第五周 day5 python学习笔记
1.软件开发的常规目录结构
更加详细信息参考博客:http://www.cnblogs.com/alex3714/articles/5765046.html
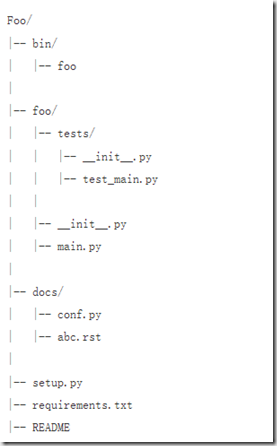
2.python中的模块
(1)定义
模块:用来从逻辑上组织python代码(变量、函数、类、处理逻辑:实现一个功能),本质上就是.py结尾的文件,(文件名test.py,对应的模块名test)
包package:用来从逻辑上组织模块的,本质上就是一个目录(必须带有一个__init__.py文件),导入一个包实质就是解释下面的__init__.py文件
(2)导入方法
import module_name
import module_name,module2_name
from module_test import logger as log#部分导入,还可以加上一个别名
from module_test import n1,n2,n3
from module_test import *
# 不建议这么做,实质上是把所有的代码都粘贴过来
(3)import本质(路径搜索和搜索路径)
导入模块的本质是把Python文件解释一遍
(4)导入优化
from module_test import logger as log#部分导入,还可以加上一个别名
(5)模块分类
import time def logger(name):
now_time=time.strftime("%Y-%m-%d %H:%M:%S")
print(now_time," %s is writing the log......"%name)
return "well done" info="hello world"
# import module_test #实质:将module_test中的代码解释了一遍
#
# #使用被导入的模块中的方法与变量,前面要跟上模块的名称
# module_test.logger("Jean_v")
# print(module_test.info) from module_test import logger as log#实质:将module_test中的logger函数部分的代码粘贴在这
# from module_test import * # 不建议这么做,实质上是把所有的代码都粘贴过来
'''
def logger(name):
now_time=time.strftime("%Y-%m-%d %H:%M:%S")
print(now_time," %s is writing the log......"%name)
return "well done"
'''
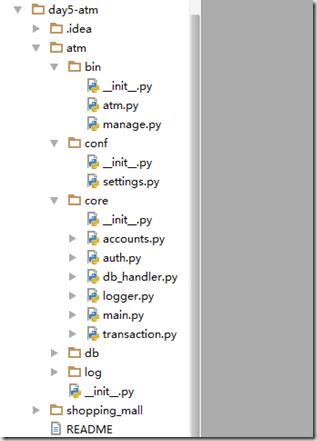
log("Jean_V") import pack # 导入一个包实质就是解释下面的__init__.py文件 #????如何导入pack包下的pack_test文件
from pack import pack_test
pack_test.func() # ??? 如何导入day5-atm/atm/bin中的atm.py文件
import os,sys print(sys.path)#打印当前文件搜索的范围
print(os.path.abspath(__file__))#当前文件的所在的绝对路径
path_x=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
pathlist=['day5-atm','atm','bin']
#路径的拼接
pa=os.path.join(path_x,'day5-atm\\atm\\bin')
print(pa) sys.path.append(pa)
import atm
3.时间time和datetime模块
参考博客:http://egon09.blog.51cto.com/9161406/1840425
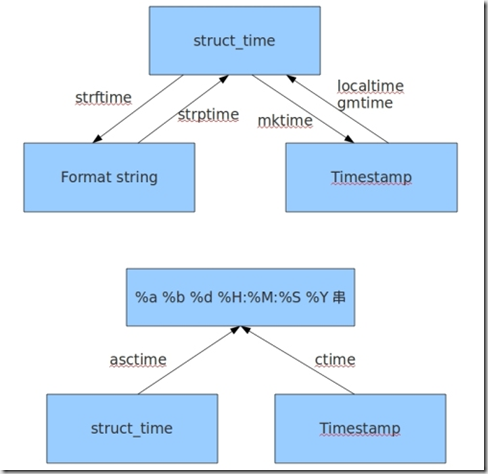
python中表示时间的方式:(1)时间戳,(2)格式化的时间字符串(3)元组struct_time共九个元素
UTC(Coordinated Universal Time世界协调时),也称格林威治天文时间,世界标准时间,在中国为UTC+8
DST(Daylight Saving Time)夏令时
时间戳timestamp:表示从1970年1月1 日00:00:00开始按秒计算,返回float类型,函数有time(),clock()函数
元组(struct_time)方式:struct_time元组共有9个元素,返回struct_time的函数主要有gmtime(),localtime(),strptime()
格式化参照:
%a 本地(locale)简化星期名称
%A 本地完整星期名称
%b 本地简化月份名称
%B 本地完整月份名称
%c 本地相应的日期和时间表示
%d 一个月中的第几天(01 - 31)
%H 一天中的第几个小时(24小时制,00 - 23)
%I 第几个小时(12小时制,01 - 12)
%j 一年中的第几天(001 - 366)
%m 月份(01 - 12)
%M 分钟数(00 - 59)
%p 本地am或者pm的相应符
%S 秒(01 - 61)
%U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。
%w 一个星期中的第几天(0 - 6,0是星期天)
%W 和%U基本相同,不同的是%W以星期一为一个星期的开始。
%x 本地相应日期
%X 本地相应时间
%y 去掉世纪的年份(00 - 99)
%Y 完整的年份
%Z 时区的名字(如果不存在为空字符)
%% ‘%’字符
时间关系的转换:

4.随机数模块 Random
参考博客:http://egon09.blog.51cto.com/9161406/1840425

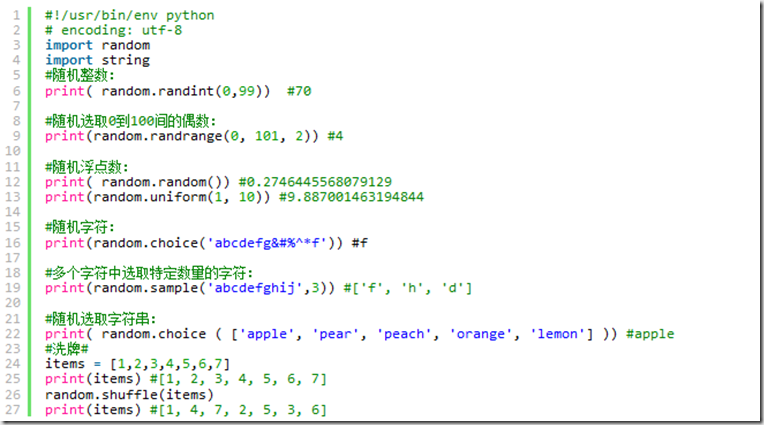
import random
checkcode=''
tmp=''
#生成一个随机的验证码
for i in range(4):
upperCase=chr(random.randint(65,90))
lowerCase=chr(random.randint(97,122))
digit=random.randint(0,9)
tmp=random.choice([upperCase,lowerCase,digit])
checkcode+=str(tmp)
print(checkcode)
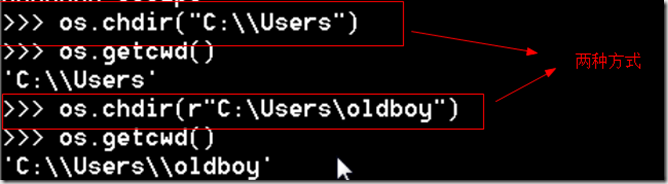
5.python中的os与sys模块
提供对操作系统进行调用的接口
参考博客:http://egon09.blog.51cto.com/9161406/1840425
参考博客:http://www.cnblogs.com/alex3714/articles/5161349.html



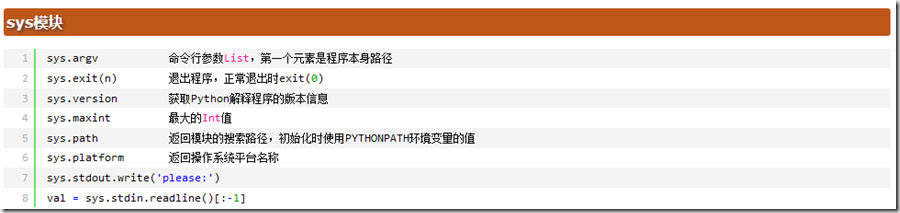
import os
import sys print(sys.argv)
print(os.name)#打印操作系统的名字
print(os.environ)#打印系统的系统的环境变量
6.shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中,可以部分内容
参考博客:http://www.cnblogs.com/wupeiqi/articles/4963027.html
import shutil # 将文件file1复制到file2,file2事先不需要存在,会自动创建
# shutil.copyfile("file1",'file2')
"""Copy data from src to dst.""" # f1=open("file1","r",encoding="utf-8")
# f2=open("file2","w",encoding="utf-8")
# shutil.copyfileobj(f1,f2)
"""copy data from file-like object fsrc to file-like object fdst""" # shutil.copystat("file1","file2")#将f1文件属性复制到f2 # shutil.copytree("dir1","dir11")#将文件目录复制
# shutil.rmtree("dir11")#将dir2文件夹删除
# 创建压缩包并返回文件路径
# 将dir1文件夹中的内容压缩打包到桌面上,取名为dirfile.zip
shutil.make_archive(r"C:\Users\wujian\Desktop\dirfile","zip",r"B:\Python\PycharmCode\pyDay5\day5\dir1")
7.shelve 模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
shelve是一额简单的数据存储方案,它只有一个函数就是open(),这个函数接收一个参数就是文件名,然后返回一个shelf对象,你可以用他来存储东西,就可以简单的把他当作一个字典,当你存储完毕的时候,就调用close函数来关闭
import datetime
import shelve
# python中的一个键值存储的filedb,简单易用,类似于数据库
d=shelve.open('file.db')# 打开一个文件(或者创建一个文件db)
# info={'name':'Jean_V','age':22,'addr':'Shanghai'}
# namelist=['Jean','Anaery','Bod']
# d['info']=info
# d['namelist']=namelist
# d['time']=datetime.datetime.now()
# d.close() # 将filedb中的数据读取出来
print(d.get("info"))
print(d.get('namelist'))
print(d.get('time'))
8.python解析xml
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
import xml.etree.ElementTree as ET# 导入包
tree=ET.parse("xmltest.xml")
root=tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag,child.attrib)
for i in child:
print(i.tag,i.text)
#只遍历year节点
for node in root.iter("year"):
print(node.tag,node.text)
# 修改和删除xml文档内容
for node in root.iter("year"):
new_year=int(node.text)+1
node.text=str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#删除节点
for country in root.findall("country"):
rank=int(country.find("rank").text)
if rank>50:
root.remove(country)
tree.write("xmltest.xml")
9.pyYAML模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
10.ConfigParser模块
用于生成和修改常见配置文档
常见的软件文档格式如下:
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes [bitbucket.org]
User = hg [topsecret.server.com]
Port = 50022
ForwardX11 = no
import configparser
#configparser生成模块
config=configparser.ConfigParser() config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'} config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)
import configparser
# configparser读取模块
conf=configparser.ConfigParser()
conf.read("example.ini") print(conf.defaults())
print(conf.sections())
11.hashlib模块
hashlib用于加密操作,主要提供SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib m=hashlib.md5()
m.update(b"Hello world")
m.update(b"It's me this is for test")
print(m.digest())#以二进制格式输出加密后的结果
print(m.hexdigest())#以十六进制格式输出加密后的结果 n=hashlib.sha256()
n.update("Hello world,this is from Alice to Bob,今天天气不错哦".encode("utf-8"))
print(n.digest())
print(n.hexdigest())
12re模块--正则表达式
常用正则表达式符号
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换

如果需要匹配文本中的“\”,很容易造成反斜杠困扰,建议采用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
----------------------------------------------------------------------------------
作业
第五周 day5 python学习笔记的更多相关文章
- 20145330第五周《Java学习笔记》
20145330第五周<Java学习笔记> 这一周又是紧张的一周. 语法与继承架构 Java中所有错误都会打包为对象可以尝试try.catch代表错误的对象后做一些处理. 使用try.ca ...
- 第三周 day3 python学习笔记
1.字符串str类型,不支持修改. 2.关于集合的学习: (1)将列表转成集合set:集合(set)是无序的,集合中不会出现重复元素--互不相同 (2)集合的操作:交集,并集.差集.对称差集.父集.子 ...
- 第六周 day6 python学习笔记
1.Python面向对象编程OOP(Object Oriented Programming) 封装:可以隐藏实现细节,使代码模块化 继承:可以扩展已存在的代码模块,可以使代码实现重用 多态:一种接口, ...
- 第二周 day2 python学习笔记
1. python中的三元运算: result=value1 if 条件 else value2 如果条件成立,result=value1 如果条件不成立,result=value2 2. pytho ...
- 第一周 day1 Python学习笔记
为什么要学习Python? Python擅长的领域 1. python2.x中不支持中文编码,默认编码格式为ASCII码,而python3.x中支持Unicode编码,支持中文,变量名可以为中文,如: ...
- Python学习笔记,day5
Python学习笔记,day5 一.time & datetime模块 import本质为将要导入的模块,先解释一遍 #_*_coding:utf-8_*_ __author__ = 'Ale ...
- python学习笔记(五岁以下儿童)深深浅浅的副本复印件,文件和文件夹
python学习笔记(五岁以下儿童) 深拷贝-浅拷贝 浅拷贝就是对引用的拷贝(仅仅拷贝父对象) 深拷贝就是对对象的资源拷贝 普通的复制,仅仅是添加了一个指向同一个地址空间的"标签" ...
- Python学习笔记(五)
Python学习笔记(五): 文件操作 另一种文件打开方式-with 作业-三级菜单高大上版 1. 知识点 能调用方法的一定是对象 涉及文件的三个过程:打开-操作-关闭 python3中一个汉字就是一 ...
- OpenCV之Python学习笔记
OpenCV之Python学习笔记 直都在用Python+OpenCV做一些算法的原型.本来想留下发布一些文章的,可是整理一下就有点无奈了,都是写零散不成系统的小片段.现在看 到一本国外的新书< ...
随机推荐
- Delphi设置表格样式
//设置表格样式wordDoc.Tables.Item(1).Borders.Item(Word.WdBorderType.wdBorderLeft).LineStyle = Word.WdLineS ...
- loadView 与 viewDidLoad 和 didReceiveMemoryWarning与viewDidUnload 详解
首先试验下:viewController初始化 分两个支路:initWithNibName加载初始化 及 init 直接初始化: <1>调用initWithNibName加载一个xib界面 ...
- light table 添加行号 更新
在上一个笔记修改完字体后.再添加上行号
- document.referrer的使用和window.opener 跟 window.parent 的区别
偶尔看到了document.referrer,之前一直有点疑惑与window.opener 和 window.parent之间的区别 首先查了一下w3cSCHOOL, 上面的解释:referrer 属 ...
- WPF实现无刷新动态切换多语言(国际化)
1. 在WPF中国际化使用的是 .xaml文件的格式 如图:Resource Dictionary (WPF) 2. 创建默认的语言文件和其他语言文件 这里以英语为默认语言,新建一个 Resource ...
- 学习笔记之--认识Xcode中的重要成员:lldb调试器
之前对lldb调试器了解比较少,平时主要用来打印日志和暂定时用鼠标查看属性数据以及使用p po一些简单的命令语句. 今天看了一些关于lldb的文章,顿时觉得之前对它了解太少了,原来它还有那么多的功能. ...
- org.springframework.web.bind.MissingServletRequestParameterException: Required String parameter 'xxxx' is not present
org.springframework.web.bind.MissingServletRequestParameterException: Required String parameter 'xxx ...
- [javaSE] java上传图片给PHP
java通过http协议上传图片给php文件,对安卓上传图片给php接口的理解 java文件: import java.io.DataOutputStream; import java.io.File ...
- 五、cent OS防火墙常用命令
查看防火墙开闭状态systemctl status firewalld 开启防火墙systemctl start firewalld 关闭防火墙systemctl stop firewalld 查看已 ...
- nginx关于 error_page指令详解.md
error_page指令解释 nginx指令error_page的作用是当发生错误的时候能够显示一个预定义的uri,比如: error_page 502 503 /50x.html; 这样实际上产生了 ...