Python 编码为什么那么蛋疼?
据说,每个做 Python 开发的都被字符编码的问题搞晕过,最常见的错误就是 UnicodeEncodeError、UnicodeDecodeError,你好像知道怎么解决,遗憾的是,错误又出现在其它地方,问题总是重蹈覆辙,str 到 unicode 之间的转换用哪 decode 还是 encode 方法还特不好记,老是混淆,问题究竟出在哪里?
为了弄清楚这个问题,我决定从 python 字符串的构成以及字符编码的细节上进行深入浅出的分析。
字节与字符
计算机存储的一切数据,文本字符、图片、视频、音频、软件都是由一串01的字节序列构成的,一个字节等于8个比特位。
而字符就是一个符号,比如一个汉字、一个英文字母、一个数字、一个标点都可以称为一个字符。
字节方便存储和网络传输,而字符用于显示,方便阅读。字符 “p” 保存到硬盘就是一串二进制数据 01110000,占用一个字节的长度。
编码与解码
我们用编辑器打开的文本,看到的一个个字符,最终保存在磁盘的时候都是以二进制字节序列形式存起来的。那么从字符到字节的转换过程就叫做编码(encode),反过来叫做解码(decode),两者是一个可逆的过程。编码是为了存储传输,解码是为了方便显示阅读。
例如字符 “p” 保存到硬盘是一串二进制 01110000 ,占用一个字节的长度。字符 “禅” 有可能是以 “11100111 10100110 10000101” 占用3个字节的长度存储,为什么说是有可能呢?这个放到后面再说。
Python 编码为什么那么蛋疼?当然,这不能怪开发者。
这是因为 Python2 使用 ASCII 字符编码作为默认编码方式,而 ASCII 不能处理中文,那么为什么不用 UTf-8 呢?因为 Guido 老爹为 Python 编写第一行代码是在1989年的冬天,1991年2月正式开源发布了第一个版本,而 Unicode 是1991年10月发布的,也就是说 Python 这门语言创立的时候 UTF-8 还没诞生,这是其一。
Python 把字符串的类型还搞成两种,unicode 和 str ,以至于把开发者都弄糊涂了,这是其二。python3 就彻底把 字符串重新改造了,只保留一种类型,这是后话,以后再说。
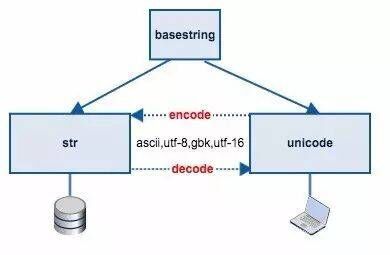
str与unicode
Python2 把字符串分为 unicode 和 str 两种类型。本质上 str 是一串二进制字节序列,下面的示例代码可以看出 str 类型的 “禅” 打印出来是十六进制的 \xec\xf8 ,对应的二进制字节序列就是 ‘11101100 11111000’。
>>> s = '禅'
>>> s
'\xec\xf8'
>>> type(s)
<type 'str'>
而 unicode 类型的 u”禅” 对应的 unicode 符号是 u’\u7985’
>>> u = u"禅"
>>> u
u'\u7985'
>>> type(u)
<type 'unicode'>
我们要把 unicode 符号保存到文件或者传输到网络就需要经过编码处理转换成 str 类型,于是 python 提供了 encode 方法,从 unicode 转换到 str,反之亦然。
encode
>>> u = u"禅"
>>> u
u'\u7985'
>>> u.encode("utf-8")
'\xe7\xa6\x85'decode
>>> s = "禅"
>>> s.decode("utf-8")
u'\u7985'
>>>
不少初学者怎么也记不住 str 与 unicode 之间的转换用 encode 还是 decode,如果你记住了 str 本质上其实是一串二进制数据,而 unicode 是字符(符号),编码(encode)就是把字符(符号)转换为 二进制数据的过程,因此 unicode 到 str 的转换要用 encode 方法,反过来就是用 decode 方法。
encoding always takes a Unicode string and returns a bytes sequence, and decoding always takes a bytes sequence and returns a Unicode string”.
清楚了 str 与 unicode 之间的转换关系之后,我们来看看什么时候会出现 UnicodeEncodeError、UnicodeDecodeError 错误。
UnicodeEncodeError
UnicodeEncodeError 发生在 unicode 字符串转换成 str 字节序列的时候,来看一个例子,把一串 unicode 字符串保存到文件
# -*- coding:utf-8 -*-
def main():
name = u'Python之禅'
f = open("output.txt", "w")
f.write(name)
错误日志
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 6-7: ordinal not in range(128)
为什么会出现 UnicodeEncodeError?
因为调用 write 方法时,Python 会先判断字符串是什么类型,如果是 str,就直接写入文件,不需要编码,因为 str 类型的字符串本身就是一串二进制的字节序列了。
如果字符串是 unicode 类型,那么它会先调用 encode 方法把 unicode 字符串转换成二进制形式的 str 类型,才保存到文件,而 encode 方法会使用 python 默认的 ascii 码来编码
相当于:
>>> u"Python之禅".encode("ascii")但是,我们知道 ASCII 字符集中只包含了128个拉丁字母,不包括中文字符,因此 出现了 ‘ascii’ codec can’t encode characters 的错误。要正确地使用 encode ,就必须指定一个包含了中文字符的字符集,比如:UTF-8、GBK。
>>> u"Python之禅".encode("utf-8")
'Python\xe4\xb9\x8b\xe7\xa6\x85'
>>> u"Python之禅".encode("gbk")
'Python\xd6\xae\xec\xf8'所以要把 unicode 字符串正确地写入文件,就应该预先把字符串进行 UTF-8 或 GBK 编码转换。
def main():
name = u'Python之禅'
name = name.encode('utf-8')
with open("output.txt", "w") as f:
f.write(name)当然,把 unicode 字符串正确地写入文件不止一种方式,但原理是一样的,这里不再介绍,把字符串写入数据库,传输到网络都是同样的原理
UnicodeDecodeError
UnicodeDecodeError 发生在 str 类型的字节序列解码成 unicode 类型的字符串时
>>> a = u"禅"
>>> a
u'\u7985'
>>> b = a.encode("utf-8")
>>> b
'\xe7\xa6\x85'
>>> b.decode("gbk")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'gbk' codec can't decode byte 0x85 in position 2: incomplete multibyte sequence把一个经过 UTF-8 编码后生成的字节序列 ‘\xe7\xa6\x85’ 再用 GBK 解码转换成 unicode 字符串时,出现 UnicodeDecodeError,因为 (对于中文字符)GBK 编码只占用两个字节,而 UTF-8 占用3个字节,用 GBK 转换时,还多出一个字节,因此它没法解析。避免 UnicodeDecodeError 的关键是保持 编码和解码时用的编码类型一致。
这也回答了文章开头说的字符 “禅”,保存到文件中有可能占3个字节,有可能占2个字节,具体处决于 encode 的时候指定的编码格式是什么。
再举一个 UnicodeDecodeError 的例子
>>> x = u"Python"
>>> y = "之禅"
>>> x + y
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
>>>str 与 unicode 字符串 执行 + 操作是,Python 会把 str 类型的字节序列隐式地转换成(解码)成 和 x 一样的 unicode 类型,但Python是使用默认的 ascii 编码来转换的,而 ASCII 中不包含中文,所以报错了。
>>> y.decode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)正确地方式应该是显示地把 y 用 UTF-8 或者 GBK 进行解码。
>>> x = u"Python"
>>> y = "之禅"
>>> y = y.decode("utf-8")
>>> x + y
u'Python\u4e4b\u7985'
Python 编码为什么那么蛋疼?的更多相关文章
- (转载) 浅谈python编码处理
最近业务中需要用 Python 写一些脚本.尽管脚本的交互只是命令行 + 日志输出,但是为了让界面友好些,我还是决定用中文输出日志信息. 很快,我就遇到了异常: UnicodeEncodeError: ...
- Python 编码简单说
先说说什么是编码. 编码(encoding)就是把一个字符映射到计算机底层使用的二进制码.编码方案(encoding scheme)规定了字符串是如何编码的. python编码,其实就是对python ...
- Python之路3【知识点】白话Python编码和文件操作
Python文件头部模板 先说个小知识点:如何在创建文件的时候自动添加文件的头部信息! 通过:file--settings 每次都通过file--setings打开设置页面太麻烦了!可以通过:View ...
- python编码规范
python编码规范 文件及目录规范 文件保存为 utf-8 格式. 程序首行必须为编码声明:# -*- coding:utf-8 -*- 文件名全部小写. 代码风格 空格 设置用空格符替换TAB符. ...
- 【转】python编码的问题
摘要: 为了在源代码中支持非ASCII字符,必须在源文件的第一行或者第二行显示地指定编码格式: # coding=utf-8 或者是: #!/usr/bin/python # -*- coding: ...
- 【转】python编码规范
http://blog.csdn.net/willhuo/article/details/49300441 决定开始Python之路了,利用业余时间,争取更深入学习Python.编程语言不是艺术,而是 ...
- python 编码 UnicodeDecodeError
将一个py脚本从Centos转到win运行,出错如下: UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: il ...
- Python编码/文件读取/多线程
Python编码/文件读取/多线程 个人笔记~~记录才有成长 编码/文件读取/多线程 编码 常用的一般是gbk.utf-8,而在python中字符串一般是用Unicode来操作,这样才能按照单个字 ...
- 关于Python编码,超诡异的,我也是醉了
Python的编码问题,真是让人醉了.最近碰到的问题还真不少.比如中文文件名.csv .python对外呈现不一致啊,感觉好不公平. 没图说个JB,下面立马上图. 我早些时候的其他脚本,csv都是 ...
随机推荐
- Asp.net MVC中repository和service的区别
在Asp.net MVC controller的底层,常常有提到repository和service layer, 好像都是逻辑相关的层,那么它们到底是什么区别呢? 简单的说: repository就 ...
- (转)mysql 5.6 原生Online DDL解析
做MySQL的都知道,数据库操作里面,DDL操作(比如CREATE,DROP,ALTER等)代价是非常高的,特别是在单表上千万的情况下,加个索引或改个列类型,就有可能堵塞整个表的读写. 然后 mysq ...
- React创建组件的三种方式比较
推荐文章: https://www.cnblogs.com/wonyun/p/5930333.html 创建组件的方式主要有: 1.function 方式 2.class App extends Re ...
- VS2013诡异问题,虚方法、泛型,通通躺枪
最近在调代码,发现一个很诡异的问题,简单复原一下 创建4.0控制台项目 以下代码 class Program { static void Main(string[] args) { var item ...
- VS2008默认的字体居然是 新宋体
本人还是觉得 C#就是要这样看着舒服
- C# ASP.NET Core使用HttpClient的同步和异步请求
引用 Newtonsoft.Json // Post请求 public string PostResponse(string url,string postData,out string status ...
- C#实体对象序列化成Json,格式化,并让字段的首字母小写
解决办法有两种:第一种:使用对象的字段属性设置JsonProperty来实现(不推荐,因为需要手动的修改每个字段的属性) public class UserInfo { [JsonProperty(& ...
- 限流(四)nginx接入层限流
一.nginx限流模块 接入层指的是请求流量的入口,我们可以在这里做很多控制,比如:负载均衡,缓存,限流等. nginx中针对限流有两个模块可以处理: 1)ngx_http_limit_req_mod ...
- MD5加密+加盐
了解: MD5加密,是属于不可逆的.我们知道正常使用MD5加密技术,同一字符,加密后的16进制数是不变的,自从出现彩虹表,对于公司内部员工来说,可以反查数据,获取不可能的权限,所以出现了salt算法. ...
- java温故而知新(8)反射机制
一.什么是反射机制 简单的来说,反射机制指的是程序在运行时能够获取自身的信息.在java中,只要给定类的名字, 那么就可以通过反射机制来获得类的所有信息. 二.哪里用到反射机制 有些时候,我们用过 ...