【Paper Reading】Deep Supervised Hashing for fast Image Retrieval
what has been done:
This paper proposed a novel Deep Supervised Hashing method to learn a compact similarity-presevering binary code for the huge body of image data.
Data sets:
CIFAR-10: 60,000 32*32 belonging to 10 mutually exclusively categories(6000 images per category)
NUS-WIDE: 269,648 from Flickr, warpped to 64*64
content based image retrieval: visually similar or semantically similar.
Traditional method: calculate the distance between the query image and the database images.
Problem: time and memory
Solution: hashing methods(map image to compact binary codes that approximately preserve the data structure in the original space)
Problem: performace depends on the features used, more suitable for dealing with the visiual similarity search rather than the sematically similarity search.
Solution: CNNs, the CNNs successful applications of CNNs in various tasks imply that the feature learned by CNNs can well capture the underlying sematic structure of images in spite of significant appearance variations.
Related works:
Locality Sensitive Hashing(LSH):use random projections to produce hashing bits
cons: requires long codes to achieve satisfactory performance.(large memory)
data-dependent hashing methods: unsupervised vs supervised
unsupervised methods: only make use of unlabelled training data to lean hash functions
- spectral hashing(SH): minimizes the weighted hamming distance of image pairs
- Iterative Quantization(ITQ): minimize the quantization error on projected image descriptors so as to allievate the information loss
supervised methods: take advantage of label inforamtion thus can preserve semantic similarity
- CCA-ITQ: an extension of iterative quantization
- predictable discriminative binary code: looks for hypeplanes that seperate categories with large margin as hash function.
- Minimal Loss Hashing(MLH): optimize upper bound of a hinge-like loss to learn the hash functions
problem: the above methods use linear projection as hash functions and can only deal with linearly seperable data.
solution: supervised hashing with kernels(KSH) and Binary Reconstructive Embedding(BRE).
Deep hashing: exploits a non-linear deep networks to produce binary code.
Problem : most hash methods relax the binary codes to real-values in optimizations and quantize the model outputs to produce binary codes. However there is no guarantee that the optimal real-valued codes are still optimal after quantization .
Solution: DIscrete Graph Hashing(DGH) and Supervided Discrete Hashing(DSH) are proposed to directly optimize the binary codes.
Problem : Use hand crafted feature and cannot capture the semantic information.
Solution: CNNs base hashing method
Our goal: similar images should be encoded to similar binary codes and the binary codes should be computed efficiently.
Loss function:
Relaxation:
Implementation details:
Network structure:
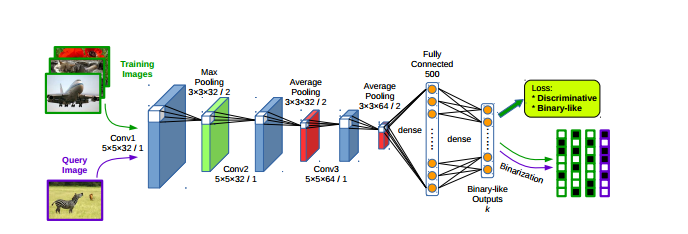
3*卷积层:
3*池化层:
2*全连接层:
Training methodology:
- generate images pairs online by exploiting all the image pairs in each mini-batch. Allivate the need to store the whole pair-wise similarity matrix, thus being scalable to large-scale data-sets.
- Fine-tune vs Train from scratch
Experiment:
CIFAR-10
GIST descriptors for conventional hashing methods
NUS-WIDE
225-D normalized block-wise color moment features
Evalutaion Metrics
mAP: mean Average Precision
precision-recall curves(48-bit)
mean precision within Hamming radius 2 for different code lengths
Network ensembles?
Comparison with state-of-the-art method
CNNH: trainin the model to fit pre-computed discriminative binary code. binary code generation and the network learning are isolated
CLBHC: train the model with a binary-line hidden layer as features for classification, encoding dissimilar images to similar binary code would not be punished.
DNNH: used triplet-based constraints to describe more complex semantic relations, training its networks become more diffucult due to the sigmoid non-linearlity and the parameterized piece-wise threshold function used in the output layer.
Combine binary code generation with network learning
Comparision of Encoding Time
【Paper Reading】Deep Supervised Hashing for fast Image Retrieval的更多相关文章
- 【Paper Reading】Learning while Reading
Learning while Reading 不限于具体的书,只限于知识的宽度 这个系列集合了一周所学所看的精华,它们往往来自不只一本书 我们之所以将自然界分类,组织成各种概念,并按其分类,主要是因为 ...
- 【Paper Reading】Object Recognition from Scale-Invariant Features
Paper: Object Recognition from Scale-Invariant Features Sorce: http://www.cs.ubc.ca/~lowe/papers/icc ...
- 【Paper Reading】Bayesian Face Sketch Synthesis
Contribution: 1) Systematic interpretation to existing face sketch synthesis methods. 2) Bayesian fa ...
- 【Paper Reading】Improved Textured Networks: Maximizing quality and diversity in Feed-Forward Stylization and Texture Synthesis
Improved Textured Networks: Maximizing quality and diversity in Feed-Forward Stylization and Texture ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- 【文献阅读】Deep Residual Learning for Image Recognition--CVPR--2016
最近准备用Resnet来解决问题,于是重读Resnet的paper <Deep Residual Learning for Image Recognition>, 这是何恺明在2016-C ...
- 【文献阅读】Augmenting Supervised Neural Networks with Unsupervised Objectives-ICML-2016
一.Abstract 从近期对unsupervised learning 的研究得到启发,在large-scale setting 上,本文把unsupervised learning 与superv ...
- 【CS-4476-project 6】Deep Learning
AlexNet / VGG-F network visualized by mNeuron. Project 6: Deep LearningIntroduction to Computer Visi ...
- 【论文阅读】Deep Mixture of Diverse Experts for Large-Scale Visual Recognition
导读: 本文为论文<Deep Mixture of Diverse Experts for Large-Scale Visual Recognition>的阅读总结.目的是做大规模图像分类 ...
随机推荐
- Project Euler 21 Distinct primes factors( 整数因子和 )
题意: 记d(n)为n的所有真因数(小于n且整除n的正整数)之和. 如果d(a) = b且d(b) = a,且a ≠ b,那么a和b构成一个亲和数对,a和b被称为亲和数. 例如,220的真因数包括1. ...
- 洛谷P1046 陶陶摘苹果
题目描述 陶陶家的院子里有一棵苹果树,每到秋天树上就会结出 101010 个苹果.苹果成熟的时候,陶陶就会跑去摘苹果.陶陶有个 303030 厘米高的板凳,当她不能直接用手摘到苹果的时候,就会踩到板凳 ...
- BZOJ 1197 [HNOI2006]花仙子的魔法 (数学题)
题面:洛谷传送门 BZOJ传送门 非常有意思的一道数学题,浓浓的$CF$风,然而我并没有想出来.. 我们想把一个$n$维空间用$n$维球分成尽可能多的块 而新增加一个$n$维球时,肯定要尽可能多地切割 ...
- 【codeforces 719E】Sasha and Array
[题目链接]:http://codeforces.com/contest/719/problem/E [题意] 给你一个数列,有两种操作1 l r x 给[l,r]区间上的数加上x, 2 l r 询问 ...
- Centos如何安装 jdk 环境变量
一.编辑 profile 文件 vim /etc/profile 二.在 profile 文件下面最下面加上以下内容 export JAVA_HOME=/usr/local/java/jdk1.7.0 ...
- Ajax接收json响应
json? Json和xml比较 Ajax如何使用JSON Ajax接收json响应案例 什么是json?JSON (JavaScript Object Notation) 是一种轻量级的 ...
- Linux-经常用到的几个命令
-- |" 拷贝本地到远程 scp /serverdata/server/tomcat-uaac/webapps/dm.war root@172.16.7.123:/serverdata/s ...
- centos6安装eclipse
1. 下载eclipse 我下载的是eclipse-jee-juno-SR2-linux-gtk-x86_64.tar.gz 能够在http://www.eclipse.org/downloads/处 ...
- C++中 pair 的使用方法
#include<iostream> #include<string> #include<map> using namespace std; // pair简单讲就 ...
- 【DataStructure】The difference among methods addAll(),retainAll() and removeAll()
In the Java collection framework, there are three similar methods, addAll(),retainAll() and removeAl ...