flume+flume+kafka消息传递+storm消费
通过flume收集其他机器上flume的监测数据,发送到本机的kafka进行消费。
环境:slave中安装flume,master中安装flume+kafka(这里用两台虚拟机,也可以用三台以上)
masterIP 192.168.83.128 slaveIP 192.168.83.129
通过监控test.log文件的变化,收集变化信息发送到主机的flume中,再发送到kafka中进行消费
1、配置slave1在flume中配置conf目录中的example.conf文件,没有就创建一个
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
#监控文件夹下的test.log文件
a1.sources.r1.command = tail -F /home/qq/pp/data/test.log
a1.sources.r1.channels = c1 # Describe the sink
##sink端的avro是一个数据发送者
a1.sinks = k1
##type设置成avro来设置发消息
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
##下沉到master这台机器
a1.sinks.k1.hostname = 192.168.83.133
##下沉到mini2中的44444
a1.sinks.k1.port = 44444
a1.sinks.k1.batch-size = # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2、master上配置flume/conf里面的example.conf(标红的注意下)
#me the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
##source中的avro组件是一个接收者服务
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444 # Describe the sink
#a1.sinks.k1.type = logger
#对于sink的配置描述 使用kafka做数据的消费
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.brokerList = 192.168.83.128:9092,192.168.83.129:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20 # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3、向监听文件写入字符串(程序循环写入,不用手动修改test.log文件了)
[root@s1 # cd /home/qq/pp/data
[root@s1 home/qq/pp/data# while true
> do
> echo "toms" >> test.log
> sleep
> done
4、查看上面的程序是否执行
#cd /home/qq/pp/data
#tail -f test.log
5、打开消息接收者master的flume
进入flume安装目录,执行如下语句
bin/flume-ng agent -c conf -f conf/example.conf -n a1 -Dflume.root.logger=INFO,console
现在回打印出一些信息
6、启动slave的flume
进入flume安装目录,执行如下语句
bin/flume-ng agent -c conf -f conf/example.conf -n a1 -Dflume.root.logger=INFO,console
7、 进入master ---kafka安装目录
1)启动zookeeper
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
2)启动kafka服务
bin/kafka-server-start.sh -daemon config/server.properties
3)创建topic
kafka-topics.sh --create --topic flume_kafka --zookeeper 192.168.83.129:,192.168.83.128: --partitions --replication-factor 1
4)创建消费者
bin/kafka-console-consumer.sh --bootstrap-server 192.168.83.128:,192.168.83.129: --topic flume_kafka --from-beginning
5)然后就会看到消费之窗口打印写入的信息,

8、此时启动 eclipse实例(https://www.cnblogs.com/51python/p/10908660.html),注意修改ip以及topic
如果启动不成功看看是不是kafka设置问题(https://www.cnblogs.com/51python/p/10919330.html第一步虚拟机部署)
启动后会打印出结果(这是第二次测试不是用的toms而是hollo word测试的,此处只是一个实例)
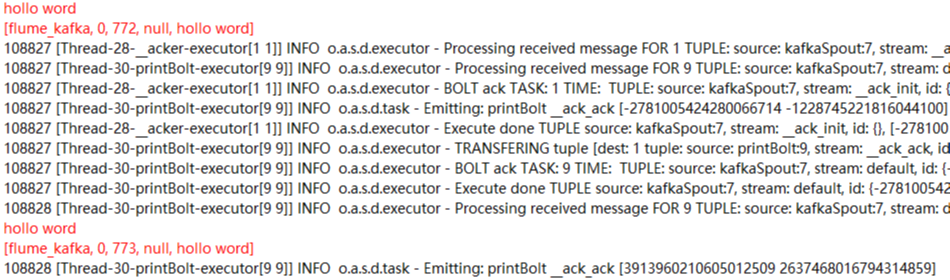
ok!一个流程终于走完了!
参考:
https://blog.csdn.net/luozhonghua2014/article/details/80369469?utm_source=blogxgwz5
https://blog.csdn.net/wxgxgp/article/details/85701844
https://blog.csdn.net/tototuzuoquan/article/details/73203241
flume+flume+kafka消息传递+storm消费的更多相关文章
- Flume、Kafka、Storm结合
Todo: 对Flume的sink进行重构,调用kafka的消费生产者(producer)发送消息; 在Sotrm的spout中继承IRichSpout接口,调用kafka的消息消费者(Consume ...
- 基于Flume+Kafka+ Elasticsearch+Storm的海量日志实时分析平台(转)
0背景介绍 随着机器个数的增加.各种服务.各种组件的扩容.开发人员的递增,日志的运维问题是日渐尖锐.通常,日志都是存储在服务运行的本地机器上,使用脚本来管理,一般非压缩日志保留最近三天,压缩保留最近1 ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- Kafka实战-Flume到Kafka
1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来源 Flume到Kafka 数据源加载 预览 下面 ...
- 【转】Kafka实战-Flume到Kafka
Kafka实战-Flume到Kafka Kafka 2015-07-03 08:46:24 发布 您的评价: 0.0 收藏 2收藏 1.概述 前面给大家介绍了整个Kafka ...
- Flume+LOG4J+Kafka
基于Flume+LOG4J+Kafka的日志采集架构方案 本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具, ...
- Kafka实战-Flume到Kafka (转)
原文链接:Kafka实战-Flume到Kafka 1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来 ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- Flume与Kafka集成
一.Flume介绍 Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能 ...
随机推荐
- 让System.Drawing.Bitmap可以在linux运行
.net core的bitmap使用的是以下类库,但无法在linux运行 https://github.com/CoreCompat/CoreCompat 在linux运行需要安装runtime.li ...
- CAD从二制流数据中加载图形(com接口)
主要用到函数说明: _DMxDrawX::ReadBinStream 从二制流数据中加载图形,详细说明如下: 参数 说明 VARIANT varBinArray 二制流数据,是个byte数组 BSTR ...
- 安装 jdk 和 IDE软件
1.jdk的安装 通过官方网站获取JDK http://www.oracle.com 针对不同操作系统,下载不同的JDK版本 识别计算机的操作系统 下载完后进行安装,傻瓜式安装,下一步下一步即可.用j ...
- 【源码阅读】opencv中opencl版本的dft函数的实现细节
1.函数声明 opencv-3.4.3\modules\core\include\opencv2\core.hpp:2157 CV_EXPORTS_W void dft(InputArray src, ...
- B树、B+树
when ? why ? how ? what ? 平衡二叉树其查找的时间复杂度是 O(log2N)与树的深度相关,那么降低树的深度自然会提高查找效率. 如果我们要操作的数据集非常大,大到内存已经没法 ...
- Yii2开发技巧 使用类似闭包的方式封装事务
在控制器中执行事务的时候,一般的代码如下: $transaction = Yii::$app->db->beginTransaction(); try { //一些业务代码 $transa ...
- Python中的@property装饰器
要了解@property的用途,首先要了解如何创建一个属性. 一般而言,属性都通过__init__方法创建,比如: class Student(object): def __init__(self,n ...
- Linux - nginx基础及常用操作
目录 Linux - nginx基础及常用操作 Tengine淘宝nginx安装流程 nginx的主配置文件nginx.conf 基于域名的多虚拟主机实战 nginx的访问日志功能 网站的404页面优 ...
- Git 基础教程 之 多人协作
多人协作时,从远程克隆时,默认情况下,只能看到master分支 git checkout -b dev origin/dev 创建远程origin的dev分支到本地 git branch ...
- 2.5.3 简单的 echo 输出
echo的任务就是产生输出,可用来提示用户,或是用来产生数据供进一步处理. 原始的echo命令只会将参数打印到标准输出,参数之间以一个空格隔开,并以换行符号(newline)结尾. ...