Hadoop之block研究
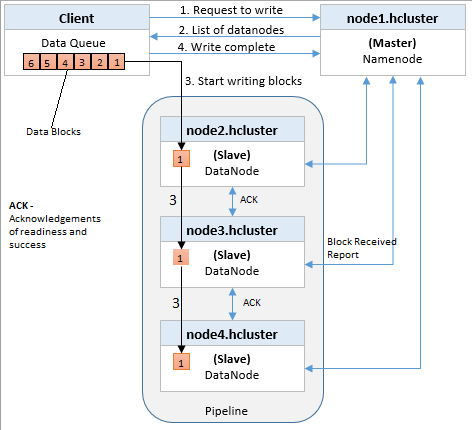
 注释:准备和成功的ACK(确认)
注释:准备和成功的ACK(确认)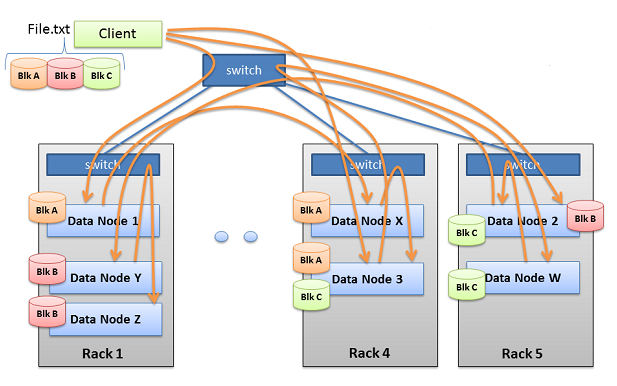

Hadoop之block研究的更多相关文章
- ios之Block研究
Block的好处,我总结了下主要有2点:1.用于回调特别方便,2.可以延长对象的作用区域.但是,Block的内存管理这个模块一直不是很清楚,这个周末好好的看了下Block的原理,有些许心得. 为了性能 ...
- hadoop中block副本的放置策略
下面的这种是针对于塔式服务器的副本的放置策略
- 【转载】Hadoop机架感知
转载自http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html 背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机 ...
- hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- Hadoop分布式配置
本作品由Man_华创作,采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可.基于http://www.cnblogs.com/manhua/上的作品创作. 请先参照Linux安 ...
- Hadoop port to Jxta P2P Framework
https://www.java.net/forum/topic/jxta/jxta-community-forum/hadoop-port-jxta-p2p-framework —————————— ...
- HADOOP实战
一.软件版本Centos6.5.VMware 10CDH5.2.0(Hadoop 2.5.0)Hive-0.13 sqoop-1.4.5 二.学完课程之后,您可以:①.一个人搞定企业Hadoop平台搭 ...
- 基于Docker一键部署大规模Hadoop集群及设计思路
一.背景: 随着互联网的发展.互联网用户的增加,互联网中的数据也急剧膨胀.每天产生的数据量数以万计,本地文件系统和单机CPU已无法满足存储和计算要求.Hadoop分布式文件系统(HDFS)是海量数据存 ...
- 第十三章 hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
随机推荐
- C# 设计模式之 单例模式
单例模式三种写法: 第一种最简单,但没有考虑线程安全,在多线程时可能会出问题,不过俺从没看过出错的现象,表鄙视我…… public class Singleton{ private static ...
- .net第三方数据库物理卡号同步功能实现
本地数据库用的是Oracle,第三方数据库是SQL Server,连接字符串保存在web.config里面. 第三方数据库为增量,每次读取要记录读取的最大位置.我是保存在本地txt文件里面. //保存 ...
- 【Hbase三】Java,python操作Hbase
Java,python操作Hbase 操作Hbase python操作Hbase 安装Thrift之前所需准备 安装Thrift 产生针对Python的Hbase的API 启动Thrift服务 执行p ...
- Python 1.1数字与字符基础
一. 基础数字操作 1.加减乘除以及内置函数: min(), max(), sum(), abs(), len() math库: math.pi math.e, math.si ...
- Vue.js核心概念
# 1. Vue.js是什么? 1). 一位华裔前Google工程师(尤雨溪)开发的前端js库 2). 作用: 动态构建用户界面 3). 特点: * 遵循MVVM模式 * 编码简洁, 体积小, 运行效 ...
- HTML5 tricks for mobile
iOS 7.1的Safari为meta标签新增minimal-ui属性,在网页加载时隐藏地址栏与导航栏 01. Creating a fullscreen experience On Android ...
- BZOJ1303_中位数图_KEY
题目传送门 较水,开两个桶即可. 题目可以理解为,将大于B的数看为1,小于B的数看为-1,将以B这个数为中位数的序列左右分为两半,加起来为0. code: #include <cstdio> ...
- 优步UBER司机全国各地奖励政策汇总 (2月29日-3月6日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 厦门Uber优步司机奖励政策(12月28日到1月3日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- PHP中array_reduce()使用
array_reduce — 用回调函数迭代地将数组简化为单一的值 给定一个数组: $ar = array(1,2,3,4,5); 如果要求得这个数组中各个元素之和. 方法一. 很自然的用foreac ...