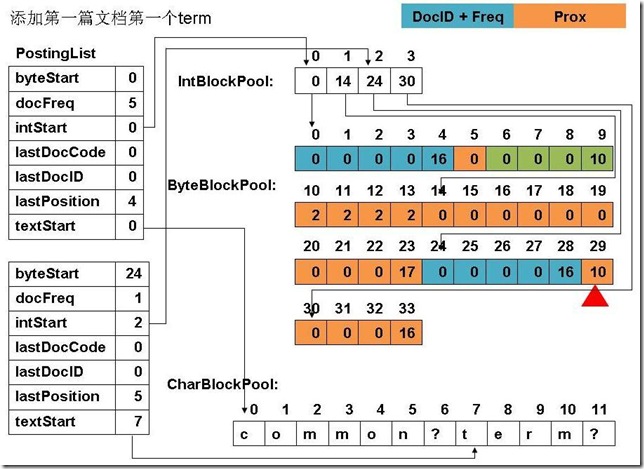
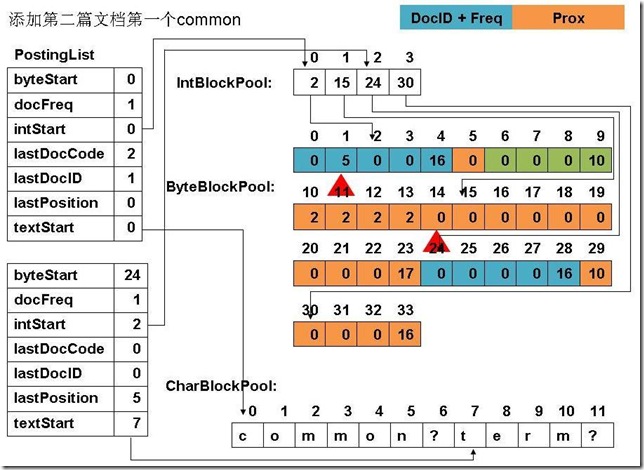

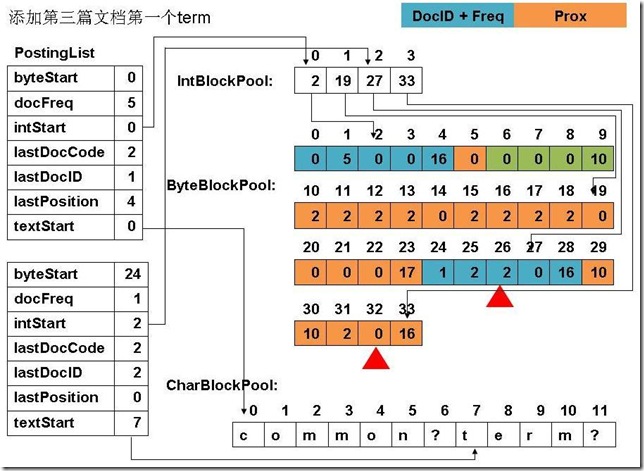
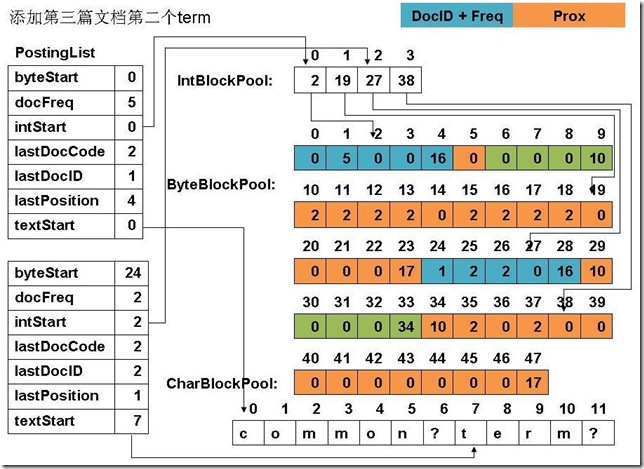
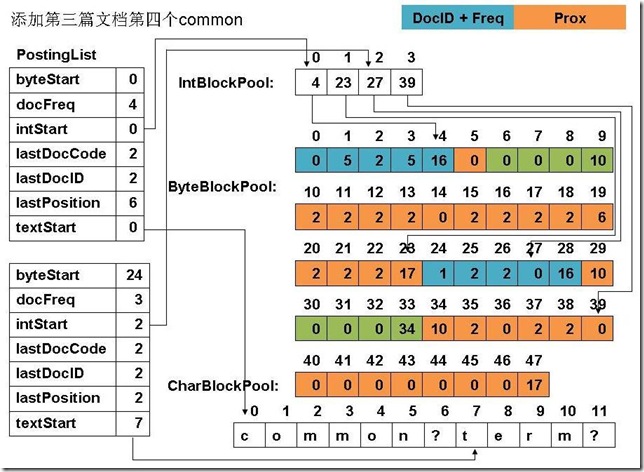
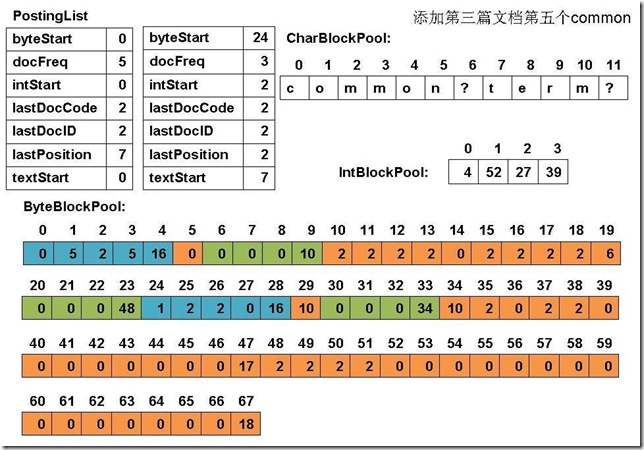
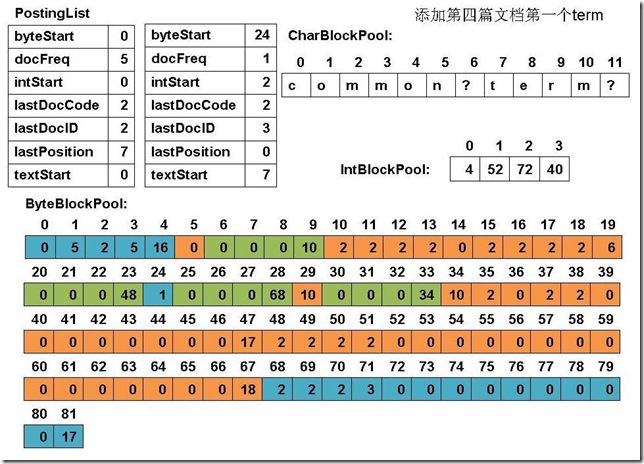
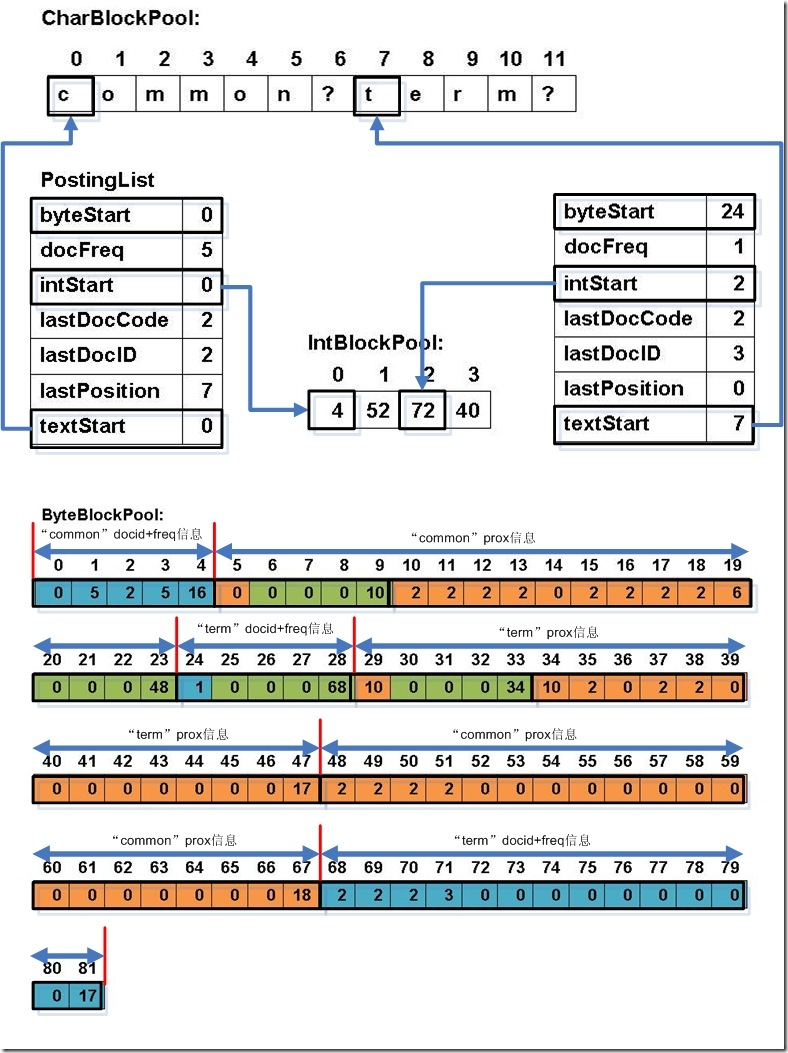
6、关闭IndexWriter对象
代码:
|
writer.close(); --> IndexWriter.closeInternal(boolean) --> (1) 将索引信息由内存写入磁盘: flush(waitForMerges, true, true); |
对段的合并将在后面的章节进行讨论,此处仅仅讨论将索引信息由写入磁盘的过程。
代码:
|
IndexWriter.flush(boolean triggerMerge, boolean flushDocStores, boolean flushDeletes) --> IndexWriter.doFlush(boolean flushDocStores, boolean flushDeletes) --> IndexWriter.doFlushInternal(boolean flushDocStores, boolean flushDeletes) |
将索引写入磁盘包括以下几个过程:
- 得到要写入的段名:String segment = docWriter.getSegment();
- DocumentsWriter将缓存的信息写入段:docWriter.flush(flushDocStores);
- 生成新的段信息对象:newSegment = new SegmentInfo(segment, flushedDocCount, directory, false, true, docStoreOffset, docStoreSegment, docStoreIsCompoundFile, docWriter.hasProx());
- 准备删除文档:docWriter.pushDeletes();
- 生成cfs段:docWriter.createCompoundFile(segment);
- 删除文档:applyDeletes();
6.1、得到要写入的段名
代码:
|
SegmentInfo newSegment = null; final int numDocs = docWriter.getNumDocsInRAM();//文档总数 String docStoreSegment = docWriter.getDocStoreSegment();//存储域和词向量所要要写入的段名,"_0" int docStoreOffset = docWriter.getDocStoreOffset();//存储域和词向量要写入的段中的偏移量 String segment = docWriter.getSegment();//段名,"_0" |
在Lucene的索引文件结构一章做过详细介绍,存储域和词向量可以和索引域存储在不同的段中。
6.2、将缓存的内容写入段
代码:
|
flushedDocCount = docWriter.flush(flushDocStores); |
此过程又包含以下两个阶段;
- 按照基本索引链关闭存储域和词向量信息
- 按照基本索引链的结构将索引结果写入段
6.2.1、按照基本索引链关闭存储域和词向量信息
代码为:
|
closeDocStore(); flushState.numDocsInStore = 0; |
其主要是根据基本索引链结构,关闭存储域和词向量信息:
- consumer(DocFieldProcessor).closeDocStore(flushState);
- consumer(DocInverter).closeDocStore(state);
- consumer(TermsHash).closeDocStore(state);
- consumer(FreqProxTermsWriter).closeDocStore(state);
- if (nextTermsHash != null) nextTermsHash.closeDocStore(state);
- consumer(TermVectorsTermsWriter).closeDocStore(state);
- endConsumer(NormsWriter).closeDocStore(state);
- consumer(TermsHash).closeDocStore(state);
- fieldsWriter(StoredFieldsWriter).closeDocStore(state);
- consumer(DocInverter).closeDocStore(state);
其中有实质意义的是以下两个closeDocStore:
- 词向量的关闭:TermVectorsTermsWriter.closeDocStore(SegmentWriteState)
|
void closeDocStore(final SegmentWriteState state) throws IOException { if (tvx != null) { |
- 存储域的关闭:StoredFieldsWriter.closeDocStore(SegmentWriteState)
|
public void closeDocStore(SegmentWriteState state) throws IOException { //关闭fdx, fdt写入流 fieldsWriter.close(); //记录写入的文件名 |
6.2.2、按照基本索引链的结构将索引结果写入段
代码为:
|
consumer(DocFieldProcessor).flush(threads, flushState); //回收fieldHash,以便用于下一轮的索引,为提高效率,索引链中的对象是被复用的。 Map> childThreadsAndFields = new HashMap>(); //写入存储域 --> fieldsWriter(StoredFieldsWriter).flush(state); //写入索引域 --> consumer(DocInverter).flush(childThreadsAndFields, state); //写入域元数据信息,并记录写入的文件名,以便以后生成cfs文件 --> final String fileName = state.segmentFileName(IndexFileNames.FIELD_INFOS_EXTENSION); --> fieldInfos.write(state.directory, fileName); --> state.flushedFiles.add(fileName); |
此过程也是按照基本索引链来的:
- consumer(DocFieldProcessor).flush(…);
- consumer(DocInverter).flush(…);
- consumer(TermsHash).flush(…);
- consumer(FreqProxTermsWriter).flush(…);
- if (nextTermsHash != null) nextTermsHash.flush(…);
- consumer(TermVectorsTermsWriter).flush(…);
- endConsumer(NormsWriter).flush(…);
- consumer(TermsHash).flush(…);
- fieldsWriter(StoredFieldsWriter).flush(…);
- consumer(DocInverter).flush(…);
6.2.2.1、写入存储域
代码为:
|
StoredFieldsWriter.flush(SegmentWriteState state) { |
从代码中可以看出,是写入fdx, fdt两个文件,但是在上述的closeDocStore已经写入了,并且把state.numDocsInStore置零,fieldsWriter设为null,在这里其实什么也不做。
6.2.2.2、写入索引域
代码为:
|
DocInverter.flush(Map>, SegmentWriteState) //写入倒排表及词向量信息 --> consumer(TermsHash).flush(childThreadsAndFields, state); //写入标准化因子 --> endConsumer(NormsWriter).flush(endChildThreadsAndFields, state); |
6.2.2.2.1、写入倒排表及词向量信息
代码为:
|
TermsHash.flush(Map>, SegmentWriteState) //写入倒排表信息 --> consumer(FreqProxTermsWriter).flush(childThreadsAndFields, state); //回收RawPostingList --> shrinkFreePostings(threadsAndFields, state); //写入词向量信息 --> if (nextTermsHash != null) nextTermsHash.flush(nextThreadsAndFields, state); --> consumer(TermVectorsTermsWriter).flush(childThreadsAndFields, state); |
6.2.2.2.1.1、写入倒排表信息
代码为:
|
FreqProxTermsWriter.flush(Map Collection>, SegmentWriteState) (a) 所有域按名称排序,使得同名域能够一起处理 Collections.sort(allFields); final int numAllFields = allFields.size(); (b) 生成倒排表的写对象 final FormatPostingsFieldsConsumer consumer = new FormatPostingsFieldsWriter(state, fieldInfos); int start = 0; (c) 对于每一个域 while(start < numAllFields) { (c-1) 找出所有的同名域 final FieldInfo fieldInfo = allFields.get(start).fieldInfo; final String fieldName = fieldInfo.name; int end = start+1; while(end < numAllFields && allFields.get(end).fieldInfo.name.equals(fieldName)) end++; FreqProxTermsWriterPerField[] fields = new FreqProxTermsWriterPerField[end-start]; for(int i=start;i fields[i-start] = allFields.get(i); fieldInfo.storePayloads |= fields[i-start].hasPayloads; } (c-2) 将同名域的倒排表添加到文件 appendPostings(fields, consumer); (c-3) 释放空间 for(int i=0;i TermsHashPerField perField = fields[i].termsHashPerField; int numPostings = perField.numPostings; perField.reset(); perField.shrinkHash(numPostings); fields[i].reset(); } start = end; } (d) 关闭倒排表的写对象 consumer.finish(); |
(b) 生成倒排表的写对象
代码为:
| public FormatPostingsFieldsWriter(SegmentWriteState state, FieldInfos fieldInfos) throws IOException { dir = state.directory; segment = state.segmentName; totalNumDocs = state.numDocs; this.fieldInfos = fieldInfos; //用于写tii,tis termsOut = new TermInfosWriter(dir, segment, fieldInfos, state.termIndexInterval); //用于写freq, prox的跳表 skipListWriter = new DefaultSkipListWriter(termsOut.skipInterval, termsOut.maxSkipLevels, totalNumDocs, null, null); //记录写入的文件名, state.flushedFiles.add(state.segmentFileName(IndexFileNames.TERMS_EXTENSION)); state.flushedFiles.add(state.segmentFileName(IndexFileNames.TERMS_INDEX_EXTENSION)); //用以上两个写对象,按照一定的格式写入段 termsWriter = new FormatPostingsTermsWriter(state, this); } |
对象结构如下:
| consumer FormatPostingsFieldsWriter (id=119) //用于处理一个域 dir SimpleFSDirectory (id=126) //目标索引文件夹 totalNumDocs 8 //文档总数 fieldInfos FieldInfos (id=70) //域元数据信息 segment "_0" //段名 skipListWriter DefaultSkipListWriter (id=133) //freq, prox中跳表的写对象 termsOut TermInfosWriter (id=125) //tii, tis文件的写对象 termsWriter FormatPostingsTermsWriter (id=135) //用于添加词(Term) currentTerm null currentTermStart 0 fieldInfo null freqStart 0 proxStart 0 termBuffer null termsOut TermInfosWriter (id=125) docsWriter FormatPostingsDocsWriter (id=139) //用于写入此词的docid, freq信息 df 0 fieldInfo null freqStart 0 lastDocID 0 omitTermFreqAndPositions false out SimpleFSDirectory$SimpleFSIndexOutput (id=144) skipInterval 16 skipListWriter DefaultSkipListWriter (id=133) storePayloads false termInfo TermInfo (id=151) totalNumDocs 8 posWriter FormatPostingsPositionsWriter (id=146) //用于写入此词在此文档中的位置信息 lastPayloadLength -1 lastPosition 0 omitTermFreqAndPositions false out SimpleFSDirectory$SimpleFSIndexOutput (id=157) parent FormatPostingsDocsWriter (id=139) storePayloads false |
- FormatPostingsFieldsWriter.addField(FieldInfo field)用于添加索引域信息,其返回FormatPostingsTermsConsumer用于添加词信息
- FormatPostingsTermsConsumer.addTerm(char[] text, int start)用于添加词信息,其返回FormatPostingsDocsConsumer用于添加freq信息
- FormatPostingsDocsConsumer.addDoc(int docID, int termDocFreq)用于添加freq信息,其返回FormatPostingsPositionsConsumer用于添加prox信息
- FormatPostingsPositionsConsumer.addPosition(int position, byte[] payload, int payloadOffset, int payloadLength)用于添加prox信息
(c-2) 将同名域的倒排表添加到文件
代码为:
|
FreqProxTermsWriter.appendPostings(FreqProxTermsWriterPerField[], FormatPostingsFieldsConsumer) { int numFields = fields.length; final FreqProxFieldMergeState[] mergeStates = new FreqProxFieldMergeState[numFields]; for(int i=0;i FreqProxFieldMergeState fms = mergeStates[i] = new FreqProxFieldMergeState(fields[i]); boolean result = fms.nextTerm(); //对所有的域,取第一个词(Term) } (1) 添加此域,虽然有多个域,但是由于是同名域,只取第一个域的信息即可。返回的是用于添加此域中的词的对象。 final FormatPostingsTermsConsumer termsConsumer = consumer.addField(fields[0].fieldInfo); FreqProxFieldMergeState[] termStates = new FreqProxFieldMergeState[numFields]; final boolean currentFieldOmitTermFreqAndPositions = fields[0].fieldInfo.omitTermFreqAndPositions; (2) 此while循环是遍历每一个尚有未处理的词的域,依次按照词典顺序处理这些域所包含的词。当一个域中的所有的词都被处理过后,则numFields减一,并从mergeStates数组中移除此域。直到所有的域的所有的词都处理完毕,方才退出此循环。 while(numFields > 0) { (2-1) 找出所有域中按字典顺序的下一个词。可能多个同名域中,都包含同一个term,因而要遍历所有的numFields,得到所有的域里的下一个词,numToMerge即为有多少个域包含此词。 termStates[0] = mergeStates[0]; int numToMerge = 1; for(int i=1;i final char[] text = mergeStates[i].text; final int textOffset = mergeStates[i].textOffset; final int cmp = compareText(text, textOffset, termStates[0].text, termStates[0].textOffset); if (cmp < 0) { termStates[0] = mergeStates[i]; numToMerge = 1; } else if (cmp == 0) termStates[numToMerge++] = mergeStates[i]; } (2-2) 添加此词,返回FormatPostingsDocsConsumer用于添加文档号(doc ID)及词频信息(freq) final FormatPostingsDocsConsumer docConsumer = termsConsumer.addTerm(termStates[0].text, termStates[0].textOffset); (2-3) 由于共numToMerge个域都包含此词,每个词都有一个链表的文档号表示包含这些词的文档。此循环遍历所有的包含此词的域,依次按照从小到大的循序添加包含此词的文档号及词频信息。当一个域中对此词的所有文档号都处理过了,则numToMerge减一,并从termStates数组中移除此域。当所有包含此词的域的所有文档号都处理过了,则结束此循环。 while(numToMerge > 0) { (2-3-1) 找出最小的文档号 FreqProxFieldMergeState minState = termStates[0]; for(int i=1;i if (termStates[i].docID < minState.docID) minState = termStates[i]; final int termDocFreq = minState.termFreq; (2-3-2) 添加文档号及词频信息,并形成跳表,返回FormatPostingsPositionsConsumer用于添加位置(prox)信息 final FormatPostingsPositionsConsumer posConsumer = docConsumer.addDoc(minState.docID, termDocFreq); //ByteSliceReader是用于读取bytepool中的prox信息的。 final ByteSliceReader prox = minState.prox; if (!currentFieldOmitTermFreqAndPositions) { int position = 0; (2-3-3) 此循环对包含此词的文档,添加位置信息 for(int j=0;j final int code = prox.readVInt(); position += code >> 1; final int payloadLength; // 如果此位置有payload信息,则从bytepool中读出,否则设为零。 if ((code & 1) != 0) { payloadLength = prox.readVInt(); if (payloadBuffer == null || payloadBuffer.length < payloadLength) payloadBuffer = new byte[payloadLength]; prox.readBytes(payloadBuffer, 0, payloadLength); } else payloadLength = 0; //添加位置(prox)信息 posConsumer.addPosition(position, payloadBuffer, 0, payloadLength); } posConsumer.finish(); } (2-3-4) 判断退出条件,上次选中的域取得下一个文档号,如果没有,则说明此域包含此词的文档已经处理完毕,则从termStates中删除此域,并将numToMerge减一。然后此域取得下一个词,当循环到(2)的时候,表明此域已经开始处理下一个词。如果没有下一个词,说明此域中的所有的词都处理完毕,则从mergeStates中删除此域,并将numFields减一,当numFields为0的时候,循环(2)也就结束了。 if (!minState.nextDoc()) {//获得下一个docid //如果此域包含此词的文档已经没有下一篇docid,则从数组termStates中移除,numToMerge减一。 int upto = 0; for(int i=0;i if (termStates[i] != minState) termStates[upto++] = termStates[i]; numToMerge--; //此域则取下一个词(term),在循环(2)处来参与下一个词的合并 if (!minState.nextTerm()) { //如果此域没有下一个词了,则此域从数组mergeStates中移除,numFields减一。 upto = 0; for(int i=0;i if (mergeStates[i] != minState) mergeStates[upto++] = mergeStates[i]; numFields--; } } } (2-4) 经过上面的过程,docid和freq信息虽已经写入段文件,而跳表信息并没有写到文件中,而是写入skip buffer里面了,此处真正写入文件。并且词典(tii, tis)也应该写入文件。 docConsumer(FormatPostingsDocsWriter).finish(); } termsConsumer.finish(); } |
(2-3-4) 获得下一篇文档号代码如下:
|
public boolean nextDoc() {//如何获取下一个docid if (freq.eof()) {//如果bytepool中的freq信息已经读完 if (p.lastDocCode != -1) {//由上述缓存管理,PostingList里面还存着最后一篇文档的文档号及词频信息,则将最后一篇文档返回 docID = p.lastDocID; if (!field.omitTermFreqAndPositions) termFreq = p.docFreq; p.lastDocCode = -1; return true; } else return false;//没有下一篇文档 } final int code = freq.readVInt();//如果bytepool中的freq信息尚未读完 if (field.omitTermFreqAndPositions) docID += code; else { //读出文档号及词频信息。 docID += code >>> 1; if ((code & 1) != 0) termFreq = 1; else termFreq = freq.readVInt(); } return true; } |
(2-3-2) 添加文档号及词频信息代码如下:
|
FormatPostingsPositionsConsumer FormatPostingsDocsWriter.addDoc(int docID, int termDocFreq) { final int delta = docID - lastDocID; //当文档数量达到skipInterval倍数的时候,添加跳表项。 if ((++df % skipInterval) == 0) { skipListWriter.setSkipData(lastDocID, storePayloads, posWriter.lastPayloadLength); skipListWriter.bufferSkip(df); } lastDocID = docID; if (omitTermFreqAndPositions) out.writeVInt(delta); else if (1 == termDocFreq) out.writeVInt((delta<<1) | 1); else { //写入文档号及词频信息。 out.writeVInt(delta<<1); out.writeVInt(termDocFreq); } return posWriter; } |
(2-3-3) 添加位置信息:
|
FormatPostingsPositionsWriter.addPosition(int position, byte[] payload, int payloadOffset, int payloadLength) { final int delta = position - lastPosition; lastPosition = position; if (storePayloads) { //保存位置及payload信息 if (payloadLength != lastPayloadLength) { lastPayloadLength = payloadLength; out.writeVInt((delta<<1)|1); out.writeVInt(payloadLength); } else out.writeVInt(delta << 1); if (payloadLength > 0) out.writeBytes(payload, payloadLength); } else out.writeVInt(delta); } |
(2-4) 将跳表和词典(tii, tis)写入文件
|
FormatPostingsDocsWriter.finish() { //将跳表缓存写入文件 long skipPointer = skipListWriter.writeSkip(out); if (df > 0) { //将词典(terminfo)写入tii,tis文件 parent.termsOut(TermInfosWriter).add(fieldInfo.number, utf8.result, utf8.length, termInfo); } } |
将跳表缓存写入文件:
|
DefaultSkipListWriter(MultiLevelSkipListWriter).writeSkip(IndexOutput) { long skipPointer = output.getFilePointer(); if (skipBuffer == null || skipBuffer.length == 0) return skipPointer; //正如我们在索引文件格式中分析的那样, 高层在前,低层在后,除最低层外,其他的层都有长度保存。 for (int level = numberOfSkipLevels - 1; level > 0; level--) { long length = skipBuffer[level].getFilePointer(); if (length > 0) { output.writeVLong(length); skipBuffer[level].writeTo(output); } } //写入最低层 skipBuffer[0].writeTo(output); return skipPointer; } |
将词典(terminfo)写入tii,tis文件:
- tii文件是tis文件的类似跳表的东西,是在tis文件中每隔indexInterval个词提取出一个词放在tii文件中,以便很快的查找到词。
- 因而TermInfosWriter类型中有一个成员变量other也是TermInfosWriter类型的,还有一个成员变量isIndex来表示此对象是用来写tii文件的还是用来写tis文件的。
- 如果一个TermInfosWriter对象的isIndex=false则,它是用来写tis文件的,它的other指向的是用来写tii文件的TermInfosWriter对象
- 如果一个TermInfosWriter对象的isIndex=true则,它是用来写tii文件的,它的other指向的是用来写tis文件的TermInfosWriter对象
|
TermInfosWriter.add (int fieldNumber, byte[] termBytes, int termBytesLength, TermInfo ti) { //如果词的总数是indexInterval的倍数,则应该写入tii文件 if (!isIndex && size % indexInterval == 0) other.add(lastFieldNumber, lastTermBytes, lastTermBytesLength, lastTi); //将词写入tis文件 writeTerm(fieldNumber, termBytes, termBytesLength); output.writeVInt(ti.docFreq); // write doc freq output.writeVLong(ti.freqPointer - lastTi.freqPointer); // write pointers output.writeVLong(ti.proxPointer - lastTi.proxPointer); if (ti.docFreq >= skipInterval) { output.writeVInt(ti.skipOffset); } if (isIndex) { output.writeVLong(other.output.getFilePointer() - lastIndexPointer); lastIndexPointer = other.output.getFilePointer(); // write pointer } lastFieldNumber = fieldNumber; lastTi.set(ti); size++; } |
6.2.2.2.1.2、写入词向量信息
代码为:
|
TermVectorsTermsWriter.flush (Map> if (tvx != null) { if (state.numDocsInStore > 0) fill(state.numDocsInStore - docWriter.getDocStoreOffset()); tvx.flush(); tvd.flush(); tvf.flush(); } for (Map.Entry> entry : for (final TermsHashConsumerPerField field : entry.getValue() ) { TermVectorsTermsWriterPerField perField = (TermVectorsTermsWriterPerField) field; perField.termsHashPerField.reset(); perField.shrinkHash(); } TermVectorsTermsWriterPerThread perThread = (TermVectorsTermsWriterPerThread) entry.getKey(); perThread.termsHashPerThread.reset(true); } } |
从代码中可以看出,是写入tvx, tvd, tvf三个文件,但是在上述的closeDocStore已经写入了,并且把tvx设为null,在这里其实什么也不做,仅仅是清空postingsHash,以便进行下一轮索引时重用此对象。
6.2.2.2.2、写入标准化因子
代码为:
|
NormsWriter.flush(Map> threadsAndFields, SegmentWriteState state) { final Map> byField = new HashMap>(); for (final Map.Entry> entry : //遍历所有的域,将同名域对应的NormsWriterPerField放到同一个链表中。 final Collection fields = entry.getValue(); final Iterator fieldsIt = fields.iterator(); while (fieldsIt.hasNext()) { final NormsWriterPerField perField = (NormsWriterPerField) fieldsIt.next(); List l = byField.get(perField.fieldInfo); if (l == null) { l = new ArrayList(); byField.put(perField.fieldInfo, l); } l.add(perField); } //记录写入的文件名,方便以后生成cfs文件。 final String normsFileName = state.segmentName + "." + IndexFileNames.NORMS_EXTENSION; state.flushedFiles.add(normsFileName); IndexOutput normsOut = state.directory.createOutput(normsFileName); try { //写入nrm文件头 normsOut.writeBytes(SegmentMerger.NORMS_HEADER, 0, SegmentMerger.NORMS_HEADER.length); final int numField = fieldInfos.size(); int normCount = 0; //对每一个域进行处理 for(int fieldNumber=0;fieldNumber final FieldInfo fieldInfo = fieldInfos.fieldInfo(fieldNumber); //得到同名域的链表 List toMerge = byField.get(fieldInfo); int upto = 0; if (toMerge != null) { final int numFields = toMerge.size(); normCount++; final NormsWriterPerField[] fields = new NormsWriterPerField[numFields]; int[] uptos = new int[numFields]; for(int j=0;j fields[j] = toMerge.get(j); int numLeft = numFields; //处理同名的多个域 while(numLeft > 0) { //得到所有的同名域中最小的文档号 int minLoc = 0; int minDocID = fields[0].docIDs[uptos[0]]; for(int j=1;j final int docID = fields[j].docIDs[uptos[j]]; if (docID < minDocID) { minDocID = docID; minLoc = j; } } // 在nrm文件中,每一个文件都有一个位置,没有设定的,放入默认值 for (;upto<minDocID;upto++) normsOut.writeByte(defaultNorm); //写入当前的nrm值 normsOut.writeByte(fields[minLoc].norms[uptos[minLoc]]); (uptos[minLoc])++; upto++; //如果当前域的文档已经处理完毕,则numLeft减一,归零时推出循环。 if (uptos[minLoc] == fields[minLoc].upto) { fields[minLoc].reset(); if (minLoc != numLeft-1) { fields[minLoc] = fields[numLeft-1]; uptos[minLoc] = uptos[numLeft-1]; } numLeft--; } } // 对所有的未设定nrm值的文档写入默认值。 for(;upto normsOut.writeByte(defaultNorm); } else if (fieldInfo.isIndexed && !fieldInfo.omitNorms) { normCount++; // Fill entire field with default norm: for(;upto normsOut.writeByte(defaultNorm); } } } finally { normsOut.close(); } } |
6.2.2.3、写入域元数据
代码为:
|
FieldInfos.write(IndexOutput) { output.writeVInt(CURRENT_FORMAT); output.writeVInt(size()); for (int i = 0; i < size(); i++) { FieldInfo fi = fieldInfo(i); byte bits = 0x0; if (fi.isIndexed) bits |= IS_INDEXED; if (fi.storeTermVector) bits |= STORE_TERMVECTOR; if (fi.storePositionWithTermVector) bits |= STORE_POSITIONS_WITH_TERMVECTOR; if (fi.storeOffsetWithTermVector) bits |= STORE_OFFSET_WITH_TERMVECTOR; if (fi.omitNorms) bits |= OMIT_NORMS; if (fi.storePayloads) bits |= STORE_PAYLOADS; if (fi.omitTermFreqAndPositions) bits |= OMIT_TERM_FREQ_AND_POSITIONS; output.writeString(fi.name); output.writeByte(bits); } } |
此处基本就是按照fnm文件的格式写入的。
6.3、生成新的段信息对象
代码:
|
newSegment = new SegmentInfo(segment, flushedDocCount, directory, false, true, docStoreOffset, docStoreSegment, docStoreIsCompoundFile, docWriter.hasProx()); segmentInfos.add(newSegment); |
6.4、准备删除文档
代码:
|
docWriter.pushDeletes(); --> deletesFlushed.update(deletesInRAM); |
此处将deletesInRAM全部加到deletesFlushed中,并把deletesInRAM清空。原因上面已经阐明。
6.5、生成cfs段
代码:
|
docWriter.createCompoundFile(segment); newSegment.setUseCompoundFile(true); |
代码为:
|
DocumentsWriter.createCompoundFile(String segment) { CompoundFileWriter cfsWriter = new CompoundFileWriter(directory, segment + "." + IndexFileNames.COMPOUND_FILE_EXTENSION); //将上述中记录的文档名全部加入cfs段的写对象。 for (final String flushedFile : flushState.flushedFiles) cfsWriter.addFile(flushedFile); cfsWriter.close(); } |
6.6、删除文档
代码:
|
applyDeletes(); |
代码为:
|
boolean applyDeletes(SegmentInfos infos) { if (!hasDeletes()) return false; final int infosEnd = infos.size(); int docStart = 0; boolean any = false; for (int i = 0; i < infosEnd; i++) { assert infos.info(i).dir == directory; SegmentReader reader = writer.readerPool.get(infos.info(i), false); try { any |= applyDeletes(reader, docStart); docStart += reader.maxDoc(); } finally { writer.readerPool.release(reader); } } deletesFlushed.clear(); return any; } |
- Lucene删除文档可以用reader,也可以用writer,但是归根结底还是用reader来删除的。
- reader的删除有以下三种方式:
- 按照词删除,删除所有包含此词的文档。
- 按照文档号删除。
- 按照查询对象删除,删除所有满足此查询的文档。
- 但是这三种方式归根结底还是按照文档号删除,也就是写.del文件的过程。
|
private final synchronized boolean applyDeletes(IndexReader reader, int docIDStart) throws CorruptIndexException, IOException { final int docEnd = docIDStart + reader.maxDoc(); boolean any = false; //按照词删除,删除所有包含此词的文档。 TermDocs docs = reader.termDocs(); try { for (Entry entry: deletesFlushed.terms.entrySet()) { Term term = entry.getKey(); docs.seek(term); int limit = entry.getValue().getNum(); while (docs.next()) { int docID = docs.doc(); if (docIDStart+docID >= limit) break; reader.deleteDocument(docID); any = true; } } } finally { docs.close(); } //按照文档号删除。 for (Integer docIdInt : deletesFlushed.docIDs) { int docID = docIdInt.intValue(); if (docID >= docIDStart && docID < docEnd) { reader.deleteDocument(docID-docIDStart); any = true; } } //按照查询对象删除,删除所有满足此查询的文档。 IndexSearcher searcher = new IndexSearcher(reader); for (Entry entry : deletesFlushed.queries.entrySet()) { Query query = entry.getKey(); int limit = entry.getValue().intValue(); Weight weight = query.weight(searcher); Scorer scorer = weight.scorer(reader, true, false); if (scorer != null) { while(true) { int doc = scorer.nextDoc(); if (((long) docIDStart) + doc >= limit) break; reader.deleteDocument(doc); any = true; } } } searcher.close(); return any; } |
Lucene学习总结之四:Lucene索引过程分析 2014-06-25 14:18 884人阅读 评论(0) 收藏的更多相关文章
- Lucene学习总结之五:Lucene段合并(merge)过程分析 2014-06-25 14:20 537人阅读 评论(0) 收藏
一.段合并过程总论 IndexWriter中与段合并有关的成员变量有: HashSet<SegmentInfo> mergingSegments = new HashSet<Segm ...
- Lucene学习总结之六:Lucene打分公式的数学推导 2014-06-25 14:20 384人阅读 评论(0) 收藏
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下.因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数. Lucene ...
- Lucene学习总结之二:Lucene的总体架构 2014-06-25 14:12 622人阅读 评论(0) 收藏
Lucene总的来说是: 一个高效的,可扩展的,全文检索库. 全部用Java实现,无须配置. 仅支持纯文本文件的索引(Indexing)和搜索(Search). 不负责由其他格式的文件抽取纯文本文件, ...
- Lucene学习总结之一:全文检索的基本原理 2014-06-25 14:11 666人阅读 评论(0) 收藏
一.总论 根据http://lucene.apache.org/java/docs/index.html 定义: Lucene 是一个高效的,基于Java 的全文检索库. 所以在了解Lucene之前要 ...
- Lucene学习总结之三:Lucene的索引文件格式(1) 2014-06-25 14:15 1124人阅读 评论(0) 收藏
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- winform datagridview如何获取索引 分类: DataGridView 2014-04-11 13:42 216人阅读 评论(0) 收藏
datagridview.CurrentCell.RowIndex; 是当前活动的单元格的行的索引 datagridview.SelectedRows ; ...
- javascript闭包获取table中tr的索引 分类: JavaScript 2015-05-04 15:10 793人阅读 评论(0) 收藏
使用javascript闭包获取table标签中tr的索引 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN& ...
- 使用Broadcast实现android组件之间的通信 分类: android 学习笔记 2015-07-09 14:16 110人阅读 评论(0) 收藏
android组件之间的通信有多种实现方式,Broadcast就是其中一种.在activity和fragment之间的通信,broadcast用的更多本文以一个activity为例. 效果如图: 布局 ...
- ubuntu权限管理常用命令 分类: linux ubuntu 学习笔记 2015-07-05 14:15 77人阅读 评论(0) 收藏
1.chmod 第一种方式 chomd [{ugoa}{+-=}{rwx}] [文件或者目录] u 代表该文件所属用户 g 代表该文件所属用户组 o 代表访客 a 代表所有用户 +-=分别表示增加权限 ...
随机推荐
- iOS应用笔记之git的本地使用
什么是git (1)什么是git >git是一个 "分布式"的版本号控制工具 >git的作者是Linux之父:Linus Benedict Torvalds,当初开发g ...
- Linux网络编程--字节序
1 .谈到字节序,那么会有朋友问什么是字节序 非常easy:[比如一个16位的整数.由2个字节组成,8位为一字节,有的系统会将高字节放在内存低的地址上,有的则将低字节放在内存高的地址上,所以存在字节序 ...
- 控制面板项 .cpl 文件说明
控制面板项 .cpl 文件说明 appwiz.cpl 程序和功能.卸载或更改程序 bthprops.cpl 蓝牙控制面板 desk.cpl ...
- [BZOJ1672][Usaco2005 Dec]Cleaning Shifts 清理牛棚 线段树优化DP
链接 题意:给你一些区间,每个区间都有一个花费,求覆盖区间 \([S,T]\) 的最小花费 题解 先将区间排序 设 \(f[i]\) 表示决策到第 \(i\) 个区间,覆盖满 \(S\dots R[i ...
- sql server存储过程调用C#编写的DLL文件
新建C#类库,编译. 引用 using Microsoft.SqlServer.Server; 方法 [SqlFunction]public static int GenerateTxt(){ ... ...
- popover弹出框
<style> #view{width: 300px;height: 200px;border: 1px solid red;} </style> 以上是为了viewport更 ...
- FineUI 页面跳转
要加 EnableAjax=false; <f:Button ID="btn1" EnableAjax="false" OnClick="btn ...
- 设计模式六大原则(六): 开闭原则(Open Closed Principle)
定义: 一个软件实体如类.模块和函数应该对扩展开放,对修改关闭. 问题由来: 在软件的生命周期内,因为变化.升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不 ...
- what happens when changing the DOM via innerHTML
what happens when changing the DOM via innerHTML
- 洛谷——P1096 Hanoi双塔问题
https://www.luogu.org/problem/show?pid=1096 题目描述 给定A.B.C三根足够长的细柱,在A柱上放有2n个中间有孔的圆盘,共有n个不同的尺寸,每个尺寸都有两个 ...