hadoop2.x 完全分布式详细集群搭建(图文:4台机器)
在准备之前说一下本次搭建的各节点角色,进程。
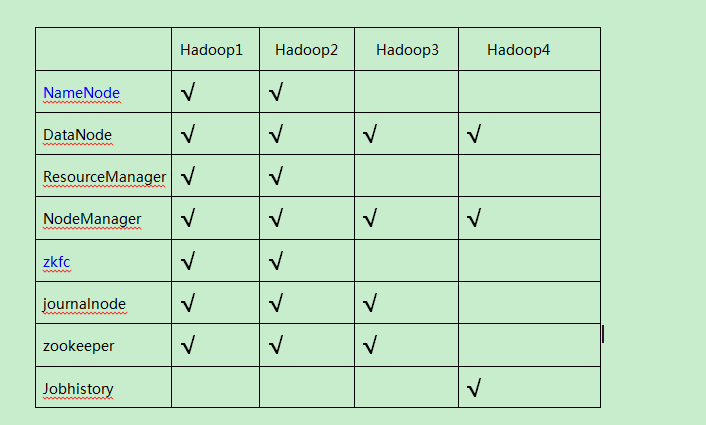
nameNode 进程:NameNode
dataNode 进程:DataNode
resourceManager :ResourceManager
nodeManeger : NodeManager
zkfc:DFSZKFailoverController
journalnode: JournalNode
zookeeper: QuorumPeerMain
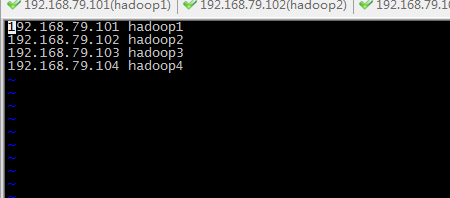
我的IP:
192.168.79.101 hadoop1
192.168.79.102 hadoop2
192.168.79.103 hadoop3
192.168.79.104 hadoop4
一:准备
1. 修改Linux主机名:
命令:vim /etc/sysconfig/network
 HOSTNAME 主机名
HOSTNAME 主机名
2. 修改IP为静态IP:
(第一种方式)
进入图形界面 -> 点击右上角的俩个小电脑图标 -> 右键 -> edit connections -> ipv4 -> manual -> 点击add按钮 -> 添加IP,NETMASK, GATEWAY,如果可以的话建议使用第一种方式。
(第二种通过修改文件) vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" ###
HWADDR="00:0C:29:3C:BF:E7"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"
IPADDR="192.168.1.119" ###
NETMASK="255.255.255.0" ###
GATEWAY="192.168.1.1" ###
3. 配置主机名和IP的映射关系,每个机器都是这样一个文件。
命令:vim /etc/hosts
4. 关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
5. 配置各个节点之间的免登陆。
生成ssh免登陆密钥 : ssh-keygen -t rsa
为了简单,一直回车即可。各个节点都执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
我这里以hadoop1 到2,3,4为例。其余各节点操作一样。
将公钥拷贝到要免登陆的机器上
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
或
ssh-copy-id -i hadoop1
将公钥拷贝到其他节点,包括自己(期间会提示输入密码):
ssh-copy-id -i hadoop1
ssh-copy-id -i hadoop2
ssh-copy-id -i hadoop3
ssh-copy-id -i hadoop4
其他节点同样操作。最后每个机器的 /root/.ssh 中 authorized_keys文件会有四个公钥。
在hadoop1上执行 ssh hadoop2
二: 各节点安装JDK,hadoop,(hadoop1,hadoop2,hadoop3上安装zookeeper),并配置环境变量
1. 上传jdk,hadoop,zookeeper
2. 添加执行权限

3. 解压。我把他们解压到 /usr/local/tools 下
4. 各个节点配置环境变量:
命令: vim /etc/profile
针对我自己的路径,配置如下:
export JAVA_HOME=/usr/local/tools/jdk1.7.0_75
export HADOOP_HOME=/usr/local/tools/hadoop-2.2.0
export ZK_HOME=/usr/local/tools/zookeeper-3.4.5
export CLASSPATH=.:%JAVA_HOME%/lib/dt.jar:%JAVA_HOME%/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin

然后执行 source /etc/profile 使其生效。验证,例如执行 java -version
三:配置hadoop
基本要配置4个配置文件,core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml
1. 配置core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property> <property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property> <property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
fs.defaultFS:指定hdfs的nameservice为ns1
hadoop.tmp.dir:指定hadoop临时目录
ha.zookeeper.quorum:指定zookeeper地址
2. 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property> <property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property> <property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop1:9000</value>
</property> <property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop1:50070</value>
</property> <property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop2:9000</value>
</property> <property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop2:50070</value>
</property> <property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1</value>
</property> <property>
<name>dfs.ha.automatic-failover.enabled.ns1</name>
<value>true</value>
</property> <property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> <property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/journal</value>
</property> <property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property> <property>
<name>dfs.data.dir</name>
<value>/usr/local/data</value>
</property> <property>
<name>dfs.datanode.socket.write.timeout</name>
<value>0</value>
</property> <property>
<name>dfs.replication</name>
<value>3</value>
</property> </configuration>
dfs.nameservices: 指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致
dfs.ha.namenodes.ns1:ns1下面有两个NameNode,分别是nn1,nn2
dfs.namenode.rpc-address.ns1.nn1: nn1的RPC通信地址
dfs.namenode.http-address.ns1.nn1: nn1的http通信地址
dfs.namenode.shared.edits.dir:指定NameNode的元数据在JournalNode上的存放位置
dfs.journalnode.edits.dir : 指定JournalNode在本地磁盘存放数据的位置
dfs.ha.automatic-failover.enabled: true是开启NameNode失败自动切换
dfs.client.failover.proxy.provider.ns1:配置失败自动切换实现方式
dfs.ha.fencing.ssh.private-key-files:使用sshfence隔离机制时需要ssh免登陆
3. 配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/yarn/hadoop/nmdir</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/yarn/logs</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>hdfs://ns1/var/log/hadoop-yarn/apps</value>
</property>
<!-- Resource Manager Configs -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>ns1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!-- RM1 configs -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop1:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop1:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>hadoop1:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop1:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop1:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hadoop1:23141</value>
</property>
<!-- RM2 configs -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop2:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop2:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>hadoop2:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop2:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop2:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hadoop2:23141</value>
</property>
<!-- Node Manager Configs -->
<property>
<description>Address where the localizer IPC is.</description>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
<property>
<description>NM Webapp address.</description>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/yarn/nodemanager/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/yarn/nodemanager/yarn/log</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
</configuration>
4. 配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- configure historyserver -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop4:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop4:19888</value>
</property>
<property>
<name>mapred.job.reuse.jvm.num.tasks</name>
<value>-1</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>20</value>
</property>
</configuration>
5. 配置slaves文件
和上述文件在同一个目录中的slaves文件,写入:
hadoop1
hadoop2
hadoop3
hadoop4
四:启动hadoop集群(步骤很重要)
1. 启动zookeeper集群(hadoop1,hadoop2,hadoop3上执行)
执行 : zkServer.sh start
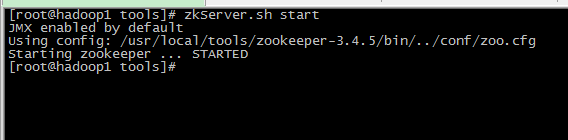
三个节点都启动后查看状态,一个 leader 两个follower
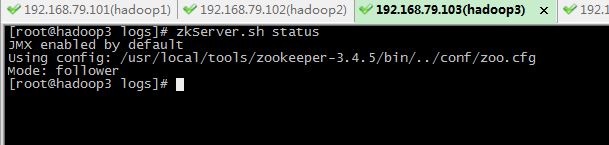
此时执行jps查看进程,启动了QuorumPeerMain
2. 启动journalnode (hadoop1,hadoop2,hadoop3上执行)
执行: hadoop-daemon.sh start journalnode

此时查看进程,多了JournalNode进程
3. 格式化HDFS(hadoop1上执行)
执行: hdfs namenode -format
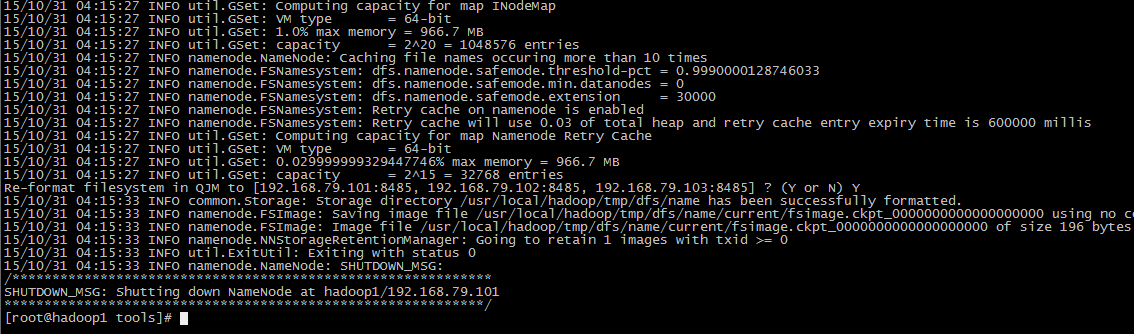
4. 格式化ZK
执行:hdfs zkfc -formatZK
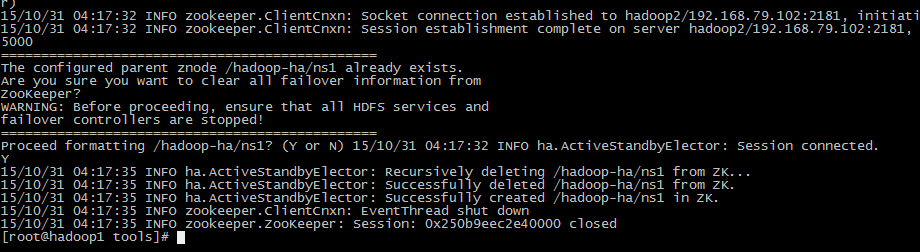
5. 启动hadoop1的namenode,zkfc
执行: hadoop-daemon.sh start namenode , hadoop-daemon.sh start zkfc
此时查看进程,zkfc,namenode都启动了。

6. hadoop2上数据同步格式化的hadoop1上的hdfs
执行: hdfs namenode -bootstrapStandby
然后同hadoop1一样启动namenode和zkfc。
7. 启动HDFS:
执行:start-dfs.sh
8. hadoop1,hadoop2启动YARN
执行:start-yarn.sh
9. hadoop4上启动 JobHistoryServer
执行: mr-jobhistory-daemon.sh start historyserver
现在全部启动好了。然后看看各节点功能和进程是否对应启动好。
至此。都已启动好。可通过浏览器访问:
1. http://192.168.79.101:50070
NameNode 'hadoop1:9000' (standby)
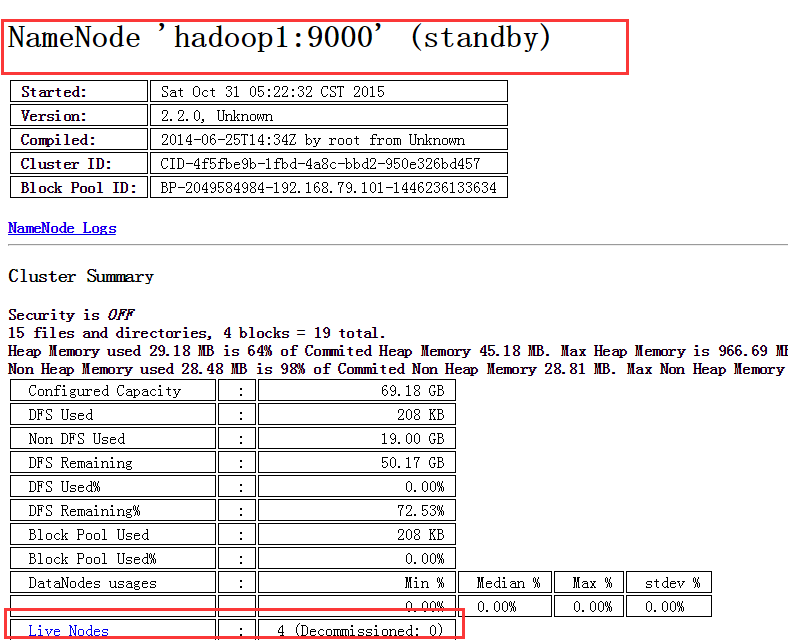
2. http://192.168.79.102:50070
NameNode 'hadoop2:9000' (active)

3. http://192.168.79.104:19888/

4. http://192.168.79.102:8088/
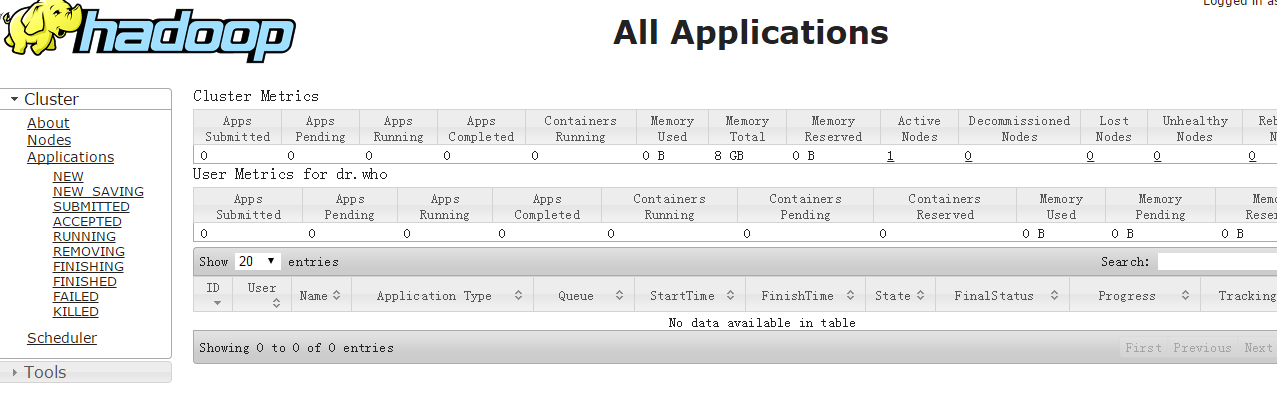
五. 验证
1. 验证hdfs HA
首先向hdfs上传一个文件: hadoop fs -put /usr/local/soft/jdk-7u75-linux-x64.gz /soft
然后查看: hadoop fs -ls /

然后再kill掉active的NameNode。然后浏览器访问 看到 hadoop1变成active的了。
在执行命令:hadoop fs -ls /
文件还在。然后再启动刚才停掉的namenode 。然后访问,变成standby的了。
2. 验证YARN
运行一下hadoop提供的demo中的WordCount程序:
自己写了个word.txt 写入几个单词测试 :
hello jerry
hello tom
hello world
上传word.txt 到hdfs: hadoop fs -put /home/word.txt /input

然后运行: hadoop jar /usr/local/tools/hadoop-2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /input /out
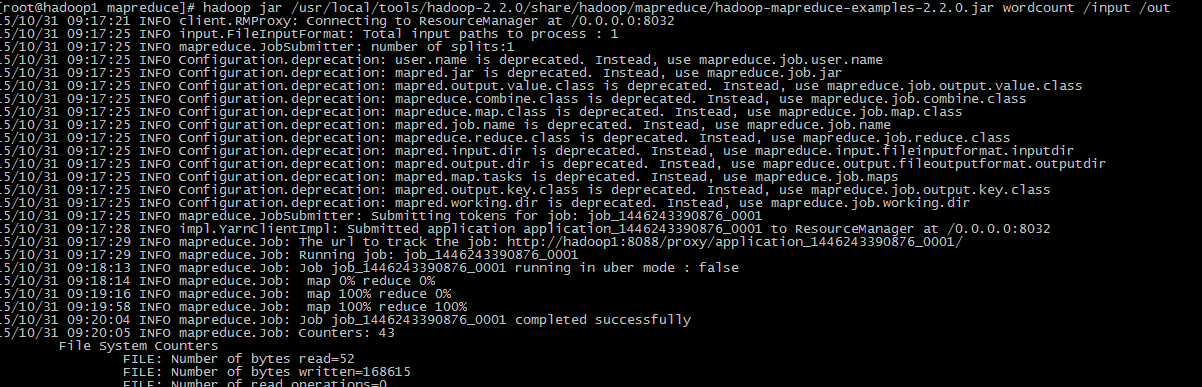
成功后查看: 按照自己的目录,我的命令是写入到out 目录 。


OK,至此就完成hadoop学习的第一课了。
hadoop2.x 完全分布式详细集群搭建(图文:4台机器)的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- kubernetes(K8S)快速安装与配置集群搭建图文教程
kubernetes(K8S)快速安装与配置集群搭建图文教程 作者: admin 分类: K8S 发布时间: 2018-09-16 12:20 Kubernetes是什么? 首先,它是一个全新的基于容 ...
- 集群中配置多台机器之间 SSH 免密码登录
集群中配置多台机器之间 SSH 免密码登录 问题描述 由于现在项目大多数由传统的单台机器部署,慢慢转变成多机器的集群化部署. 但是,这就涉及到机器间的 SSH 免密码互通问题. 当集群机器比较多的时候 ...
- Hadoop2.6.5高可用集群搭建
软件环境: linux系统: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3, m4, m5这五部机, 每部主机的用户名 ...
- Zookeeper详解-伪分布式和集群搭建(八)
说到分布式开发Zookeeper是必须了解和掌握的,分布式消息服务kafka .hbase 到hadoop等分布式大数据处理都会用到Zookeeper,所以在此将Zookeeper作为基础来讲解. Z ...
- kafka集群搭建(图文并用)
将安装包上传服务器并解压 scp kafka_2.11-1.0.0.tgz username@{ip}:~/. mkdir /usr/local/kafka mv kafka_2.11-1.0.0.t ...
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~)
http://blog.csdn.net/licongcong_0224/article/details/12972889 历时一周多,终于搭建好最新版本hadoop2.2集群,期间遇到各种问题,作为 ...
- hadoop2.6.4的HA集群搭建超详细步骤
hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA.YARN等.最新的hadoop-2.6.4又增加了YARN HA 注意:apache提供的hadoop-2.6.4的安装包是 ...
- Hadoop2.7.4 yarn(HA)集群搭建步骤(CentOS7)
群节点分配: Park01:Zookeeper.NameNode(active).ResourceManager(active) Park02:Zookeeper.NameNode(standby) ...
随机推荐
- exe4j 打包(多个jar打包)
一,自行下载exe4j 注册码: 用户名和公司名可随便填A-XVK258563F-1p4lv7mg7savA-XVK209982F-1y0i3h4ywx2h1A-XVK267351F-dpurrhny ...
- mysql 存储过程学习 汇总
存储过程框架 DEMILITER $$ -- 重定义符 DROP PROCEDURE IF EXISTS store_procedure$$ -- 如果存在此名的存储过程,先删除 CREATE PRO ...
- CF774L Bars
题意:给你一个二进制表示是否可以吃巧克力.一共有k个巧克力,第一天和最后一天必须吃.最小化每两次吃巧克力的最大间隔? 标程: #include<bits/stdc++.h> using n ...
- Oracle18C安装后首次创建数据库并用sql developer 创建连接和用户
注意: SQL Developer 不能用于创建Oracle数据库,只能用来连接已经创建的数据库,数据库的建立要通过Database Configuration Assistant(DBCA)来完成. ...
- [JZOJ4665] 【GDOI2017模拟7.21】数列
题目 题目大意 给你一个数列,让你找到一个最长的连续子序列,满足在添加了至多KKK个数之后,能够变成一条公差为DDD的等差数列. 思考历程 一眼看上去似乎是一道神题-- 没有怎么花时间思考,毕竟时间都 ...
- 一张图轻松掌握 Flink on YARN 应用启动全流程(上)
Flink 支持 Standalone 独立部署和 YARN.Kubernetes.Mesos 等集群部署模式,其中 YARN 集群部署模式在国内的应用越来越广泛.Flink 社区将推出 Flink ...
- kubernetes配置(kubeconfig)对多集群的访问
配置对多集群的访问 本文展示如何使用配置文件来配置对多个集群的访问. 在将集群.用户和上下文定义在一个或多个配置文件中之后,用户可以使用 kubectl config use-context 命令快速 ...
- 主页面与iframe页面之间的javascript函数的调用
1:在主页面里调用iframe页里面的javascript函数 <script type="text/javascript"> var childWindow = $( ...
- neo4j安装APOC插件
1.APOC下载地址:https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/3.4.0.1 只要下载.jar这一个压缩文件就好 ...
- 判断Paging File 的方法
当前环境,MiniFilter 1:FsRtlIsPagingFile 参数是一个 FileObject 2:判断操作标识 SL_OPEN_PAGING_FILE FlagOn 宏可以直接做到,传 ...