(转)Android 创建与解析XML—— Dom4j方式 .
转:http://blog.csdn.net/ithomer/article/details/7521605
1、Dom4j概述
dom4j is an easy to use, open source library for working with XML, XPath and XSLT on the Java platform using the Java Collections Framework and with full support for DOM, SAX and JAXP.
dom4j官方网址:dom4j
dom4j源码下载:dom4j download
本示例中,需要导入dom4j.jar包,才能引用dom4j相关类,dom4j源码和jar包,请见本示例【源码下载】或访问 dom4j
org.dom4j包,不仅包含创建xml的构建器类DocumentHelper、Element,而且还包含解析xml的解析器SAXReader、Element,包含类如下:
org.dom4j
org.dom4j.DocumentHelper;
org.dom4j.Element;
org.dom4j.io.SAXReader;
org.dom4j.io.XMLWriter;
org.dom4j.DocumentException;
创建和解析xml的效果图:
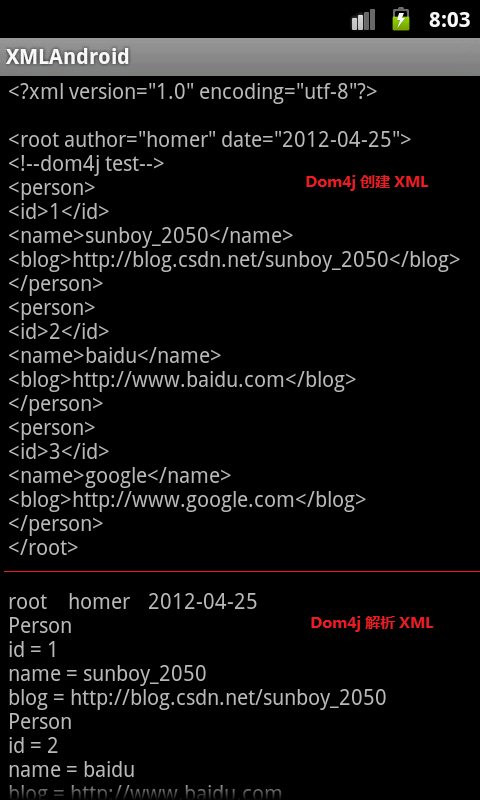
2、Dom4j 创建 XML
Dom4j,创建xml主要用到了org.dom4j.DocumentHelper、org.dom4j.Document、org.dom4j.io.OutputFormat、org.dom4j.io.XMLWriter
首先,DocumentHelper.createDocument(),创建 org.dom4j.Document 的实例 doc
接着,通过doc,设置xml属性doc.setXMLEncoding("utf-8")、doc.addElement("root")根节点,以及子节点等
然后,定义xml格式并输出,new XMLWriter(xmlWriter, outputFormat)
Code
/** Dom4j方式,创建 XML */
public String dom4jXMLCreate(){
StringWriter xmlWriter = new StringWriter();
Person []persons = new Person[3]; // 创建节点Person对象
persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050");
persons[1] = new Person(2, "baidu", "http://www.baidu.com");
persons[2] = new Person(3, "google", "http://www.google.com");
try {
org.dom4j.Document doc = DocumentHelper.createDocument();
doc.setXMLEncoding("utf-8");
org.dom4j.Element eleRoot = doc.addElement("root");
eleRoot.addAttribute("author", "homer");
eleRoot.addAttribute("date", "2012-04-25");
eleRoot.addComment("dom4j test");
int personsLen = persons.length;
for(int i=0; i<personsLen; i++){
Element elePerson = eleRoot.addElement("person"); // 创建person节点,引用类为 org.dom4j.Element
Element eleId = elePerson.addElement("id");
eleId.addText(persons[i].getId()+"");
Element eleName = elePerson.addElement("name");
eleName.addText(persons[i].getName());
Element eleBlog = elePerson.addElement("blog");
eleBlog.addText(persons[i].getBlog());
}
org.dom4j.io.OutputFormat outputFormat = new org.dom4j.io.OutputFormat(); // 设置xml输出格式
outputFormat.setEncoding("utf-8");
outputFormat.setIndent(false);
outputFormat.setNewlines(true);
outputFormat.setTrimText(true);
org.dom4j.io.XMLWriter output = new XMLWriter(xmlWriter, outputFormat); // 保存xml
output.write(doc);
output.close();
} catch (Exception e) {
e.printStackTrace();
}
savedXML(fileName, xmlWriter.toString());
return xmlWriter.toString();
}
运行结果:
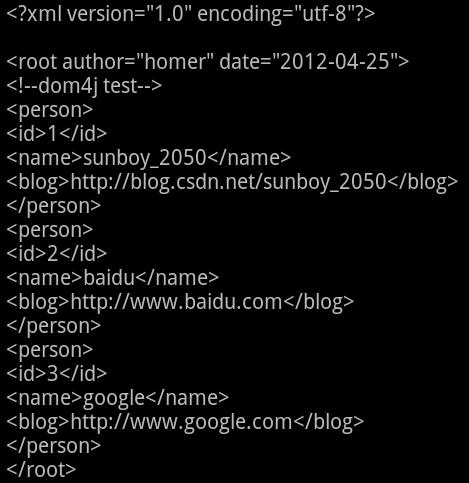
3、Dom4j 解析 XML
Dom4j,解析xml主要用到了org.dom4j.io.SAXReader、org.dom4j.Document、doc.getRootElement(),以及ele.getName()、ele.getText()等
首先,创建SAXReader的实例reader,读入xml字节流 reader.read(is)
接着,通过doc.getRootElement()得到root根节点,利用迭代器取得root下一级的子节点eleRoot.elementIterator()等
然后,得到解析的xml内容xmlWriter.append(xmlHeader)、xmlWriter.append(personsList.get(i).toString())
解析一:标准解析(Iterator 迭代)
Code
/** Dom4j方式,解析 XML */
public String dom4jXMLResolve(){
StringWriter xmlWriter = new StringWriter();
InputStream is = readXML(fileName);
try {
SAXReader reader = new SAXReader();
org.dom4j.Document doc = reader.read(is);
List<Person> personsList = null;
Person person = null;
StringBuffer xmlHeader = new StringBuffer();
Element eleRoot = doc.getRootElement(); // 获得root根节点,引用类为 org.dom4j.Element
String attrAuthor = eleRoot.attributeValue("author");
String attrDate = eleRoot.attributeValue("date");
xmlHeader.append("root").append("\t\t");
xmlHeader.append(attrAuthor).append("\t");
xmlHeader.append(attrDate).append("\n");
personsList = new ArrayList<Person>();
// 获取root子节点,即person
Iterator<Element> iter = eleRoot.elementIterator();
for(; iter.hasNext(); ) {
Element elePerson = (Element)iter.next();
if("person".equals(elePerson.getName())){
person = new Person();
// 获取person子节点,即id、name、blog
Iterator<Element> innerIter = elePerson.elementIterator();
for(; innerIter.hasNext();) {
Element ele = (Element)innerIter.next();
if("id".equals(ele.getName())) {
String id = ele.getText();
person.setId(Integer.parseInt(id));
} else if("name".equals(ele.getName())) {
String name = ele.getText();
person.setName(name);
} else if("blog".equals(ele.getName())) {
String blog = ele.getText();
person.setBlog(blog);
}
}
personsList.add(person);
person = null;
}
}
xmlWriter.append(xmlHeader);
int personsLen = personsList.size();
for(int i=0; i<personsLen; i++) {
xmlWriter.append(personsList.get(i).toString());
}
} catch (DocumentException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
return xmlWriter.toString();
}
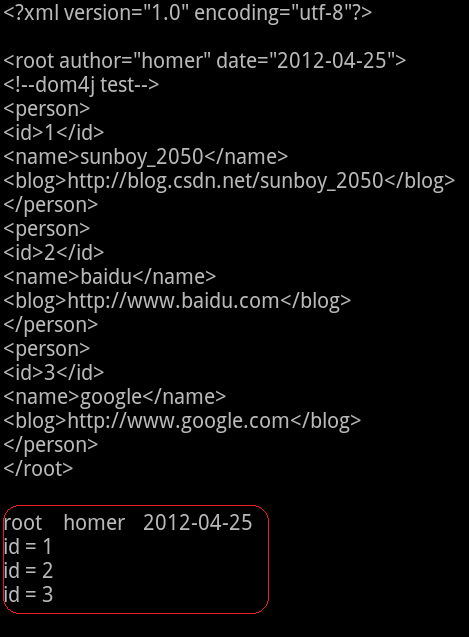
运行结果:

解析二:选择性解析(XPath路径)
Dom4j+XPath,选择性只解析id,doc.selectNodes("//root//person//id")
Code
/** Dom4j方式,解析 XML(方式二) */
public String dom4jXMLResolve2(){
StringWriter xmlWriter = new StringWriter();
InputStream is = readXML(fileName);
try {
org.dom4j.io.SAXReader reader = new org.dom4j.io.SAXReader();
org.dom4j.Document doc = reader.read(is);
List<Person> personsList = null;
Person person = null;
StringBuffer xmlHeader = new StringBuffer();
Element eleRoot = doc.getRootElement(); // 获得root根节点,引用类为 org.dom4j.Element
String attrAuthor = eleRoot.attributeValue("author");
String attrDate = eleRoot.attributeValue("date");
xmlHeader.append("root").append("\t\t");
xmlHeader.append(attrAuthor).append("\t");
xmlHeader.append(attrDate).append("\n");
personsList = new ArrayList<Person>();
@SuppressWarnings("unchecked")
List<Element> idList = (List<Element>) doc.selectNodes("//root//person//id"); // 选择性获取全部id
Iterator<Element> idIter = idList.iterator();
while(idIter.hasNext()){
person = new Person();
Element idEle = (Element)idIter.next();
String id = idEle.getText();
person.setId(Integer.parseInt(id));
personsList.add(person);
}
xmlWriter.append(xmlHeader);
int personsLen = personsList.size();
for(int i=0; i<personsLen; i++) {
xmlWriter.append("id = ").append(personsList.get(i).getId()+"").append("\n");
}
} catch (DocumentException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
return xmlWriter.toString();
}
注:借助 XPath 解析 XML 时,需要导入 jaxen;本示例需要导入的是最新的jaxen包jaxen-1.1.3.jar,可以下载本示例下面【源码下载】或 访问 jaxen jar
Jaxen is an open source XPath library written in Java. It is adaptable to many different object models, including DOM, XOM, dom4j, and JDOM. Is it also possible to write adapters that treat non-XML trees such as compiled Java byte code or Java beans as XML, thus enabling you to query these trees with XPath too.
jaxen 官方网址:jaxen
jaxen下载jar包:jaxen jar 或 jaxen jar
jaxen源码查看:jaxen src 或 jaxen trunk
运行结果:
(转)Android 创建与解析XML—— Dom4j方式 .的更多相关文章
- 使用dom4j创建和解析xml
之前工作中用到了,相信写java的都会碰到xml,这里写了两个方法,创建和解析xml,废话不多说,直接上代码 package xml; import java.io.File; import java ...
- 使用dom4j创建和解析xml文件
使用dom4j创建和解析xml文件 在项目开发中,我们经常会遇到xml文件的创建和解析从别人接口得到的xml文件,而我们最常使用的组件是dom4j. 下面我就以代码来讲解一下如何使用dom4j来创建x ...
- Android中用PULL解析XML
解析XML的方式有DOM,SAX,PULL,那为什么要在Android中使用PULL解析呢?首先来说一下PULL解析的优点,然后再说一下其他两种解析方式的缺点,答案就清晰可见啦. DOM不适合文档较大 ...
- dom4j创建和解析xml文档
DOM4J解析 特征: 1.JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功能. 2.它使用接口和抽象基本类方法. 3.具有性能优异.灵活性好.功能强大和极端易用的特点. 4.是一个开 ...
- Android几种解析XML方式的比较
https://blog.csdn.net/isee361820238/article/details/52371342 一.使用SAX解析XML SAX(Simple API for XML) 使用 ...
- Android之Pull解析XML
一.Pull解析方法介绍 除了可以使用SAX和DOM解析XML文件,也可以使用Android内置的Pull解析器解析XML文件.Pull解析器的运行方式与SAX解析器相似.它也是事件触发的.Pull解 ...
- Android之SAX解析XML
一.SAX解析方法介绍 SAX(Simple API for XML)是一个解析速度快并且占用内存少的XML解析器,非常适合用于Android等移动设备. SAX解析器是一种基于事件的解析器,事件驱动 ...
- Android使用pull解析xml
一.理论准备 Pull解析器的运行方式与 SAX 解析器相似.它提供了类似的事件,如:开始元素和结束元素事件,使用parser.next()可以进入下一个元素并触发相应事件.跟SAX不同的是, ...
- Android之DOM解析XML
一.DOM解析方法介绍 DOM是基于树形结构的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树,检索所需数据.分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息 ...
随机推荐
- FromBase64String(String)和Encoding.Default.GetBytes(String)
今天突然被问FromBase64String(String)和Encoding.Default.GetBytes(String)有啥区别,我刚开始学C#对这个一脸懵逼,于是总结一下今天查资料的内容. ...
- C#接口的作用实例解析
一.接口的作用: 我们定义一个接口: public interface IBark { void Bark(); } 1. 再定义一个类,继承于IBark,并且必需实现其中的Bark()方法 pub ...
- 【基础】Linux软件安装方法
linux中wget .apt-get.yum rpm区别 wget 类似于迅雷,是一种下载工具, 通过HTTP.HTTPS.FTP三个最常见的TCP/IP协议下载,并可以使用HTTP代理 名字是Wo ...
- PHP ftp_chdir() 函数
定义和用法 ftp_chdir() 函数改变 FTP 服务器上的当前目录为指定目录. 如果成功,该函数返回 TRUE.如果失败,则返回 FALSE 和一个警告. 语法 ftp_chdir(ftp_co ...
- aspcms 这个靶场。。。
这个网站源码是我打 webug 里收集的靶场,但是由于我自己水平菜的不行,没搭建成功 = =!然后,我也就懒的搞,就给我一朋友,在他的公网服务器上搭上这个站,好让我玩玩.由于上次我朋友靶场发生挂黑页的 ...
- 虚拟机安装VMware Tools, 安装gcc编译器
一.虚拟机安装VMware Tools 1.虚拟机=>安装VMware Tools 2.打开文件,将下载的压缩包VMwareTools-10.3.10-12406962.tar.gz移动到指定安 ...
- jquery 临时存值
function toSort(orderBy) { if (orderBy == $('#orderBy').data("order")) {// 再次点击同一个排序时 $('# ...
- QT MSVC2017 ratio chrono
如果引用了stdint.h可能会引发一些列错误,各种未申明和语法错误. 参加以下帖子解决问题 https://github.com/ftylitak/qzxing/issues/54 When com ...
- 无法CREATE UNIQUE INDEX;找到重复的关键字
- add new color number to the color drop down in enovia PLM
Ticket description:A55482L Ticket attachment: Open the attached page 2. Open the internationalizing ...