python 爬取妹子
爬取妹子图片
2019-06-13
环境WIN10 1903 python 3.7.3
个人习惯先在IDLE中进行调试
import requests
from bs4 import BeautifulSoup
url='https://www.mzitu.com/'
response=requests.get(url=url)
print(response.status_code)
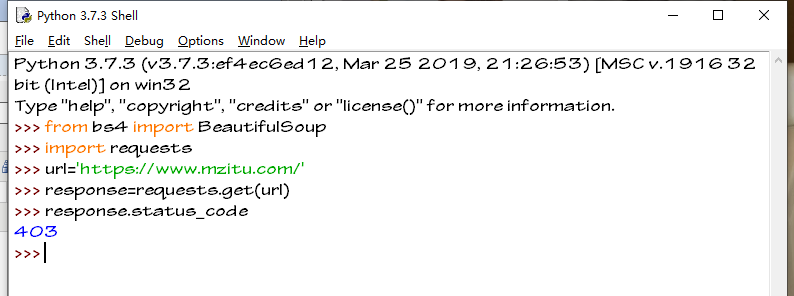
403是返回的状态码
403错误,表示资源不可用。服务器理解客户的请求,但拒绝处理它,通常由于服务器上文件或目录的权限设置导致的WEB访问错误。
该网站有反爬措施
我们先试一下伪造浏览器
打开google看一下我们发送的请求
我们构造headers
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'
}
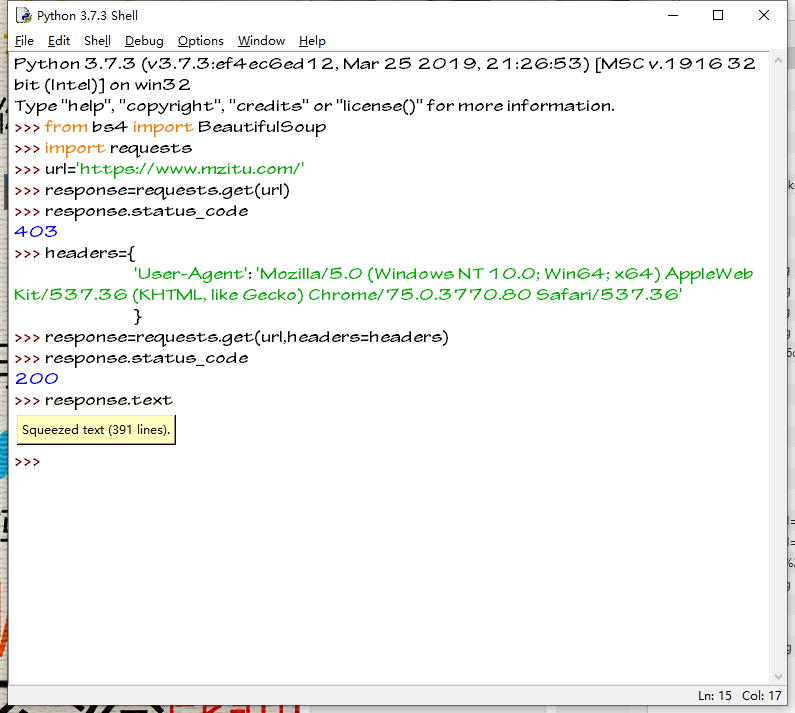
返回的状态码为 200
说明伪造浏览器成功
使用response.text查看返回的内容
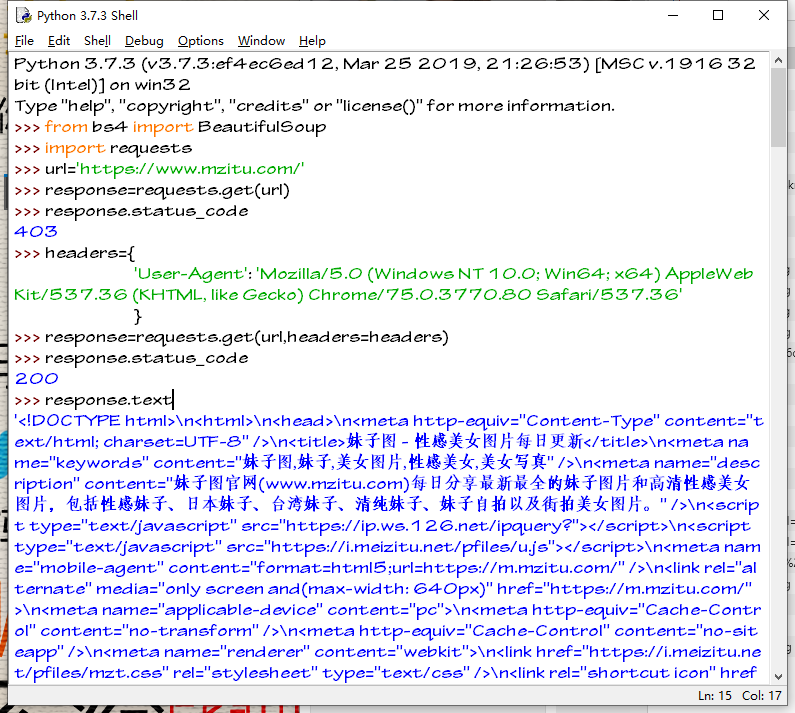
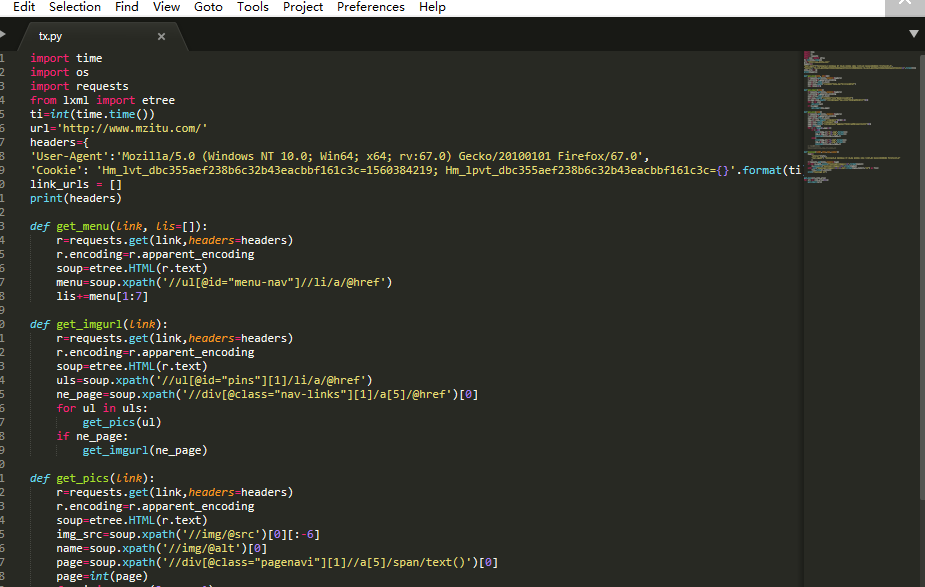
我习惯调试使用bs4库BeautifulSoup类
正式写脚本我习惯用lxml库的etree类
查看网页编码

解析判断的编码与备用编码相同 我们可以忽略
开始进入解析部分
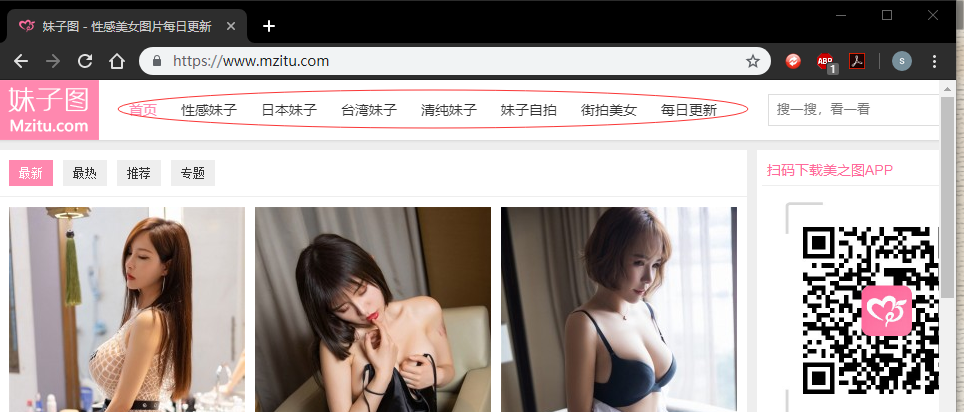
我们选取网页格式相同的4个部分进行爬取
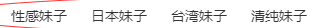
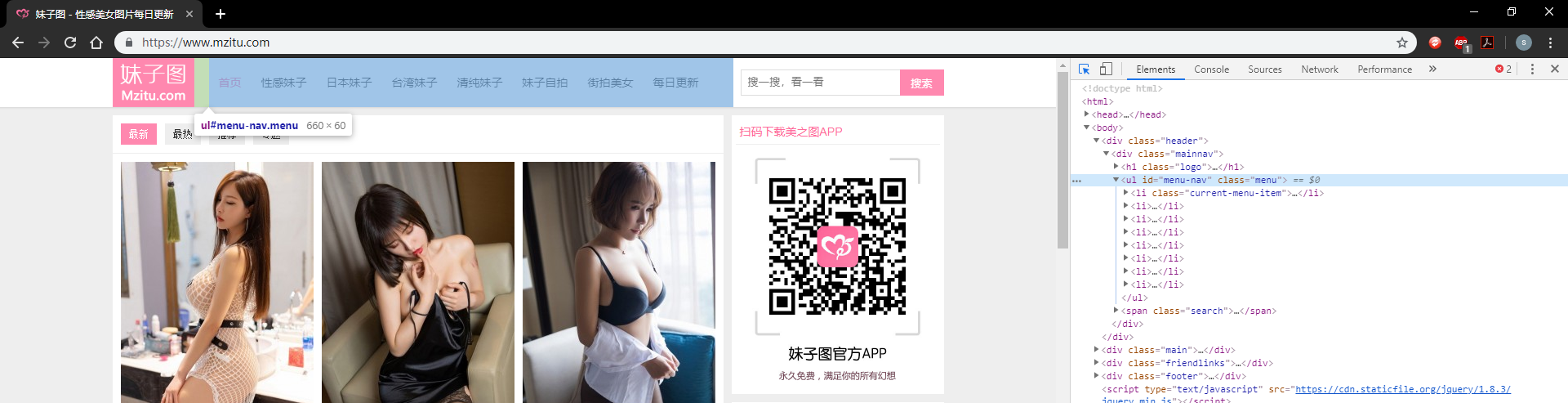
菜单栏为<ul></ul>标签而且id='menu-nav'开始写代码
首先我们先创建BeautifulSoup对象

关于BeautifulSoup的使用 查看官方文档 https://www.crummy.com/software/BeautifulSoup/bs3/documentation.zh.html
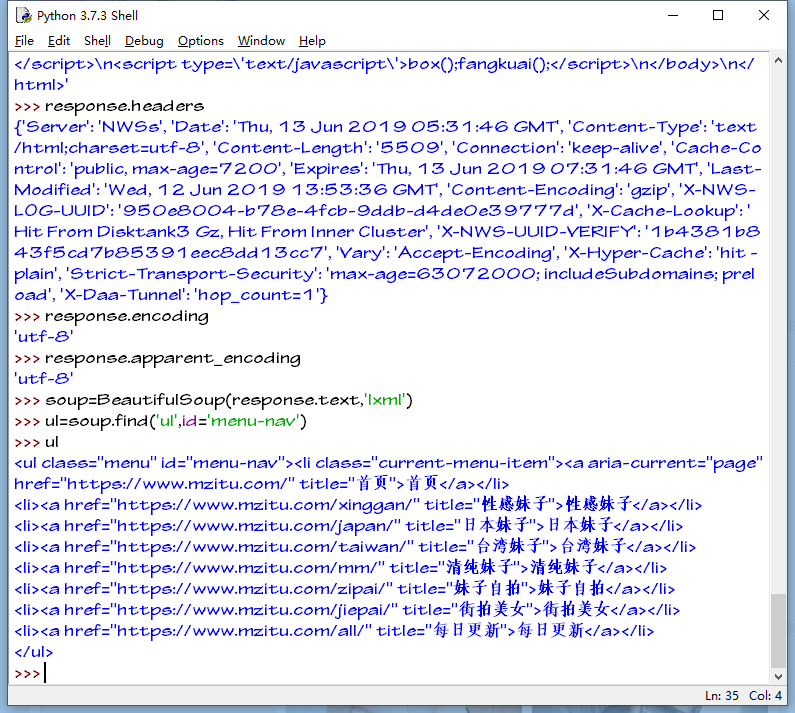
选取我们需要的三个li标签加入我们创建的link_urls列表中
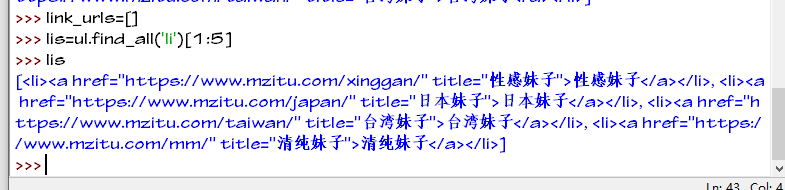
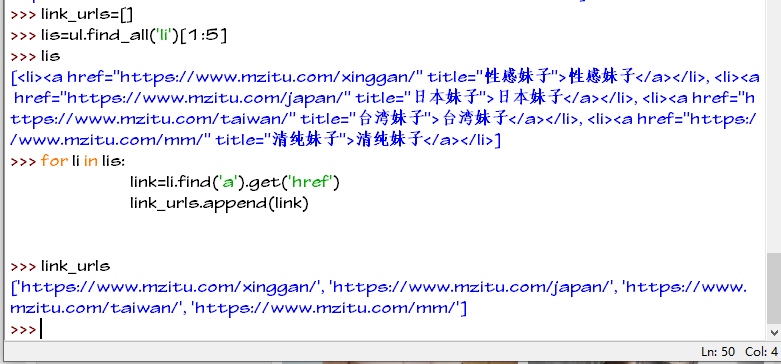
现在我们要爬取的三个美女类型的链接已经保存到link_urls列表中了
我们以第一类型的性感美女进行爬取

打开这个网页
我们分析这个网页会发现
总共有27个图片缩略图
其中有三个是广告
提取数据的时候要对广告进行清除
查看源代码
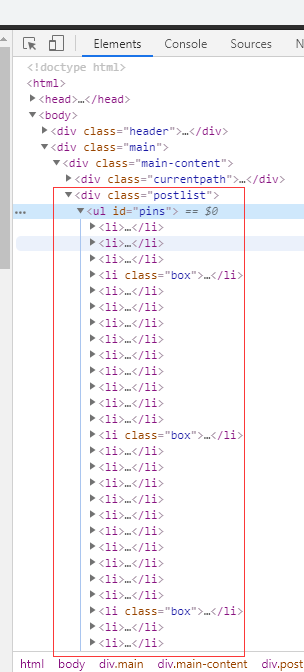
图片在<ul>标签里面且id='pins'
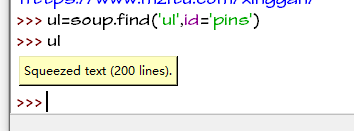
找到这个ul标签之后
我们继续提取其中的li标签
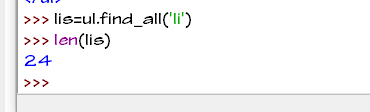
由于广告的标签含有class属性我们提取li标签已经过滤了三个广告
所以长度为24
下一步获取图片的该类图片的地址 属性为href
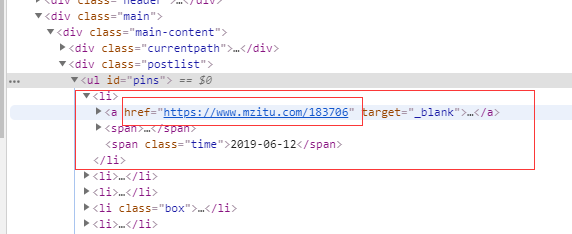
一个图片是一个<li>标签
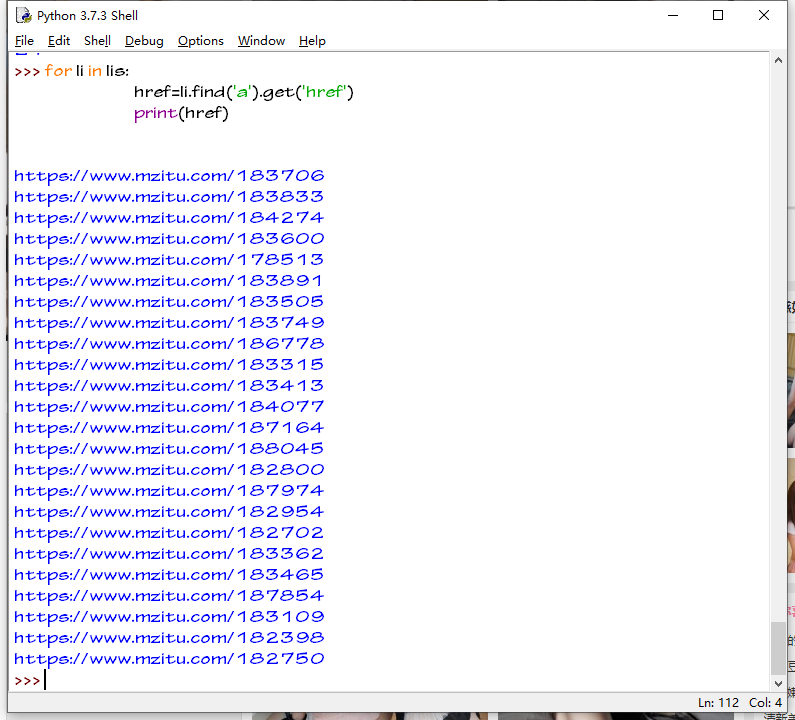
图片的链接到手 现在的链接只是我们要爬取的图片的地址 并不是图片的链接
现在我们进入图片的提取部分
我们以这个链接 https://www.mzitu.com/184274 进行分析
我们要的图片链接在这里


获取页面还是要通过伪造浏览器的方式
下载页面完成我们去获得图片的链接
方法与前面类似
网页中第一个img标签就是我们要的图片
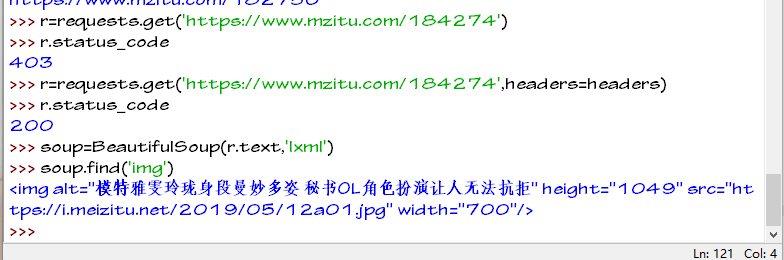

获取到图片的地址 地址在img标签的src属性中我们提取出来
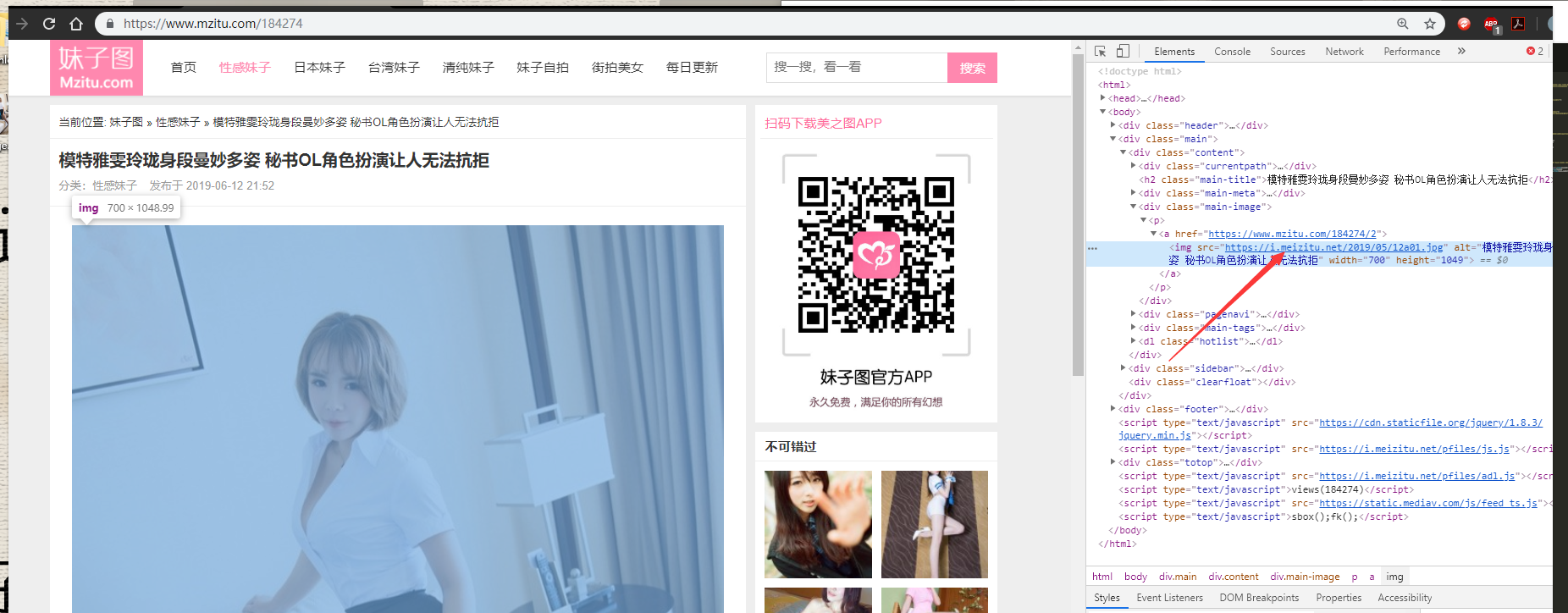
使用requests去下载它
我们使用requests下载时候会发现下载失败
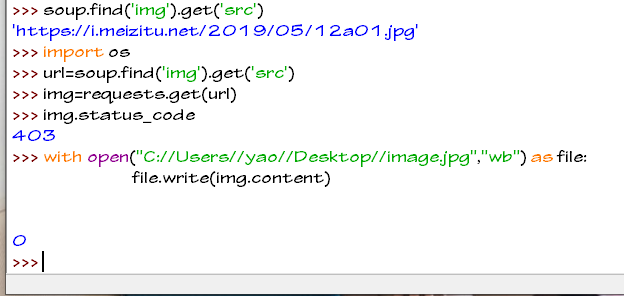
文件写入为0
我们继续构造headers来成功下载图片
headers={
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36',
'Referer':'https://www.mzitu.com/184274'
}
# 这里的Referer是你跳转到这个图片的上一个地址 这也是一个反爬小技巧
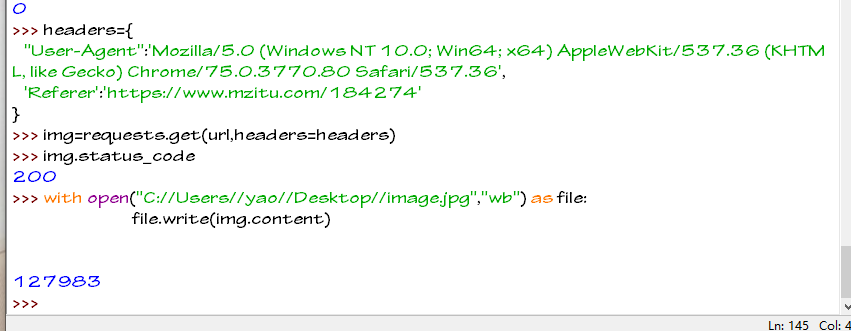
图片下载成功
img是requests返回内容
由于图片是二进制文件我们用"wb"方式打开写入文件
保存为jpg这样图片就写入成功了
视频 音频也可以这样下载
打开我们下载的图片
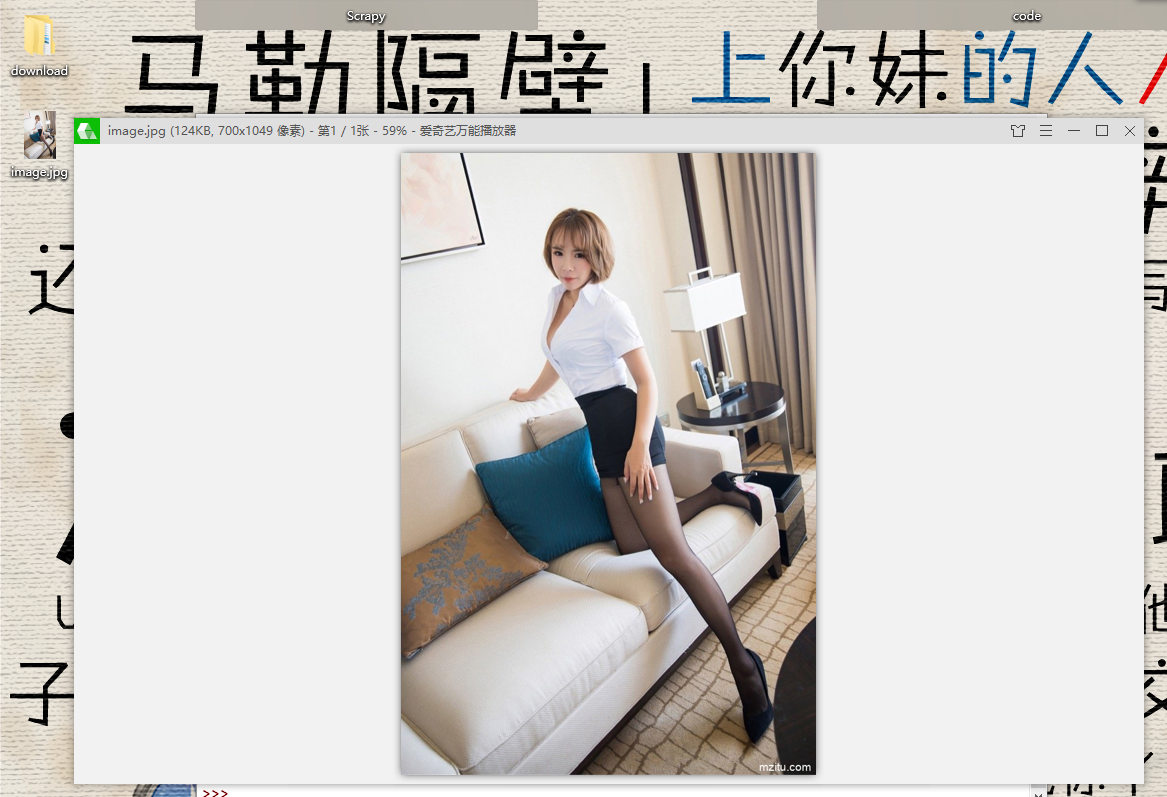
成功下载
爬取整个类型的图片我们只需要构造几个函数对url进行解析就好
以下笔者的思路

1 找到一个图片的地址我们可以提取页面的下一页的链接然后就是递归调用函数 进行爬取
2 通过查看图片的url我们发现图片是有规律的
https://i.meizitu.net/2019/05/12a02.jpg
https://i.meizitu.net/2019/05/12a03.jpg
...................
最后一张图片就是

https://i.meizitu.net/2019/05/12a50.jpg
这样就能爬取这个系列的图片了
python 爬取妹子的更多相关文章
- python爬取妹子图全站全部图片-可自行添加-线程-进程爬取,图片去重
from bs4 import BeautifulSoupimport sys,os,requests,pymongo,timefrom lxml import etreedef get_fenlei ...
- Python 爬取 妹子图(技术是无罪的)
... #!/usr/bin/env python import urllib.request from bs4 import BeautifulSoup def crawl(url): header ...
- Python 爬取妹子图(技术是无罪的)
... import requests from bs4 import BeautifulSoup import os import sys class mzitu(): def html(self, ...
- Python协程爬取妹子图(内有福利,你懂得~)
项目说明: 1.项目介绍 本项目使用Python提供的协程+scrapy中的选择器的使用(相当好用)实现爬取妹子图的(福利图)图片,这个学会了,某榴什么的.pow(2, 10)是吧! 2.用到的知 ...
- 用python爬取全网妹子图片【附源码笔记】
这是晚上没事无聊写的python爬虫小程序,专门爬取妹子图的,养眼用的,嘻嘻!身为程序狗只会这个了! 废话不多说,代码附上,仅供参考学习! """ 功能:爬取妹子图全网妹 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
随机推荐
- round()和trunc()函数的应用
http://blog.chinaunix.net/uid-7801695-id-68136.html round()和trunc()函数的应用 关键字: round()和trunc()函数的应用 ...
- Servlet请求参数编码处理(POST & GET)
小巧,但在中文语境下,还是要注意的. 以下是关键语句,注意转码的先后顺序,这源于GET是HTTP服务器处理,而POST是WEB容器处理: String name = request.getParame ...
- Java重载和覆盖
重写 Overriding 如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding) 1.参数列表必须完全与被重写的方法相同,否则不能称其为重写而是重载. 2.返 ...
- python 执行环境
一些函数 执行其它非python程序 1 一些函数 callable callable()是一个布尔函数,确定一个对象是否可以通过函数操作符(())来调用.如果函数可调用便返回True,否则便是Fal ...
- kendo AutoComplete实现多筛选条件
kendo autoComplete 原始情况下是不支持多筛选条件的 $("#autocomplete").kendoAutoComplete({ filter: "co ...
- UI层自动化测试框架(一)-简介和环境搭建
http://blog.csdn.net/ToBeTheEnder/article/details/52302777
- light oj1074
Description The people of Mohammadpur have decided to paint each of their houses red, green, or blue ...
- java 集合交并补
通过使用泛型方法和Set来表达数学中的表达式:集合的交并补.在下面三个方法中都将第一个參数Set复制了一份,并未直接改动參数中Set. package Set; import java.util.Ha ...
- 好记性不如烂笔头——WebService与Remoting
一.WebService总体上分为5个层次: 1)HTTP传输信道 2)XML的数据格式 3)SOAP的封装协议,用于传输 4)WSDL的描述方式,用于引用 5)UDDI,通用描述.发现与集成服务,用 ...
- 10.0arcmap切片生成ptk步骤
注意:在制作之前需要点将图放到原本大小.并且保存一下不然容易造成数据丢失. 1.制作mxd 我们将待发布的数据,鼠标选中,拖入到ArcMap中间区域,单击保存. 可以对layers下面的图层进行改名. ...