爬虫实战【12】使用cookie登陆豆瓣电影以及获取单个电影的所有短评
昨天我们已经实现了如何抓取豆瓣上的热门电影信息,虽然不多,只有几百,但是足够我们进行分析了。
今天我们来讲一下如何获取某一部电影的所有短评论信息,并保存到mongodb中。
反爬虫
豆瓣设置的反爬虫机制是比较简单的,我们可以通过selenium模拟浏览器登陆这种终极办法来绕过,但是更加有效率的方法是设置请求头信息的cookie,是豆瓣认为在访问的就是一个用户,而不是机器。
【插入图片,我的cookie】
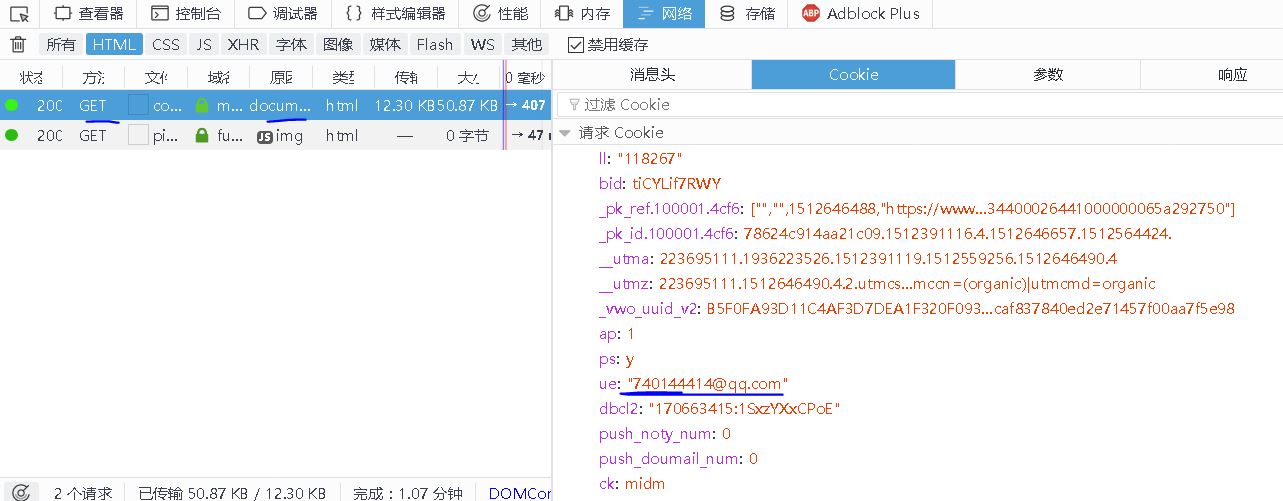
我们首先要登陆自己的豆瓣账户,随便点击一个评论页面,在请求信息里面,找到cookie,保存下来。
分析评论页
我们先看一下评论页面的url特点,或者说请求网址的构成。
https://movie.douban.com/subject/26378579/comments?start=20&limit=20&sort=new_score&status=P&percent_type=
一看上面的url,我们就能分析出来这又是一个参数传递的url,前面的地址是这部电影的url,我们通过昨天的学习,应该能够得到并且已经保存在数据库中了。
【插入图片,评论url参数】
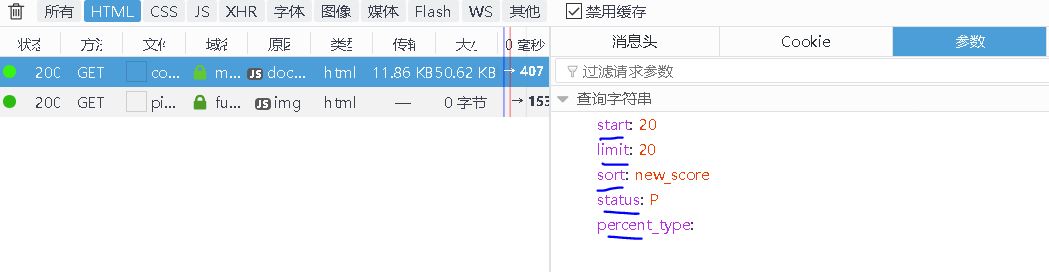
改变start的值,就可以得到很多个页面了。
值得注意的是,评论并不是通过ajax加载的,而是在html的响应中存在的,我们解析url的响应内容,就可以获取评论。我还是喜欢用最方便的PyQuery来解析源代码。
然后我们分析一下评论的源代码构成:
【插入图片,所有评论的源码】
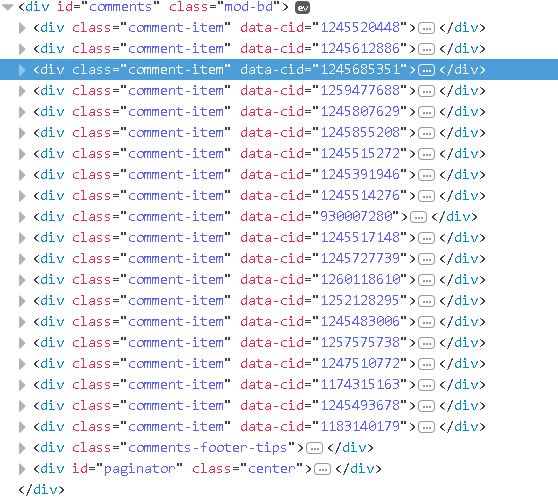
所有的评论内容都在一个class属性为comment-item的div标签里面,每页有大概20个。进一步来分析:
【插入图片,评论所在的div】
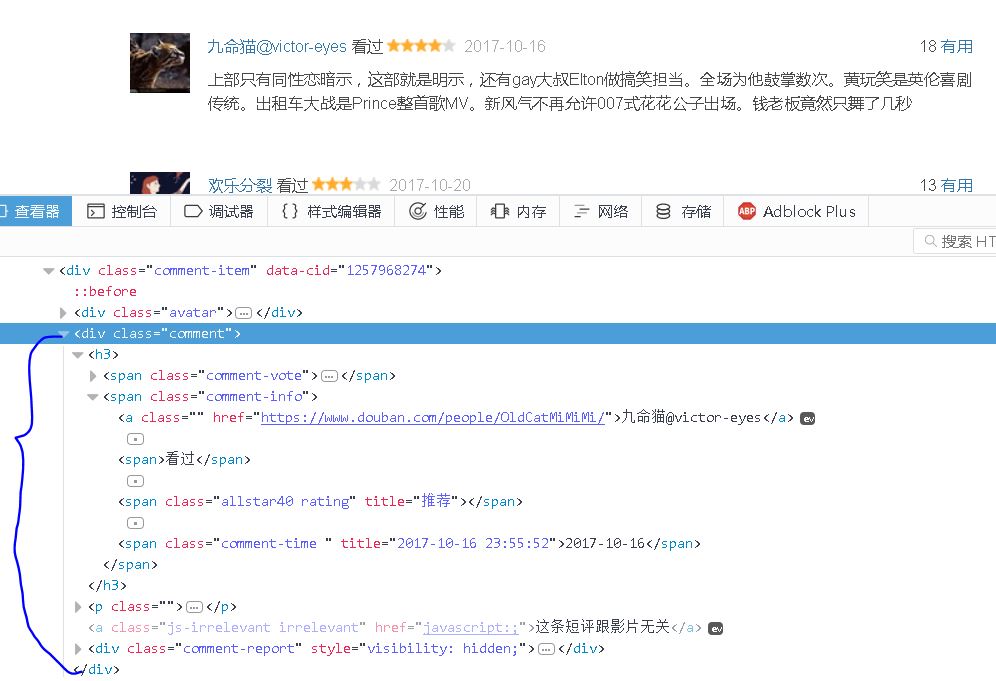
其实所有的评论内容,都能从一个class属性为comment的div标签里面获取,这个div是comment-item的子标签,我们直接获取这个标签就可以。
通过pyquery可以直接得到这些div,我们将其转换成list方便操作,还有一个就是用来判断何时停止迭代页面。
【插入图片,没有评论了】

如上所示,我们需要判断一下,start什么时候就要停止迭代,因为评论不可能是无穷多的。
我们发现在没有评论的页面,是没有comment的div存在的,也就是上面提到的list的长度应该是0.
这里有一个坑,最后我再讲给大家。
解析评论的组成
【插入图片,评论的组成部分】

我们看上面的图片,大致关心的内容包括评论用户、评论时间、评论内容以及对这条评论的投票数量。
一一来讲。
【插入图片,评论用户名】
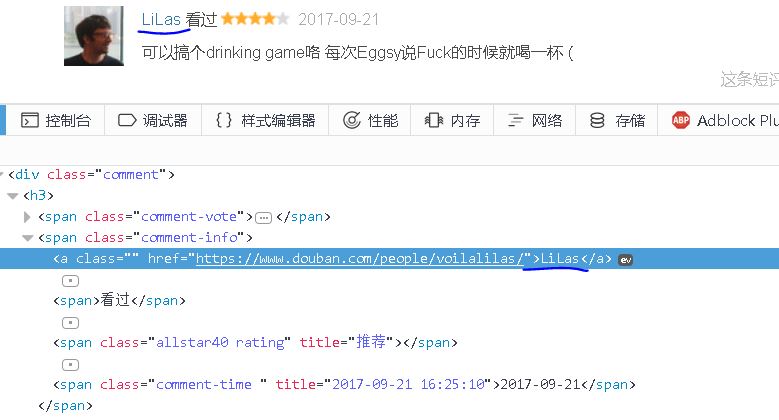
用户名在一个class属性为comment-info的span标签内容的a标签的text。
【插入图片,评论内容】

评论内容在我们div下面唯一的p标签里面。
【插入图片,评论vote】
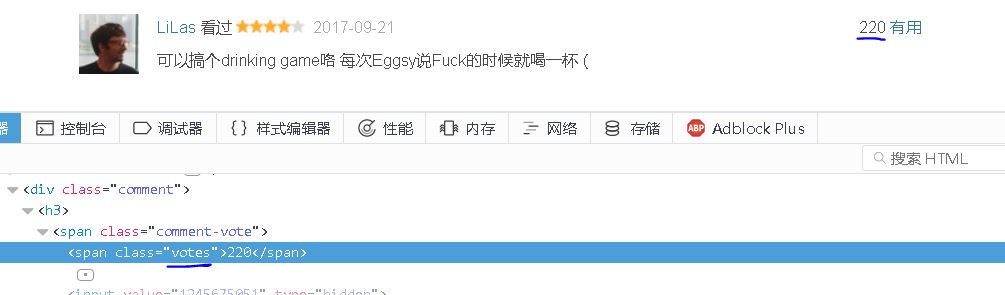
vote内容在一个class为votes的span里面。
评论时间在一个class为comment-time的span里面。
全部源码
我在每一条短评中假如了电影的名字,这样可以将多个电影的评论都放入一个mongodb表中。
我们设置了一个布尔值flag,用于判断什么时候结束翻页,并且在每次解析页面的时候返回一个bool值。当返回False的时候,就停止迭代了。
import requests
from urllib.parse import urlencode
import re
from pyquery import PyQuery
import pymongo
'''MONGO设置'''
MONGO_URL = 'localhost'
MONGO_DB = 'douban'
MONGO_Table = '热门电影评论'
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
def get_one_page(start_no):
data = {
'start': start_no,
'limit': 20,
'sort': 'new_score',
'status': 'P',
'percent_type': ''
}
url = 'https://movie.douban.com/subject/26378579/comments?' + urlencode(data)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393',
'Cookie': 'ck=midm; __utmc=30149280; bid=4MkCJCpc9l0;'
' __utma=30149280.714093067.1510577422.1512480946.1512561835.4;'
' __utmz=30149280.1510577422.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; '
'll=108296; ps=y; dbcl2=170663415:1SxzYXxCPoE; __utmb=30149280.0.10.1512561835; '
'push_noty_num=0; push_doumail_num=0; __utmc=223695111;'
' _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1512561809%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D;'
' _pk_id.100001.4cf6=f414e971fcd4f788.1511518102.3.1512561978.1512480916.;'
' _pk_ses.100001.4cf6=*;'
' __utma=223695111.1064880032.1511518153.1512480946.1512561835.3;'
' __utmz=223695111.1511518153.1.1.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/;'
' __yadk_uid=sC5FTKHfpeiLyKd7wwi41h2JVxoLBNaF; __utmb=223695111.4.10.1512561835; __utmt=1'
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
# print(response.text)
return response.text
except Exception:
print('访问页面' + url + '出错!')
return None
def parse_one_page(html):
doc = PyQuery(html)
title = doc.find('#content > h1:nth-child(1)').text()
# print(title[:-2])
items = list(doc('div.comment').items())
length = len(items)
# print(length)
if length != 0:
for item in items:
commnet = {
'movie': title,
'comment user': item.find('span.comment-info').find('a').text(),#PyQuery的特点,可以连续使用find
'comment': item.find('p').text(),
'vote': item.find('span.votes').text(),
'comment time': item.find('span.comment-time').text()
}
save_to_db(commnet)
return True
else:
print('已没有短评了!')
return False
#没有使用到
def get_commnets_number():
html = get_one_page(0)
pattern = re.compile('<span>看过(.*?)</span>')
number = re.search(pattern, html).group(1)
number = int(number[1:-1])
page_number = number // 20
print(page_number)
def save_to_db(film):
try:
if db[MONGO_Table].insert(film):
print('保存成功', film)
except Exception:
print('保存出错', film)
pass
def main():
i = 0
flag = True
while flag:
html = get_one_page(i * 20)
flag = parse_one_page(html)
i += 1
if __name__ == '__main__':
main()
【插入图片,评论结果】
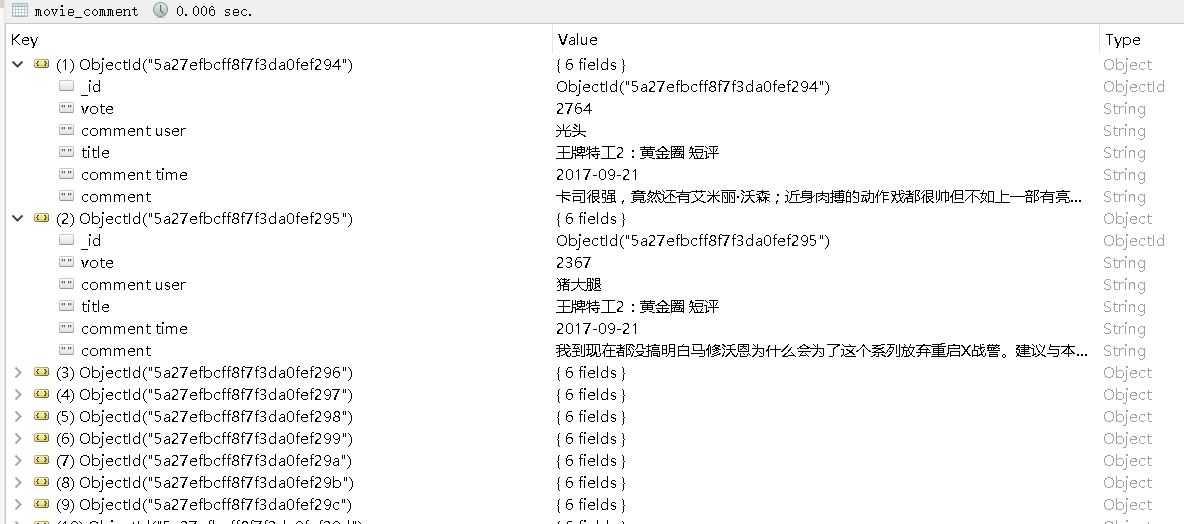
遇到的一个大坑
上面的代码中有一部分内容,让我烦恼了很久。
如果我们这么写,先获取items,然后使用len(list(items))获取这个items的长度,在if判断之后,for循环根本就不会运行。
经过多次长度,改成现在的版本能够实现我要的功能了。
大家可以试一下。

爬虫实战【12】使用cookie登陆豆瓣电影以及获取单个电影的所有短评的更多相关文章
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- (python3爬虫实战-第一篇)利用requests+正则抓取猫眼电影热映口碑榜
今天是个值得纪念了日子,我终于在博客园上发表自己的第一篇博文了.作为一名刚刚开始学习python网络爬虫的爱好者,后期本人会定期发布自己学习过程中的经验与心得,希望各位技术大佬批评指正.以下是我自己做 ...
- 爬虫实战【5】送福利!Python获取妹子图上的内容
[插入图片,妹子图首页] 哈,只敢放到这个地步了. 今天给直男们送点福利,通过今天的代码,可以把你的硬盘装的满满的~ 下面就开始咯! 第一步:如何获取一张图片 假如我们知道某张图片的url,如何获取到 ...
- python爬虫学习(3)_模拟登陆
1.登陆超星慕课,chrome抓包,模拟header,提取表单隐藏元素构成params. 主要是验证码图片地址,在js中发现由js->new Date().getTime()时间戳动态生成url ...
- python爬虫实战 获取豆瓣排名前250的电影信息--基于正则表达式
一.项目目标 爬取豆瓣TOP250电影的评分.评价人数.短评等信息,并在其保存在txt文件中,html解析方式基于正则表达式 二.确定页面内容 爬虫地址:https://movie.douban.co ...
- 爬虫实战【11】Python获取豆瓣热门电影信息
之前我们从猫眼获取过电影信息,而且利用分析ajax技术,获取过今日头条的街拍图片. 今天我们在豆瓣上获取一些热门电影的信息. 页面分析 首先,我们先来看一下豆瓣里面选电影的页面,我们默认选择热门电影, ...
- <爬虫实战>豆瓣电影TOP250(三种解析方法)
1.豆瓣电影排行.py # 目标:爬取豆瓣电影排行榜TOP250的电影信息 # 信息包括:电影名字,上映时间,主演,评分,导演,一句话评价 # 解析用学过的几种方法都实验一下①正则表达式.②Beaut ...
- 小白学 Python 爬虫(24):2019 豆瓣电影排行
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- Caused by: java.lang.NoSuchMethodError: javax.persistence.JoinColumn.foreignKey()Ljavax/persistence/
Caused by: Java.lang.NoSuchMethodError: javax.persistence.JoinColumn.foreignKey()Ljavax/persistence/ ...
- mqtt选择
1.名称 MQTT kafka 2.历史 IBM推出的一种针对移动终端设备的发布/预订协议. LinkedIn公司开发的分布式发布-订阅消息系统.后来,成为Apache项目的一部分. 3.原理 基于二 ...
- C++的多态例子
1.多态的例子 题目: 某小型公司,主要有四类员工(Employee):经理(Manager).技术人员(Technician).销售经理(SalesManager)和推销员(SalesMan).现在 ...
- 5V转3.3v电路
方案一: MIC5205-3.3 输出电流150ma 输出电压3.3V 其中:CT24为钽电容: 方案二: AMS1117-3.3 输出电流800ma 输出电压:3.3V 输入电压:4.75~12v
- ajax 上传图片
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- emacs 中使用git diff命令行
在shell中执行git diff命令,常常会看到例如以下警告信息: terminal is not fully functional 事实上非常easy,配置一下就可以. git config -- ...
- [na][win]系统优化工具dism++
系统优化工具, 确实能将c盘扩大个2-3g. 主要是删除日志 优化系统等功能. https://www.chuyu.me/
- vncviewer鼠标不同步问题
sh-4.1# virsh edit win7 把下面的参数: <input type='mouse' bus='ps2'/> 改成: <input type='tablet' bu ...
- JS高程3:事件
事件是JS和HTML交互的方式. 事件流 事件流是HTML文档接收事件的顺序.分为2个流派:事件冒泡流和事件捕捉流. 事件冒泡流 由内到外 事件捕捉流 由外到内 DOM事件流 事件处理程序 跨浏览器时 ...
- CSS学习笔记(3)--表格边框
http://www.alixixi.com/web/a/2009082657736.shtml 对于很多初学HTML的人来说,表格<table>是最常用的标签了,但对于表格边框的控制,很 ...