elasticsearch的master选举机制
master作为cluster的灵魂必须要有,还必须要唯一,否则集群就出大问题了。因此master选举在cluster分析中尤为重要。对于这个问题我将分两篇来分析。第一篇也就是本篇,首先会简单说一说mater选举的一些算法,及elasticsearch的选举原理。第二篇也就是下一篇,会结合zenDiscovery代码为仔细分析elasticsearch的master选举的实现。
简单来说master的作用跟单个jvm中的同步关键字synchronized相同,集群中多节点协调工作必须要保证数据的一致性,但是不同节点分布在不同的jvm中,不可能用jvm的同步机制。所以需要一个“锁”,节点操作集群中的资源时都通过它来解决一致性问题,这就是master。关于分布式系统的master选举算法有很多,最有名的当然要数paxos算法,在它的基础上出现了非常多的变体算法。关于这个算法请参考相关网页和资料,不是一两句话能说清楚的,这里不再祥述。但是paxos的功能远远超出了master选举,一致性向才是它的目标,任何需要实现一致性的问题都可以使用该算法,因此zookeeper功能远远不止master选举。还有一种比较简单的算法就是Bully,它通过一定的直接给每个节点赋予一唯一的ID,这些ID是可以排序的,每次master选举都会选举ID最大的节点。这种实现非常简单。但是会存在一些问题,在master负载过重时它会假死,于是第二大节点就成为了master节点。因此假死master节点因负载减轻又活了过来,于是他又被选为master,然后又假死……,这种情况可能一直存在导致系统不稳定。
集群还有一个问题就是brain split:一个集群因为网络问题导致多个master选举出来而分裂。这也是master选举必须要解决的问题。elasticsearch的master选举原理我觉得是在bully的基础上做了改进。相比于paxos实现的zookeeper它完美的解决了master选举问题,但不如zookeeper强大,因为zookeeper功能远远超出了master选举,它的master选举却不需要这么多功能。它原理如下:
- 对所有可以成为master的节点根据nodeId排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
- 如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举。
- 对于brain split问题,需要把候选master节点最小值设置为可以成为master节点数n/2+1(quorum )
以上就是master选举的三条原则,其实第三天包含在第二条之中,为了说明brain split问题这里单独拿出来说一下。下面看一下ElectMasterService的相关代码,来补充说明一下一上的文字描述:
public DiscoveryNode electMaster(Iterable<DiscoveryNode> nodes) {
List<DiscoveryNode> sortedNodes = sortedMasterNodes(nodes);
if (sortedNodes == null || sortedNodes.isEmpty()) {
return null;
}
return sortedNodes.get(0);
}
上面就是选举master的方法,可以看到,它的做法就是对候选节点排序然后直接将第一个返回。当然这只是上面所说的第一条。其实只有这个是不能够保证maser选举顺利的,之前也看到一些文章分析elasticsearch的master选举,只提到了这个点和这一部分代码,应该是作者没有仔细研究Discovery代码而导致的疏忽。如果每个节点都只是选举自己排序后的节点的第一个肯定会导致brain split和选举不一致。master比较的方法也比较简单如下所示:
private static class NodeComparator implements Comparator<DiscoveryNode> {
@Override
public int compare(DiscoveryNode o1, DiscoveryNode o2) {
if (o1.masterNode() && !o2.masterNode()) {
return -1;
}
if (!o1.masterNode() && o2.masterNode()) {
return 1;
}
return o1.id().compareTo(o2.id());
}
}
以上是节点排序比较器,可以看到它只是比较了nodeId,因此是按nodeId排序。从这两两段代码来看很像是bully算法的实现。为了解决brain split问题开发者加入了master候选数据量限制,代码如下:
public boolean hasEnoughMasterNodes(Iterable<DiscoveryNode> nodes) {
if (minimumMasterNodes < 1) {
return true;
}
int count = 0;
for (DiscoveryNode node : nodes) {
if (node.masterNode()) {
count++;
}
}
return count >= minimumMasterNodes;
}
通过比较节点能“看到”的候选master数量和配置的最小值来确定是否可以进行选举,如果数量不够会导致选举不能进行,这样就可以保证集群不会被分裂。下面以一个图(图片来自于elasticsearch官网)来说明:
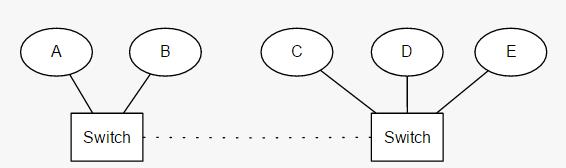
假设之前选举了A节点为master,两个switch之间突然断线了,这样就分词了两部分。CDE和AB,因为 minimumMasterNodes的数目为3(集群中5个节点都可以成为master,3=5/2+1),因此cde会可以进行选举假设C成为master。AB两个节点因为少于3所以无法选举,只能一直寻求加入集群,要么线路连通加入到CDE中要么就一直处于寻找集群状态,这样就保证了集群不分裂。
总结一下,本篇介绍了master选举的两种算法和elasticsearch的选举原理,并分析了它原理中的两条,第二条将在下一篇discovery中接下分析。
elasticsearch的master选举机制的更多相关文章
- zenDiscovery和master选举
上一篇通过 ElectMasterService源码,分析了master选举的原理的大部分内容:master候选节点ID排序保证选举一致性及通过设置最小可见候选节点数目避免brain split.节点 ...
- elasticsearch从入门到出门-08-Elasticsearch容错机制:master选举,replica容错,数据恢复
假如: 9 shard,3 node Elasticsearch容错机制:master选举,replica容错,数据恢复 最佳分配情况: 这样分配之后,不管其中哪个node 宕机这个es 依然可以提供 ...
- Zookeeper实现Master选举(哨兵机制)
master选举使用场景及结构 现在很多时候我们的服务需要7*24小时工作,假如一台机器挂了,我们希望能有其它机器顶替它继续工作.此类问题现在多采用master-salve模式,也就是常说的主从模式, ...
- Elasticsearch系列---分布式架构机制讲解
概要 本篇主要介绍Elasticsearch的数据索引时的分片机制,集群发现机制,primary shard与replica shard是如何分工合作的,如何对集群扩容,以及集群的容错机制. 分片机制 ...
- ElasticSearch 分布式及容错机制
1 ElasticSearch分布式基础 1.1 ES分布式机制 分布式机制:Elasticsearch是一套分布式的系统,分布式是为了应对大数据量.它的特性就是对复杂的分布式机制隐藏掉. 分片机制: ...
- 学习笔记:Zookeeper选举机制
1.Zookeeper选举机制 Zookeeper虽然在配置文件中并没有指定master和slave 但是,zookeeper工作时,是有一个节点为leader,其他则为follower Leader ...
- Zookeeper系列五:Master选举、ZK高级特性:基本模型
一.Master选举 1. master选举原理: 有多个master,每次只能有一个master负责主要的工作,其他的master作为备份,同时对负责工作的master进行监听,一旦负责工作的mas ...
- ZooKeeper 的读写操作 & 选举机制
0. 说明 记录 ZooKeeper 的读写操作和选举机制 1. ZooKeeper 的读写操作 读操作:所有 ZooKeeper 节点都可以提供读请求(包括 follower 和 leader ) ...
- zookeeper选举机制
在上一篇文章中我们大致浏览了zookeeper的启动过程,并且提到在Zookeeper的启动过程中leader选举是非常重要而且最复杂的一个环节.那么什么是leader选举呢?zookeeper为什么 ...
随机推荐
- 【Henu ACM Round#19 D】 Points on Line
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 考虑l..r这个区间. 且r是满足a[r]-a[l]<=d的最大的r 如果是第一个找到的区间,则直接累加C(r-l+1,3); ...
- 洛谷 P1407 工资
P1407 工资 题目描述 有一家世界级大企业,他们经过调查,发现了一个奇特的现象,竟然在自己的公司里,有超过一半的雇员,他们的工资完全相同! 公布了这项调查结果后,众多老板对于这一现象很感兴趣,他们 ...
- 对GPDB查询计划的Motion结点的理解
GPDB在进行join查询时,可能会产生Motion结点 根据官方文档,总共有这几种Motion: redistribute 重分布(用hash取模的方法把join字段重分布到各个segment,相当 ...
- Linux同步与相互排斥应用(零):基础概念
[版权声明:尊重原创,转载请保留出处:blog.csdn.net/shallnet 或 .../gentleliu,文章仅供学习交流,请勿用于商业用途] 当操作系统进入多道批处理系统时 ...
- Raphaeljs入门到精通(一)
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <t ...
- UvaLive 6600 Spanning trees in a secure lock pattern 矩阵行列式
链接:https://icpcarchive.ecs.baylor.edu/index.php? option=com_onlinejudge&Itemid=8&page=show_p ...
- centos7;windows下安装和使用spice
感谢朋友支持本博客,欢迎共同探讨交流,因为能力和时间有限,错误之处在所难免,欢迎指正! 假设转载,请保留作者信息. 博客地址:http://blog.csdn.net/qq_21398167 原博文地 ...
- [BZOJ4026]dC Loves Number Theory 欧拉函数+线段树
链接 题意:给定长度为 \(n\) 的序列 A,每次求区间 \([l,r]\) 的乘积的欧拉函数 题解 考虑离线怎么搞,将询问按右端点排序,然后按顺序扫这个序列 对于每个 \(A_i\) ,枚举它的质 ...
- thinkphp里面使用原生php
thinkphp里面使用原生php Php代码可以和标签在模板文件中混合使用,可以在模板文件里面书写任意的PHP语句代码 ,包括下面两种方式: 使用php标签 例如: {php}echo 'Hello ...
- Introspector
import java.beans.BeanInfo; import java.beans.Introspector; import java.beans.PropertyDescriptor; im ...