四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1、映射(mapping)介绍
映射:创建索引的时候,可以预先定义字段的类型以及相关属性
elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项,mapping就是我们自己定义的字段数据类型,同时告诉elasticsearch如何索引数据以及是否可以被搜索
作用:会让索引建立的更加细致和完善
类型:静态映射和动态映射
2、内置映射类型(也就是数据类型)
string类型:text,keyword两种
text类型:会进行分词,抽取词干,建立倒排索引
keyword类型:就是一个普通字符串,只能完全匹配才能搜索到
数字类型:long,integer,short,byte,double,float
日期类型:date
bool(布尔)类型:boolean
binary(二进制)类型:binary
复杂类型:object,nested
geo(地区)类型:geo-point,geo-shape
专业类型:ip,competion
3、属性介绍
store属性
index属性
null_value属性
analyzer属性
include_in_all属性
format属性

更多属性:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-boost.html
4、创建索引(相当于创建数据库)、创建表、创建字段-设置字段类型,添加数据
说明:

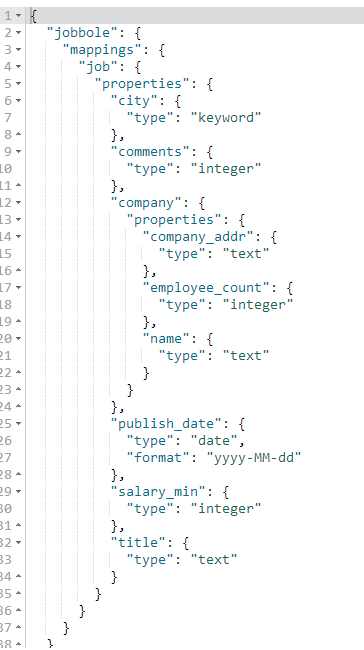
- #创建索引(设置字段类型)
- PUT jobbole #创建索引设置索引名称
- {
- "mappings": { #设置mappings映射字段类型
- "job": { #表名称
- "properties": { #设置字段类型
- "title":{ #title字段
- "type": "text" #text类型,text类型可以分词,建立倒排索引
- },
- "salary_min":{ #salary_min字段
- "type": "integer" #integer数字类型
- },
- "city":{ #city字段
- "type": "keyword" #keyword普通字符串类型
- },
- "company":{ #company字段,是嵌套字段
- "properties":{ #设置嵌套字段类型
- "name":{ #name字段
- "type":"text" #text类型
- },
- "company_addr":{ #company_addr字段
- "type":"text" #text类型
- },
- "employee_count":{ #employee_count字段
- "type":"integer" #integer数字类型
- }
- }
- },
- "publish_date":{ #publish_date字段
- "type": "date", #date时间类型
- "format":"yyyy-MM-dd" #yyyy-MM-dd格式化时间样式
- },
- "comments":{ #comments字段
- "type": "integer" #integer数字类型
- }
- }
- }
- }
- }
- #保存文档(相当于数据库的写入数据)
- PUT jobbole/job/1 #索引名称/表/id
- {
- "title":"python分布式爬虫开发", #字段名称:字段值
- "salary_min":15000, #字段名称:字段值
- "city":"北京", #字段名称:字段值
- "company":{ #嵌套字段
- "name":"百度", #字段名称:字段值
- "company_addr":"北京市软件园", #字段名称:字段值
- "employee_count":50 #字段名称:字段值
- },
- "publish_date":"2017-4-16", #字段名称:字段值
- "comments":15 #字段名称:字段值
- }
代码:
- #创建索引(设置字段类型)
- PUT jobbole
- {
- "mappings": {
- "job": {
- "properties": {
- "title":{
- "type": "text"
- },
- "salary_min":{
- "type": "integer"
- },
- "city":{
- "type": "keyword"
- },
- "company":{
- "properties":{
- "name":{
- "type":"text"
- },
- "company_addr":{
- "type":"text"
- },
- "employee_count":{
- "type":"integer"
- }
- }
- },
- "publish_date":{
- "type": "date",
- "format":"yyyy-MM-dd"
- },
- "comments":{
- "type": "integer"
- }
- }
- }
- }
- }
- #保存文档(相当于数据库的写入数据)
- PUT jobbole/job/1
- {
- "title":"python分布式爬虫开发",
- "salary_min":15000,
- "city":"北京",
- "company":{
- "name":"百度",
- "company_addr":"北京市软件园",
- "employee_count":50
- },
- "publish_date":"2017-4-16",
- "comments":15
- }
5、获取索引下的mappings映射字段类型
- #获取一个索引下的所有表的mappings映射字段类型
- GET jobbole/_mapping
- #获取一个索引下的指定表的mappings映射字段类型
- GET jobbole/_mapping/job
【重点】在创建索引时一旦给字段设置了类型后就不可修改了,如果必须要修改就的重新创建索引,所以在创建索引时就必须确定好字段类型
四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理的更多相关文章
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引 倒排索引 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包 ...
随机推荐
- java 子类不能继承父类的static方法
先来看一段代码 /** * Created by bjchengpeng on 2018/7/19. */ /**运行结果 * woof * woofaa * * woof * Basenjiaa * ...
- 转!!DNS域名解析使用的是TCP协议还是UDP协议?
原文地址:https://segmentfault.com/a/1190000006100959 DNS同时占用UDP和TCP端口53是公认的,这种单个应用协议同时使用两种传输协议的情况在TCP/IP ...
- mysql 客户端命令行下 直接查询并导出数据
mysql原来还能这么导出数据,涨知识了. 方式1: select ....(sql语句) INTO OUTFILE '/var/lib/mysql/msg_data.csv ' (导出的文件位置 ...
- GSM/GPRS/3G/4G
1.状态机机制的gprs拨号 像GPRS/3G模块之类的应用,需要连接,登陆,初始化等步骤完成后才能传输数据,而这些步骤又比较耗时. 所以用 状态机 + 超时 的机制来实现比较合理. 如下代码片段来描 ...
- Hadoop家族学习路线图-张丹老师
前言 使用Hadoop已经有一段时间了,从开始的迷茫,到各种的尝试,到现在组合应用….慢慢地涉及到数据处理的事情,已经离不开hadoop了.Hadoop在大数据领域的成功,更引发了它本身的加速发展.现 ...
- mysql增量恢复的一个实例操作
通过防火墙禁止web等应用向主库写数据或者锁表,让主库暂时停止更新,然后进行恢复 模拟整个场景 1.登录数据库 [root@promote 3306]# mysql -uroot -S /data/3 ...
- JAVA垃圾回收笔记
一.分析GC日志 /** * @author : Hejinsheng * @date : 2019/1/18 0018 * @Description: 模拟FULL GC/YOUNG GC * -X ...
- PL/SQL编程—视图
create or replace view test_view as select TestA.id, TestB.idno, TestB.name, TestB.sex from TestB le ...
- OpenOCD SWD调试stm32f0
参考:http://www.stmcu.org.cn/module/forum/thread-610998-1-2.html
- POJ - 2226 Muddy Fields (最小顶点覆盖)
*.*. .*** ***. ..*. 题意:有一个N*M的像素图,现在问最少能用几块1*k的木条覆盖所有的 * 点,k为>=1的任意值. 分析:和小行星那题很像.小行星那题是将一整行(列)看作 ...