Impala储存与分区
不多说,直接上干货!



hive的元数据存储在/user/hadoop/warehouse
Impala的内部表也在/user/hadoop/warehouse。
那两者怎么区分,看前面的第一列。
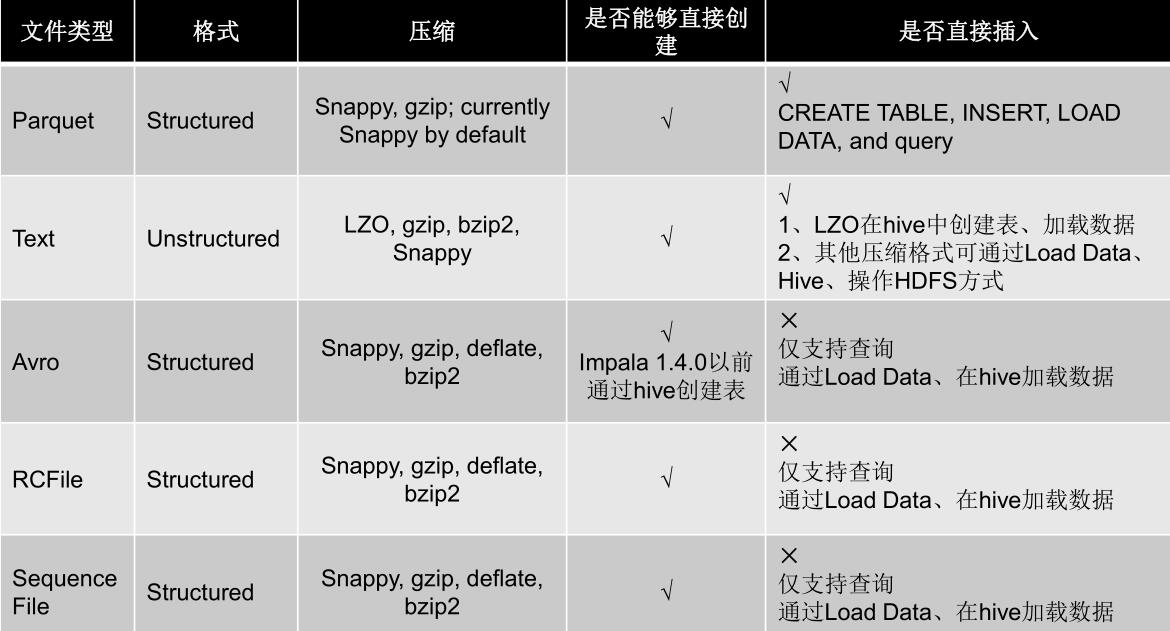
下面是Impala对文件的格式及压缩类型的支持

• 添加分区方式
– 1、partitioned by 创建表时,添加该字段指定分区列表
– 2、使用alter table 进行分区的添加和删除操作
create table t_person(id int, name string, age int) partitioned by (type string);
alter table t_person add partition (sex=‘man');
alter table t_person drop partition (sex=‘man');
alter table t_person drop partition (sex=‘man‘,type=‘boss’);
• 分区内添加数据
insert into t_person partition (type='boss') values (,’zhangsan’,),(,’lisi’,)
insert into t_person partition (type='coder') values(,wangwu’,),(,’zhaoliu’,),(,’tianqi’,)
• 查询指定分区数据
select id,name from t_person where type=‘coder
进行数据分区将会极大的提高数据查询的效率,尤其是对于当下大数据的运用,是一门不可或缺的知识。那数据怎么创建分区呢?数据怎样加载到分区
一、 Impala/Hive按State分区Accounts
(1)示例:accounts是非分区表

通过以上方式创建的话,数据就存放在accounts目录里面。那么,如果Loudacre大部分对customer表的分析是按state来完成的?比如:

这种情况下如果数据量很大,为了避免全表扫描的发生,我们可以去创建分区。如果不创建分区的话,它会默认所有查询不得不扫描目录的所有文件。创建分区按state将数据存储到不同的子目录,当按照“NY”的条件进行查询的时候,它只会扫描到子目录,下面我具体来看一下分区创建。
二、分区创建
(1)使用PARTITIONED BY来创建分区表

在这里注意state是被删除掉的,因为它作为分区字段,我们知道分区数据是不会出现在实际的文件当中的,所以state作为分区字段是不会出现在列当中的。换句话说,分区键就是一个虚列,它是不会存在列当中的。那么,如何去查看我们分区的列呢?它会出现在我们的结构当中吗?会的。
三、查看分区列
使用DESCRIBE显示分区列,它会出现在结构最后一列,它是一个虚列,并不是真实在数据中存在的列。

我们创建单个分区,但有时候会有嵌套分区,如何来处理呢?
四、创建嵌套分区:

创建好了分区,我们怎么加载数据到分区呢?有两种方式动态分区和静态分区。动态分区是指Impala/Hive在加载的时候自动添加新的分区,数据基于列值存储到正确的分区(子目录)。而静态分区需要我们通过ADD PARTITION提前去定义分区的名称,当加载数据的时候,指定存储数据到哪个分区。那么动态分区和静态分区各有什么特征呢?后续为大家接着分享。
Impala储存与分区的更多相关文章
- 【impala学习之二】impala 使用
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 CM5.4 一.Impala shell 1.进入impal ...
- Impala SQL 语言元素(翻译)[转载]
原 Impala SQL 语言元素(翻译) 本文来源于http://my.oschina.net/weiqingbin/blog/189413#OSC_h2_2 摘要 http://www.cloud ...
- 大数据时代快速SQL引擎-Impala
背景 随着大数据时代的到来,Hadoop在过去几年以接近统治性的方式包揽的ETL和数据分析查询的工作,大家也无意间的想往大数据方向靠拢,即使每天数据也就几十.几百M也要放到Hadoop上作分析,只会适 ...
- 转:大数据时代快速SQL引擎-Impala
本文来自:http://blog.csdn.net/yu616568/article/details/52431835 如有侵权 可立即删除 背景 随着大数据时代的到来,Hadoop在过去几年以接近统 ...
- Impala SQL 语言元素(翻译)
摘要: http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Usin ...
- (3)SQL Server表分区
1.简介 当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度.比如电商平台订单表,库存表,由于长年累月读写较多,积累数 ...
- Linux文件系统的实现
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! Linux文件管理从用户的层面介绍了Linux管理文件的方式.Linux有一个树状 ...
- (转)Linux文件系统的实现
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! Linux文件管理从用户的层面介绍了Linux管理文件的方式.Linux有一个树状 ...
- 2019/4/17 Linux学习
一.Linux的文件系统 其中/prov./srv./sys 文件为文件系统,技术不过硬不要去修改:二.关于Xshell.Xft1.服务器的端口可有65535个可设置,开的越多安全性越差:2.远程登录 ...
随机推荐
- 【AngularJS学习笔记】AngularJS表单验证
AngularJS表单验证 AngularJS提供了一些自带的验证属性 1.novalidate:添加到HTML的表单属性中,用于禁用浏览器默认的验证. 2.$dirty 表单有填写记录 3.$v ...
- <Sicily>Catch the thief
一.题目描述 A thief has robbed a bank in city 1 and he wants to go to city N. The police know that the th ...
- SSD-实现
一.制作voc数据集 1.数据集文件夹 新建一个文件夹,用来存放整个数据集,或者和voc2007一样的名字:VOC2007 然后像voc2007一样,在文件夹里面新建如下文件夹: 2.将训练图片放到J ...
- AlexNet (ImageNet模型)
介绍 AlexNet是LeNet的一种更深更宽的版本.首次在CNN中应用ReLU.Dropout和LRN,GPU进行运算加速. 一共有13层,有8个需要训练参数的层(不包括池化层和LRN层),前5层是 ...
- 去除input的前后的空格
这里用的是jquery的方法
- docker切换默认镜像源
docker切换默认镜像源 基于 debian8 默认安装的 docker 镜像源是在国外,pull 镜像的时候奇慢无比,需要自己手动切换成国内的镜像源. 1. 修改配置文件 docker 默认的 ...
- NodeJS学习笔记 (13)数据加密-crypto(OK)
写在前面 本章节写得差不多了,不过还需要再整理一下(TODO). hash例子 hash.digest([encoding]):计算摘要.encoding可以是hex.latin1或者base64.如 ...
- UVALive 6486 Skyscrapers 简单动态规划
题意: 有N个格子排成一排,在每个格子里填上1到N的数(每个只能填一次),分别代表每个格子的高度.现在给你两个数left和right,分别表示从左往右看,和从右往左看,能看到的格子数.问有多少种情况. ...
- Vs2012在Linux开发中的应用(1):开发环境
在Linux的开发过程中使用过多个IDE.code::blocks.eclipse.source insight.还有嵌入式厂商提供的各种IDE.如VisualDsp等,感觉总是不如vs强大好用.尽管 ...
- easyui combobox 获取焦点
easyui combobox 获取焦点 学习了:http://blog.csdn.net/foart/article/details/14446809 可以直接用: $('#spanZhudaoci ...