CUDA学习(三)之使用GPU进行两个数组相加
传入两个数组,在GPU中将两个数组对应索引位置相加
#include "cuda_runtime.h"
#include "device_launch_parameters.h" #include <iomanip>
#include <iostream>
#include <stdio.h> using namespace std; //检测GPU
bool CheckCUDA(void){
int count = ;
int i = ; cudaGetDeviceCount(&count);
if (count == ) {
printf("找不到支持CUDA的设备!\n");
return false;
}
cudaDeviceProp prop;
for (i = ; i < count; i++) {
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
if (prop.major >= ) {
break;
}
}
}
if (i == count) {
printf("找不到支持CUDA的设备!\n");
return false;
}
cudaGetDeviceProperties(&prop, );
printf("GPU is: %s\n", prop.name);
cudaSetDevice();
printf("CUDA initialized success.\n");
return true;
}//使用一维数组相加
__global__ void addForOneDim(double *a, double *b, double *c, int N); //初始化一维数组
void InitOneDimArray(double *a, double b, int N); int main(){
//检测GPU
if (!CheckCUDA()){
cout << "No CUDA device.";
return ;
} //****数组相加************************************************************************************************************************
cout << "****************************************数组相加*********************************************************************" << endl;
int N = ; //定义数组大小
double *h_a_one, *h_b_one, *h_c_one; //声明在CPU上使用的指针
double *d_a_one, *d_b_one, *d_c_one; //声明在GPU上使用的指针
//为数组分配大小
h_a_one = new double[N];
h_b_one = new double[N];
h_c_one = new double[N]; cudaMalloc((void **)&d_a_one, sizeof(double)*N); //在GPU上分配内存空间
cudaMalloc((void **)&d_b_one, sizeof(double)*N);
cudaMalloc((void **)&d_c_one, sizeof(double)*N);
//为数组初始化
InitOneDimArray(h_a_one, 1.1, N);
InitOneDimArray(h_b_one, 2.2, N); //使用GPU中分配的指针指向CPU中的数组
cudaMemcpy(d_a_one, h_a_one, sizeof(double)*N, cudaMemcpyHostToDevice);
cudaMemcpy(d_b_one, h_b_one, sizeof(double)*N, cudaMemcpyHostToDevice); //调用核函数,使用1个线程块N个线程
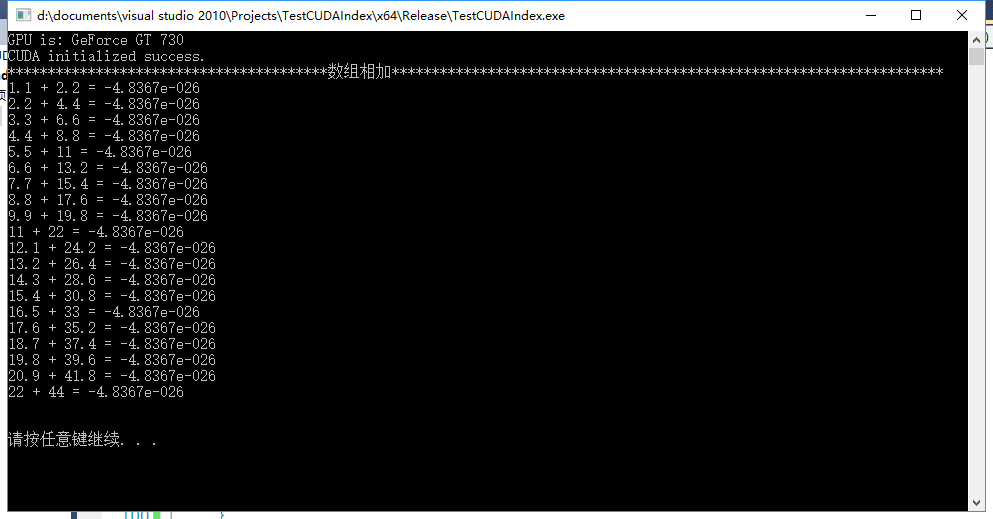
//addForOneDim<<<1, N>>>(h_a_one, h_b_one, d_c_one, N); //不能使用h_a_one和h_b_one,只能使用GPU上定义的指针,不然结果如图一所示
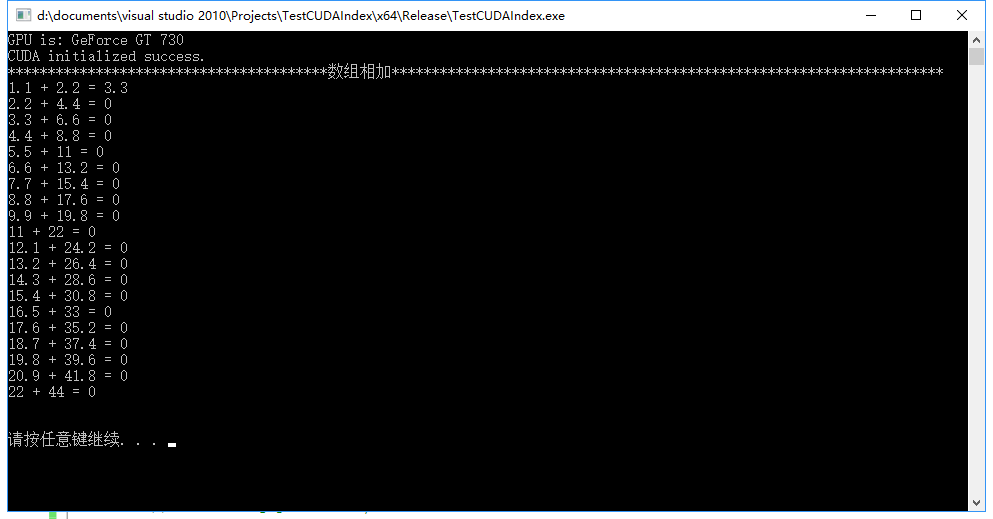
addForOneDim<<<, N>>>(d_a_one, d_b_one, d_c_one, N); //结果如图二所示
//调用核函数,使用N个线程块,每个线程块中包含1个线程
//addForOneDim<<<N, >>>(d_a_one, d_b_one, d_c_one, N); //结果如图三所示
//将GPU上计算好的结果返回到CPU上定义好的变量
cudaMemcpy(h_c_one, d_c_one, sizeof(double)*N, cudaMemcpyDeviceToHost); //打印结果
for (int i = ; i < N; i++){
cout << h_a_one[i] << " + " << h_b_one[i] << " = " << h_c_one[i] << endl;
} cout << endl << endl;
system("pause");
return ;
}
//使用一维数组相加
__global__ void addForOneDim(double *a, double *b, double *c, int N){
int tid = threadIdx.x; //线程索引,启用1个线程块,每个线程块N个线程
if (tid < N){
c[tid] = a[tid] + b[tid];
}
} //初始化一维数组
void InitOneDimArray(double *a, double b, int N){
for (int i = ; i < N; i++){
a[i] = (i+) * b;
//cout << a[i] << endl;
}
}
图一 (该图是错误的)
图二 (该图是正确的)

图三 (该图是错误的)当在调用核函数时,
addForOneDim<<<N, >>>(d_a_one, d_b_one, d_c_one, N);
使用的索引是
int tid = threadIdx.x; //对应的是一个线程块中每个线程id
正确的索引是
int tid = blockIdx.x; //对应的是每个线程块id
CUDA学习(三)之使用GPU进行两个数组相加的更多相关文章
- PHP两个数组相加
在PHP中,当两个数组相加时,会把第二个数组的取值添加到第一个数组上,同时覆盖掉下标相同的值: <?php $a = array("a" => "apple& ...
- PHP基础--两个数组相加
在PHP中,当两个数组相加时,会把第二个数组的取值添加到第一个数组上,同时覆盖掉下标相同的值: <?php $a = array("a" => "apple& ...
- PHP将两个数组相加
$arr_a=[1=>1,2=>2,3=>3];$arr_b=[1=>'a',4=>4];print_r($arr_a+$arr_b);返回结果:Array ( [1] ...
- OpenCL入门:(二:用GPU计算两个数组和)
本文编写一个计算两个数组和的程序,用CPU和GPU分别运算,计算运算时间,并且校验最后的运算结果.文中代码偏多,原理建议阅读下面文章,文中介绍了OpenCL相关名词概念. http://opencl. ...
- CUDA学习(三)之使用GPU进行两个数相加
在CPU上定义两个数并赋值,然后使用GPU核函数将两个数相加并返回到CPU,在CPU上显示 #include "cuda_runtime.h" #include "dev ...
- cuda学习3-共享内存和同步
为什么要使用共享内存呢,因为共享内存的访问速度快.这是首先要明确的,下面详细研究. cuda程序中的内存使用分为主机内存(host memory) 和 设备内存(device memory),我们在这 ...
- CUDA学习,第一个kernel函数及代码讲解
前一篇CUDA学习,我们已经完成了编程环境的配置,现在我们继续深入去了解CUDA编程.本博文分为三个部分,第一部分给出一个代码示例,第二部分对代码进行讲解,第三部分根据这个例子介绍如何部署和发起一个k ...
- CUDA学习笔记3:CUFFT(CUDA提供了封装好的CUFFT库)的使用例子
一.FFT介绍 傅里叶变换是数字信号处理领域一个很重要的数学变换,它用来实现将信号从时域到频域的变换,在物理学.数论.组合数学.信号处理.概率.统计.密码学.声学.光学等领域有广泛的应用.离散傅里叶变 ...
- CUDA学习之二:shared_memory使用,矩阵相乘
CUDA中使用shared_memory可以加速运算,在矩阵乘法中是一个体现. 矩阵C = A * B,正常运算时我们运用 C[i,j] = A[i,:] * B[:,j] 可以计算出结果.但是在CP ...
随机推荐
- [梁山好汉说IT] 区块链在梁山的应用
[梁山好汉说IT] 区块链在梁山的应用 0x00 摘要 区块链属于一种去中心分布式数据存储系统,有其擅长的应用场景,也有其缺点. 下面用梁山为例来阐释下区块链部分概念&应用. 0x01 梁山好 ...
- ABP取其精华
目录 ABP中使用Swagger UI集成接口文档 ABP-AsyncLocal的使用 ABP-多个DbContext实现事物更新 持续更新中.
- TCP/IP|| 建立连接或终止
1.TCP是一个面向连接的协议,在双方发送数据时需要之间建立连接. 当使用telnet命令是连接对应的端口产生TCP连接,通过tcpdump命令查看TCP报文段的输出 源>目的:标志 在标识中有 ...
- 【温故知新】Java web 开发(二)Servlet 和 简单JSP
系列一介绍了新建一个 web 项目的基本步骤,系列二就准备介绍下基本的 jsp 和 servlet 使用. (关于jsp的编译指令.动作指令.内置对象不在本文讨论范围之内) 1. 首先,在 pom. ...
- FRPC 双向socket通讯 转发请求类轮子
一直在找一个能双向通讯的C#库 学识浅薄没有找到 于是封装一个预计BUG奇多的轮子 他是基于SuperSocket开发的 这样的 它跟传统的 架构不一样 它的最小架构 或者 客户端即是服务端 比如一个 ...
- JS进阶——this绑定了谁?
一.this的意义 二.寻找this绑定对象 经常听到这么一句话,找this只需要看谁是调用方.当函数被调用时会记录函数调用调用方式.传参包括this等各种属性.有时候this绑定对象情况太抽象,找到 ...
- Appium Mac系统 自动测试环境搭建
一.python 环境准备 Mac 自带 Python 环境,一般为 2.7 版本. 1.查看当前系统默认的Python路径 which python ==> /usr/bin/python 2 ...
- 【DDD】持久化领域对象的方法实践
[toc] 概述 在实践领域驱动设计(DDD)的过程中,我们会根据项目的所在领域以及需求情况捕获出一定数量的领域对象.设计得足够好的领域对象便于我们更加透彻的理解业务,方便系统后期的扩展和维护,不至于 ...
- cannot open git-upload-pack,cannot open git-receive-pack,Can't connect to any URI错误解决方法eclipse
cannot open git-upload-pack,cannot open git-receive-pack,Can't connect to any URI错误解决方法eclipse 解决ecl ...
- PGSQL 字符串作为查询参数的处理
刚从mysql转到pgsql,不太熟悉用法,今天在查询的时候有一个查询参数是字符串,一直没有这一列的错误 ERROR: column "A 桥梁" does not exist L ...