spark 应用场景1-求年龄平均值
原文引自:http://blog.csdn.net/fengzhimohan/article/details/78535143
该案例中,我们将假设我们需要统计一个 10 万人口的所有人的平均年龄,当然如果您想测试 Spark 对于大数据的处理能力,您可以把人口数放的更大,比如 1 亿人口,当然这个取决于测试所用集群的存储容量。假设这些年龄信息都存储在一个文件里,并且该文件的格式如下,第一列是 ID,第二列是年龄。如下图格式:
以下利用java随机生成10万个人口年龄文件
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Random; /**
* Created by Administrator on 2017/11/13.
*/
public class DataFileGenerator {
public static void main(String[] args){
File file = new File("F:\\DataFile.txt");
try {
FileWriter fileWriter = new FileWriter(file);
Random rand = new Random();
for (int i=1;i<=100000;i++){
fileWriter.write(i +" " + (rand.nextInt(100)+1));
fileWriter.write(System.getProperty("line.separator"));
}
fileWriter.flush();
fileWriter.close(); }catch(IOException e){
e.printStackTrace();
}
}
}
场景分析:
要计算平均年龄,那么首先需要对源文件对应的 RDD 进行处理,也就是将它转化成一个只包含年龄信息的 RDD,其次是计算元素个数即为总人数,然后是把所有年龄数加起来,最后平均年龄=总年龄/人数。
对于第一步我们需要使用 map 算子把源文件对应的 RDD 映射成一个新的只包含年龄数据的 RDD,很显然需要对在 map 算子的传入函数中使用 split 方法,得到数组后只取第二个元素即为年龄信息;第二步计算数据元素总数需要对于第一步映射的结果 RDD 使用 count 算子;第三步则是使用 reduce 算子对只包含年龄信息的 RDD 的所有元素用加法求和;最后使用除法计算平均年龄即可。
以下实现对平均年龄的计算的代码:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import java.util.Arrays; /**
* Created by Administrator on 2017/11/13.
*/
public class AvgAgeCalculator {
public static void main(String[] args){ SparkConf sparkConf = new SparkConf().setAppName("AvgAgeCalculator").setMaster("local[3]");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
//读取文件
JavaRDD<String> dataFile = sc.textFile("F:\\DataFile.txt");
//数据分片并取第二个数
JavaRDD<String> ageData = dataFile.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")[1]);
}
});
//求出所有年龄个数。
long count = ageData.count();
//转换数据类型
JavaRDD<Integer> ageDataInt = ageData.map(new Function<String, Integer>() {
@Override
public Integer call(String s) throws Exception {
return Integer.parseInt(String.valueOf(s));
}
});
//求出年龄的和
Integer totalAge = ageDataInt.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer x, Integer y) throws Exception {
return x+y;
}
});
//平均值结果为double类型
Double avgAge = totalAge.doubleValue()/count;
/*System.out.println(ageData.collect());
System.out.println(count);*/
System.out.println("Total Age:" + totalAge + "; Number of People:" + count );
System.out.println("Average Age is " + avgAge); }
}
运行结果:
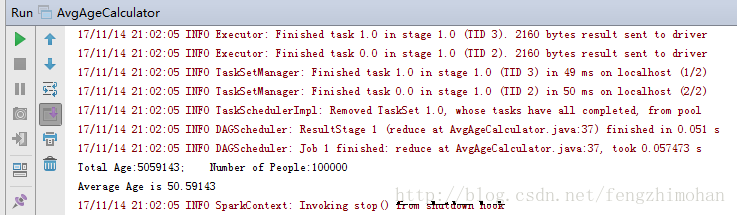
从结果可以看出,计算出所以年龄的总和,以及总人数,以及平均年龄值。看似简单的例子,在对数组取值和数据类型转换时候需要特别的注意。
spark 应用场景1-求年龄平均值的更多相关文章
- MySQL中求年龄
时间函数: 1.curdate() --- 当前系统日期 调取: select curdate() 2.curtime() --- 当前系统时间 调取: select curtime() 3.now( ...
- 使用基础知识完成java小作业?强化练习-1.输入数组计算最大值-2.输出数组反向打印-3.求数组平均值与总和-4.键盘输两int,并求总和-5.键盘输三个int,并求最值;
完成几个小代码练习?让自己更加强大?学习新知识回顾一下基础? 1.输入数组计算最大值 2.输出数组反向打印 3.求数组平均值与总和 4.键盘输两int,并求总和 5.键盘输三个int,并求最值 /* ...
- 利用Python读取json数据并求数据平均值
要做的事情:一共十二个月的json数据(即12个json文件),json数据的一个单元如下所示.读取这些数据,并求取各个(100多个)城市年.季度平均值. { "time_point&quo ...
- SQL 跟据出生日期求年龄
最近做项目时遇到一个问题. 跟据人员的生日与当前日期进行比较求出该人员实际年龄.这个看上去比较简单的问题,其实不细心去看也会有很多问题. 先看第一种: 一张人员信息表里有一人生日(Birthday)列 ...
- 【spark】示例:求极值
我们有这样的数据 1.建立SparkContext读取数据 (1)建立sc (2)通过sc.textFile()读取数据创建Rdd 2.过滤数据 通过filter(line => line.tr ...
- 【spark】示例:求Top值
我们有这样的两个文件 第一个数字为行号,后边为三列数据.我们来求第二列数据的Top(N) (1)我们先读取数据,创建Rdd (2)过滤数据,取第二列数据. 我们用filter()来过滤数据 line. ...
- java代码,输入n多个数,求其平均值,虽有重复,但是第二次,我就乱写了
总结:对象调用方法,与在main 里直接输出没什么大的区别,少用方法, 乱搞++++ package com.c2; import java.util.Scanner; public class DD ...
- Spark应用场景以及与hadoop的比较
一.大数据的四大特征: a.海量的数据规模(volume) b.快速的数据流转和动态的数据体系(velocity) c.多样的数据类型(variety) d.巨大的数据价值(value) 二.Spar ...
- [spark程序]统计人口平均年龄(HDFS文件)(详细过程)
一.题目描述 (1)请编写Spark应用程序,该程序可以在分布式文件系统HDFS中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包 ...
随机推荐
- bzoj1045题解
[解题思路] (数据范围劝退?正确范围应该是n≤1000000) 设xi表示第i个小朋友给第i+1个小朋友的糖果数(特殊的,xn表示第n个小朋友给第1个小朋友的糖果数),Â表示平均糖果数,有如下方程组 ...
- 字符串hash+找模数——cf985F
19260817比自然溢出都要好使 /* 把原串变成用26个01串表示,第i个串对应的字符是i 然后进行字符串hash,s和t双射的条件是26个串的hash值排序后一一相等 */ #include&l ...
- NX二次开发-UFUN询问注释对象的数据UF_DRF_ask_ann_data
NX11+VS2013 #include <uf.h> #include <uf_ui.h> #include <uf_drf.h> UF_initialize() ...
- fastText一个库用于词表示的高效学习和句子分类
fastText fastText 是 Facebook 开发的一个用于高效学习单词呈现以及语句分类的开源库. 要求 fastText 使用 C++11 特性,因此需要一个对 C++11 支持良好的编 ...
- git 安装 使用过程遇到的问题
git add "文件名"->git commit -m 'add' ->>git push origin develop 1.git基础之切换分支 选择gi ...
- 前端开发者进阶之ECMAScript新特性--Object.create
前端开发者进阶之ECMAScript新特性[一]--Object.create Object.create(prototype, descriptors) :创建一个具有指定原型且可选择性地包含指 ...
- Mybatis 使用的 9 种设计模式,真是太有用了~
Java技术栈 ) { name = fullname.substring(0, delim); children = fullname.substring(delim + 1); ...
- 注意:字符串substring方法在jkd6,7,8中的差异。
标题中的substring方法指的是字符串的substring(int beginIndex, int endIndex)方法,这个方法在jdk6,7是有差异的. substring有什么用? sub ...
- springboot中参数校验
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring- ...
- 【Wikioi】P1401 逆序统计 代码
题目链接:http://wikioi.com/solution/list/1401/ 题解链接:http://user.qzone.qq.com/619943612/blog/1377265690 代 ...