使用py-faster-rcnn训练VOC2007数据集时遇到问题
使用py-faster-rcnn训练VOC2007数据集时遇到如下问题:
1. KeyError: 'chair'
File "/home/sai/py-faster-rcnn/tools/../lib/datasets/pascal_voc.py", line 217, in _load_pascal_annotation
cls = self._class_to_ind[obj.find('name').text.lower().strip()]
KeyError: 'chair'
解决:
You probably need to write some line of codes to ignore any objects with classes except the classes you are looking for when you are loading the annotation _load_pascal_annotation.
Something like
cls_objs = [
obj for obj, clas in objs, self._classes if obj.find('name').text== clas]
when you are loading the annotation in _load_pascal_annotation method, look for something likeobjs = diff_objs (or non_diff_objs)
After that line insert something similar to below code
cls_objs = [obj for obj in objs if obj.find('name').text in self._classes]I'd just like to point out that CUDA runtime error (30) might show if your program is unable to create or open the
objs = cls_objs https://github.com/rbgirshick/py-faster-rcnn/issues/316 2. Check failed: error == cudaSuccess (30 vs. 0) unknown error 1./dev/nvidia-uvmdevice file. This is usually fixed by installing packagenvidia-modprobe:
sudo apt-get install nvidia-modprobe
Note also that since your GPU has compute capability 2.1 as per this page you will not be able to use CuDNN and will need to disable support for CuDNN in the Caffe makefile.
2. The problem happened because modprobe could not insert nvidia_340_uvm.
Thus, I had to install nvidia_340_uvm via: sudo apt-get install nvidia-340-uvm.
对于第二点,由于我不是340的显卡驱动,我运行后系统崩了。据说将其改为自己的驱动版本即可,我是378版本的驱动,将340换成378后显示无法定位软件包。
3. 我发现自己没有装cuda samples,参考别人的教程进行安装。(系统和应用版本不一致,需注意)
编译CUDA Samples
命令:
- cd /usr/local/cuda-6.5/samples
- sudo make
编译完成后,进入路径:/samples/bin/x86_64/linux/release
运行命令:
- ./deviceQuery
输出:
- ./deviceQuery Starting...
- CUDA Device Query (Runtime API) version (CUDART static linking)
- Detected 1 CUDA Capable device(s)
- Device 0: "Tesla K40c"
- CUDA Driver Version / Runtime Version 6.5 / 6.5
- CUDA Capability Major/Minor version number: 3.5
- Total amount of global memory: 11520 MBytes (12079136768 bytes)
- (15) Multiprocessors, (192) CUDA Cores/MP: 2880 CUDA Cores
- GPU Clock rate: 745 MHz (0.75 GHz)
- Memory Clock rate: 3004 Mhz
- Memory Bus Width: 384-bit
- L2 Cache Size: 1572864 bytes
- Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
- Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
- Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
- Total amount of constant memory: 65536 bytes
- Total amount of shared memory per block: 49152 bytes
- Total number of registers available per block: 65536
- Warp size: 32
- Maximum number of threads per multiprocessor: 2048
- Maximum number of threads per block: 1024
- Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
- Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
- Maximum memory pitch: 2147483647 bytes
- Texture alignment: 512 bytes
- Concurrent copy and kernel execution: Yes with 2 copy engine(s)
- Run time limit on kernels: No
- Integrated GPU sharing Host Memory: No
- Support host page-locked memory mapping: Yes
- Alignment requirement for Surfaces: Yes
- Device has ECC support: Enabled
- Device supports Unified Addressing (UVA): Yes
- Device PCI Bus ID / PCI location ID: 1 / 0
- Compute Mode:
- < Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
- deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 6.5, CUDA Runtime Version = 6.5, NumDevs = 1, Device0 = Tesla K40c
- Result = PASS
(2.2.4.9)验证NVIDIA 驱动和CUDA是否安装成功
查看安装NVIDIA驱动版本 命令:
cat /proc/driver/nvidia/version
输出
- NVRM version: NVIDIA UNIX x86_64 Kernel Module 340.96 Sun Nov 8 22:33:28 PST 2015
- GCC version: gcc version 4.7.3 (Ubuntu/Linaro 4.7.3-12ubuntu1)
3. 发现一个遇到了一样问题的人,注册nvidia帐号后向其请教。
https://devtalk.nvidia.com/default/topic/987119/problem-with-run-cuda-on-geforce-gt-755m/#reply
https://github.com/NVIDIA/DIGITS/issues/1663
Hello,
I have a problem with using GeForce GTX 1080Ti for machine learning (CAFFA framework)
My platform:
ubuntu 16.04, Cuda V8.0.61, CuDNN8.0
I suggest my version is too new and I have to downgrade.
Could you advise the best way for solve my problem?
Find in following more details:
nvcc is warning about deprecation. But it not error and as I know it is about future.
nvcc warning : The 'compute_20', 'sm_20', and 'sm_21' architectures are deprecated, and may be removed in a future release
CAFFE & py-faster-rcnn install with no error, but on training with py-faster-rcnn I recieve next massage:
I0601 15:30:44.833746 28338 layer_factory.hpp:77] Creating layer input-data
I0601 15:30:44.834151 28338 net.cpp:106] Creating Layer input-data
I0601 15:30:44.834161 28338 net.cpp:411] input-data -> data
I0601 15:30:44.834169 28338 net.cpp:411] input-data -> im_info
I0601 15:30:44.834178 28338 net.cpp:411] input-data -> gt_boxes
F0601 15:30:44.852488 28338 syncedmem.hpp:18] Check failed: error == cudaSuccess (30 vs. 0) unknown error
*** Check failure stack trace: ***
More outputs:
~/caffe#nvcc -V gives
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2016 NVIDIA Corporation
Built on Tue_Jan_10_13:22:03_CST_2017
Cuda compilation tools, release 8.0, V8.0.61
~/caffe# nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 378.13 Driver Version: 378.13 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Graphics Device Off | 0000:01:00.0 On | N/A |
| 23% 39C P8 17W / 250W | 578MiB / 11171MiB | 15% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1155 G /usr/lib/xorg/Xorg 20MiB |
| 0 1341 G /usr/lib/xorg/Xorg 262MiB |
| 0 1794 G compiz 82MiB |
| 0 1939 G fcitx-qimpanel 9MiB |
| 0 2015 G ...el-token=3645A468136299F390B7B0886FE96671 173MiB |
+-----------------------------------------------------------------------------+4. 仍然是2的错误,看见有人说 sudo ./experiments/scripts/faster_rcnn_alt_opt.sh 0 VGG16 pascal_voc
可以解决该问题,但是试了之后出现如下问题:
ImportError: libcudart.so.8.0: cannot open shared object file: No such file or directory
全部显示结果如下:
+ set -e
+ export PYTHONUNBUFFERED=True
+ PYTHONUNBUFFERED=True
+ GPU_ID=0
+ NET=VGG16
+ NET_lc=vgg16
+ DATASET=pascal_voc
+ array=($@)
+ len=3
+ EXTRA_ARGS=
+ EXTRA_ARGS_SLUG=
+ case $DATASET in
+ TRAIN_IMDB=voc_2007_trainval
+ TEST_IMDB=voc_2007_test
+ PT_DIR=pascal_voc
+ ITERS=40000
++ date +%Y-%m-%d_%H-%M-%S
+ LOG=experiments/logs/faster_rcnn_alt_opt_VGG16_.txt.2017-06-01_14-56-06
+ exec
++ tee -a experiments/logs/faster_rcnn_alt_opt_VGG16_.txt.2017-06-01_14-56-06
+ echo Logging output to experiments/logs/faster_rcnn_alt_opt_VGG16_.txt.2017-06-01_14-56-06
Logging output to experiments/logs/faster_rcnn_alt_opt_VGG16_.txt.2017-06-01_14-56-06
+ ./tools/train_faster_rcnn_alt_opt.py --gpu 0 --net_name VGG16 --weights data/imagenet_models/VGG16.v2.caffemodel --imdb voc_2007_trainval --cfg experiments/cfgs/faster_rcnn_alt_opt.yml
Traceback (most recent call last):
File "./tools/train_faster_rcnn_alt_opt.py", line 17, in <module>
from fast_rcnn.train import get_training_roidb, train_net
File "/home/jz/py-faster-rcnn/tools/../lib/fast_rcnn/train.py", line 10, in <module>
import caffe
File "/home/jz/py-faster-rcnn/tools/../caffe-fast-rcnn/python/caffe/__init__.py", line 1, in <module>
from .pycaffe import Net, SGDSolver, NesterovSolver, AdaGradSolver, RMSPropSolver, AdaDeltaSolver, AdamSolver
File "/home/jz/py-faster-rcnn/tools/../caffe-fast-rcnn/python/caffe/pycaffe.py", line 13, in <module>
from ._caffe import Net, SGDSolver, NesterovSolver, AdaGradSolver, \
ImportError: libcudart.so.8.0: cannot open shared object file: No such file or directory
5. 仍然是2的错误,有人说是显卡驱动的问题,于是我查询NVIDIA X server setting想看自己使用的是否是NVIDIA的驱动,发现ubuntu16.04没有prime profiles选项,无法一键切换驱动。
有人说要单独安装prime profiles,我sudo apt-get install nvidia-prime之后,在NVIDIA X server里仍然没有该选项。想起在安装驱动之后好像没有禁用ubuntu自带的显卡,于是在软件和更新里查看结果如下图,修改不使用设备后,修改nouveau后重启。
把 nouveau 驱动加入黑名单
$sudo nano /etc/modprobe.d/blacklist-nouveau.conf 在文件 blacklist-nouveau.conf 中加入如下内容:
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
禁用 nouveau 内核模块
$echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf $sudo update-initramfs -u
重启
lsmod | grep nouveau
如果什么都没有代表卸载成功,这时候重新启动你会发现屏幕分辨率明显变化了,如果没有变化,注意可能默认驱动没有被禁止,ubuntu16.04好像和14.04有区别,请查其他禁止驱动的方法
- 禁用成功后仍然出现2的错误。
6. 在5的基础上,我试着跑caffe的mnist例程,未果。
输入:./examples/mnist/train_lenet.sh
输出:
F0601 20:57:37.822069 3866 db_lmdb.hpp:15] Check failed: mdb_status == 0 (13 vs. 0) Permission denied
*** Check failure stack trace: ***
@ 0x7f9308c9a95d google::LogMessage::Fail()
@ 0x7f9308c9c6e0 google::LogMessage::SendToLog()
@ 0x7f9308c9a543 google::LogMessage::Flush()
@ 0x7f9308c9d0ae google::LogMessageFatal::~LogMessageFatal()
@ 0x7f9309415428 caffe::db::LMDB::Open()
@ 0x7f93092b3b9f caffe::DataLayer<>::DataLayer()
@ 0x7f93092b3d32 caffe::Creator_DataLayer<>()
@ 0x7f9309468d90 caffe::Net<>::Init()
@ 0x7f930946b79e caffe::Net<>::Net()
@ 0x7f930944e865 caffe::Solver<>::InitTrainNet()
@ 0x7f930944fc55 caffe::Solver<>::Init()
@ 0x7f930944ff6f caffe::Solver<>::Solver()
@ 0x7f93094402b1 caffe::Creator_SGDSolver<>()
@ 0x40a9e8 train()
@ 0x4072e0 main
@ 0x7f9307c0b830 (unknown)
@ 0x407b09 _start
输入:sudo ./examples/mnist/train_lenet.sh
输出:
error while loading shared libraries: libcudart.so.8.0: cannot open shared object file: No such file or directory
解决:https://cgcvtutorials.wordpress.com/2016/10/14/error-while-loading-shared-libraries-libcudart-so-8-0-cannot-open-shared-object-file-no-such-file-or-directory/
sudo ldconfig /usr/local/cuda-8.0/lib64
再输入sudo ./examples/mnist/train_lenet.sh后成功训练mnist.
参考链接:https://devtalk.nvidia.com/default/topic/963814/cuda-setup-and-installation/cuda-8-libcudart-error/
https://askubuntu.com/questions/889015/cant-install-cuda-8-but-have-correct-nvidia-driver-ubuntu-16
https://github.com/tensorflow/tensorflow/issues/5343
http://blog.crboy.net/2012/05/solution-for-cannot-open-shared-object.html
7. 在6成功的基础上,已经可以开始训练py-faster-rcnn。
sudo ./experiments/scripts/faster_rcnn_alt_opt.sh 0 VGG16 pascal_voc
8. 成功训练完模型之后,测试时又出现如下问题:
输入:python ./tools/demo.py
输出:I0602 20:04:00.106807 10014 net.cpp:413] Input 0 -> data
F0602 20:04:00.110862 10014 syncedmem.hpp:18] Check failed: error == cudaSuccess (30 vs. 0) unknown error
*** Check failure stack trace: ***
已放弃 (核心已转储)
解决:先后使用了如下命令:
1. sudo ldconfig /usr/local/cuda-8.0/lib64(未果)
2. export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64(未果)
3. export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}(在faster-rcnn路径下,所以该句无效,修改根路径后依然未果)
4. export LD_LIBRARY_PATH=${CUDA_HOME}/lib64
export PATH=${CUDA_HOME}/bin:${PATH}(未果)
5. export CUDA_HOME=/usr/local/cuda | export LD_LIBRARY_PATH=${CUDA_HOME}/lib64(未果)
6. sudo ldconfig /usr/local/cuda/lib64
python ./tools/demo.py(未果)
7. sudo python ./tools/demo.py
报错:
Cannot copy param 0 weights from layer 'bbox_pred'; shape mismatch. Source param shape is 8 4096 (32768); target param shape is 84 4096 (344064). To learn this layer's parameters from scratch rather than copying from a saved net, rename the layer.
解决:修改'/home/jz/py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_alt_opt/faster_rcnn_test.pt'文件中的bbox_pred为out_num为8
再次输入7命令:sudo python ./tools/demo.py后成功测试结果。
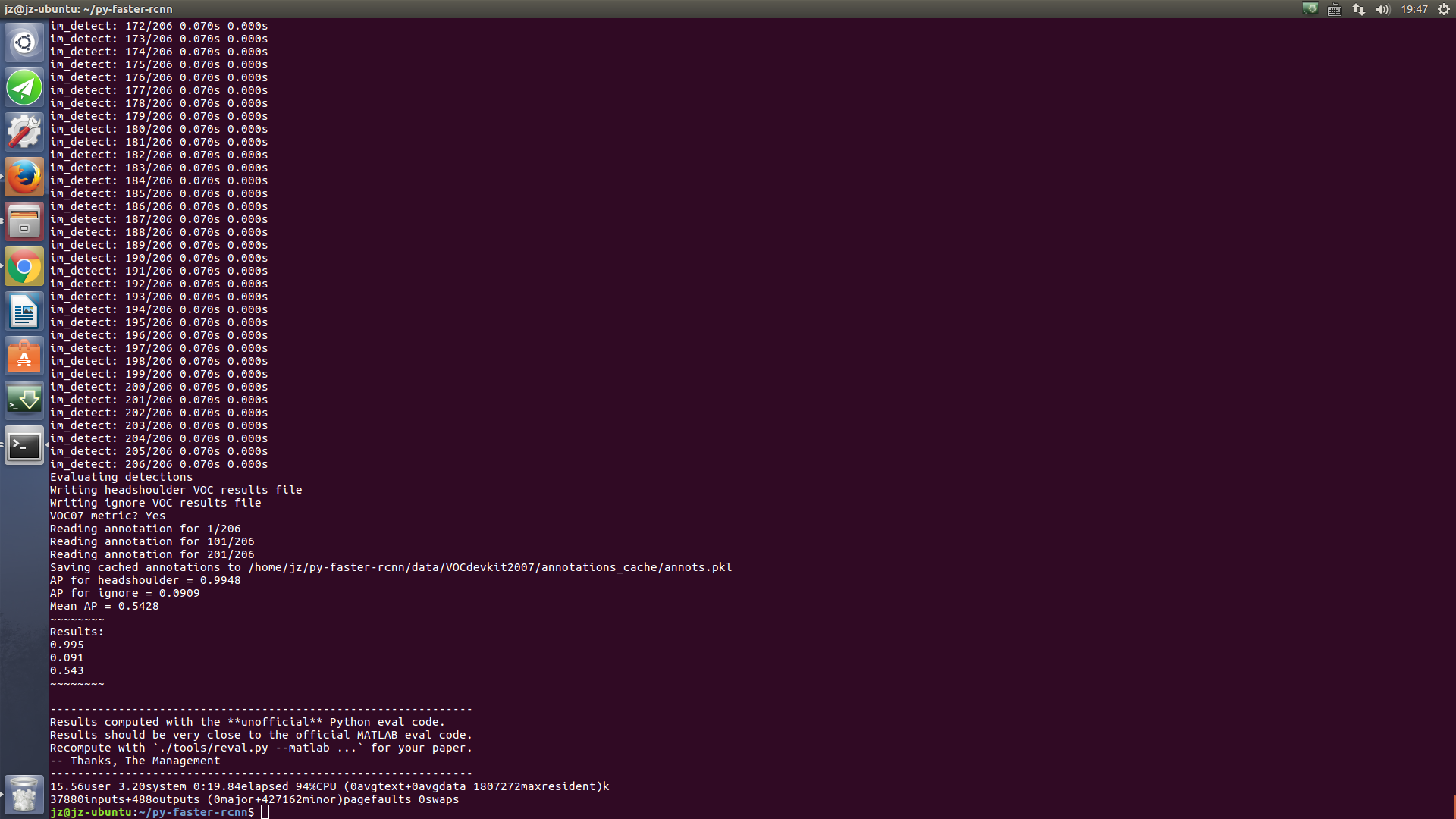
8. 测试
sudo time ./tools/test_net.py --gpu 0 --def models/pascal_voc/VGG16/faster_rcnn_end2end/test.prototxt --net data/faster_rcnn_models/VGG16_end2end_ignore-difficult1.caffemodel
最终: sudo ./experiments/scripts/faster_rcnn_end2end_test.sh 0 VGG16 pascal_voc
参考:sudo ./tools/test_net.py --gpu 0 --def models/pascal_voc/VGG16/faster_rcnn_end2end/test.prototxt --net /home/jz/py-faster-rcnn/output/faster_rcnn_end2end/voc_2012_train/vgg16_faster_rcnn_iter_60000.caffemodel --imdb voc_2012_test --cfg experiments/cfgs/faster_rcnn_end2end.yml
问题:
wrote gt roidb to /home/jz/py-faster-rcnn/data/cache/voc_2007_test_gt_roidb.pkl
Traceback (most recent call last):
File "./tools/test_net.py", line 90, in <module>
test_net(net, imdb, max_per_image=args.max_per_image, vis=args.vis)
File "/home/jz/py-faster-rcnn/tools/../lib/fast_rcnn/test.py", line 242, in test_net
roidb = imdb.roidb
File "/home/jz/py-faster-rcnn/tools/../lib/datasets/imdb.py", line 67, in roidb
self._roidb = self.roidb_handler()
File "/home/jz/py-faster-rcnn/tools/../lib/datasets/pascal_voc.py", line 128, in selective_search_roidb
ss_roidb = self._load_selective_search_roidb(gt_roidb)
File "/home/jz/py-faster-rcnn/tools/../lib/datasets/pascal_voc.py", line 162, in _load_selective_search_roidb
'Selective search data not found at: {}'.format(filename)
AssertionError: Selective search data not found at: /home/jz/py-faster-rcnn/data/selective_search_data/voc_2007_test.mat
Command exited with non-zero status 1
1.39user 2.38system 0:06.47elapsed 58%CPU (0avgtext+0avgdata 1815028maxresident)k
1263144inputs+48outputs (589major+388691minor)pagefaults 0swaps
解决:You can modify the following flag in "lib/fast-rcnn/config.py"
# Propose boxes
__C.TEST.HAS_RPN = True 问题:
- 如果在最后出现
KeyError: 'xxxxxxxxxx',请删除$FRCN_ROOT/data/VOCdevkit2007/annotations_cache/annots.pkl - 如果中途发现标错了数据,重新标注数据后,请删除
$FRCN_ROOT/data/cache/voc_2007_trainval_gt_roidb.pkl - 如果最后测试出现
IndexError: too many indices for array,那是因为你的测试数据中缺少了某些类别。请根据错误提示,找到对应的代码($FRCN_ROOT/lib/datasets/voc_eval.py第148行),前面加上一个if语句:if len(BB) != 0:
BB = BB[sorted_ind, :]
====================================================================================================================================================================
视频检测:
sudo python ./tools/demo_video1.py --net zf
10.结果
在py-faster-rcnn下,
执行:
- ./tools/demo.py --net zf
或者将默认的模型改为zf:
- parser.add_argument('--net', dest='demo_net', help='Network to use [vgg16]',
- choices=NETS.keys(), default='vgg16')
修改:
- default='zf'
执行:
- ./tools/demo.py
使用py-faster-rcnn训练VOC2007数据集时遇到问题的更多相关文章
- caffe学习三:使用Faster RCNN训练自己的数据
本文假设你已经完成了安装,并可以运行demo.py 不会安装且用PASCAL VOC数据集的请看另来两篇博客. caffe学习一:ubuntu16.04下跑Faster R-CNN demo (基于c ...
- 如何才能将Faster R-CNN训练起来?
如何才能将Faster R-CNN训练起来? 首先进入 Faster RCNN 的官网啦,即:https://github.com/rbgirshick/py-faster-rcnn#installa ...
- py faster rcnn+ 1080Ti+cudnn5.0
看了py-faster-rcnn上的issue,原来大家都遇到各种问题. 我要好好琢磨一下,看看到底怎么样才能更好地把GPU卡发挥出来.最近真是和GPU卡较上劲了. 上午解决了g++的问题不是. 然后 ...
- faster rcnn训练自己的数据集
采用Pascal VOC数据集的组织结构,来构建自己的数据集,这种方法是faster rcnn最便捷的训练方式
- Fast RCNN 训练自己数据集 (2修改数据读取接口)
Fast RCNN训练自己的数据集 (2修改读写接口) 转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ http ...
- python3 + Tensorflow + Faster R-CNN训练自己的数据
之前实现过faster rcnn, 但是因为各种原因,有需要实现一次,而且发现许多博客都不全面.现在发现了一个比较全面的博客.自己根据这篇博客实现的也比较顺利.在此记录一下(照搬). 原博客:http ...
- Fast RCNN 训练自己数据集 (1编译配置)
FastRCNN 训练自己数据集 (1编译配置) 转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https:/ ...
- faster rcnn训练详解
http://blog.csdn.net/zy1034092330/article/details/62044941 py-faster-rcnn训练自己的数据:流程很详细并附代码 https://h ...
- Faster Rcnn训练自己的数据集过程大白话记录
声明:每人都有自己的理解,动手实践才能对细节更加理解! 一.算法理解 此处省略一万字.................. 二.训练及源码理解 首先配置: 在./lib/utils文件下....运行 p ...
随机推荐
- Unity编辑器 - 输入控件聚焦问题
Unity编辑器整理 - 输入控件聚焦问题 EditorGUI的输入控件在聚焦后,如果在其他地方改变值,聚焦的框不会更新,而且无法取消聚焦,如下图: 在代码中取消控件的聚焦 取消聚焦的"时机 ...
- ## 在webapp上使用input:file, 指定capture属性调用默认相机,摄像,录音功能
在iOS6下开发webapp,使用inputz之file,很有用 <input type="file" accept="image/*" capture= ...
- Scala学习笔记之Actor多线程与线程通信的简单例子
题目:通过子线程读取每个文件,并统计单词数,将单词数返回给主线程相加得出总单词数 package review import scala.actors.{Actor, Future} import s ...
- Python3获取新浪微博内容乱码问题
用python获取新浪微博最近发布内容的时候调用 public_timeline()函数的返回值是个jsonDict对象,首先需要将该对象通过json.dumps函数转换成字符串,然后对该字符串用GB ...
- 【RL系列】Multi-Armed Bandit笔记补充(一)
在此之前,请先阅读上一篇文章:[RL系列]Multi-Armed Bandit笔记 本篇的主题就如标题所示,只是上一篇文章的补充,主要关注两道来自于Reinforcement Learning: An ...
- LeetCode - 136. Single Number - ( C++ ) - 解题报告 - 位运算思路 xor
1.题目大意 Given an array of integers, every element appears twice except for one. Find that single one. ...
- zookeeper:一.zookeeper集群安装
1.zookeeper简介2.安装zookeeper2.1 安装环境准备2.2 安装zookeeper2.2.1.解压zookeeper压缩包到/opt/zookeeper2.2.2.编辑zookee ...
- centos配置iptables
第一次配置前消除默认的规则 #这个一定要先做,不然清空后可能会悲剧 iptables -P INPUT ACCEPT #清空默认所有规则 iptables -F #清空自定义的所有规则 iptable ...
- “Hello World”团队第一周博客汇总
时间:2017-10-13——2017-10-19 Scrum会议: 会议要求博客:https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/1 ...
- eg_3
3. 编写一个程序,返回一个 double 类型的二维数组,数组中的元素通过解析字符串参数获得,如字符串参数:“1,2;3,4,5;6,7,8”,则对应的数组为: d[0][0]=1.0, d[0][ ...