分布式唯一ID实现
ID生成的核心需求
全局唯一
趋势有序
为什么要全局唯一
避免ID冲突
著名的例子就是身份证号码,身份证号码确实是对人唯一的,然而一个人是可以办理多个身份证的,例如你身份证丢了,又重新补办了一张,号码不变。
问题来了,因为系统是按照身份证号码做唯一主键的。此时,如果身份证是被盗的情况下,你是没有办法在系统里面注销的,因为新旧2个身份证的“主键”都是身份证号码。
也就是说,旧的身份证仍然逍遥在外,完全有效。这个时候,还好有一个身份证有效时间的东西,只有靠身份证有效期来辨识了。不过,这就是现在这么多银行,电信诈骗的由来,捡到一张身份证,去很多银行,手机,酒店都可以使用!身份证缺乏注销机制!
所以,经验告诉我们。不要相信自己的直觉,业务上所谓的唯一往往都是不靠谱的,经不起时间的考研的。所以需要单独设置一个和业务无关的主键,专业术语叫做代理主键(surrogate key)。
为什么要趋势有序
提高读写性能
以mysql为例,InnoDB引擎表是基于B+树的索引组织表(IOT);每个表都需要有一个聚集索引(clustered index);所有的行记录都存储在B+树的叶子节点(leaf pages of the tree);基于聚集索引的增、删、改、查的效率相对是最高的;如下图:
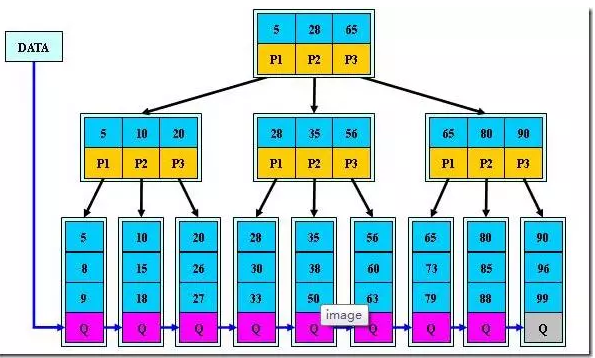
如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择其作为聚集索引;
如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引;
如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
综上总结,如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高
使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致;
除此以外,如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时(例如字符串、UUID、多字段联合唯一索引的情况),该表的存取效率就会比较差)
面对分布式ID需求,常见的处理方案
1.数据库自增长序列或字段
利用数据库自增长,全局数据库唯一。
优点:
- 简单,代码方便
缺点:
- 兼容性低:不同的数据库语法和实现不同,数据库多版本支持的时候需要作调整。
- 存在单点故障风险:在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。
- 扩展性低:性能达不到要求,难以扩展。
- 多个数据库合并或者涉及到迁移操作难度大。
- 分库分表麻烦。
2.UUID
利用数据库或者程序生成,全球唯一。
优点:
- 简单,代码方便。
- 生成ID性能好,基本不会有性能问题。
- 数据迁移,数据合并,数据库变更。都可以简单进行。
缺点:
- 不能保证趋势递增。
- UUID一般采用字符串存储,查询效率低。
- 存储空间大。
- 传输数据量大。
- 不可读。
3.Redis生成ID
Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,随便负载到哪个机确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 数据中ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 如果系统中没有Redis,还需要引进新的组件,增加系统复杂度。
- 需要编码和配置的工作量比较多。
4.Twitter
twitter在把存储系统从MySQL迁移到Cassandra的过程中由于Cassandra没有顺序ID生成机制,于是自己开发了一套全局唯一ID生成服务:Snowflake。
1 41位的时间序列(精确到毫秒,41位的长度可以使用69年)
2 10位的机器标识(10位的长度最多支持部署1024个节点)
3 12位的计数顺序号(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号) 最高位是符号位,始终为0。
优点:
- 高性能,低延迟;独立的应用。
- 按时间有序。
缺点:
- 需要独立的开发和部署。
- 强依赖时钟,如果主机时间回拨,则会造成重复ID,会产生。
- ID虽然有序,但是不连续。
原理:

5.MongoDB的ObjectId
MongoDB的ObjectId和snowflake算法类似。它设计成轻量型的,不同的机器都能用全局唯一的同种方法方便地生成它。MongoDB 从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求。使其在分片环境中要容易生成得多。
ObjectId使用12字节的存储空间,其生成方式如下:
|0|1|2|3|4|5|6 |7|8|9|10|11|
|时间戳 |机器ID|PID|计数器 |
前四个字节时间戳是从标准纪元开始的时间戳,单位为秒,有如下特性:
1 时间戳与后边5个字节一块,保证秒级别的唯一性;
2 保证插入顺序大致按时间排序;
3 隐含了文档创建时间;
4 时间戳的实际值并不重要,不需要对服务器之间的时间进行同步(因为加上机器ID和进程ID已保证此值唯一,唯一性是ObjectId的最终诉求)。
机器ID是服务器主机标识,通常是机器主机名的散列值。
同一台机器上可以运行多个mongod实例,因此也需要加入进程标识符PID。
前9个字节保证了同一秒钟不同机器不同进程产生的ObjectId的唯一性。后三个字节是一个自动增加的计数器(一个mongod进程需要一个全局的计数器),保证同一秒的ObjectId是唯一的。同一秒钟最多允许每个进程拥有(256^3 = 16777216)个不同的ObjectId。
总结一下:时间戳保证秒级唯一,机器ID保证设计时考虑分布式,避免时钟同步,PID保证同一台服务器运行多个mongod实例时的唯一性,最后的计数器保证同一秒内的唯一性(选用几个字节既要考虑存储的经济性,也要考虑并发性能的上限)。
"_id"既可以在服务器端生成也可以在客户端生成,在客户端生成可以降低服务器端的压力。
6.类snowflake算法
国内有很多厂家基于snowflake算法进行了国产化,例如
百度的uid-generator:
https://github.com/baidu/uid-generator
美团Leaf:
https://github.com/zhuzhong/idleaf
基本是对snowflake的进一步优化,比如解决时钟 回拨问题!
总结
分布式ID满足条件:
- 高可用:不能有单点故障。
- 全局唯一性:不能出现重复的ID。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 时间有序:少一个索引,冷热数据容易分离。
- 分片支持:可以控制ShardingId。比如某一个用户的文章要放在同一个分片内,这样查询效率高,修改也容易。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 长度适中:不要太长,最好64bit。使用long比较好操作。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞争对手可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
本文参考:https://mp.weixin.qq.com/s/cgCElpjlKcJIE-d3d7JfjQ
分布式唯一ID实现的更多相关文章
- 分布式唯一id:snowflake算法思考
匠心零度 转载请注明原创出处,谢谢! 缘起 为什么会突然谈到分布式唯一id呢?原因是最近在准备使用RocketMQ,看看官网介绍: 一句话,消息可能会重复,所以消费端需要做幂等.为什么消息会重复后续R ...
- 分布式唯一id生成器的想法
0x01 起因 前端时间遇到一个问题,怎么快速生成唯一的id,后来采用了hashid的方法.最近在网上读到了美团关于分布式唯一id生成器的解决方案, 其中提到了三种生成法:(建议看一下这篇文章,写得很 ...
- 分布式唯一ID极简教程
原创 2017-11-21 帝都羊 架构师小秘圈 一,题记 所有的业务系统,都有生成ID的需求,如订单id,商品id,文章ID等.这个ID会是数据库中的唯一主键,在它上面会建立聚集索引! ID生成的核 ...
- 分布式唯一ID生成算法-雪花算法
在我们的工作中,数据库某些表的字段会用到唯一的,趋势递增的订单编号,我们将介绍两种方法,一种是传统的采用随机数生成的方式,另外一种是采用当前比较流行的“分布式唯一ID生成算法-雪花算法”来实现. 一. ...
- 百度开源的分布式唯一ID生成器UidGenerator,解决了时钟回拨问题
UidGenerator是百度开源的Java语言实现,基于Snowflake算法的唯一ID生成器.而且,它非常适合虚拟环境,比如:Docker.另外,它通过消费未来时间克服了雪花算法的并发限制.Uid ...
- 关于分布式唯一ID,snowflake的一些思考及改进(完美解决时钟回拨问题)
1.写唯一ID生成器的原由 在阅读工程源码的时候,发现有一个工具职责生成一个消息ID,方便进行全链路的查询,实现方式特别简单,核心源码不过两行,根据时间戳以及随机数生成一个ID,这种算法ID在分布式系 ...
- 分布式唯一ID生成方案选型!详细解析雪花算法Snowflake
分布式唯一ID 使用RocketMQ时,需要使用到分布式唯一ID 消息可能会发生重复,所以要在消费端做幂等性,为了达到业务的幂等性,生产者必须要有一个唯一ID, 需要满足以下条件: 同一业务场景要全局 ...
- 开源项目|Go 开发的一款分布式唯一 ID 生成系统
原文连接: 开源项目|Go 开发的一款分布式唯一 ID 生成系统 今天跟大家介绍一个开源项目:id-maker,主要功能是用来在分布式环境下生成唯一 ID.上周停更了一周,也是用来开发和测试这个项目的 ...
- 讲分布式唯一id,这篇文章很实在
分布式唯一ID介绍 分布式系统全局唯一的 id 是所有系统都会遇到的场景,往往会被用在搜索,存储方面,用于作为唯一的标识或者排序,比如全局唯一的订单号,优惠券的券码等,如果出现两个相同的订单号,对于用 ...
- .Net下的分布式唯一ID
分布式唯一ID,顾名思义,是指在全世界任何一台计算机上都不会重复的唯一Id. 在单机/单服务器/单数据库的小型应用中,不需要用到这类东西.但在高并发.海量数据.大型分布式应用中,这类却是构建整个系统的 ...
随机推荐
- Linxu下JMeter进行接口压力测试
****************************************************************************** 本文主要介绍Jmeter脚本如何在Linx ...
- CDH6.1.0离线安装——笔记
一. 概述 该文档主要记录大数据平台的搭建CDH版的部署过程,以供后续部署环境提供技术参考. 1.1 主流大数据部署方法 目前主流的hadoop平台部署方法主要有以下三种: Apache hadoop ...
- leetcode.数组.16最接近的三数之和-java
1. 具体题目 给定一个包括 n 个整数的数组 nums 和 一个目标值 target.找出 nums 中的三个整数,使得它们的和与 target 最接近.返回这三个数的和.假定每组输入只存在唯一答案 ...
- python全栈开放实践第三版第一章的练习题完成情况
练习题: 1.简述编译型与解释型语言的区别,且分别列出你知道哪些语言属于编译型,哪些数以解释型.1 编译型:只须编译一次就可以把源代码编译成机器语言,后面的执行无须重新编译,直接使用之前的编译结果就可 ...
- gulp+sass+react前端开发,环境搭建
由于前端技术的发展与市场需求的提高,前端开发已经不仅仅是写几个页面那么简单.如何有效的开发.管理一个越来越庞大.越来越复杂的前端项目,成为互联网团队必须要面对的难题. 各种js库.ui库曾经火极一时. ...
- 22-7map
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- uname - 显示输出系统信息
总览 uname [OPTION]... 描述 显示相应的系统信息. 没有指定选项时,同 -s. -a, --all 显示所有的信息 -m, --machine 显示机器(硬件)类型 -n, --no ...
- Deb版本Linux配置Selenium+Chrome+Java实现自动化测试
1.安装chrome sudo apt-get install libxss1 libappindicator1 libindicator7 wget https://dl.google.com/li ...
- main中的argc,argv
那么我们运行程序时,传入的参数,就是这个argc的值:从截图中,我们很清楚的可以看出,argc是传入参数的个数,”传入的参数“加上可执行文件的文件名:
- Promise 解决同步请求问题
在写小程序和vue项目中,由于 api 不提供 同步请求,因此,可以通过 Promise 来实现 同步请求操作 在这里 对于 Promise 不太了解的小伙伴 可以查找 Promise 的api 文 ...