PLAY2.6-SCALA(七) Streaming HTTP response
1.从HTTP1.1开始,服务端为了在single connection下对HTTP请求及响应提供服务,需要在response中提供响应的Content-Length。
默认情况下,不需要显示的指明Content-Length,比如以下的例子
def index = Action { Ok("Hello World")}
由于发送的内容十分简单,play可以帮助我们计算内容的长度。看一个用于play.http.HttpEntity指明相应体的例子:
def action = Action {
Result(
header = ResponseHeader(200, Map.empty),
body = HttpEntity.Strict(ByteString("Hello world"), Some("text/plain"))
)
}
这表明play在计算Content-Length时需要将整个内容读进内存中。
2.发送大量数据
如果需要发送很大的数据集该如何处理,来看一个给web客户端返回大文件的例子。首先创建为文件创建一个Source[ByteString, _]
val file = new java.io.File("/tmp/fileToServe.pdf")
val path: java.nio.file.Path = file.toPath
val source: Source[ByteString, _] = FileIO.fromPath(path)
用这个流式HttpEntity来指定响应主体
def streamed = Action {
val file = new java.io.File("/tmp/fileToServe.pdf")
val path: java.nio.file.Path = file.toPath
val source: Source[ByteString, _] = FileIO.fromPath(path)
Result(
header = ResponseHeader(200, Map.empty),
body = HttpEntity.Streamed(source, None, Some("application/pdf"))
)
}
这里存在一个问题,由于没有指定内容的长度,play需要将整个文件读到内存中来计算长度。在处理大文件时我们不希望这么处理,我们可以指定内容长度
def streamedWithContentLength = Action {
val file = new java.io.File("/tmp/fileToServe.pdf")
val path: java.nio.file.Path = file.toPath
val source: Source[ByteString, _] = FileIO.fromPath(path)
val contentLength = Some(file.length())
Result(
header = ResponseHeader(200, Map.empty),
body = HttpEntity.Streamed(source, contentLength, Some("application/pdf"))
)
}
在这种模式下Play会使用懒加载的方式,一块块的读取内容。
3.处理文件
Play提供了一种简单的方式来返回本地文件
def file = Action {Ok.sendFile(new java.io.File("/tmp/fileToServe.pdf"))}
这种方式业务根据文件名来计算Content-Type,然后添加Content-Disposition来告诉浏览器该如何处理文件。默认的方式是通过在相应头添加Content-Disposition: inline; filename=fileToServe.pdf显示文件为inline。
也可以提供自己的文件名
def fileWithName = Action {
Ok.sendFile(
content = new java.io.File("/tmp/fileToServe.pdf"),
fileName = _ => "termsOfService.pdf"
)
}
如果希望以attachment的方式提供文件
def fileAttachment = Action {
Ok.sendFile(
content = new java.io.File("/tmp/fileToServe.pdf"),
inline = false
)
}
现在不必指定一个文件名因为浏览器不会尝试去下载文件,仅仅是在窗口中进行展示
4.Chunked response
现在我们可以很好的处理流式文件,但是如果返回的内容是动态生成的,无法提前获取大小,该如何处理?对于这种响应可以使用Chunked transfer encoding
| Chunked transfer encoding是HTTP1.1中一种数据传输方式,用于web服务以 a series of chunks的形式提供内容。使用Transfer-Encoding的响应头来取代Content-Length。由于Content-Length头没有使用,服务端在开始传送响应时不需要知道返回内容的长度。服务端在了解整个内容的长度前,可以以动态生成的方式传输内容。 在传输每个chunk之前会发送这个chunk的大小,所以客户端可以得知chunk的数据是否接收完毕。当最后一个chunk长度为0时整个传输结束。 https://en.wikipedia.org/wiki/Chunked_transfer_encoding |
这么处理的优势是we can serve data live,意味着当数据可用时可以尽快的发送数据。缺点是浏览器不知道整个文件的大小,就无法显示一个正确的下载进度。假设我们有一个服务会提供一个动态的计算一些数据的InputStream。我们可以让Play直接使用chunked response来流化内容。
val data = getDataStream
val dataContent: Source[ByteString, _] = StreamConverters.fromInputStream(() => data)
//We can now stream these data using a Ok.chunked:
def chunked = Action {
val data = getDataStream
val dataContent: Source[ByteString, _] = StreamConverters.fromInputStream(() => data)
Ok.chunked(dataContent)
}
//Of course, we can use any Source to specify the chunked data:
def chunkedFromSource = Action {
val source = Source.apply(List("kiki", "foo", "bar"))
Ok.chunked(source)
}
我们可以看到服务端发来的http响应
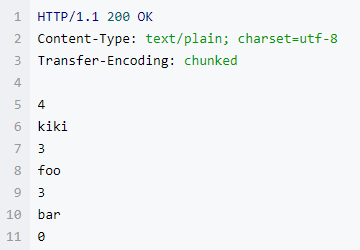
我们得到了三个有数据的chunks和一个空的chunk来结束响应。
PLAY2.6-SCALA(七) Streaming HTTP response的更多相关文章
- Scala(七)【异常处理】
目录 一.try-catch-finally 二.Try(表达式).getOrElse(异常出现返回的默认值) 三. 直接抛出异常 一.try-catch-finally 使用场景:在获取外部链接的时 ...
- play1.x vs play2.x 对比(转)
个人看到对比play1.x和play2.x比较的文章中,写的最深入,最清晰的一个.转自:http://freewind.me/blog/20120728/965.html 为了方便群中的Play初学者 ...
- Spark Streaming源码分析 – JobScheduler
先给出一个job从被generate到被执行的整个过程在JobGenerator中,需要定时的发起GenerateJobs事件,而每个job其实就是针对DStream中的一个RDD,发起一个Spark ...
- R、Python、Scala和Java,到底该使用哪一种大数据编程语言?
有一个大数据项目,你知道问题领域(problem domain),也知道使用什么基础设施,甚至可能已决定使用哪种框架来处理所有这些数据,但是有一个决定迟迟未能做出:我该选择哪种语言?(或者可能更有针对 ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- 【Spark】SparkStreaming-流处理-规则动态更新-解决方案
SparkStreaming-流处理-规则动态更新-解决方案 image2017-10-27_11-10-53.png (1067×738) elasticsearch-head Elasticsea ...
- Play1+angularjs+bootstrap ++ (idea + livereload)
我的web开发最强组合:Play1+angularjs+bootstrap ++ (idea + livereload) 时间 2012-12-26 20:57:26 Freewind.me原文 ...
- Jquery + echarts 使用
常规用法,就不细说了,按照官网一步步来. 本文主要解决问题(已参考网上其他文章): 1.把echarts给扩展到JQuery上,做到更方便调用. 2.多图共存 3.常见的X轴格式化,钻取时传业务实体I ...
- 第二章 微服务网关基础组件 - zuul入门
一.zuul简介 1.作用 zuul使用一系列的filter实现以下功能 认证和安全 - 对每一个resource进行身份认证 追踪和监控 - 实时观察后端微服务的TPS.响应时间,失败数量等准确的信 ...
随机推荐
- PHP数组循环遍历的四种方式
1.使用for循环遍历数组 conut($arr);用于统计数组元素的个数. for循环只能用于遍历,纯索引数组!!!! 如果存在关联数组,count统计时会统计两种数组的总 ...
- 解Bug之路-记一次中间件导致的慢SQL排查过程
解Bug之路-记一次中间件导致的慢SQL排查过程 前言 最近发现线上出现一个奇葩的问题,这问题让笔者定位了好长时间,期间排查问题的过程还是挺有意思的,正好博客也好久不更新了,就以此为素材写出了本篇文章 ...
- struts2-result-servletAPI-获得参数-参数封装
1 结果跳转方式 转发 重定向 转发到Action 重定向到Action 2 访问servletAPI方式 2.1 原理 2.2 获得API 通过ActionContext ★★★★ 通过Servl ...
- Tensorflow技巧
1.尽量控制图片大小在1024以内,不然显存会爆炸. 2.尽量使用多GPU并行工作,训练下降速度快. 3.当需要被检测的单张图片里物体太多时,记得修改Region_proposals的个数 4.测试的 ...
- C# 制作ActiveX控件并添加到网页
1.创建ActiveX控件——按钮 2.定义一个接口,并在控件中实现 3.部署安装 4.CAB打包 5.添加到网页中进行测试 一. 创建ActiveX控件——按钮 1.新建一个Window窗体控件库项 ...
- PHP实现微信小程序支付完整版,可以借鉴!
本文实例为大家分享了php实现小程序支付的具体代码,供大家参考,具体内容如下 环境: tp3.2.3 + 小程序 微信支付功能开通 Step1: 下载PHP 支付SDK(下载地址) 放到Libr ...
- java opencv 4.0.1安装配置
如果没有把dll扔到jdk会报错 Exception in thread "AWT-EventQueue-0" java.lang.UnsatisfiedLinkError: no ...
- 2019.9.24 csp-s模拟测试51(a) 反思总结
T1:还在头铁,顺便复习了一下lct[虽然这题用不上因为复杂度不对] 头铁结束. 虽然题目存在换根的操作,实际上并不用真的换根. 2操作中求lca的时候只要考虑原树上root和x.y的lca以及x,y ...
- 2019-3-1-WPF-从零开始开发-dotnet-Remoting-程序
title author date CreateTime categories WPF 从零开始开发 dotnet Remoting 程序 lindexi 2019-03-01 09:30:45 +0 ...
- iostat统计信息
用途:报告中央处理器(CPU)统计信息和整个系统.适配器.tty 设备.磁盘和 CD-ROM 的输入/输出统计信息. 语法:iostat [ -c | -d ] [ -k ] [ -t | -m ] ...