Django全面讲解(2/2)
前戏
Django是Python语言编写的一个全栈式Web框架(其他的还有Tornado,Flask),可帮助我们快速编写一个具有数据库功能,增删改查、后台管理等功能的网站,若不考虑很高的执行速度,去实现一个xx管理系统,Django的最大优势就是开发效率高。
关键词:一个大而全的框架,集成了ORM、模版引擎、路由、视图、缓存、session等诸多功能。
这里使用的是1.13版本,(目前最新是2.1版本,路由系统和SQL语句有些许差异,目前暂不考虑,后期会看工作情况一并纳入本文)
准备工作
web框架: 别人已经设定好的一个web网站模板,你学习它的规则,然后“填空”或“修改”成你自己需要的样子。一般web框架的架构是这样的:
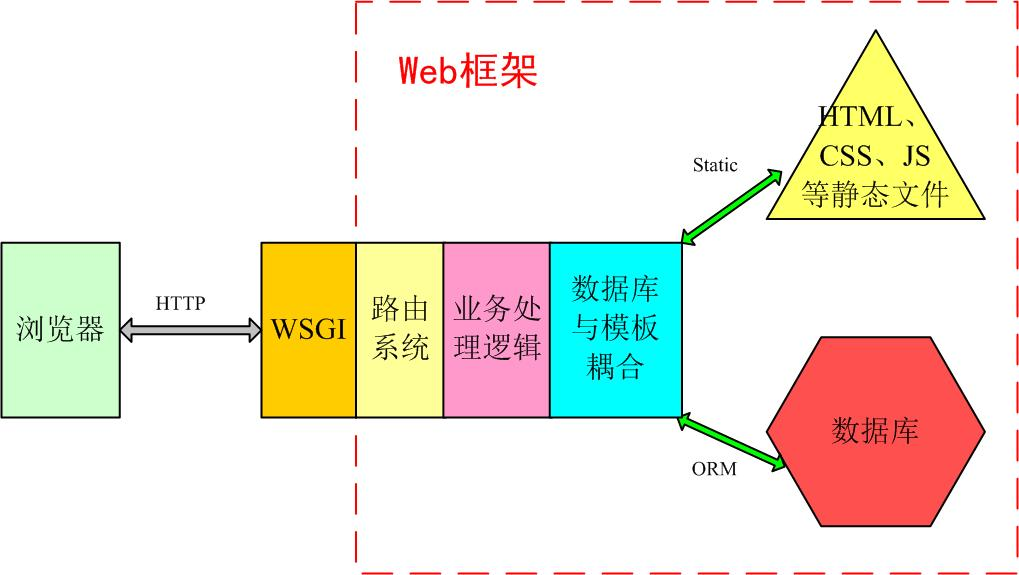
MVC/MTV介绍
MVC百度百科:全名Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。
通俗解释:一种文件的组织和管理形式!不要被缩写吓到了,这其实就是把不同类型的文件放到不同的目录下的一种方法,然后取了个高大上的名字。当然,它带来的好处有很多,比如前后端分离,松耦合等等,就不详细说明了。
模型(model):定义数据库相关的内容,一般放在models.py文件中。
视图(view):定义HTML等静态网页文件相关,也就是那些html、css、js等前端的东西。
控制器(controller):定义业务逻辑相关,就是你的主要代码。
MTV: 有些WEB框架觉得MVC的字面意思很别扭,就给它改了一下。view不再是HTML相关,而是主业务逻辑了,相当于控制器。html被放在Templates中,称作模板,于是MVC就变成了MTV。这其实就是一个文字游戏,和MVC本质上是一样的,换了个名字和叫法而已,换汤不换药。
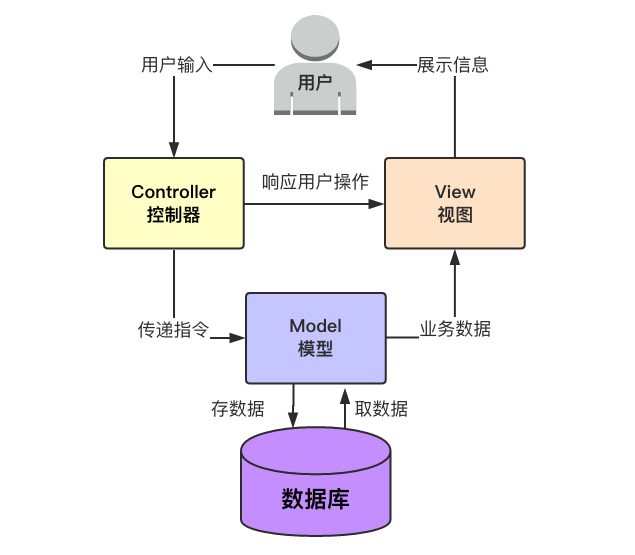
Django的MTV模型组织
Model(模型):负责业务对象与数据库的对象(ORM)
Template(模版):负责如何把页面展示给用户
View(视图):负责业务逻辑,并在适当的时候调用Model和Template
此外,Django还有一个urls分发器,它的作用是将一个个URL的页面请求分发给不同的view处理,view再调用相应的Model和Template
目录分开,就必须有机制将他们在内里进行耦合。在Django中,urls、orm、static、settings等起着重要的作用。一个典型的业务流程是如下图所示:
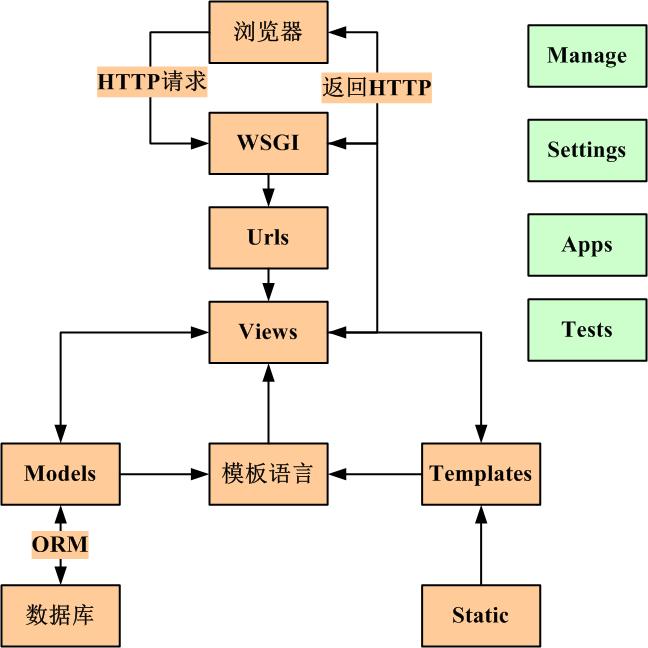
Django框架图示

目录(传送门)
一、 Django流程介绍
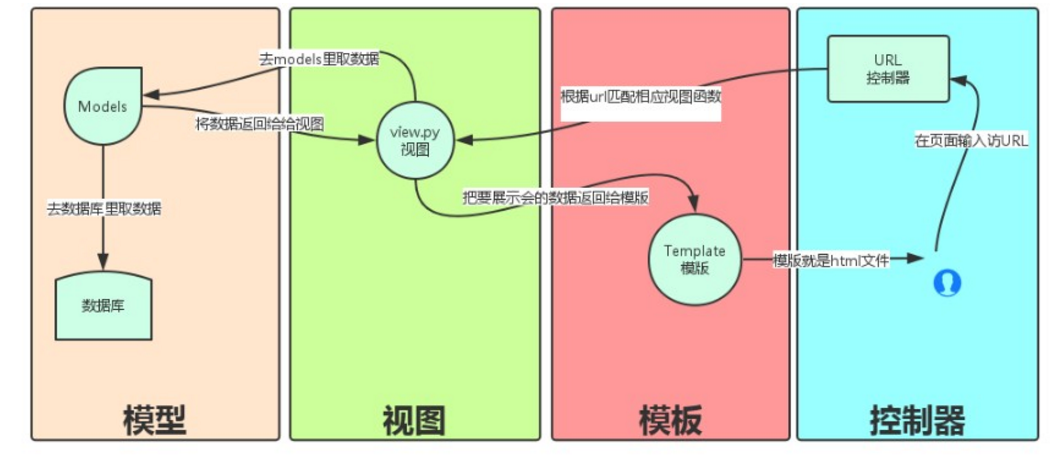
MVC是众所周知的模式,即:将应用程序分解成三个组成部分:model(模型),view(视图),和 controller(控制 器)。其中:
M——管理应用程序的状态(通常存储到数据库中),并约束改变状态的行为(或者叫做“业务规则”)。
C——接受外部用户的操作,根据操作访问模型获取数据,并调用“视图”显示这些数据。控制器是将“模型”和“视图”隔离,并成为二者之间的联系纽带。
V——负责把数据格式化后呈现给用户。
Django也是一个MVC框架。但是在Django中,控制器接受用户输入的部分由框架自行处理,所以 Django 里更关注的是模型(Model)、模板(Template)和视图(Views),称为 MTV模式:
M 代表模型(Model),即数据存取层。 该层处理与数据相关的所有事务: 如何存取、如何验证有效性、包含哪些行为以及数据之间的关系等。
T 代表模板(Template),即表现层。 该层处理与表现相关的决定: 如何在页面或其他类型文档中进行显示。
V 代表视图(View),即业务逻辑层。 该层包含存取模型及调取恰当模板的相关逻辑。 你可以把它看作模型与模板之间的桥梁。
二、 Django 基本配置
1. 创建django程序
- 终端命令:django-admin startproject sitename (在当前目录下创建一个Django程序)
- IDE创建Django程序时,本质上都是自动执行上述命令
其他常用命令:
python manage.py runserver ip:port (启动服务器,默认ip和端口为http://127.0.0.1:8000/)
python manage.py startapp appname (新建 app)
python manage.py syncdb (同步数据库命令,Django 1.7及以上版本需要用以下的命令)
python manage.py makemigrations (显示并记录所有数据的改动)
python manage.py migrate (将改动更新到数据库)
python manage.py createsuperuser (创建超级管理员)
python manage.py dbshell (数据库命令行)
python manage.py (查看命令列表)
2. 程序目录

3. 配置文件
a、数据库
支持SQLite 3(默认)、PostgreSQL 、MySQL、Oracle数据库的操作(具体配置如下)
# 默认是SQLit 3 的配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
# MySQL的配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'dbname', #注意这里的数据库应该以utf-8编码
'USER': 'xxx',
'PASSWORD': 'xxx',
'HOST': '',
'PORT': '',
}
}
# 对于python3的使用者们还需要再加一步操作
# 由于Django内部连接MySQL时使用的是MySQLdb模块,而python3中还无此模块,所以需要使用pymysql来代替
# 如下设置放置的与project同名的配置的 __init__.py文件中
import pymysql
pymysql.install_as_MySQLdb()
# PostgreSQL配置
DATABASES = {
'default': {
'NAME': 'app_data',
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'USER': 'XXX',
'PASSWORD': 'XXX'
}
# Oracle配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.oracle',
'NAME': 'xe',
'USER': 'a_user',
'PASSWORD': 'a_password',
'HOST': '',
'PORT': '',
}
}
具体配置
Django框架对于开发者而言高度透明化,对于不同数据库的具体使用方法是一致的,改变数据库类型只需要变动上述配置即可。
官方文档,请点此传送门
b、静态文件添加
# 首先在项目根目录下创建static目录 # 接着在settings.py 文件下添加 STATIC_URL = '/static/' # 默认已添加,使用静态文件时的前缀
STATICFILES_DIRS = (
os.path.join(BASE_DIR,'static'), #行末的逗号不能漏
) # 这样在template中就可以导入static目录下的静态文件啦 # 例:
<script src="/static/jquery-1.12.4.js"></script>
settings配置
三、 Django 路由系统
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL模式以及要为该URL模式调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调用那段代码。URL的加载是从配置文件中开始。
urlpatterns = [
url(正则表达式,views函数,参数,别名)
] urlpatterns = [
url(r'index',views.index,{"name":""},name="index")
]
参数说明:
- 一个正则表达式字符串
- 一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
- 可选的要传递给视图函数的默认参数(字典形式)
- 一个可选的name参数
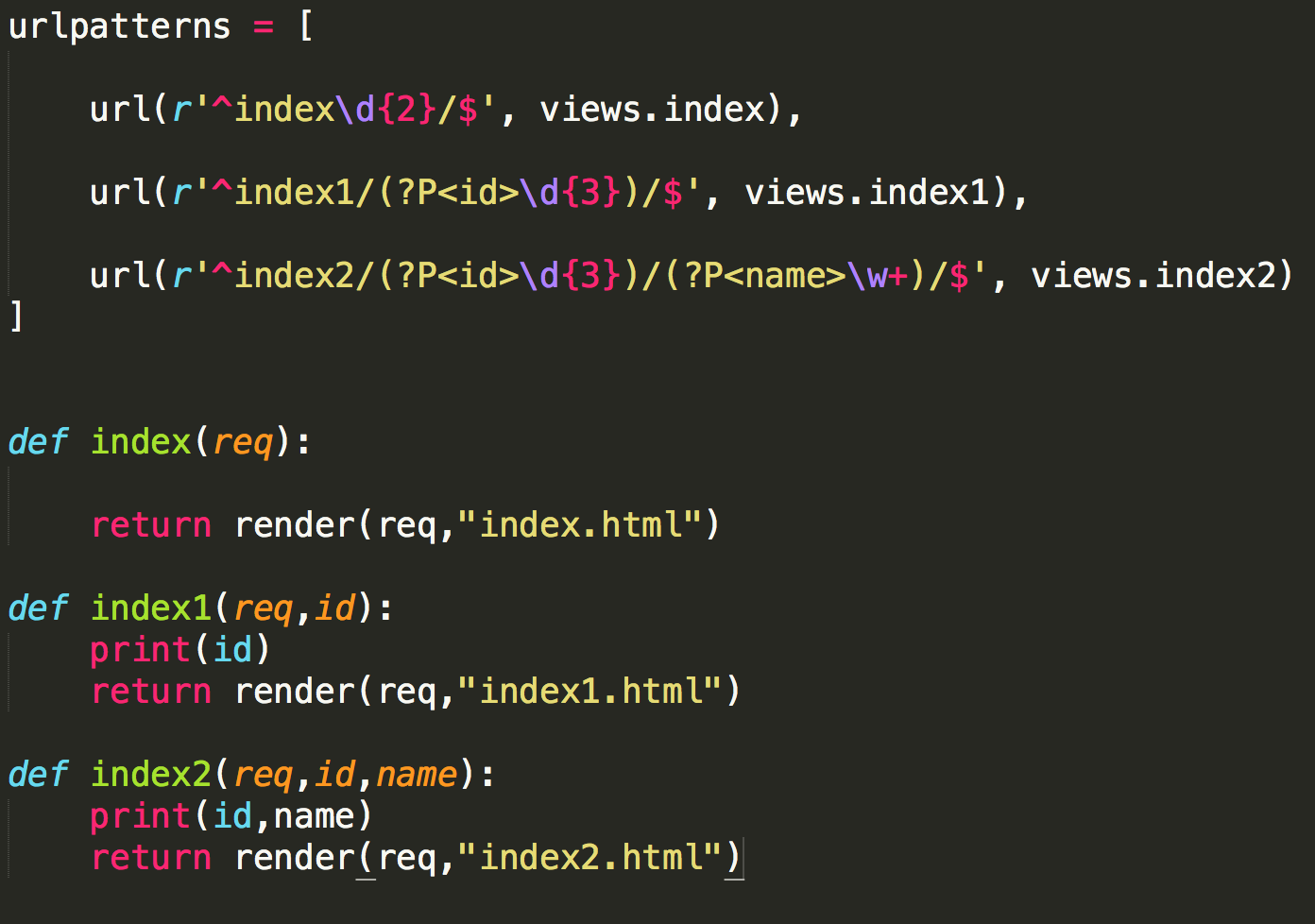
1. 示例
from django.conf.urls import url from . import views urlpatterns = [
url(r'^articles/2003/$', views.special_case_2003),
url(r'^articles/([0-9]{4})/$', views.year_archive),
url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive),
url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail),
]
说明:
- 要捕获从URL中的值,用括号括起来,会当参数传入 views 视图。
- 没有必要添加一个斜线,因为每个URL都有。例如,它
^articles不是^/articles。 - 在
'r'前面的每个正则表达式字符串中是可选的,但建议。它告诉Python字符串是“原始” -没有什么字符串中应该进行转义。
请求示例:
- 一个请求
/articles/2005/03/会匹配上面列表中的第三条. Django 会调用函数views.month_archive(request, '2005', '03'). /articles/2005/3/不会匹配上面列表中的任何条目, 因为第三条的月份需要二位数字./articles/2003/会匹配上第一条而不是第二条,因为匹配是按照从上到下顺序而进行的, Django 会调用函数views.special_case_2003(request)/articles/2003不会匹配上面列表中的任何条目, 因为每个URL应该以 / 结尾./articles/2003/03/03/会匹配上最后一条. Django 会调用函数views.article_detail(request, '2003', '03', '03').
2. 命名组(Named groups)
在上面的简单例子中,并没有使用正则表达式分组,在更高级的用法中,很有可能使用正则分组来匹配URL并且将分组值通过参数传递给view函数。
在Python的正则表达式中,分组的语法是 (?P<name>pattern), name表示分组名,pattern表示一些匹配正则.
这里是一个简单的小例子:
# 正则知识
import re ret=re.search('(?P<id>\d{3})/(?P<name>\w{3})','weeew34ttt123/ooo') print(ret.group())
print(ret.group('id'))
print(ret.group('name'))
-------------------------------------
123/ooo
123
ooo
另一个栗子:
from django.conf.urls import url from . import views urlpatterns = [
url(r'^articles/2003/$', views.special_case_2003),
url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive),
url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$', views.article_detail),
]
For example:
- A request to
/articles/2005/03/会调用函数views.month_archive(request, year='2005',month='03'), 而不是views.month_archive(request, '2005', '03'). - A request to
/articles/2003/03/03/会调用函数views.article_detail(request, year='2003',month='03', day='03')
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/06/13 17:55
# @Author : MJay_Lee
# @File : test.py
# @Contact : limengjiejj@hotmail.com import re test_string = "life is short,your need is practice."
# ret = re.match(r'life',test_string)
# 匹配成功后返回一个匹配对象
# <_sre.SRE_Match object; span=(0, 4), match='life'>
# ret = re.match(r'life',test_string).span()
# ret = re.match(r'life',test_string) # 对于匹配对象可以使用group(num)和groups()来获取匹配表达式。
ret = re.match(r'(.*)is(.*)',test_string)
print(ret)
# <_sre.SRE_Match object; span=(0, 36), match='life is short,your need is practice.'>
# print("ret.group():",ret.group())
# ret.group(): life is short,your need is practice.
print("ret.group(1):",ret.group(1))
# ret.group(1): life is short,your need
print("ret.group(2):",ret.group(2))
# ret.group(2): practice.
# print("ret.group(1,2):",ret.group(1,2))
# 注意:从 1 到 所含的小组号。
# ret.group(1,2): ('life is short,your need ', ' practice.')
# print("ret.groups():",ret.groups())
# ret.groups(): ('life is short,your need ', ' practice.') '''
分组命名匹配: (?P<分组的名字>正则规则) 注意:是大写的P
'''
print(' 分割线 '.center(50,'*')) ret2 = re.match(r'(?P<m1>.*)is(?P<m2>.*)',test_string)
print(ret2)
# <_sre.SRE_Match object; span=(0, 36), match='life is short,your need is practice.'>
print("ret.group('m1'):", ret2.group('m1')) # 支持使用组名访问匹配项
# ret.group('m1'): life is short,your need
print("ret.group('m2'):", ret2.group('m2'))
# ret.group('m2'): practice. from django.conf.urls import url
我的实例
常见写法实例:
3. 二级路由(Including)
那如果映射 url 太多怎么办,全写一个在 urlpatterns 显得繁琐,so 二级路由应用而生
from django.conf.urls import include, url from apps.main import views as main_views
from credit import views as credit_views extra_patterns = [
url(r'^reports/$', credit_views.report),
url(r'^reports/(?P<id>[0-9]+)/$', credit_views.report),
url(r'^charge/$', credit_views.charge),
] urlpatterns = [
url(r'^$', main_views.homepage),
url(r'^help/', include('apps.help.urls')),
url(r'^credit/', include(extra_patterns)),
]
在上面这个例子中,如果请求url为 /credit/reports/ 则会调用函数 credit_views.report().
使用二级路由也可以减少代码冗余,使代码更加简洁易懂
# 原始版本
from django.conf.urls import url
from . import views urlpatterns = [
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/history/$', views.history),
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/edit/$', views.edit),
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/discuss/$', views.discuss),
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/permissions/$', views.permissions),
] # 改进版本
from django.conf.urls import include, url
from . import views urlpatterns = [
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/', include([
url(r'^history/$', views.history),
url(r'^edit/$', views.edit),
url(r'^discuss/$', views.discuss),
url(r'^permissions/$', views.permissions),
])),
]
使用include语法,将其他的urls.py包含进来
from django.conf.urls import url,include
from django.contrib import admin
from myapp01 import views
from myapp01 import urls as app01_urls
from myapp02 import urls as app02_urls urlpatterns = [
url(r'^admin/', admin.site.urls), # 使用include语言,将其他应用的的urls.py包含进来
url(r'^class_list/', views.class_list),
url(r'^add_classes/', views.add_class),
url(r'^delete_class/', views.delete_class),
url(r'^edit_class/', views.edit_class),
url(r'^student_list/', views.student_list),
url(r'^add_student/', views.AddStudent.as_view()),
url(r'^delete_student/', views.delete_student),
url(r'^edit_student/', views.EditStudent.as_view()),
url(r'^teacher_list/', views.teacher_list),
url(r'^add_teacher/', views.AddTeacher.as_view()),
url(r'^delete_teacher/', views.delete_teacher),
url(r'^edit_teacher/', views.EditTeacher.as_view()), # 二级路由
url(r'^fms/',include(app02_urls)), # 原始内容
# url(r'^file_list/', views.file_list),
# url(r'^uploading/', views.Uploading.as_view()),
# url(r'^download_file/', views.download_file),
# url(r'^delete_file/', views.delete_file), # 以上匹配不成功时,则默认引导至此页面
url(r'^$',views.hello_page)
]
4. 添他加额外的参数
URLconfs 有一个钩子可以让你加入一些额外的参数到view函数中.
from django.conf.urls import url
from . import views urlpatterns = [
url(r'^blog/(?P<year>[0-9]{4})/$', views.year_archive, {'foo': 'bar'}),
]
在上面的例子中,如果一个请求为 /blog/2005/, Django 将会调用函数l views.year_archive(request, year='2005',foo='bar').
需要注意的是,当你加上参数时,对应函数views.year_archive必须加上一个参数,参数名也必须命名为 foo,如下:
def year_archive(request, foo):
print(foo)
return render(request, 'index.html')
5. 别名的使用
url(r'^index',views.index,name='bieming')
url中还支持name参数的配置,如果配置了name属性,在模板的文件中就可以使用name值来代替相应的url值.
我们来看一个例子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{# <form action="/index/" method="post">#}
{# 这里只要使用bieming即可代替/index #}
<form action="{% url 'bieming' %}" method="post">
用户名:<input type="text" name="username">
密码:<input type="password" name="password">
<input type="submit" value="submit">
</form>
</body>
</html>
模版表现层html
urlpatterns = [
url(r'^index',views.index,name='bieming'),
url(r'^admin/', admin.site.urls),
# url(r'^articles/2003/$', views.special_case_2003),
url(r'^articles/([0-9]{4})/$', views.year_archive),
# url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive),
# url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail),
] def index(req):
if req.method=='POST':
username=req.POST.get('username')
password=req.POST.get('password')
if username=='alex' and password=='':
return HttpResponse("登陆成功")
return render(req,'index.html')
路由+业务逻辑的py配置
6. 指定view的默认配置
# URLconf
from django.conf.urls import url from . import views urlpatterns = [
url(r'^blog/$', views.page),
url(r'^blog/page(?P<num>[0-9]+)/$', views.page),
] # View (in blog/views.py)
def page(request, num=""):
# Output the appropriate page of blog entries, according to num.
...
在上述的例子中,两个 URL 模式指向同一个视图 views.page 但第一图案不捕获从 URL 任何东西。如果第一个模式匹配,该 page() 函数将使用它的默认参数 num,"1"。如果第二图案相匹配时, page()将使用任何 num 值由正则表达式捕获。
补充:
URLconf匹配的位置
URLconf 在请求的URL 上查找,将它当做一个普通的Python 字符串。不包括GET和POST参数以及域名。
例如,http://www.example.com/myapp/ 请求中,URLconf 将查找myapp/。
在http://www.example.com/myapp/?page=3 请求中,URLconf 仍将查找myapp/。
URLconf 不检查请求的方法。换句话讲,所有的请求方法 —— 同一个URL的POST、GET、HEAD等等 —— 都将路由到相同的函数。
捕获的参数永远都是字符串
每个在URLconf中捕获的参数都作为一个普通的Python字符串传递给视图,无论正则表达式使用的是什么匹配方式。例如,下面这行URLconf 中:
url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
传递到视图函数views.year_archive() 中的year 参数永远是一个字符串类型。
命名URL和URL反向解析
在使用Django 项目时,一个常见的需求是获得URL的最终形式,以用于嵌入到生成的内容中(视图中和显示给用户的URL等)或者用于处理服务器端的导航(重定向等)。
人们强烈希望不要硬编码这些URL(费力、不可扩展且容易产生错误)或者设计一种与URLconf 毫不相关的专门的URL 生成机制,因为这样容易导致一定程度上产生过期的URL。
换句话讲,需要的是一个DRY 机制。除了其它有点,它还允许设计的URL 可以自动更新而不用遍历项目的源代码来搜索并替换过期的URL。
获取一个URL 最开始想到的信息是处理它视图的标识(例如名字),查找正确的URL 的其它必要的信息有视图参数的类型(位置参数、关键字参数)和值。
Django 提供一个办法是让URL 映射是URL 设计唯一的地方。你填充你的URLconf,然后可以双向使用它:
- 根据用户/浏览器发起的URL 请求,它调用正确的Django 视图,并从URL 中提取它的参数需要的值。
- 根据Django 视图的标识和将要传递给它的参数的值,获取与之关联的URL。
第一种方式是我们在前面的章节中一直讨论的用法。第二种方式叫做反向解析URL、反向URL 匹配、反向URL 查询或者简单的URL 反查。
在需要URL 的地方,对于不同层级,Django 提供不同的工具用于URL 反查:
- 在模板中:使用url模板标签。
- 在Python 代码中:使用django.core.urlresolvers.reverse() 函数。
- 在更高层的与处理Django 模型实例相关的代码中:使用get_absolute_url() 方法。
上面说了一大堆,你可能并没有看懂。(那是官方文档的生硬翻译)。
咱们简单来说就是可以给我们的URL匹配规则起个名字,一个URL匹配模式起一个名字。
这样我们以后就不需要写死URL代码了,只需要通过名字来调用当前的URL。
举个简单的例子:
url(r'^home', views.home, name='home'), # 给我的url匹配模式起名为 home
url(r'^index/(\d*)', views.index, name='index'), # 给我的url匹配模式起名为index
这样:
在模板里面可以这样引用:
{% url 'home' %}
在views函数中可以这样引用:
from django.urls import reverse
reverse("index", args=("2018", ))
例子:
考虑下面的URLconf:

from django.conf.urls import url from . import views urlpatterns = [
# ...
url(r'^articles/([0-9]{4})/$', views.year_archive, name='news-year-archive'),
# ...
]
根据这里的设计,某一年nnnn对应的归档的URL是/articles/nnnn/。
你可以在模板的代码中使用下面的方法获得它们:
<a href="{% url 'news-year-archive' 2012 %}">2012 Archive</a>
<ul>
{% for yearvar in year_list %}
<li><a href="{% url 'news-year-archive' yearvar %}">{{ yearvar }} Archive</a></li>
{% endfor %}
</ul>
在Python 代码中,这样使用:
from django.urls import reverse
from django.shortcuts import redirect def redirect_to_year(request):
# ...
year = 2006
# ...
return redirect(reverse('news-year-archive', args=(year,)))
如果出于某种原因决定按年归档文章发布的URL应该调整一下,那么你将只需要修改URLconf 中的内容。
在某些场景中,一个视图是通用的,所以在URL 和视图之间存在多对一的关系。对于这些情况,当反查URL 时,只有视图的名字还不够。
注意:
为了完成上面例子中的URL 反查,你将需要使用命名的URL 模式。URL 的名称使用的字符串可以包含任何你喜欢的字符。不只限制在合法的Python 名称。
当命名你的URL 模式时,请确保使用的名称不会与其它应用中名称冲突。如果你的URL 模式叫做comment,而另外一个应用中也有一个同样的名称,当你在模板中使用这个名称的时候不能保证将插入哪个URL。
在URL 名称中加上一个前缀,比如应用的名称,将减少冲突的可能。我们建议使用myapp-comment 而不是comment。
命名空间模式
即使不同的APP使用相同的URL名称,URL的命名空间模式也可以让你唯一反转命名的URL。
举个例子:
project中的urls.py
from django.conf.urls import url, include urlpatterns = [
url(r'^app01/', include('app01.urls', namespace='app01')),
url(r'^app02/', include('app02.urls', namespace='app02')),
]
app01中的urls.py
from django.conf.urls import url
from app01 import views app_name = 'app01'
urlpatterns = [
url(r'^(?P<pk>\d+)/$', views.detail, name='detail')
]
app02中的urls.py
from django.conf.urls import url
from app02 import views app_name = 'app02'
urlpatterns = [
url(r'^(?P<pk>\d+)/$', views.detail, name='detail')
]
现在,我的两个app中 url名称重复了,我反转URL的时候就可以通过命名空间的名称得到我当前的URL。
语法:
'命名空间名称:URL名称'
模板中使用:
{% url 'app01:detail' pk=12 pp=99 %}
views中的函数中使用
v = reverse('app01:detail', kwargs={'pk':11})
这样即使app中URL的命名相同,我也可以反转得到正确的URL了。
总结:
urls.py(路由系统)
. 正则匹配的模式
. 分组匹配 --> 调用视图函数的时候额外传递 位置参数
. 分组命名匹配 --> 调用视图函数的时候额外传递 关键字参数
注意:
. 要么全都用分组匹配,要么全都用分组命名匹配, 不要混着用!!!!!!
. django URL正则表达式匹配的位置
. 从第一个斜线到问号之前这一段 路径!!!
. URL正则表达式 捕获的值都是 字符串类型!!!
. 可以给视图函数的参数设置默认值
. include 分级路由
查找的顺序:
请求 --> project/urls.py --> app/urls.py --> app/views.py
. URL匹配规则的别名
. 起别名是为了,增加代码的健壮性,不将URL硬编码到代码中!
. 用法
. 在views.py中如何根据别名找到 url
from django.urls import reverse
url = reverse('别名')
. 在模板语言中如何根据别名找到url
{% url '别名' %}
. 带参数的url如何反向生成?
. 位置参数
. 在views.py中:
reverse("别名", args=(参数1, 参数2, ...))
. 在模板语言中:
{% url "别名" 参数1, 参数2... %}
. 关键字参数
. 在views.py中:
reverse("别名", kwargs={"k1":参数1, ...})
. 在模板语言中:
{% url "别名" 参数1, 参数2... %}
. namespace(命名空间)
# 使用include语法,将其他的urls.py 包含进来
url(r'^app01/', include(app01_urls, namespace="app01"),),
url(r'^app02/', include(app02_urls, namespace="app02")),
. 位置参数
. 在views.py中:
reverse("命名空间:别名", args=(参数1, 参数2, ...))
. 在模板语言中:
{% url "命名空间:别名" 参数1, 参数2... %}
. 关键字参数
. 在views.py中:
reverse("命名空间:别名", kwargs={"k1":参数1, ...})
. 在模板语言中:
{% url "命名空间:别名" 参数1, 参数2... %}
示例:用一个函数一个URL匹配模式实现 书书籍表、作者表、出版社表的展示和删除操作
关键点:
1. URL匹配模式的设计
分组匹配或分组命名匹配
给URL匹配模式起别名
2. 反射
由一个字符串,找到对应的类变量
3. URL的反向解析(别名--> 完整的URL)
urls.py匹配模式改写
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/06/19 23:07
# @Author : MJay_Lee
# @File : urls.py
# @Contact : limengjiejj@hotmail.com from django.conf.urls import url
from myapp02 import views as v2 urlpatterns = [
# 原始写法
# url(r'^file_list/', v2.file_list, name = "file_index"),
# url(r'^file_delete/', v2.delete_file), # 改进写法
url(r'(?P<table_name_init>\w+)_(?P<operation>delete|list+)/',v2.showtime,name="showtime"), url(r'^uploading/', v2.Uploading.as_view()),
url(r'^download_file/', v2.download_file), ]
url改写
views.py反射,匹配业务类型,同时实现url反向解析获得完整url
import os
import shutil
import platform
import uuid
from django.views import View
from django.shortcuts import render,redirect,HttpResponse
from django.http import StreamingHttpResponse
from django.utils.encoding import escape_uri_path
from . import models
from SMS0614 import settings
from unrar import rarfile
from django.urls import reverse def showtime(request,table_name_init,operation): # 拼接类名
table_name = table_name_init.capitalize()
# 反射
if hasattr(models,table_name):
# 若存在匹配的类名
class_obj = getattr(models,table_name) # 规避大小写的书写情况,一律采用大写来判断
# 展示内容:
if operation.upper() == "LIST": # models.File.objects.all()
ret = class_obj.objects.all()
if table_name == "File":
for file_obj in ret:
file_obj.fileMsg = eval(file_obj.fileMsg)
return render(
request,
"{}_{}.html".format(table_name_init,operation),
{
"objs_list":ret,
"table_name_init":table_name_init,
"operation":operation,
"nav_sidebar_obj":"{}_{}".format(table_name_init,operation)
}
) # 删除操作
elif operation.upper() == "DELETE":
delete_id = request.GET.get("id")
# 删除
class_obj.objects.get(id=delete_id).delete()
# 跳转相应的列表页面
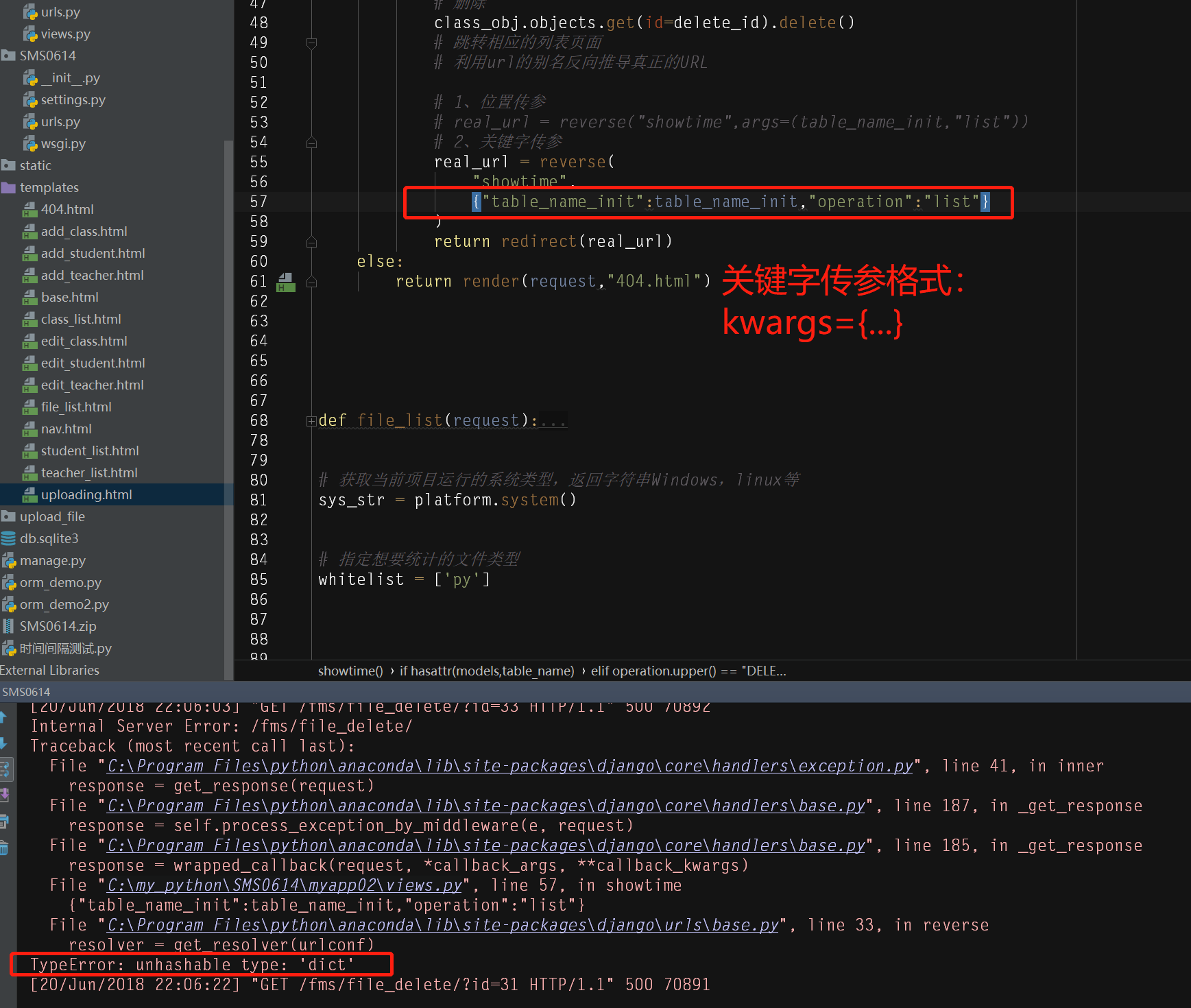
# 利用url的别名反向推导真正的URL # 1、位置传参
# real_url = reverse("showtime",args=(table_name_init,"list"))
# 2、关键字传参
real_url = reverse(
"showtime",
kwargs={"table_name_init":table_name_init,"operation":"list"}
)
return redirect(real_url)
else:
return render(request,"404.html") # 原始展示文件列表
# def file_list(request):
# file_list = models.File.objects.all()
# # 将数据库中的str对象转为list对象
# for file_obj in file_list:
# file_obj.fileMsg = eval(file_obj.fileMsg)
# return render(
# request,
# "file_list.html",
# {"file_list": file_list,"nav_sidebar_obj":"file_list"}
# ) # 获取当前项目运行的系统类型,返回字符串Windows,linux等
sys_str = platform.system() # 指定想要统计的文件类型
whitelist = ['py'] # 遍历文件, 递归遍历文件夹中的所有
def getFile(basedir):
filelists = []
for parent, dirnames, filenames in os.walk(basedir):
# for dirname in dirnames:
# getFile(os.path.join(parent,dirname)) #递归
# MAC环境下略过__MACOSX文件夹
if "__MACOSX" in dirnames:
pop_index = dirnames.index("__MACOSX")
dirnames.pop(pop_index)
for filename in filenames:
ext = filename.split('.')[-1]
# 只统计指定的文件类型,略过一些log和cache文件
if ext in whitelist:
filelists.append(os.path.join(parent, filename))
return filelists # 统计一个文件的行数
def countLine(fname):
count = 0
single_quotes_flag = False
double_quotes_flag = False
with open(fname, 'rb') as f:
for file_line in f:
file_line = file_line.strip()
# print(file_line)
# 空行
if file_line == b'':
pass # 注释 # 开头
elif file_line.startswith(b'#'):
pass # 注释 单引号 ''' 开头
elif file_line.startswith(b"'''") and not single_quotes_flag:
single_quotes_flag = True
# 注释 中间 和 ''' 结尾
elif single_quotes_flag == True:
if file_line.endswith(b"'''"):
single_quotes_flag = False # 注释 双引号 """ 开头
elif file_line.startswith(b'"""') and not double_quotes_flag:
double_quotes_flag = True
# 注释 中间 和 """ 结尾
elif double_quotes_flag == True:
if (file_line.endswith(b'"""')):
double_quotes_flag = False # 代码
else:
count += 1 # 单个文件行数
# print(fname, '----count:', count)
# return count
if sys_str == "Windows":
fileinfo = str(fname.split('\\')[-1] + ",count:----" + str(count))
else:
fileinfo = str(fname.split('/')[-1] + ",count:----" + str(count))
return fileinfo, count UPLOAD_FILE_TYPE = ["zip", "tar", "gztar","bztar","xztar","rar"] # 上传功能
class Uploading(View): def get(self, request):
return render(request, "uploading.html") def post(self, request):
# 拿到上传文件对象
file_obj = request.FILES.get("user_file")
# 将上传文件的文件名字,从右边按'.'切割一次,返回值是列表[文件名,类型]
filename, suffix = file_obj.name.rsplit(".", maxsplit=1)
# 校验上传文件类型,不匹配的类型返回错误提示
if suffix not in UPLOAD_FILE_TYPE:
return HttpResponse("上传文件格式不正确")
# 拼接得到上传文件的全路径,并且统一上传文件放在upload_file文件夹中
file_name = os.path.join(settings.UPLOAD_FILE_DIR, file_obj.name)
# 新建一个和上传文件同名的文件
with open(file_name, "wb") as f:
# 从上传文件对象一点一点读取数据,避免过大文件溢出内存
for chunk in file_obj.chunks():
f.write(chunk) # 对上传的文件做处理
upload_path = os.path.join(settings.UPLOAD_FILE_DIR, "files",str(uuid.uuid4()))
# 解压文件至指定文件夹
if suffix == "rar":
# 读取rar文件
rar = rarfile.RarFile(file_name)
if not os.path.isdir(upload_path):
os.mkdir(upload_path)
os.chdir(upload_path)
# 通过索引获取压缩文件中的文件
rar.extractall()
else:
shutil.unpack_archive(file_name, extract_dir=upload_path) filelists = getFile(upload_path)
# 初始化总行数和单个文件信息属性
totalline = 0
fileinfo_list = []
# 遍历解压后的文件列表,统计单个文件的行数并汇总 for filelist in filelists:
fileinfo_list.append(countLine(filelist)[0])
totalline = totalline + countLine(filelist)[1] # 解压压缩文件,并获取代码行数属性
file_info = fileinfo_list
total_line = totalline
# 单个文件进行文件对象实例化,文件名,文件大小,代码行数
models.File.objects.create(
fileName=file_obj.name,
fileSize=file_obj.size,
fileMsg=file_info,
fileLineCount=total_line,
)
return redirect('/fms/file_list/') # 切片读取文件
def file_iterator(filename, chunk_size=512):
with open(filename, 'rb') as f:
while True:
c = f.read(chunk_size)
if c:
yield c
else:
break # 下载功能
def download_file(request):
the_file_name = models.File.objects.get(
id=request.GET.get("id")).fileName # 显示在弹出对话框中的默认的下载文件名
file_path = os.path.join(settings.UPLOAD_FILE_DIR, the_file_name) # 要下载的文件路径
response = StreamingHttpResponse(file_iterator(file_path))
response[
'Content-Type'] = 'application/octet-stream' # #设定文件头,这种设定可以让任意文件都能正确下载,而且已知文本文件不是本地打开
# response['Content-Disposition'] = 'attachment;filename="download.zip"' # BUG1:给出一个固定的文件名,且不能为中文,文件名写死了
# response['Content-Disposition'] = 'attachment;filename={0}'.format(the_file_name.encode("utf-8")) # BUG2:中文会乱码
response['Content-Disposition'] = "attachment; filename*=utf-8''{}".format(
escape_uri_path(the_file_name)) # 正确写法
return response # 原始删除功能
# def delete_file(request):
# file_index = reverse("file_index")
# print(file_index)
# del_file_id = request.GET.get("id")
# models.File.objects.get(id=del_file_id).delete()
# return redirect(file_index)
views.py改写
注意:反向解析url时,注意传参格式
四、 Django Views(视图函数)
一个视图函数(类),简称视图,是一个简单的Python 函数(类),它接受Web请求并且返回Web响应。 响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片。 无论视图本身包含什么逻辑,都要返回响应。代码写在哪里也无所谓,只要它在你当前项目目录下面。
除此之外没有更多的要求了——可以说“没有什么神奇的地方”。
为了将代码放在某处,大家约定成俗将视图放置在项目(project)或应用程序(app)目录中的名为views.py的文件中。
一个简单的视图
下面是一个以HTML文档的形式返回当前日期和时间的视图:
from django.http import HttpResponse
import datetime def current_datetime(request):
now = datetime.datetime.now()
html = "<html><body>It is now %s.</body></html>" % now
return HttpResponse(html)
让我们来逐行解释下上面的代码:
首先,我们从 django.http模块导入了HttpResponse类,以及Python的datetime库。
接着,我们定义了current_datetime函数。它就是视图函数。每个视图函数都使用HttpRequest对象作为第一个参数,并且通常称之为request。
注意,视图函数的名称并不重要;不需要用一个统一的命名方式来命名,以便让Django识别它。我们将其命名为current_datetime,是因为这个名称能够比较准确地反映出它实现的功能。
这个视图会返回一个HttpResponse对象,其中包含生成的响应。每个视图函数都负责返回一个HttpResponse对象。
Django使用请求和响应对象来通过系统传递状态。
当浏览器向服务端请求一个页面时,Django创建一个HttpRequest对象,该对象包含关于请求的元数据。然后,Django加载相应的视图,将这个HttpRequest对象作为第一个参数传递给视图函数。
每个视图负责返回一个HttpResponse对象。
CBV和FBV
我们之前写过的都是基于函数的view,就叫FBV。还可以把view写成基于类的,就叫CBV。
就拿我们之前写过的添加班级为例:
FBV版:
# FBV版添加班级
def add_class(request):
if request.method == "POST":
class_name = request.POST.get("class_name")
models.Classes.objects.create(name=class_name)
return redirect("/class_list/")
return render(request, "add_class.html")
CBV版:
# CBV版添加班级
from django.views import View class AddClass(View): def get(self, request):
return render(request, "add_class.html") def post(self, request):
class_name = request.POST.get("class_name")
models.Classes.objects.create(name=class_name)
return redirect("/class_list/")
注意:
使用CBV时,urls.py中也做对应的修改:
# urls.py中
url(r'^add_class/$', views.AddClass.as_view()),
(装饰器相关,后续补上)
Request对象和Response对象
http请求中产生两
个核心对象:
http请求:HttpRequest对象
http响应:HttpResponse对象
request对象
当一个页面被请求时,Django就会创建一个包含本次请求原信息的HttpRequest对象。
Django会将这个对象自动传递给响应的视图函数,一般视图函数约定俗成地使用 request 参数承接这个对象。
请求相关的常用值
- path_info 返回用户访问url,不包括域名
- method 请求中使用的HTTP方法的字符串表示,全大写表示。
- GET 包含所有HTTP GET参数的类字典对象
- POST 包含所有HTTP POST参数的类字典对象
- body 请求体,byte类型 request.POST的数据就是从body里面提取到的
属性
所有的属性应该被认为是只读的,除非另有说明。
属性:
django将请求报文中的请求行、头部信息、内容主体封装成 HttpRequest 类中的属性。
除了特殊说明的之外,其他均为只读的。 0.HttpRequest.scheme
表示请求方案的字符串(通常为http或https) 1.HttpRequest.body 一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,例如:二进制图片、XML,Json等。 但是,如果要处理表单数据的时候,推荐还是使用 HttpRequest.POST 。 另外,我们还可以用 python 的类文件方法去操作它,详情参考 HttpRequest.read() 。 2.HttpRequest.path 一个字符串,表示请求的路径组件(不含域名)。 例如:"/music/bands/the_beatles/" 3.HttpRequest.method 一个字符串,表示请求使用的HTTP 方法。必须使用大写。 例如:"GET"、"POST" 4.HttpRequest.encoding 一个字符串,表示提交的数据的编码方式(如果为 None 则表示使用 DEFAULT_CHARSET 的设置,默认为 'utf-8')。
这个属性是可写的,你可以修改它来修改访问表单数据使用的编码。
接下来对属性的任何访问(例如从 GET 或 POST 中读取数据)将使用新的 encoding 值。
如果你知道表单数据的编码不是 DEFAULT_CHARSET ,则使用它。 5.HttpRequest.GET 一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象。 6.HttpRequest.POST 一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。 POST 请求可以带有空的 POST 字典 —— 如果通过 HTTP POST 方法发送一个表单,但是表单中没有任何的数据,QueryDict 对象依然会被创建。
因此,不应该使用 if request.POST 来检查使用的是否是POST 方法;应该使用 if request.method == "POST" 另外:如果使用 POST 上传文件的话,文件信息将包含在 FILES 属性中。 7.HttpRequest.COOKIES 一个标准的Python 字典,包含所有的cookie。键和值都为字符串。 8.HttpRequest.FILES 一个类似于字典的对象,包含所有的上传文件信息。
FILES 中的每个键为<input type="file" name="" /> 中的name,值则为对应的数据。 注意,FILES 只有在请求的方法为POST 且提交的<form> 带有enctype="multipart/form-data" 的情况下才会
包含数据。否则,FILES 将为一个空的类似于字典的对象。 9.HttpRequest.META 一个标准的Python 字典,包含所有的HTTP 首部。具体的头部信息取决于客户端和服务器,下面是一些示例: CONTENT_LENGTH —— 请求的正文的长度(是一个字符串)。
CONTENT_TYPE —— 请求的正文的MIME 类型。
HTTP_ACCEPT —— 响应可接收的Content-Type。
HTTP_ACCEPT_ENCODING —— 响应可接收的编码。
HTTP_ACCEPT_LANGUAGE —— 响应可接收的语言。
HTTP_HOST —— 客服端发送的HTTP Host 头部。
HTTP_REFERER —— Referring 页面。
HTTP_USER_AGENT —— 客户端的user-agent 字符串。
QUERY_STRING —— 单个字符串形式的查询字符串(未解析过的形式)。
REMOTE_ADDR —— 客户端的IP 地址。
REMOTE_HOST —— 客户端的主机名。
REMOTE_USER —— 服务器认证后的用户。
REQUEST_METHOD —— 一个字符串,例如"GET" 或"POST"。
SERVER_NAME —— 服务器的主机名。
SERVER_PORT —— 服务器的端口(是一个字符串)。
从上面可以看到,除 CONTENT_LENGTH 和 CONTENT_TYPE 之外,请求中的任何 HTTP 首部转换为 META 的键时,
都会将所有字母大写并将连接符替换为下划线最后加上 HTTP_ 前缀。
所以,一个叫做 X-Bender 的头部将转换成 META 中的 HTTP_X_BENDER 键。 10.HttpRequest.user 一个 AUTH_USER_MODEL 类型的对象,表示当前登录的用户。 如果用户当前没有登录,user 将设置为 django.contrib.auth.models.AnonymousUser 的一个实例。你可以通过 is_authenticated() 区分它们。 例如: if request.user.is_authenticated():
# Do something for logged-in users.
else:
# Do something for anonymous users. user 只有当Django 启用 AuthenticationMiddleware 中间件时才可用。 ------------------------------------------------------------------------------------- 匿名用户
class models.AnonymousUser django.contrib.auth.models.AnonymousUser 类实现了django.contrib.auth.models.User 接口,但具有下面几个不同点: id 永远为None。
username 永远为空字符串。
get_username() 永远返回空字符串。
is_staff 和 is_superuser 永远为False。
is_active 永远为 False。
groups 和 user_permissions 永远为空。
is_anonymous() 返回True 而不是False。
is_authenticated() 返回False 而不是True。
set_password()、check_password()、save() 和delete() 引发 NotImplementedError。
New in Django 1.8:
新增 AnonymousUser.get_username() 以更好地模拟 django.contrib.auth.models.User。 11.HttpRequest.session 一个既可读又可写的类似于字典的对象,表示当前的会话。只有当Django 启用会话的支持时才可用。
完整的细节参见会话的文档。
属性相关
上传文件示例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>上传文件示例</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
<h1>django文件上传</h1>
<form action="/upload_file/" method="post" enctype="multipart/form-data">
<input type="file" name="user_pic">
<input type="submit" value="上传">
</form>
</body>
</html>
html
py源码
def upload_file(request):
"""
保存上传文件前,数据需要存放在某个位置。默认当上传文件小于2.5M时,django会将上传文件的全部内容读进内存。从内存读取一次,写磁盘一次。
但当上传文件很大时,django会把上传文件写到临时文件中,然后存放到系统临时文件夹中。
:param request:
:return:
"""
if request.method == "POST":
file_obj = request.FILES.get("user_pic")
print(file_obj,type(file_obj)) # test.png <class 'django.core.files.uploadedfile.InMemoryUploadedFile'>
file_name = file_obj.name # 得到文件名
with open(file_name,"wb") as f:
for line in file_obj.chunks(): # 从上传的文件对象中一点一点读取数据
f.write(line) # 写到新建的文件中
return HttpResponse(file_name + "上传成功")
return render(request,"upload_file.html")
方法
1.HttpRequest.get_host() 根据从HTTP_X_FORWARDED_HOST(如果打开 USE_X_FORWARDED_HOST,默认为False)和 HTTP_HOST 头部信息返回请求的原始主机。
如果这两个头部没有提供相应的值,则使用SERVER_NAME 和SERVER_PORT,在PEP 3333 中有详细描述。 USE_X_FORWARDED_HOST:一个布尔值,用于指定是否优先使用 X-Forwarded-Host 首部,仅在代理设置了该首部的情况下,才可以被使用。 例如:"127.0.0.1:8000" 注意:当主机位于多个代理后面时,get_host() 方法将会失败。除非使用中间件重写代理的首部。 2.HttpRequest.get_full_path() 返回 path,如果可以将加上查询字符串。 例如:"/music/bands/the_beatles/?print=true" 3.HttpRequest.get_signed_cookie(key, default=RAISE_ERROR, salt='', max_age=None) 返回签名过的Cookie 对应的值,如果签名不再合法则返回django.core.signing.BadSignature。 如果提供 default 参数,将不会引发异常并返回 default 的值。 可选参数salt 可以用来对安全密钥强力攻击提供额外的保护。max_age 参数用于检查Cookie 对应的时间戳以确保Cookie 的时间不会超过max_age 秒。 复制代码
>>> request.get_signed_cookie('name')
'Tony'
>>> request.get_signed_cookie('name', salt='name-salt')
'Tony' # 假设在设置cookie的时候使用的是相同的salt
>>> request.get_signed_cookie('non-existing-cookie')
...
KeyError: 'non-existing-cookie' # 没有相应的键时触发异常
>>> request.get_signed_cookie('non-existing-cookie', False)
False
>>> request.get_signed_cookie('cookie-that-was-tampered-with')
...
BadSignature: ...
>>> request.get_signed_cookie('name', max_age=60)
...
SignatureExpired: Signature age 1677.3839159 > 60 seconds
>>> request.get_signed_cookie('name', False, max_age=60)
False
复制代码 4.HttpRequest.is_secure() 如果请求时是安全的,则返回True;即请求通是过 HTTPS 发起的。 5.HttpRequest.is_ajax() 如果请求是通过XMLHttpRequest 发起的,则返回True,方法是检查 HTTP_X_REQUESTED_WITH 相应的首部是否是字符串'XMLHttpRequest'。 大部分现代的 JavaScript 库都会发送这个头部。如果你编写自己的 XMLHttpRequest 调用(在浏览器端),你必须手工设置这个值来让 is_ajax() 可以工作。 如果一个响应需要根据请求是否是通过AJAX 发起的,并且你正在使用某种形式的缓存例如Django 的 cache middleware,
你应该使用 vary_on_headers('HTTP_X_REQUESTED_WITH') 装饰你的视图以让响应能够正确地缓存。
方法
注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,需要用:
request.POST.getlist("hobby")
Response对象
与由Django自动创建的HttpRequest对象相比,HttpResponse对象是我们的职责范围了。我们写的每个视图都需要实例化,填充和返回一个HttpResponse。
HttpResponse类位于django.http模块中。
使用
传递字符串
from django.http import HttpResponse
response = HttpResponse("Here's the text of the Web page.")
response = HttpResponse("Text only, please.", content_type="text/plain")
设置或删除响应头信息
response = HttpResponse()
response['Content-Type'] = 'text/html; charset=UTF-8'
del response['Content-Type']
属性
HttpResponse.content:响应内容
HttpResponse.charset:响应内容的编码
HttpResponse.status_code:响应的状态码
JsonResponse对象
常用场景,后台写API将python数据给其他框架vue,react等使用
from django.http import JsonResponse def test(request):
data = {"name": "Egon", "hobby": "喊麦"}
# import json
# return HttpResponse(json.dumps(data))
# 上句等同于
# return JsonResponse(data)
list1 = [1, 2, 3, 4]
return JsonResponse(list1, safe=False)
JsonResponse是HttpResponse的子类,专门用来生成JSON编码的响应。
from django.http import JsonResponse
response = JsonResponse({'foo': 'bar'})
print(response.content)
b'{"foo": "bar"}'
默认只能传递字典类型,如果要传递非字典类型需要设置一下safe关键字参数。
response = JsonResponse([1, 2, 3], safe=False)
Django shortcut functions
render()

结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
参数:
request: 用于生成响应的请求对象。 template_name:要使用的模板的完整名称,可选的参数 context:添加到模板上下文的一个字典。默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。 content_type:生成的文档要使用的MIME类型。默认为 DEFAULT_CONTENT_TYPE 设置的值。默认为'text/html' status:响应的状态码。默认为200。 useing: 用于加载模板的模板引擎的名称。 一个简单的例子:
from django.shortcuts import render def my_view(request):
# 视图的代码写在这里
return render(request, 'myapp/index.html', {'foo': 'bar'})
上面的代码等于:
from django.http import HttpResponse
from django.template import loader def my_view(request):
# 视图代码写在这里
t = loader.get_template('myapp/index.html')
c = {'foo': 'bar'}
return HttpResponse(t.render(c, request))
redirect()
参数可以是:
- 一个模型:将调用模型的get_absolute_url() 函数
- 一个视图,可以带有参数:将使用urlresolvers.reverse 来反向解析名称
- 一个绝对的或相对的URL,将原封不动的作为重定向的位置。
默认返回一个临时的重定向;传递permanent=True 可以返回一个永久的重定向。
示例:
你可以用多种方式使用redirect() 函数。
传递一个具体的ORM对象(了解即可)
将调用具体ORM对象的get_absolute_url() 方法来获取重定向的URL:
from django.shortcuts import redirect def my_view(request):
...
object = MyModel.objects.get(...)
return redirect(object)
传递一个视图的名称
def my_view(request):
...
return redirect('some-view-name', foo='bar')
传递要重定向到的一个具体的网址
def my_view(request):
...
return redirect('/some/url/')
当然也可以是一个完整的网址
def my_view(request):
...
return redirect('http://example.com/')
默认情况下,redirect() 返回一个临时重定向。以上所有的形式都接收一个permanent 参数;如果设置为True,将返回一个永久的重定向:
def my_view(request):
...
object = MyModel.objects.get(...)
return redirect(object, permanent=True)
扩展阅读:
临时重定向(响应状态码:302)和永久重定向(响应状态码:301)对普通用户来说是没什么区别的,它主要面向的是搜索引擎的机器人。
A页面临时重定向到B页面,那搜索引擎收录的就是A页面。
A页面永久重定向到B页面,那搜索引擎收录的就是B页面。
再次强调:
1. HttpRequest对象
当请求一个页面时,Django 创建一个 HttpRequest对象包含原数据的请求。然后 Django 加载适当的视图,通过 HttpRequest作为视图函数的第一个参数。每个视图负责返回一个HttpResponse目标。
path: 请求页面的全路径,不包括域名
method: 请求中使用的HTTP方法的字符串表示。全大写表示。例如
if req.method=="GET":
do_something()
elseif req.method=="POST":
do_something_else()
GET: 包含所有HTTP GET参数的类字典对象
POST: 包含所有HTTP POST参数的类字典对象
服务器收到空的POST请求的情况也是可能发生的,也就是说,表单form通过
HTTP POST方法提交请求,但是表单中可能没有数据,因此不能使用
if req.POST来判断是否使用了HTTP POST 方法;应该使用 if req.method=="POST"
COOKIES: 包含所有cookies的标准Python字典对象;keys和values都是字符串。
FILES: 包含所有上传文件的类字典对象;FILES中的每一个Key都是<input type="file" name="" />标签中
name属性的值,FILES中的每一个value同时也是一个标准的python字典对象,包含下面三个Keys:
filename: 上传文件名,用字符串表示
content_type: 上传文件的Content Type
content: 上传文件的原始内容
user: 是一个django.contrib.auth.models.User对象,代表当前登陆的用户。如果访问用户当前
没有登陆,user将被初始化为django.contrib.auth.models.AnonymousUser的实例。你
可以通过user的is_authenticated()方法来辨别用户是否登陆:
if req.user.is_authenticated();只有激活Django中的AuthenticationMiddleware
时该属性才可用
session: 唯一可读写的属性,代表当前会话的字典对象;自己有激活Django中的session支持时该属性才可用。
META: 一个标准的Python字典包含所有可用的HTTP头。可用标题取决于客户端和服务器,但这里是一些例子:
CONTENT_LENGTH – 请求体的长度(一个字符串)。
CONTENT_TYPE – 请求体的类型。
HTTP_ACCEPT - 为响应–可以接受的内容类型。
HTTP_ACCEPT_ENCODING – 接受编码的响应
HTTP_ACCEPT_LANGUAGE – 接受语言的反应
HTTP_HOST – 客户端发送的HTTP主机头。
HTTP_REFERER – 参考页面
HTTP_USER_AGENT – 客户端的用户代理字符串。
QUERY_STRING – 查询字符串,作为一个单一的(分析的)字符串。
REMOTE_ADDR – 客户端的IP地址
REMOTE_HOST – 客户端的主机名
REMOTE_USER – 用户通过Web服务器的身份验证。
REQUEST_METHOD – 字符串,如"GET"或"POST"
SERVER_NAME – 服务器的主机名
SERVER_PORT – 服务器的端口(一个字符串)。
HTTPRequest对象
2. HttpResponse对象
对于HttpRequest对象来说,是由django自动创建的,但是,HttpResponse对象就必须我们自己创建。每个view请求处理方法必须返回一个HttpResponse对象。
在HttpResponse对象上扩展的常用方法:
- 页面渲染:render(推荐),render_to_response,
- 页面跳转:redirect
- locals: 可以直接将对应视图函数中所有的变量传给模板
def index(request):
name = "limengjie"
return render(request,"index.html",{"name":"limengjie"}) # 页面渲染
# return render_to_response("index.html",{"name":"limengjie"}) # 页面渲染
# return redirect("http://www.google.com") #跳转
# return render_to_response("index.html",locals())
值得注意的是对于页面渲染的方法中,render和render_to_response使用方法和功能类似,但是render功能更为强大,推荐使用
3. render()
- render(request, template_name, context=None, content_type=None, status=None, using=None)[source]
- 结合给定的模板与一个给定的上下文,返回一个字典HttpResponse在渲染文本对象
所需的参数
template_name 一个模板的使用或模板序列名称全称。如果序列是给定的,存在于第一个模板将被使用。
可选参数
context 一组字典的值添加到模板中。默认情况下,这是一个空的字典。
content_type MIME类型用于生成文档。
status 为响应状态代码。默认值为200
using 这个名字一个模板引擎的使用将模板。
# url.py文件中配置 from django.contrib import admin
from django.conf.urls import url
from app01 import views # 用户访问的URL与将要执行的函数的对应关系
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^publisher_list/', views.publisher_list),
url(r'^add_publisher/', views.add_publisher,name='other_name'),
url(r'^delete_publisher/', views.delete_publisher),
url(r'^edit_publisher/', views.edit_publisher),
url(r'^book_list/', views.book_list),
url(r'^add_book/', views.add_book),
url(r'^delete_book/', views.delete_book),
url(r'^edit_book/', views.edit_book),
] # views.py文件中配置 from django.shortcuts import HttpResponse,render,redirect
from app01 import models def publisher_list(request):
# return HttpResponse('ok')
# 1、取数据(使用ORM工具去查询)
res = models.Publisher.objects.all()
# 2、在HTML页面上显示出来
return render(request, 'publisher_list.html', {'publisher_list':res}) def add_publisher(request):
# 当你是POST方法提交数据时,
# 1、拿到用户提交的数据
if request.method == "POST":
new_publisher_name = request.POST.get('name')
# 2、去数据库中去存储
models.Publisher.objects.create(name=new_publisher_name)
# return HttpResponse("添加成功")
return redirect('/publisher_list/')
return render(request,'add_publisher.html') def delete_publisher(request):
# 1、拿到用户要删除的出版社的ID值
# print(request.method)
# print(request.GET)
# print(request.POST)
delete_id = request.GET.get('id')
# 2、去数据库中根据ID值删除数据
models.Publisher.objects.get(id=delete_id).delete()
return redirect('/publisher_list/')
render实例部分源码参考
五、 模板
Django模板系统
常用语法
只需要记两种特殊符号:
{{ }}和 {% %}
变量相关的用{{}},逻辑相关的用{%%}。
变量
{{ 变量名 }}
变量名由字母数字和下划线组成。
点(.)在模板语言中有特殊的含义,用来获取对象的相应属性值。
几个例子:
view中代码:
def template_test(request):
l = [11, 22, 33]
d = {"name": "alex"} class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age def dream(self):
return "{} is dream...".format(self.name) Alex = Person(name="Alex", age=34)
Egon = Person(name="Egon", age=9000)
Eva_J = Person(name="Eva_J", age=18) person_list = [Alex, Egon, Eva_J]
return render(request, "template_test.html", {"l": l, "d": d, "person_list": person_list})
模板中支持的写法:
{# 取l中的第一个参数 #}
{{ l.0 }}
{# 取字典中key的值 #}
{{ d.name }}
{# 取对象的name属性 #}
{{ person_list.0.name }}
{# .操作只能调用不带参数的方法 #}
{{ person_list.0.dream }}
Filters
语法: {{ value|filter_name:参数 }}
default
{{ value|default: "nothing"}}
如果value值没传的话就显示nothing
length
{{ value|length }}
'|'左右没有空格没有空格没有空格
返回value的长度,如 value=['a', 'b', 'c', 'd']的话,就显示4.
filesizeformat
将值格式化为一个 “人类可读的” 文件尺寸 (例如 '13 KB', '4.1 MB', '102 bytes', 等等)。例如:
{{ value|filesizeformat }}
如果 value 是 123456789,输出将会是 117.7 MB。
slice
切片
{{value|slice:"2:-1"}}
date
格式化
{{ value|date:"Y-m-d H:i:s"}}
safe
Django的模板中会对HTML标签和JS等语法标签进行自动转义,原因显而易见,这样是为了安全。但是有的时候我们可能不希望这些HTML元素被转义,比如我们做一个内容管理系统,后台添加的文章中是经过修饰的,这些修饰可能是通过一个类似于FCKeditor编辑加注了HTML修饰符的文本,如果自动转义的话显示的就是保护HTML标签的源文件。为了在Django中关闭HTML的自动转义有两种方式,如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义。
防止跨站脚本xss攻击。
比如:
value = "<a href='#'>点我</a>"
{{ value|safe}}
truncatechars
如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾。
参数:截断的字符数
{{ value|truncatechars:9}}
自定义filter
自定义filter实现思路
1、在app新建一个 templatetags 包(Python package)
2、新建一个py文件,命名为xx
3、xx.py文件中定义一个实现具体功能的函数,同时按照固定的写法注册到django的模板语言中
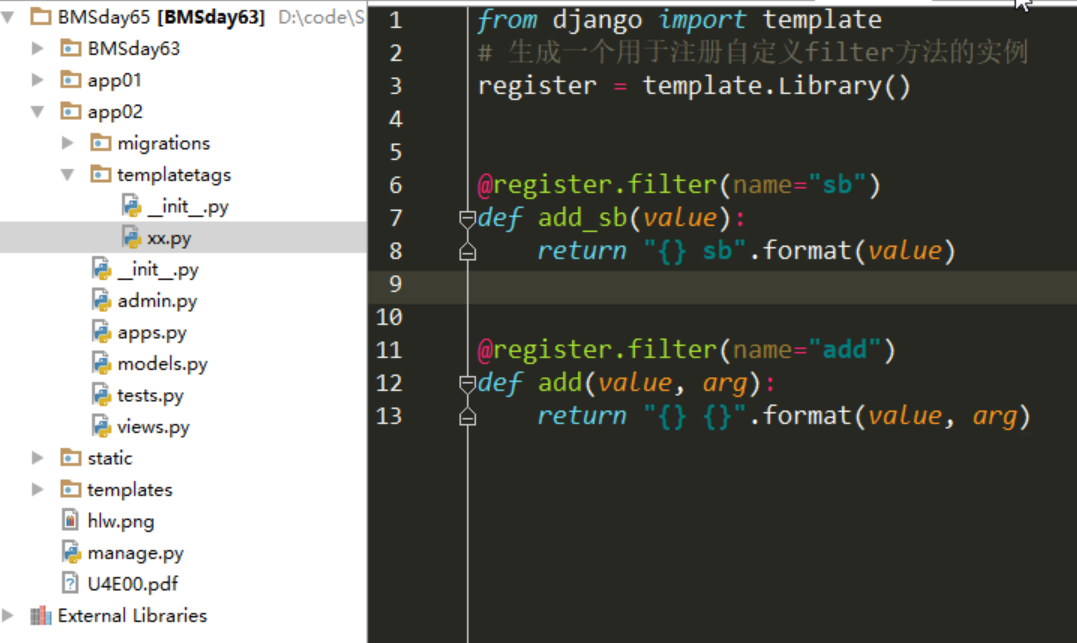
from django import template
register = template.Library()
@register.filter() # 可指定别名,如@register.filter(name="addSB")
def add_sb(value):
return value + "sb"
4、重启项目
5、实际调用
1、先导入新建的py文件名字
{% load xx %}
2、调用自己写的filter
{{ value|add_sb }}
自定义过滤器只是带有一个或两个参数的Python函数:
- 变量(输入)的值 - -不一定是一个字符串
- 参数的值 - 这可以有一个默认值,或完全省略
例如,在过滤器{{var | foo:“bar”}}中,过滤器foo将传递变量var和参数“bar”。
自定义filter代码文件摆放位置:
app01/
__init__.py
models.py
templatetags/ # 在app01下面新建一个templatetages package
__init__.py
app01_filters.py # 建一个存放自定义filter的文件
views.py
编写自定义filter
from django import template
register = template.Library() @register.filter(name="cut")
def cut(value, arg):
return value.replace(arg, "") @register.filter(name="addSB")
def add_sb(value):
return "{} SB".format(value)
使用自定义filter
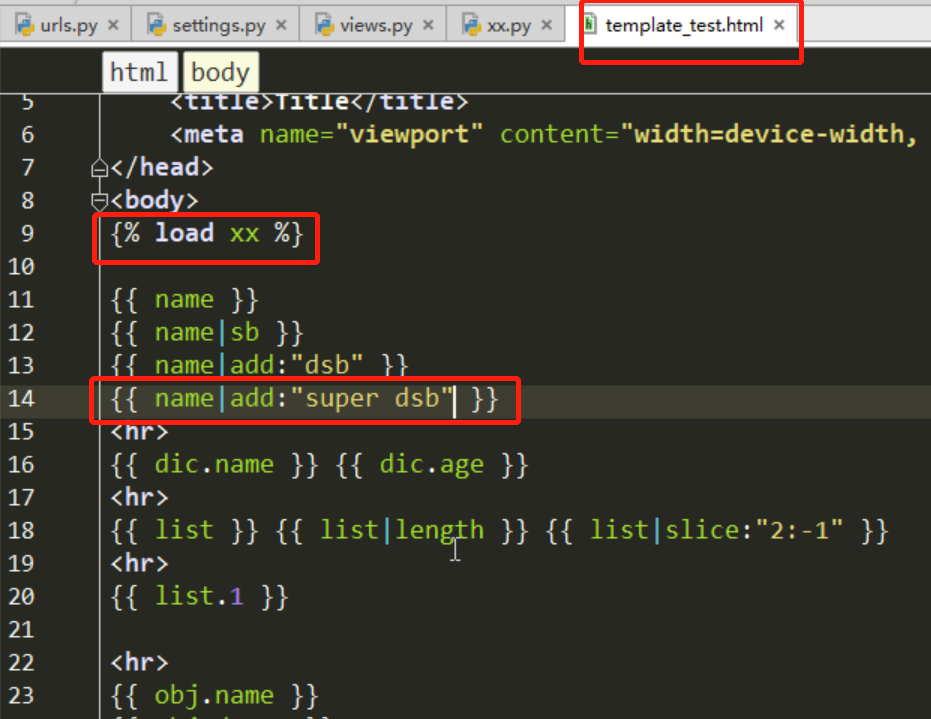
{# 先导入我们自定义filter那个文件 #}
{% load app01_filters %}
{# 使用我们自定义的filter #}
{{ somevariable|cut:"" }}
{{ d.name|addSB }}
Tags
for
<ul>
{% for user in user_list %}
<li>{{ user.name }}</li>
{% endfor %}
</ul>
for循环可用的一些参数:
| Variable | Description |
|---|---|
forloop.counter |
当前循环的索引值(从1开始) |
forloop.counter0 |
当前循环的索引值(从0开始) |
forloop.revcounter |
当前循环的倒序索引值(从1开始) |
forloop.revcounter0 |
当前循环的倒序索引值(从0开始) |
forloop.first |
当前循环是不是第一次循环(布尔值) |
forloop.last |
当前循环是不是最后一次循环(布尔值) |
forloop.parentloop |
本层循环的外层循环 |
for ... empty
<ul>
{% for user in user_list %}
<li>{{ user.name }}</li>
{% empty %}
<li>空空如也</li>
{% endfor %}
</ul>
if,elif和else
{% if user_list %}
用户人数:{{ user_list|length }}
{% elif black_list %}
黑名单数:{{ black_list|length }}
{% else %}
没有用户
{% endif %}
当然也可以只有if和else
{% if user_list|length > 5 %}
七座豪华SUV
{% else %}
黄包车
{% endif %}
一个栗子如下两图:
错误写法:

正确写法:

if语句支持 and 、or、==、>、<、!=、<=、>=、in、not in、is、is not判断。
with
定义一个中间变量
{% with total=business.employees.count %}
{{ total }} employee{{ total|pluralize }}
{% endwith %}
csrf_token
这个标签用于跨站请求伪造保护。
在页面的form表单里面写上{% csrf_token %}
注释
{# ... #}
注意事项
1. Django的模板语言不支持连续判断,即不支持以下写法:
{% if a > b > c %}
...
{% endif %}
2. Django的模板语言中属性的优先级大于方法
def xx(request):
d = {"a": 1, "b": 2, "c": 3, "items": ""}
return render(request, "xx.html", {"data": d})
如上,我们在使用render方法渲染一个页面的时候,传的字典d有一个key是items并且还有默认的 d.items() 方法,此时在模板语言中:
{{ data.items }}
默认会取d的items key的值。
母板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
{% block page-css %} {% endblock %}
</head>
<body> <h1>这是母板的标题</h1> {% block page-main %} {% endblock %}
<h1>母板底部内容</h1>
{% block page-js %} {% endblock %}
</body>
</html>
注意:我们通常会在母板中定义页面专用的CSS块和JS块,方便子页面替换。
继承母板
在子页面中在页面最上方使用下面的语法来继承母板。
{% extends 'layouts.html' %}
母版与继承
1、定义模板
其他很多页面会用到的公共部分,可提取出来放在单独的一个如 base.html文件中
2、在母版中
通过定义不同的block 等待子页面来替换对应的内容
3、在子页面中
通过 {% extends 'base.html' %}来继承已经定义好的母版
4、在子页面中
通过block来实现自定义页面内容
5、在母版中定义
子页面专用的 page-css 和 page-js 两个块
块(block)
通过在母板中使用{% block xxx %}来定义"块"。
在子页面中通过定义母板中的block名来对应替换母板中相应的内容。
{% block page-main %}
<p>世情薄</p>
<p>人情恶</p>
<p>雨送黄昏花易落</p>
{% endblock %}
组件
可以将常用的页面内容如导航条,页尾信息等组件保存在单独的文件中,然后在需要使用的地方按如下语法导入即可。
{% include 'navbar.html' %}
静态文件相关
{% load static %}
<img src="{% static "images/hi.jpg" %}" alt="Hi!" />
引用JS文件时使用:
{% load static %}
<script src="{% static "mytest.js" %}"></script>
某个文件多处被用到可以存为一个变量
{% load static %}
{% static "images/hi.jpg" as myphoto %}
<img src="{{ myphoto }}"></img>
使用get_static_prefix
% load static %}
<img src="{% get_static_prefix %}images/hi.jpg" alt="Hi!" />
或者
{% load static %}
{% get_static_prefix as STATIC_PREFIX %}
<img src="{{ STATIC_PREFIX }}images/hi.jpg" alt="Hi!" />
<img src="{{ STATIC_PREFIX }}images/hi2.jpg" alt="Hello!" />
自定义simpletag
和自定义filter类似,只不过接收更灵活的参数。
定义注册simple tag
@register.simple_tag(name="plus")
def plus(a, b, c):
return "{} + {} + {}".format(a, b, c)
使用自定义simple tag
{% load app01_demo %}
{# simple tag #}
{% plus "" "" "abc" %}
inclusion_tag
多用于返回html代码片段
示例:
templatetags/my_inclusion.py
from django import template
register = template.Library()
@register.inclusion_tag('result.html')
def show_results(n):
n = 1 if n < 1 else int(n)
data = ["第{}项".format(i) for i in range(1, n+1)]
return {"data": data}
templates/snippets/result.html
<ul>
{% for choice in data %}
<li>{{ choice }}</li>
{% endfor %}
</ul>
templates/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>inclusion_tag test</title>
</head>
<body> {% load inclusion_tag_test %} {% show_results 10 %}
</body>
</html>
再次强调:
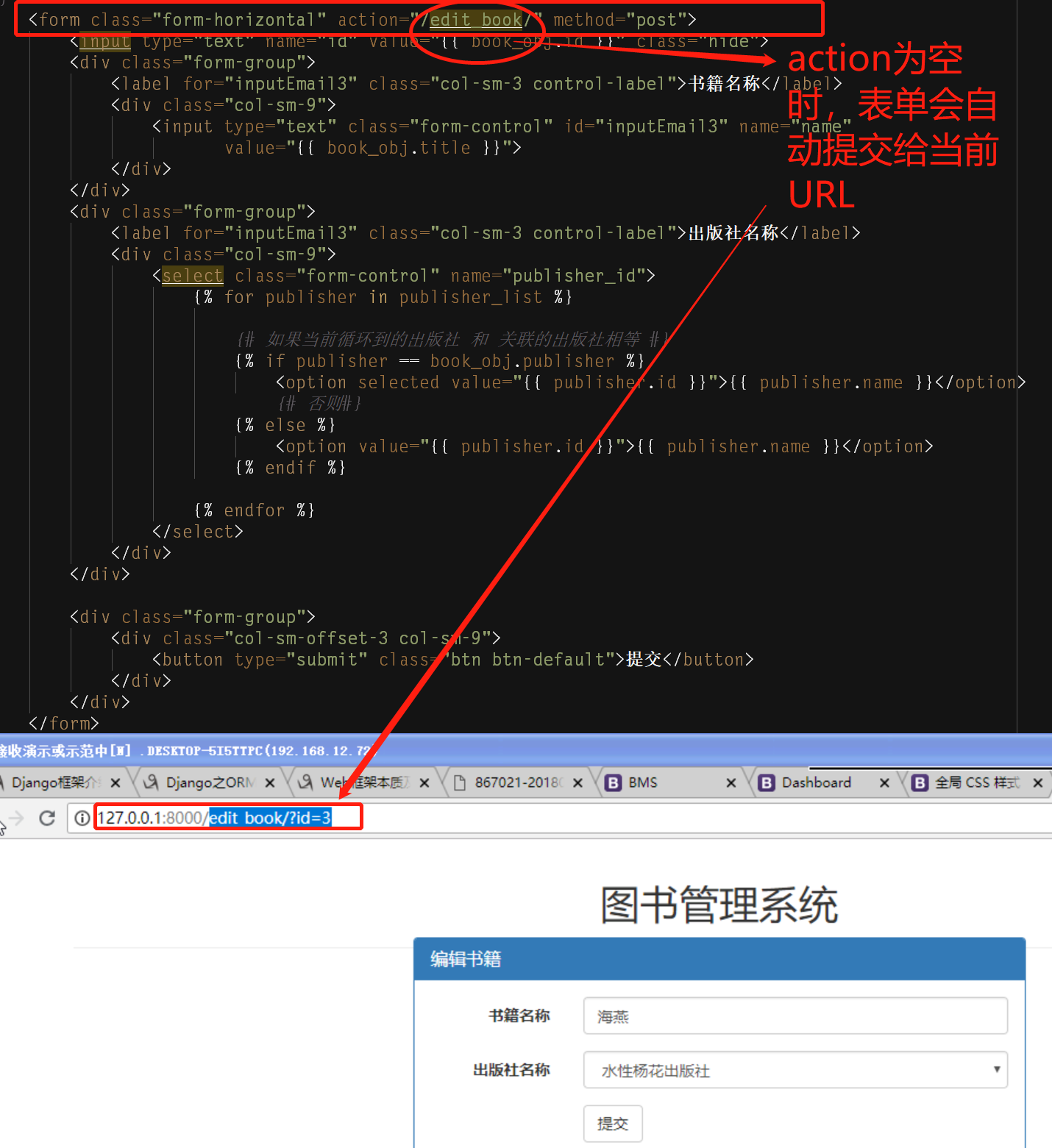
一个关于form表单POST请求提交的栗子:action为空则默认提交给当前URL
1. 模板的执行
模版的创建过程,对于模版,其实就是读取模版(其中嵌套着模版标签),然后将 Model 中获取的数据插入到模版中,最后将信息返回给用户。
# view.py def index(request):
return render(request, 'index.html', {'title':'welcome'}) # index.html <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<h1>{{ title }}</h1>
</div> </body>
</html>
2. 模板语言
模板中也有自己的语言,该语言可以实现数据展示
- {{ item }}
- {% for item in item_list %} <a>{{ item }}</a> {% endfor %}
forloop.counter
forloop.first
forloop.last - {% if ordered_warranty %} {% else %} {% endif %}
- 母板:{% block title %}{% endblock %}
子板:{% extends "base.html" %}
{% block title %}{% endblock %} - 帮助方法:
{{ item.event_start|date:"Y-m-d H:i:s"}}
{{ bio|truncatewords:"30" }}
{{ my_list|first|upper }}
{{ name|lower }}
一个错误示例:(混淆模板语言的格式)
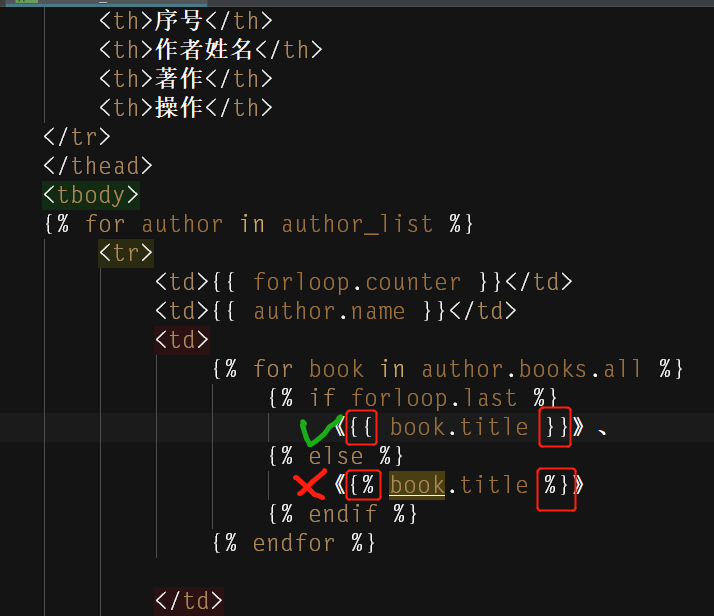
小知识点:在模板语言中字典数据类型的取值是通过dict.xxx而不是dict[xxx]
3. 自定义标签
因为在模板语言中不能够做运算等一些稍显复杂的操作,所以在Django中提供了两种自定制标签,一种是simple_tag,一种是filter。
simple_tag: 任意传递参数,但是不能用作布尔判断
filter: 最多只能传递二个参数,可以用作布尔判断
在这里着重介绍simple_tag类型,filter的实现类似
a、在app中创建templatetags模块
b、创建任意 .py 文件,如:xx.py
#!/usr/bin/env python
#coding:utf-8
from django import template
from django.utils.safestring import mark_safe
from django.template.base import resolve_variable, Node, TemplateSyntaxError register = template.Library() @register.simple_tag
def my_simple_time(v1,v2,v3):
return v1 + v2 + v3 @register.simple_tag
def my_input(id,arg):
result = "<input type='text' id='%s' class='%s' />" %(id,arg,)
return mark_safe(result)
栗子
c、在使用自定义simple_tag的html文件中导入之前创建的 xx.py 文件名
{% load xx %}
d、使用simple_tag
{% my_simple_time 1 2 3%}
{% my_input 'id_username' 'hide'%}
e、在settings中配置当前app,不然django无法找到自定义的simple_tag
# Application definition INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
# 'app01', # 老版本
'app01.apps.App01Config', # 新版本要求,推荐!
]
更多见文档:https://docs.djangoproject.com/en/1.10/ref/templates/language/
六、 Model
Django提供了一个抽象层(“Model”)来构建和管理Web应用程序的数据。
django中遵循 Code Frist 的原则,即:根据代码中定义的类来自动生成数据库表。
关系对象映射(Object Relational Mapping,简称ORM)。
Django Models的数据类型
|
AutoField |
IntegerField |
|||||||
|
BooleanField |
true/false |
|||||||
|
CharField |
maxlength,必填 |
|||||||
|
TextField |
||||||||
|
CommaSeparatedIntegerField |
maxlength,必填 |
逗号分隔 |
||||||
|
DateField |
|
|||||||
|
DateTimeField |
|
|||||||
|
EmailField |
||||||||
|
FileField |
upload_to,可选 |
object.get_myfile_url |
||||||
|
FilePathField |
|
|||||||
|
FloatField |
|
|
ImageField |
|
需要验证,即Python Imaging Library |
||||||
|
IntegerField |
||||||||
|
IPAddressField |
||||||||
|
NullBooleanField |
相当于设置了null=True的BooleanField |
|||||||
|
PhoneNumberField |
美国电话号码格式 |
|||||||
|
PositiveIntegerField |
正整数字段 |
|||||||
|
PositiveSmallIntegerField |
小的正整数字段,取决于数据库特性 |
|||||||
|
SlugField |
|
短标签,仅包含字母、数字、下划线、连字符,一般用于url |
||||||
|
SmallIntegerField |
小整数字段,依赖于数据库特性 |
|||||||
|
TimeField |
|
|||||||
|
URLField |
verify_exists(True),检查URL可用性 |
|||||||
|
USStateField |
两个字母表示的美国州名字段 |
|||||||
|
XMLField |
schema_path,必选 |
1. 创建表
a、基本结构
注意:一定要继承models.Model类
from django.db import models # Create your models here. # 出版社
class Publisher(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=64) # 书籍
class Book(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Publisher) # 外键是一个对象
1、null=True
数据库中字段是否可以为空
2、blank=True
django的 Admin 中添加数据时是否可允许空值
3、primary_key = False
主键,对AutoField设置主键后,就会代替原来的自增 id 列
4、auto_now 和 auto_now_add
auto_now 自动创建---无论添加或修改,都是当前操作的时间
auto_now_add 自动创建---永远是创建时的时间
5、choices
GENDER_CHOICE = (
(u'M', u'Male'),
(u'F', u'Female'),
)
gender = models.CharField(max_length=2,choices = GENDER_CHOICE)
6、max_length
7、default 默认值
8、verbose_name Admin中字段的显示名称
9、name|db_column 数据库中的字段名称
10、unique=True 不允许重复
11、db_index = True 数据库索引
12、editable=True 在Admin里是否可编辑
13、error_messages=None 错误提示
14、auto_created=False 自动创建
15、help_text 在Admin中提示帮助信息
16、validators=[]
17、upload-to
更多参数
1、models.AutoField 自增列 = int(11)
如果没有的话,默认会生成一个名称为 id 的列,如果要显示的自定义一个自增列,必须将给列设置为主键 primary_key=True。
2、models.CharField 字符串字段
必须 max_length 参数
3、models.BooleanField 布尔类型=tinyint(1)
不能为空,Blank=True
4、models.ComaSeparatedIntegerField 用逗号分割的数字=varchar
继承CharField,所以必须 max_lenght 参数
5、models.DateField 日期类型 date
对于参数,auto_now = True 则每次更新都会更新这个时间;auto_now_add 则只是第一次创建添加,之后的更新不再改变。
6、models.DateTimeField 日期类型 datetime
同DateField的参数
7、models.Decimal 十进制小数类型 = decimal
必须指定整数位max_digits和小数位decimal_places
8、models.EmailField 字符串类型(正则表达式邮箱) =varchar
对字符串进行正则表达式
9、models.FloatField 浮点类型 = double
10、models.IntegerField 整形
11、models.BigIntegerField 长整形
integer_field_ranges = {
'SmallIntegerField': (-32768, 32767),
'IntegerField': (-2147483648, 2147483647),
'BigIntegerField': (-9223372036854775808, 9223372036854775807),
'PositiveSmallIntegerField': (0, 32767),
'PositiveIntegerField': (0, 2147483647),
}
12、models.IPAddressField 字符串类型(ip4正则表达式)
13、models.GenericIPAddressField 字符串类型(ip4和ip6是可选的)
参数protocol可以是:both、ipv4、ipv6
验证时,会根据设置报错
14、models.NullBooleanField 允许为空的布尔类型
15、models.PositiveIntegerFiel 正Integer
16、models.PositiveSmallIntegerField 正smallInteger
17、models.SlugField 减号、下划线、字母、数字
18、models.SmallIntegerField 数字
数据库中的字段有:tinyint、smallint、int、bigint
19、models.TextField 字符串=longtext
20、models.TimeField 时间 HH:MM[:ss[.uuuuuu]]
21、models.URLField 字符串,地址正则表达式
22、models.BinaryField 二进制
23、models.ImageField 图片
24、models.FilePathField 文件
更多字段
class UserInfo(models.Model):
nid = models.AutoField(primary_key=True)
username = models.CharField(max_length=32)
class Meta:
# 数据库中生成的表名称 默认 app名称 + 下划线 + 类名
db_table = "table_name" # 联合索引
index_together = [
("pub_date", "deadline"),
] # 联合唯一索引
unique_together = (("driver", "restaurant"),) # admin中显示的表名称
verbose_name # verbose_name加s
verbose_name_plural
元信息
PS:元信息相关,更多:https://docs.djangoproject.com/en/1.10/ref/models/options/
1.触发Model中的验证和错误提示有两种方式:
a. Django Admin中的错误信息会优先根据Admiin内部的ModelForm错误信息提示,如果都成功,才来检查Model的字段并显示指定错误信息
b. 调用Model对象的 clean_fields 方法,如:
# models.py
class UserInfo(models.Model):
nid = models.AutoField(primary_key=True)
username = models.CharField(max_length=32) email = models.EmailField(error_messages={'invalid': '格式错了.'}) # views.py
def index(request):
obj = models.UserInfo(username='', email='uu')
try:
print(obj.clean_fields())
except Exception as e:
print(e)
return HttpResponse('ok') # Model的clean方法是一个钩子,可用于定制操作,如:上述的异常处理。 2.Admin中修改错误提示
# admin.py
from django.contrib import admin
from model_club import models
from django import forms class UserInfoForm(forms.ModelForm):
username = forms.CharField(error_messages={'required': '用户名不能为空.'})
email = forms.EmailField(error_messages={'invalid': '邮箱格式错误.'})
age = forms.IntegerField(initial=1, error_messages={'required': '请输入数值.', 'invalid': '年龄必须为数值.'}) class Meta:
model = models.UserInfo
# fields = ('username',)
fields = "__all__" class UserInfoAdmin(admin.ModelAdmin):
form = UserInfoForm admin.site.register(models.UserInfo, UserInfoAdmin)
拓展内容知识
常用字段
AutoField
int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
IntegerField
一个整数类型,范围在 -2147483648 to 2147483647。
CharField
字符类型,必须提供max_length参数, max_length表示字符长度。
DateField
日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
DateTimeField
日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。
字段合集(争取记忆)
AutoField(Field)
- int自增列,必须填入参数 primary_key=True BigAutoField(AutoField)
- bigint自增列,必须填入参数 primary_key=True 注:当model中如果没有自增列,则自动会创建一个列名为id的列
from django.db import models class UserInfo(models.Model):
# 自动创建一个列名为id的且为自增的整数列
username = models.CharField(max_length=32) class Group(models.Model):
# 自定义自增列
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32) SmallIntegerField(IntegerField):
- 小整数 -32768 ~ 32767 PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正小整数 0 ~ 32767
IntegerField(Field)
- 整数列(有符号的) -2147483648 ~ 2147483647 PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正整数 0 ~ 2147483647 BigIntegerField(IntegerField):
- 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807 BooleanField(Field)
- 布尔值类型 NullBooleanField(Field):
- 可以为空的布尔值 CharField(Field)
- 字符类型
- 必须提供max_length参数, max_length表示字符长度 TextField(Field)
- 文本类型 EmailField(CharField):
- 字符串类型,Django Admin以及ModelForm中提供验证机制 IPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制 GenericIPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6
- 参数:
protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6"
unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启此功能,需要protocol="both" URLField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证 URL SlugField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号) CommaSeparatedIntegerField(CharField)
- 字符串类型,格式必须为逗号分割的数字 UUIDField(Field)
- 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证 FilePathField(Field)
- 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能
- 参数:
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹 FileField(Field)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage ImageField(FileField)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串) DateTimeField(DateField)
- 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] DateField(DateTimeCheckMixin, Field)
- 日期格式 YYYY-MM-DD TimeField(DateTimeCheckMixin, Field)
- 时间格式 HH:MM[:ss[.uuuuuu]] DurationField(Field)
- 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型 FloatField(Field)
- 浮点型 DecimalField(Field)
- 10进制小数
- 参数:
max_digits,小数总长度
decimal_places,小数位长度 BinaryField(Field)
- 二进制类型
字段合集
自定义字段(了解为主)
class UnsignedIntegerField(models.IntegerField):
def db_type(self, connection):
return 'integer UNSIGNED'
自定义char字段类的示例:
from django.db import models # 自定义字段类
class FixedCharField(models.Field):
"""
自定义的固定char类型的字段类
"""
def __init__(self,max_length,*args,**kwargs):
self.max_length = max_length
super(FixedCharField,self).__init__(max_length=max_length,*args,**kwargs) def db_type(self,connection):
"""
限定生成数据库表的字段类型为char,长度为max_length指定的值
:param connection:
:return:
"""
return 'char(%s)' % self.max_length # 文件表
class FileObj(models.Model):
id = models.AutoField(primary_key=True)
fileName = models.CharField(max_length=64)
# 原始字段类
# fileSize = models.CharField(max_length=32)
# 修改为自定义字段类
fileSize = FixedCharField(max_length=16) fileMsg = models.TextField()
fileLineCount = models.CharField(max_length=32)
fileCreateTime = models.DateTimeField(auto_now_add=True)
效果如下:
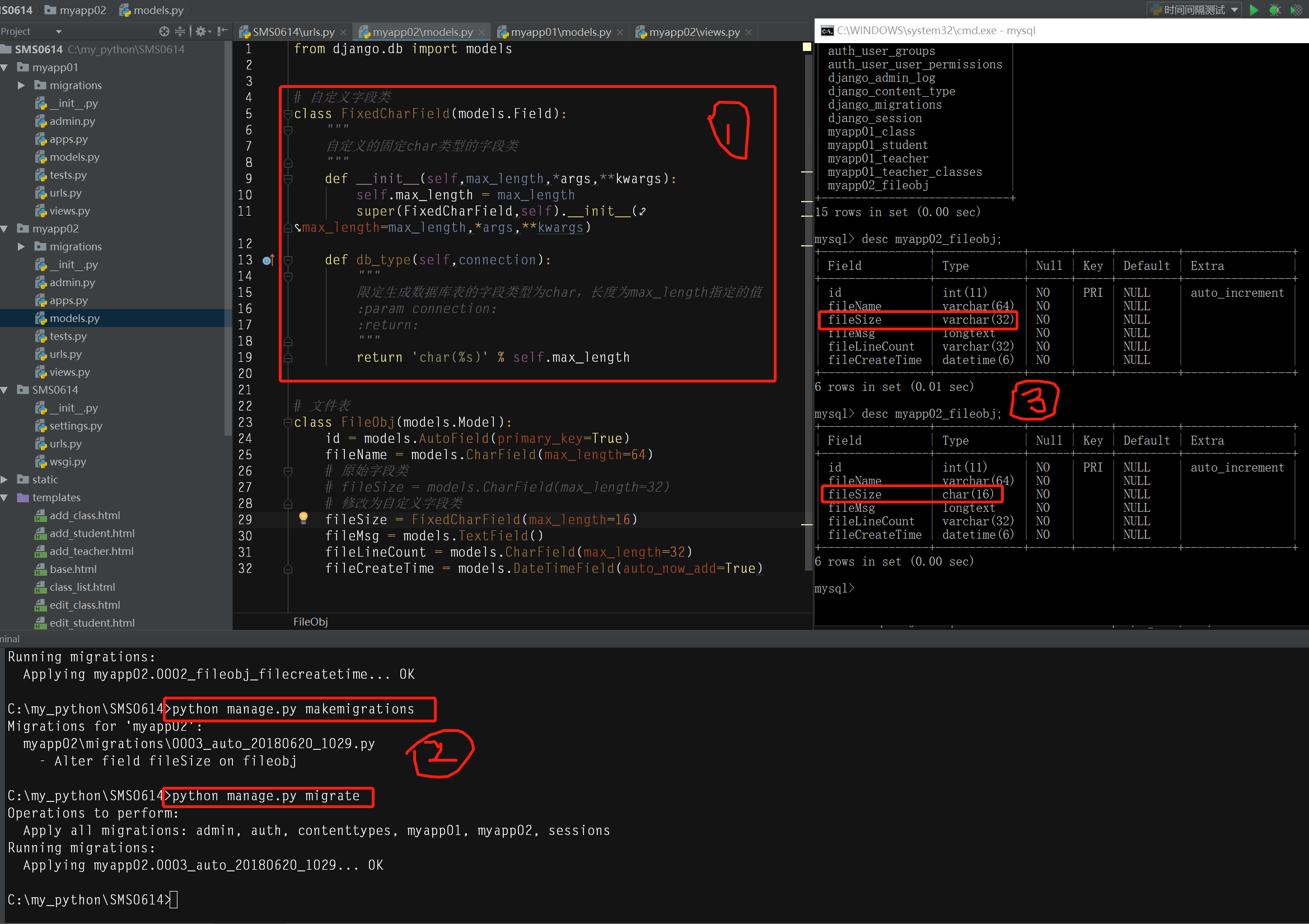
附ORM字段与数据库实际字段的对应关系
对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
ORM字段与数据库实际字段对应关系
字段参数
null
用于表示某个字段可以为空。
unique
如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index
如果db_index=True 则代表着为此字段设置索引。
default
为该字段设置默认值。
DateField和DateTimeField
auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段。
关系字段
ForeignKey
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方。
ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系。
注意:
外键关联的表的时候,
如Book表关联出版社表Publisher
1)Book表的属性设置to=Publisher,则Publisher最好放在Book表之前,否则会报错:‘Publisher’ not defined
2)或者to=‘Publisher’(解释器会用该字符串在当前文件查找反射),此时Publisher表的位置可放置Book表之后
字段参数
to
设置要关联的表
to_field
设置要关联的表的字段
related_name
反向操作时,使用的字段名,用于代替原反向查询时的'表名_set'。
例如:
class Classes(models.Model):
name = models.CharField(max_length=32) class Student(models.Model):
name = models.CharField(max_length=32)
theclass = models.ForeignKey(to="Classes")
当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
models.Classes.objects.first().student_set.all()
当我们在ForeignKey字段中添加了参数 related_name 后,
class Student(models.Model):
name = models.CharField(max_length=32)
theclass = models.ForeignKey(to="Classes", related_name="students")
当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
models.Classes.objects.first().students.all()
related_query_name
反向查询操作时,使用的连接前缀,用于替换表名。
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
models.CASCADE
删除关联数据,与之关联也删除
models.DO_NOTHING
删除关联数据,引发错误IntegrityError
models.PROTECT
删除关联数据,引发错误ProtectedError
models.SET_NULL
删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空)
models.SET_DEFAULT
删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值)
models.SET
删除关联数据,
a. 与之关联的值设置为指定值,设置:models.SET(值)
b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)
def func():
return 10 class MyModel(models.Model):
user = models.ForeignKey(
to="User",
to_field="id",
on_delete=models.SET(func)
)
db_constraint
是否在数据库中创建外键约束,默认为True。
OneToOneField
一对一字段。
通常一对一字段用来扩展已有字段。
注意:
class User(models.Model):
name = models.CharField(max_length=16)
gender_choice = ((1, "男"), (2, "女"), (3, "保密"))
gender = models.SmallIntegerField(choices=gender_choice, default=3)
detail = models.OneToOneField(to='UserInfo') class UserInfo(models.Model):
phone = models.CharField(max_length=11, unique=True, db_index=True)
addr = models.TextField()
hunfou = models.BooleanField() 一对一字段,(应用场景:第三方网站关联账户,获取账户的头像,昵称,个性签名等)
1、把控关联账户的信息,避免不必要的信息泄露
2、账户信息分开存,将经常操作的信息放一个表,不经常操作的信息放另一个表,有利于信息检索的效率
3、方便扩展已有字段
字段参数
to
设置要关联的表。
to_field
设置要关联的字段。
on_delete
同ForeignKey字段。
ManyToManyField
用于表示多对多的关联关系。在数据库中通过第三张表来建立关联关系。
字段参数
to
设置要关联的表
related_name
同ForeignKey字段。
related_query_name
同ForeignKey字段。
symmetrical
仅用于多对多自关联时,指定内部是否创建反向操作的字段。默认为True。
举个例子:
class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self")
此时,person对象就没有person_set属性。
class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self", symmetrical=False)
此时,person对象现在就可以使用person_set属性进行反向查询。
through
在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。
但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过through来指定第三张表的表名。
through_fields
设置关联的字段。
db_table
默认创建第三张表时,数据库中表的名称。
多对多关联关系的三种方式
方式一:自行创建第三张表
models1.py
from django.db import models # Create your models here. class Book(models.Model):
title = models.CharField(max_length=32) class Author(models.Model):
name = models.CharField(max_length=32) # 自己创建第三张表,分别通过外键关联书和作者
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book") class Meta:
unique_together = ("author", "book")
orm_demo1.py操作示例:
import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "orm_demo.settings")
import django
django.setup() # ORM查询操作
from app02 import models first_book = models.Book.objects.first() # 找到第一本书
# 查询
# ret = models.Book.objects.first().author2book_set.all().values("author__name")
# print(ret) ret = models.Book.objects.filter(id=1).values("author2book__author__name")
print(ret) # first_book.author.set()
models.Author2Book.objects.create(book=first_book, author_id=1)
# 清空
models.Author2Book.objects.filter(book=first_book).delete()
自行创建第三张表的orm操作示例
方式二:设置ManyTomanyField并指定自行创建的第三张表
models2.py
from django.db import models # Create your models here.
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名") # 自己创建第三张表,并通过ManyToManyField指定关联
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(
to="Book",
through="Author2Book",
through_fields=("author", "book")
)
# through_fields接受一个2元组('field1','field2'):
# 其中field1是定义ManyToManyField的模型外键的名(author),field2是关联目标模型(book)的外键名。 class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book") class Meta:
unique_together = ("author", "book")
orm_demo2.py操作示例:
import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "orm_demo.settings")
import django
django.setup() # ORM查询操作
from app03 import models first_book = models.Book.objects.first() # 找到第一本书
# 查询
# ret = models.Book.objects.first().author2book_set.all().values("author__name")
# print(ret) # ret = models.Book.objects.filter(id=1).values("author__name")
# print(ret) # 给某人的小故事 加一个作者 id是3 # models.Author2Book.objects.create(book=first_book, author_id=3) # 删除
models.Author2Book.objects.filter(book=first_book, author_id=3).delete()
通过ManyToManyField创建并关联自己创建的第三张表的操作示例
方式三:通过ManyToManyField自动创建第三张表
models3.py
from django.db import models # Create your models here. # 书
class Book(models.Model):
title = models.CharField(max_length=32)
publish_date = models.DateField(auto_now_add=True)
price = models.DecimalField(max_digits=5, decimal_places=2)
memo = models.TextField(null=True)
# 创建外键,关联publish
# publisher = models.ForeignKey(to="Publisher", related_name="books", related_query_name="zhangzhao")
publisher = models.ForeignKey(to="Publisher", related_name="books")
# 创建多对多关联author
author = models.ManyToManyField(to="Author") def __str__(self):
return self.title # 作者
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
phone = models.CharField(max_length=11)
detail = models.OneToOneField(to="AuthorDetail") def __str__(self):
return self.name # 作者详情
class AuthorDetail(models.Model):
addr = models.CharField(max_length=64)
email = models.EmailField()
orm_demo3.py操作示例
# 连表查询
book_obj = models.Book.objects.first()
# 基于对象查找
ret = book_obj.publisher.name
print(ret)
# 基于双下划线的跨表查询
ret = models.Book.objects.values("publisher__name", "publisher__city").first()
print(ret) # 正向查找
# 查找书名是“番茄物语”的书的出版社
# 1. 基于对象的查找方式
ret = models.Book.objects.get(title="番茄物语").publisher
print(ret)
# 查找书名是“番茄物语”的书的出版社所在的城市
ret = models.Book.objects.get(title="番茄物语").publisher.city
print(ret)
# 2. 基于双下划线的夸表查询
ret = models.Book.objects.filter(title="番茄物语").values("publisher__city")
print(ret) # 外键的反向查找
# 1. 基于对象的查找方式
publisher_obj = models.Publisher.objects.first()
ret = publisher_obj.book_set.all()
print(ret)
# 如果设置了 related_name="books"
publisher_obj = models.Publisher.objects.first()
ret = publisher_obj.books.all()
print(ret) # 基于双下划线的跨表查询
ret = models.Publisher.objects.filter(id=1).values("books__title")
print(ret) # 如果设置了 related_query_name="zhangzhao"
ret = models.Publisher.objects.filter(id=1).values("zhangzhao__title")
print(ret) # 多对多操作
# 1. create
# 做了两件事情:
# 1. 创建了一个新的作者,2. 将新创建的作者和第一本书做关联
ret = models.Book.objects.first().author.create(
name="张曌",
age=16,
phone="",
detail_id=4
)
ret = models.Book.objects.first().author.all().values("id")
print(ret) # 2. set
models.Book.objects.first().author.set([2,3])
ret = models.Book.objects.first().author.all().values("id")
print(ret) # 3. add
models.Book.objects.first().author.add(1) ret = models.Book.objects.first().author.all().values("id")
print(ret) # 4. remove
models.Book.objects.first().author.remove(3) ret = models.Book.objects.first().author.all().values("id")
print(ret) # 5.clear
models.Book.objects.first().author.clear() ret = models.Book.objects.first().author.all().values("id")
print(ret) # 6. all
ret = models.Book.objects.first().author.all()
print(ret) # 聚合
# 查询所有书的总价格
from django.db.models import Avg, Sum, Max, Min, Count ret = models.Book.objects.aggregate(total_price=Sum("price"))
print(ret) ret = models.Book.objects.aggregate(avg_price=Avg("price"), max_price=Max("price"), min_price=Min("price"))
print(ret) # 求每一本书的作者个数
ret = models.Book.objects.annotate(c=Count("author")).values("title", "c")
print(ret) # 统计出每个出版社买的最便宜的书的价格
ret = models.Publisher.objects.annotate(min_price=Min("books__price")).values("name", "min_price")
print(ret) # 统计不止一个作者的图书 (书作者的数量大于1)
ret = models.Book.objects.annotate(c=Count("author")).filter(c__gt=1)
print(ret) # 按照书作者的数量做排序
ret = models.Book.objects.annotate(c=Count("author")).order_by("c")
print(ret) # 查询各个作者出的书的总价格
ret = models.Author.objects.annotate(sum_price=Sum("book__price")).values("name", "sum_price")
print(ret)
通过ManyToManyField自行创建的第三张表
注意:
当我们需要在第三张关系表中存储额外的字段时,就要使用第三种方式。
但是当我们使用第三种方式创建多对多关联关系时,就无法使用set、add、remove、clear方法来管理多对多的关系了,需要通过第三张表的model来管理多对多关系。
补充:
多对多方式的三种实现方法:
1、ORM 自动创建第三张表
优点:表的结构更清晰,并提供一套更简易的操作方法(.all和.set方法)
2、手动创建第三张表
优点:
1)扩展额外的字段关联
2)关联对象有对应的类
缺点:
体现不出来两个表的关系
操作不方便
3、通过through字段方法
优点:
集结1和2 的优点(但仅仅只有1方法中的.all检索方法)
当我们使用多对多的中间模型之后,add(),remove(),create()这些方法都会被禁用,所以在创建这种类型的关系的时候唯一的方法就是通过创建中间模型的实例
元信息
ORM对应的类里面包含另一个Meta类,而Meta类封装了一些数据库的信息。主要字段如下:
db_table
ORM在数据库中的表名默认是 app_类名,可以通过db_table可以重写表名。
index_together
联合索引。
unique_together
联合唯一索引。
ordering
指定默认按什么字段排序。
只有设置了该属性,我们查询到的结果才可以被reverse()。
b、连表结构
- 一对多:models.ForeignKey(其他表)
- 多对多:models.ManyToManyField(其他表)
- 一对一:models.OneToOneField(其他表)
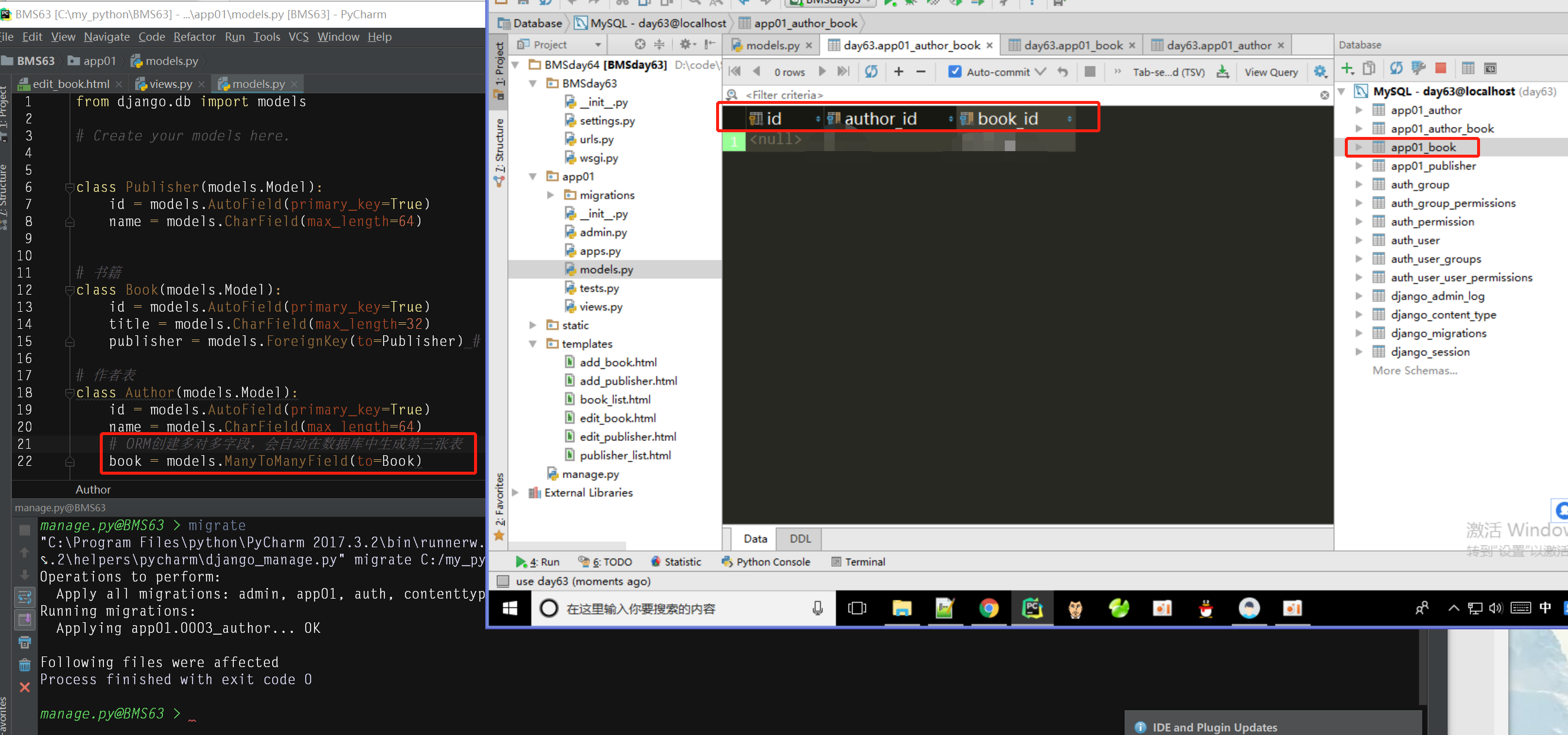
一个多对多例子:作者表是多对多关系,建模时会自动生成第三张表,如下图
另一个多对多views中的栗子:
取值.getlist(),
设值.set()
def edit_author(request):
if request.method == "POST":
edit_author_id = request.POST.get("author_id")
new_author_name = request.POST.get("author_name")
# 如果提交过来的数据是多个值(多选select/多选checkbox),用.getlist()
new_books_id = request.POST.getlist("books_id")
# new_books_id = request.POST.get("books_id")
# print(request.POST) # <QueryDict: {'id': ['4'], 'name': ['陈杰二狗子'], 'book_id': ['1', '4', '6']}>
edit_author_obj = models.Author.objects.get(id=edit_author_id)
edit_author_obj.name = new_author_name
edit_author_obj.save()
# ORM中的set方法会用new_books_id去第三张表查找数据并处理
edit_author_obj.books.set(new_books_id)
return redirect('/author_list/') edit_author_id = request.GET.get("id")
edit_author = models.Author.objects.get(id=edit_author_id)
book_list = models.Book.objects.all()
return render(
request,
"edit_author.html",
{"author":edit_author,"book_list":book_list}
)
对应的html的模板语言,便利多个值对象,应用此格式,xx.all:
<select multiple class="form-control" name="new_class_ids">
{% for class in class_list %}
{% if class in edit_teacher_obj.classes.all %}
<option selected value="{{ class.id }}">{{ class.className }}</option>
{% else %}
<option value="{{ class.id }}">{{ class.className }}</option>
{% endif %}
{% endfor %}
</select>
应用场景: 一对多:当一张表中创建一行数据时,有一个单选的下拉框(可以被重复选择)
例如:创建用户信息时候,需要选择一个用户类型【普通用户】【金牌用户】【铂金用户】等。
多对多:在某表中创建一行数据是,有一个可以多选的下拉框
例如:创建用户信息,需要为用户指定多个爱好
一对一:在某表中创建一行数据时,有一个单选的下拉框(下拉框中的内容被用过一次就消失了
例如:原有含10列数据的一张表保存相关信息,经过一段时间之后,10列无法满足需求,需要为原来的表再添加5列数据
一般操作
必知必会13条
<1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 <5> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列 <6> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <7> order_by(*field): 对查询结果排序(-*field,逆序) <8> reverse(): 对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用(在model类的Meta中指定ordering或调用order_by()方法)。 <9> distinct(): 从返回结果中剔除重复纪录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果。此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重。) <10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <11> first(): 返回第一条记录 <12> last(): 返回最后一条记录 <13> exists(): 如果QuerySet包含数据,就返回True,否则返回False
上述方法示例代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/06/20 11:57
# @Author : MJay_Lee
# @File : orm_demo.py.py
# @Contact : limengjiejj@hotmail.com import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "SMS0614.settings")
import django
django.setup() from myapp02 import models
"""
数据库中fileobj表内容: 25 文件1.rar 1061 ['08_常用内置模块和方法1.py,count:----20'] 20 2018-06-20 06:19:31.255807
26 文件2.zip 1194 ['08_常用内置模块和方法2.py,count:----20'] 20 2017-06-20 06:19:38.057557
27 文件3.zip 1194 ['08_常用内置模块和方法3.py,count:----20'] 20 2016-06-20 06:19:45.082578 print(type(FileObj.objects.get(id=27).fileCreateTime)) # <class 'datetime.datetime'>
print(FileObj.objects.get(id=27).fileCreateTime) # 2016-06-20 06:19:45.082578+00:00 """
ret1 = models.FileObj.objects.all() # QuerySet类型,对象,列表
print(ret1)
# <QuerySet [<FileObj: 08_常用内置模块和方法.zip>, <FileObj: 08_常用内置模块和方法.rar>]> ret2 = models.FileObj.objects.filter(fileName="文件1.rar") # QuerySet类型,对象,列表
print(ret2)
# <QuerySet [<FileObj: 文件1.rar>]> ret3 = models.FileObj.objects.filter(id=27) # QuerySet类型,对象,列表
print(ret3)
# <QuerySet [<FileObj: 文件3.zip>]> # id值大于25
ret4 = models.FileObj.objects.filter(id__gt=25) # QuerySet类型,对象,列表
print(ret4)
# <QuerySet [<FileObj: 文件2.zip>, <FileObj: 文件3.zip>]> # id值小于27,大于25
ret5 = models.FileObj.objects.filter(id__gt=25,id__lt=27) # QuerySet类型,对象,列表
print(ret5)
# <QuerySet [<FileObj: 文件2.zip>]> # 创建时间为2018年的文件
ret6 = models.FileObj.objects.filter(fileCreateTime__year=2018) # QuerySet类型,对象,列表
print(ret6)
# < QuerySet[ < FileObj: 文件1.rar >] > # 创建时间大于2016年的文件
ret7 = models.FileObj.objects.filter(fileCreateTime__year__gt=2016) # QuerySet类型,对象,列表
print(ret7)
# <QuerySet [<FileObj: 文件1.rar>, <FileObj: 文件2.zip>]> # 文件名包含”文件“
# 当检索内容为英文,且不区分大小写的时候,用"__icontains"
ret8 = models.FileObj.objects.filter(fileName__contains="文件") # QuerySet类型,对象,列表
print(ret8)
# <QuerySet [<FileObj: 文件1.rar>, <FileObj: 文件2.zip>, <FileObj: 文件3.zip>]> # 文件名包含”文件“,且创建时间大于2017年
# 当多条件检索时,用逗号分隔条件
ret9 = models.FileObj.objects.filter(fileName__contains="文件",fileCreateTime__year__gt=2017) # QuerySet类型,对象,列表
print(ret9) # 区别.filter()和.get()
# .filter()找不到对象时,返回空列表
ret10 = models.FileObj.objects.filter(id=100)
print(ret10) # <QuerySet []>
# .get()找不到对象时,报错
# ret11 = models.FileObj.objects.get(id=100)
# print(ret11) # myapp02.models.DoesNotExist: FileObj matching query does not exist. # 将满足条件的去掉,留下不满足条件的
ret12 = models.FileObj.objects.exclude(id__in=[25,27]) # QuerySet类型,对象,列表
print(ret12)
# <QuerySet [<FileObj: 文件2.zip>]> # values 取字段的值
ret13 = models.FileObj.objects.exclude(id__in=[25, 27]).values("id","fileName")
print(ret13) # QuerySet类型 --> 字段及字段值的字典的列表
# <QuerySet [{'id': 26, 'fileName': '文件2.zip'}]> ret14 = models.FileObj.objects.exclude(id__in=[25,27]).values_list("id","fileName")
print(ret14) # QuerySet类型 --> 字段值的元组的列表
# <QuerySet [(26, '文件2.zip')]> # 按字段排序,默认为升序,ASC
ret15 = models.FileObj.objects.order_by("fileCreateTime") # QuerySet类型
print(ret15) # 时间则按时间戳的值大小排序
# <QuerySet [<FileObj: 文件3.zip>, <FileObj: 文件2.zip>, <FileObj: 文件1.rar>]> # 按字段排序,字段前加负号则逆序,DESC
ret16 = models.FileObj.objects.order_by("-fileCreateTime") # QuerySet类型
print(ret16) # 时间则按时间戳的值大小排序
# <QuerySet [<FileObj: 文件1.rar>, <FileObj: 文件2.zip>, <FileObj: 文件3.zip>]> # 按字段排序,必须先使用order_by()方法后才能使用.reverse()方法,实现逆序,DESC
ret17 = models.FileObj.objects.order_by("-fileCreateTime").reverse() # QuerySet类型
print(ret17)
# <QuerySet [<FileObj: 文件3.zip>, <FileObj: 文件2.zip>, <FileObj: 文件1.rar>]> # *去重,连表查询
ret18 = models.FileObj.objects.order_by("-fileCreateTime").reverse().values_list("fileCreator__name").distinct()
print(ret18)
# <QuerySet [('李梦杰',), ('程灵燕',), ('李梦杰',)]> # count 计数
ret19 = models.FileObj.objects.all().count() # 数字 --> 结果集中数据的个数
print(ret19)
# # first()和last()
ret20 = models.FileObj.objects.all().first() # 对象 --> 结果集中的第一个数据
print(ret20)
# 文件1.rar # 判断结果集中是否有数据
ret21 = models.FileObj.objects.filter(id=100).exists() # 布尔值 --> 结果集中是否有数据
print(ret21)
# False
13种常用方法示例
双下划线释义:
__exact 精确等于 like 'aaa'
__iexact 精确等于 忽略大小写 ilike 'aaa'
__contains 包含 like '%aaa%'
__icontains 包含 忽略大小写 ilike '%aaa%',但是对于sqlite来说,contains的作用效果等同于icontains。
__gt 大于
__gte 大于等于
__lt 小于
__lte 小于等于
__in 存在于一个list范围内
__startswith 以...开头
__istartswith 以...开头 忽略大小写
__endswith 以...结尾
__iendswith 以...结尾,忽略大小写
__range 在...范围内
__year 日期字段的年份
__month 日期字段的月份
__day 日期字段的日
__isnull=True/False
__isnull=True 与 __exact=None的区别
返回QuerySet对象的方法有
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元祖序列
返回具体对象的
get()
first()
last()
返回布尔值的方法有:
exists()
返回数字的方法有
count()
单表查询之神奇的双下划线
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") # 获取name字段包含"ven"的
models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 3]) # id范围是1到3的,等价于SQL的bettwen and 类似的还有:startswith,istartswith, endswith, iendswith date字段还可以:
models.Class.objects.filter(first_day__year=2017)
ForeignKey操作
数据库JOIN方法回顾:
数据库原生SQL知识补充(>>>链表操作传送门<<<):https://www.cnblogs.com/limengjie0104/p/9209810.html
正向查找
对象查找(跨表)
语法:
对象.关联字段.字段
示例:
book_obj = models.Book.objects.first() # 第一本书对象
print(book_obj.publisher) # 得到这本书关联的出版社对象
print(book_obj.publisher.name) # 得到出版社对象的名称
原始SQL语句查看:

字段查找(跨表)
语法:
关联字段__字段
示例:
print(models.Book.objects.values_list("publisher__name"))
原始SQL语句查询:

反向操作
对象查找(相当于SQL的子查询)
语法:
obj.表名_set
示例:
publisher_obj = models.Publisher.objects.first() # 找到第一个出版社对象
books = publisher_obj.book_set.all() # 找到第一个出版社出版的所有书
titles = books.values_list("title") # 找到第一个出版社出版的所有书的书名
字段查找
语法:
表名__字段
示例:
titles = models.Publisher.objects.values_list("book__title")
正向,反向示例:
# 联表查询
#
# 正向查询
# 查看id为4的书籍的出版社,及该出版社的地址
# 1、基于对象
book_obj = models.Book.objects.get(id=4)
ret = book_obj.publisher.city
print(ret)
#
ret = models.Book.objects.get(id=4).publisher
print(type(ret),ret) # <class 'app01.models.Publisher'> 上海出版社
#
ret = models.Book.objects.get(id=4).publisher.city
print(ret)
#
# 2、基于双下划线的跨表查询
ret = models.Book.objects.filter(id=4).values("publisher__city")
print(ret) # <QuerySet [{'publisher__city': '上海浦东'}]> # 反向查询
# 查看id为4的书籍的出版社出版的所有书籍
# 1、基于对象的查找方式
publisher_obj = models.Book.objects.get(id=4).publisher
# 默认使用反向查询的'表名_set'
ret = publisher_obj.book_set.all()
print(ret)
# 若在Book中publisher字段属性中设置了 related_name="books"
ret = publisher_obj.books.all()
print(ret)
#
# 2、基于双下划线的字段查找
# 默认使用反向查询的'表名__字段'
ret = models.Publisher.objects.filter(id=1).values("book__title")
# 若设置了related_query_name="shuji"
ret = models.Publisher.objects.filter(id=1).values("shuji__title")
print(ret)
截图:
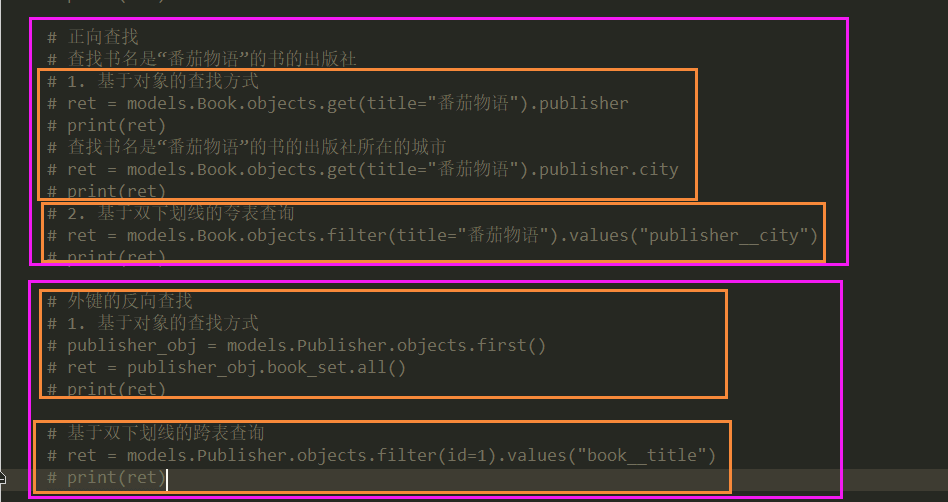
ManyToManyField
class RelatedManager
"关联管理器"是在一对多或者多对多的关联上下文中使用的管理器。
ManyToManyField()多设置在正向查询的业务逻辑高的那张表中
它存在于下面两种情况:
- 外键关系的反向查询
- 多对多关联关系
简单来说就是当 点后面的对象 可能存在多个的时候就可以使用以下的方法。
方法
create()
创建一个新的对象,保存对象,并将它添加到关联对象集之中,返回新创建的对象。
>>> import datetime
>>> models.Author.objects.first().book_set.create(title="番茄物语", publish_date=datetime.date.today())
add()
把指定的model对象添加到关联对象集中。
添加对象
>>> author_objs = models.Author.objects.filter(id__lt=3)
>>> models.Book.objects.first().authors.add(*author_objs)
添加id
>>> models.Book.objects.first().authors.add(*[1, 2])
set()
更新model对象的关联对象。
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.set([2, 3])
remove()
从关联对象集中移除执行的model对象
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.remove(3)
clear()
从关联对象集中移除一切对象。
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.clear()
注意:
对于ForeignKey对象,clear()和remove()方法仅在null=True时存在。
举个例子:
ForeignKey字段没设置null=True时,
class Book(models.Model):
title = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Publisher)
没有clear()和remove()方法:
>>> models.Publisher.objects.first().book_set.clear()
Traceback (most recent call last):
File "<input>", line 1, in <module>
AttributeError: 'RelatedManager' object has no attribute 'clear'
当ForeignKey字段设置null=True时,
class Book(models.Model):
name = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Class, null=True)
此时就有clear()和remove()方法:
>>> models.Publisher.objects.first().book_set.clear()
补充:
blank = True 和 null = True 的区别: blank只是在填写表单的时候可以为空,而在数据库上存储的是一个空字符串;
null是在数据库上表现NULL,而不是一个空字符串; *需要注意的是: 日期型(DateField、TimeField、DateTimeField)和数字型(IntegerField、DecimalField、FloatField)不能接受空字符串
如要想要在填写表单的时候这两种类型的字段为空的话
则需要同时设置null=True、blank=True; 另外,设置完null=True后需要重新更新一下数据库。
注意:
- 对于所有类型的关联字段,add()、create()、remove()和clear(),set()都会马上更新数据库。换句话说,在关联的任何一端,都不需要再调用save()方法。
聚合查询和分组查询
聚合
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。
用到的内置函数:
from django.db.models import Avg, Sum, Max, Min, Count
示例:
>>> from django.db.models import Avg, Sum, Max, Min, Count
>>> models.Book.objects.all().aggregate(Avg("price"))
{'price__avg': 13.233333}
如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
>>> models.Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 13.233333}
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
>>> models.Book.objects.all().aggregate(Avg("price"), Max("price"), Min("price"))
{'price__avg': 13.233333, 'price__max': Decimal('19.90'), 'price__min': Decimal('9.90')}
分组
我们在这里先复习一下SQL语句的分组。
假设现在有一张公司职员表:

我们使用原生SQL语句,按照部分分组求平均工资:
select dept,AVG(salary) from employee group by dept;
ORM查询:
from django.db.models import Avg
Employee.objects.values("dept").annotate(avg=Avg("salary").values(dept, "avg")
连表查询的分组:

SQL查询:
select dept.name,AVG(salary) from employee inner join dept on (employee.dept_id=dept.id) group by dept_id;
ORM查询:
from django.db.models import Avg
models.Dept.objects.annotate(avg=Avg("employee__salary")).values("name", "avg")
更多示例:
示例1:统计每一本书的作者个数
>>> book_list = models.Book.objects.all().annotate(author_num=Count("author"))
>>> for obj in book_list:
... print(obj.author_num)
...
2
1
1
示例2:统计出每个出版社买的最便宜的书的价格
>>> publisher_list = models.Publisher.objects.annotate(min_price=Min("book__price"))
>>> for obj in publisher_list:
... print(obj.min_price)
...
9.90
19.90
方法二:
>>> models.Book.objects.values("publisher__name").annotate(min_price=Min("price"))
<QuerySet [{'publisher__name': '沙河出版社', 'min_price': Decimal('9.90')}, {'publisher__name': '人民出版社', 'min_price': Decimal('19.90')}]>
示例3:统计不止一个作者的图书
>>> models.Book.objects.annotate(author_num=Count("author")).filter(author_num__gt=1)
<QuerySet [<Book: 番茄物语>]>
示例4:根据一本图书作者数量的多少对查询集 QuerySet进行排序
>>> models.Book.objects.annotate(author_num=Count("author")).order_by("author_num")
<QuerySet [<Book: 香蕉物语>, <Book: 橘子物语>, <Book: 番茄物语>]>
示例5:查询各个作者出的书的总价格
>>> models.Author.objects.annotate(sum_price=Sum("book__price")).values("name", "sum_price")
<QuerySet [{'name': '小精灵', 'sum_price': Decimal('9.90')}, {'name': '小仙女', 'sum_price': Decimal('29.80')}, {'name': '小魔女', 'sum_price': Decimal('9.90')}]>
聚合、分组查询示例补充
聚合、分组orm操作示例:
# 聚合和分组
from django.db.models import Avg,Sum,Max,Min,Count
# 查询所有书的总价格
ret = models.Book.objects.aggregate(
zongjia=Sum("price"),
pingjunjiage=Avg("price")
)
print(ret)
# {'zongjia': Decimal('1000.00'), 'pingjunjiage': 250.0}
# 求每一本书的作者个数
# 思路:
# 1)先分组书;2)再统计此组书的作者个数
ret = models.Book.objects.annotate(autor_count=Count("author")).values("title","autor_count")
print(ret)
# 统计出每个出版社出售的最便宜的书的价格
ret = models.Publisher.objects.annotate(min_price=Min("shuji__price")).values("name","min_price")
print(ret)
# 统计不止一个作者的图书
# 思路:书籍作者的数量大于1
ret = models.Book.objects.annotate(author_count=Count("author")).filter(author_count__gt=1).values("title","author_count")
print(ret)
# 按照书捉着的数量做排序(逆序)
# 默认按照升序
ret = models.Book.objects.annotate(author_count=Count("author")).order_by("author_count").reverse().values("title","author_count")
print(ret)
# 查询各个作者出书的总价格,逆序
# 错误写法
ret = models.Book.objects.annotate(total_price=Sum("price")).filter("author").values("author__name","total_price")
print(ret)
# 正确写法
# 思路:
# 先分组作者的书,在统计书的价格
ret = models.Author.objects.annotate(total_price=Sum("book__price")).order_by("-total_price").values("name","total_price")
print(ret)
聚合、分组orm示例
上述操作对应的原生SQL示例:
# 求每一本书的作者个数
# 思路:
# 1)先分组书;2)再统计此组书的作者个数
SELECT "app01_book"."title", COUNT("app01_book_author"."author_id") AS "autor_count"
FROM "app01_book" LEFT OUTER JOIN "app01_book_author"
ON ("app01_book"."id" = "app01_book_author"."book_id")
GROUP BY "app01_book"."id", "app01_book"."title", "app01_book"."publish_date", "app01_book"."price", "app01_book"."publisher_id" LIMIT 21 # 统计出每个出版社出售的最便宜的书的价格
SELECT "app01_publisher"."name", CAST(MIN("app01_book"."price") AS NUMERIC) AS "min_price"
FROM "app01_publisher" LEFT OUTER JOIN "app01_book"
ON ("app01_publisher"."id" = "app01_book"."publisher_id")
GROUP BY "app01_publisher"."id", "app01_publisher"."name", "app01_publisher"."city" LIMIT 21; # 统计不止一个作者的图书
SELECT "app01_book"."title", COUNT("app01_book_author"."author_id") AS "author_count"
FROM "app01_book" LEFT OUTER JOIN "app01_book_author"
ON ("app01_book"."id" = "app01_book_author"."book_id")
GROUP BY "app01_book"."id", "app01_book"."title", "app01_book"."publish_date", "app01_book"."price", "app01_book"."publisher_id"
HAVING COUNT("app01_book_author"."author_id") > 1 LIMIT 21; # 按照书捉着的数量做排序(逆序)
SELECT "app01_book"."title", COUNT("app01_book_author"."author_id") AS "author_count"
FROM "app01_book" LEFT OUTER JOIN "app01_book_author"
ON ("app01_book"."id" = "app01_book_author"."book_id")
GROUP BY "app01_book"."id", "app01_book"."title", "app01_book"."publish_date", "app01_book"."price", "app01_book"."publisher_id"
ORDER BY "author_count" DESC LIMIT 21 # 查询各个作者出书的总价格,逆序
SELECT "app01_author"."name", CAST(SUM("app01_book"."price") AS NUMERIC) AS "total_price"
FROM "app01_author" LEFT OUTER JOIN "app01_book_author"
ON ("app01_author"."id" = "app01_book_author"."author_id") LEFT OUTER JOIN "app01_book"
ON ("app01_book_author"."book_id" = "app01_book"."id")
GROUP BY "app01_author"."id", "app01_author"."name", "app01_author"."age", "app01_author"."phone", "app01_author"."detail_id"
ORDER BY "total_price" DESC LIMIT 21;
聚合、分组原生SQL示例
F查询和Q查询
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
示例1:
查询评论数大于收藏数的书籍
from django.db.models import F
models.Book.objects.filter(commnet_num__gt=F('keep_num'))
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
models.Book.objects.filter(commnet_num__lt=F('keep_num')*2)
修改操作也可以使用F函数,比如将每一本书的价格提高30元
models.Book.objects.all().update(price=F("price")+30)
引申:
如果要修改char字段咋办?
如:把所有书名后面加上(第一版)
>>> from django.db.models.functions import Concat
>>> from django.db.models import Value
>>> models.Book.objects.all().update(title=Concat(F("title"), Value("("), Value("第一版"), Value(")")))
SQL,update方法补充:
update修改字段 和 对象.属性 修改字段的区别:
、update 修改字段(推荐使用)
只会更新指定修改的字段 、对象.属性 修改字段(效率低)
会更新所有字段
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR语句),你可以使用Q对象。
示例1:
查询作者名是小仙女或小魔女的
models.Book.objects.filter(Q(authors__name="小仙女")|Q(authors__name="小魔女"))
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询。
示例:查询作者名字是小仙女并且不是2018年出版的书的书名。
>>> models.Book.objects.filter(Q(author__name="小仙女") & ~Q(publish_date__year=2018)).values_list("title")
<QuerySet [('番茄物语',)]>
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。
例如:查询出版年份是2017或2018,书名中带物语的所有书。
>>> models.Book.objects.filter(Q(publish_date__year=2018) | Q(publish_date__year=2017), title__icontains="物语")
<QuerySet [<Book: 番茄物语>, <Book: 香蕉物语>, <Book: 橘子物语>]>
一个面试题,练习:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/06/20 17:54
# @Author : MJay_Lee
# @File : orm_demo2.py
# @Contact : limengjiejj@hotmail.com import os
from django.db.models import Q if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "SMS0614.settings")
import django django.setup() from myapp02 import models """
class Planner(models.Model):
name = models.CharField(max_length=50)
mobile = models.CharField(max_length=20) def __str__(self):
return self.name class Action(models.Model):
action_name = models.CharField(max_length=100)
action_type = models.IntegerField(choices=(
(1,"室内"),
(2,"室外"),
(3,"其他")
))
planner = models.ForeignKey(Planner)
start_time = models.DateTimeField(null=True,blank=True)
end_time = models.DateTimeField(null=True,blank=True) def __str__(self):
return self.action_name 查询出:
活动策划人手机号以“139”开头
活动名称为“action name”
活动类型不是室内
活动时间在“2018-01-01”,“2018-02-01”之间或者在“2018-03-01”,“2018-04-01”之间
活动的ID不在(100,200)的所有活动。 """
ret = models.Action.objects.exclude(id__range=(100, 200)).filter(
Q(start_time__gt="2018-01-01", end_time__lt="2018-02-01") | Q(
start_time__gt="2018-03-01", end_time__lt="2018-04-01"),
planner__mobile__startswith="",
action_name="action name",
action_type__in=[2, 3]
).values_list()
print(ret)
查询示例题
事务
import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings")
import django
django.setup() import datetime
from app01 import models try:
from django.db import transaction
with transaction.atomic():
new_publisher = models.Publisher.objects.create(name="火星出版社")
models.Book.objects.create(title="橘子物语", publish_date=datetime.date.today(), publisher_id=10) # 指定一个不存在的出版社id
except Exception as e:
print(str(e))
其他鲜为人知的操作(有个印象即可)
Django ORM执行原生SQL
# extra
# 在QuerySet的基础上继续执行子语句
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # select和select_params是一组,where和params是一组,tables用来设置from哪个表
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) 举个例子:
models.UserInfo.objects.extra(
select={'newid':'select count(1) from app01_usertype where id>%s'},
select_params=[1,],
where = ['age>%s'],
params=[18,],
order_by=['-age'],
tables=['app01_usertype']
)
"""
select
app01_userinfo.id,
(select count(1) from app01_usertype where id>1) as newid
from app01_userinfo,app01_usertype
where
app01_userinfo.age > 18
order by
app01_userinfo.age desc
""" # 执行原生SQL
# 更高灵活度的方式执行原生SQL语句
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [1])
# row = cursor.fetchone()
ORM执行原生SQL的方法
QuerySet方法大全
主要常用:
# 注意:sqlite没有DATE_FORMAT方法,请使用MySQL
# 将书籍 按 年月 的格式归档(默认日期为 年月日)
from django.db.models import Count
ret = models.Book.objects.extra(select={
"year_month":"DATE_FORMAT(publish_date,'%%Y-%%m')"
}).values("year_month").annotate(num=Count("id")).values("year_month","num")
print(ret) """
原生SQL:
SELECT (DATE_FORMAT(publish_date,'%Y-%m')) AS `year_month`, COUNT(`app03_book`.`id`) AS `num`
FROM `app03_book`
GROUP BY (DATE_FORMAT(publish_date,'%Y-%m'))
ORDER BY NULL LIMIT 21;
""" # 打印结果
# <QuerySet [{'year_month': '2018-05', 'num': 2}, {'year_month': '2018-06', 'num': 1}]>
extra示例
# 查找第一本书
from django.db import connection
cursor = connection.cursor()
cursor.execute("""select * from app03_book WHERE id = %s""",[1])
row = cursor.fetchone()
print(row) """
原生SQL:
select * from app03_book WHERE id = 1; args=[1]
""" # 打印结果
# (1, '书籍一', datetime.datetime(2018, 5, 22, 5, 31, 6, 319000))
connection--使用原生SQL,类似pymysql方式
# random和列表生成式来模拟100个随机数字【知识储备】 import random # 每个数字格式如下:
# ["66676869", "69656863", ...] # 方式一
# ret = []
# for j in range(100):
# list1 = []
# for i in range(4):
# list1.append(str(random.randint(65, 99)))
# ret.append("".join(list1))
# print(ret) # 方式二
# 列表生成式 (外层for循坏放在生成式右边)
ret2 = [ "".join([str(random.randint(65, 99)) for i in range(4)]) for j in range(100)]
print(ret2) #####################################
# 创建100个书籍示例对象【实例】 # 方式一,逐个执行SQL单独创建独个的对象,效率低
data = ["".join([str(random.randint(65, 99)) for i in range(4)]) for j in range(100)]
# for i in data:
# models.Book.objects.create(name=i) # 方式二,bulk_create方法,批量一次性执行SQL,效率大大提升【推荐】
obj_list = [models.Book(name=i) for i in data]
# 批量插入
models.Book.objects.bulk_create(obj_list)
bulk_create--批量创建100个实例对象
补充:
##################################################################
# PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
################################################################## def all(self)
# 获取所有的数据对象 def filter(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q def exclude(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。 总结:
1. select_related主要针一对一和多对一关系进行优化。
2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。 def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 总结:
1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。
2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。 def annotate(self, *args, **kwargs)
# 用于实现聚合group by查询 from django.db.models import Count, Avg, Max, Min, Sum v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 def distinct(self, *field_names)
# 用于distinct去重
models.UserInfo.objects.values('nid').distinct()
# select distinct nid from userinfo 注:只有在PostgreSQL中才能使用distinct进行去重 def order_by(self, *field_names)
# 用于排序
models.UserInfo.objects.all().order_by('-id','age') def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by('-nid').reverse()
# 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序 def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列数据 def only(self, *fields):
#仅取某个表中的数据
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id') def using(self, alias):
指定使用的数据库,参数为别名(setting中的设置) ##################################################
# PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
################################################## def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid from 其他表') # 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) # 将获取的到列名转换为指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) # 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default") ################### 原生SQL ###################
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..) def values(self, *fields):
# 获取每行数据为字典格式 def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖 def dates(self, field_name, kind, order='ASC'):
# 根据时间进行某一部分进行去重查找并截取指定内容
# kind只能是:"year"(年), "month"(年-月), "day"(年-月-日)
# order只能是:"ASC" "DESC"
# 并获取转换后的时间
- year : 年-01-01
- month: 年-月-01
- day : 年-月-日 models.DatePlus.objects.dates('ctime','day','DESC') def datetimes(self, field_name, kind, order='ASC', tzinfo=None):
# 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间
# kind只能是 "year", "month", "day", "hour", "minute", "second"
# order只能是:"ASC" "DESC"
# tzinfo时区对象
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC)
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai')) """
pip3 install pytz
import pytz
pytz.all_timezones
pytz.timezone(‘Asia/Shanghai’)
""" def none(self):
# 空QuerySet对象 ####################################
# METHODS THAT DO DATABASE QUERIES #
#################################### def aggregate(self, *args, **kwargs):
# 聚合函数,获取字典类型聚合结果
from django.db.models import Count, Avg, Max, Min, Sum
result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid'))
===> {'k': 3, 'n': 4} def count(self):
# 获取个数 def get(self, *args, **kwargs):
# 获取单个对象 def create(self, **kwargs):
# 创建对象 def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10) def get_or_create(self, defaults=None, **kwargs):
# 如果存在,则获取,否则,创建
# defaults 指定创建时,其他字段的值
obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '','u_id': 2, 't_id': 2}) def update_or_create(self, defaults=None, **kwargs):
# 如果存在,则更新,否则,创建
# defaults 指定创建时或更新时的其他字段
obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '','u_id': 2, 't_id': 1}) def first(self):
# 获取第一个 def last(self):
# 获取最后一个 def in_bulk(self, id_list=None):
# 根据主键ID进行查找
id_list = [11,21,31]
models.DDD.objects.in_bulk(id_list) def delete(self):
# 删除 def update(self, **kwargs):
# 更新 def exists(self):
# 是否有结果
QuerySet方法大全
Django终端打印SQL语句
在Django项目的settings.py文件中,在最后复制粘贴如下代码:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
即为你的Django项目配置上一个名为django.db.backends的logger实例即可查看翻译后的SQL语句。
在Python脚本中调用Django环境
import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings")
import django
django.setup() from app01 import models books = models.Book.objects.all()
print(books)
另外两个调试django项目的方法
调试django项目的便捷方法:
1、Terminal界面,输入:python manage.py shell(自动导入项目的配置参数)
2、python console界面,直接操作
a、基本操作
# 增
#
# models.Tb1.objects.create(c1='xx', c2='oo') 增加一条数据,可以接受字典类型数据 **kwargs # obj = models.Tb1(c1='xx', c2='oo')
# obj.save() # 查
#
# models.Tb1.objects.get(id=123) # 获取单条数据,不存在则报错(不建议)
# models.Tb1.objects.all() # 获取全部
# models.Tb1.objects.filter(name='seven') # 获取指定条件的数据 # 删
#
# models.Tb1.objects.filter(name='seven').delete() # 删除指定条件的数据 # 改
# models.Tb1.objects.filter(name='seven').update(gender='0') # 将指定条件的数据更新,均支持 **kwargs
# obj = models.Tb1.objects.get(id=1)
# obj.c1 = '111'
# obj.save() # 修改单条数据
基本操作
b、进阶操作(了不起的双下划线)
利用双下划线将字段和对应的操作连接起来

# 获取个数
#
# models.Tb1.objects.filter(name='seven').count() # 大于,小于
#
# models.Tb1.objects.filter(id__gt=1) # 获取id大于1的值
# models.Tb1.objects.filter(id__gte=1) # 获取id大于等于1的值
# models.Tb1.objects.filter(id__lt=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lte=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 # in
#
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in # isnull
# Entry.objects.filter(pub_date__isnull=True) # contains
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
# models.Tb1.objects.exclude(name__icontains="ven") # range
#
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and # 其他类似
#
# startswith,istartswith, endswith, iendswith, # order by
#
# models.Tb1.objects.filter(name='seven').order_by('id') # asc
# models.Tb1.objects.filter(name='seven').order_by('-id') # desc # group by
#
# from django.db.models import Count, Min, Max, Sum
# models.Tb1.objects.filter(c1=1).values('id').annotate(c=Count('num'))
# SELECT "app01_tb1"."id", COUNT("app01_tb1"."num") AS "c" FROM "app01_tb1" WHERE "app01_tb1"."c1" = 1 GROUP BY "app01_tb1"."id" # limit 、offset
#
# models.Tb1.objects.all()[10:20] # regex正则匹配,iregex 不区分大小写
#
# Entry.objects.get(title__regex=r'^(An?|The) +')
# Entry.objects.get(title__iregex=r'^(an?|the) +') # date
#
# Entry.objects.filter(pub_date__date=datetime.date(2005, 1, 1))
# Entry.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1)) # year
#
# Entry.objects.filter(pub_date__year=2005)
# Entry.objects.filter(pub_date__year__gte=2005) # month
#
# Entry.objects.filter(pub_date__month=12)
# Entry.objects.filter(pub_date__month__gte=6) # day
#
# Entry.objects.filter(pub_date__day=3)
# Entry.objects.filter(pub_date__day__gte=3) # week_day
#
# Entry.objects.filter(pub_date__week_day=2)
# Entry.objects.filter(pub_date__week_day__gte=2) # hour
#
# Event.objects.filter(timestamp__hour=23)
# Event.objects.filter(time__hour=5)
# Event.objects.filter(timestamp__hour__gte=12) # minute
#
# Event.objects.filter(timestamp__minute=29)
# Event.objects.filter(time__minute=46)
# Event.objects.filter(timestamp__minute__gte=29) # second
#
# Event.objects.filter(timestamp__second=31)
# Event.objects.filter(time__second=2)
# Event.objects.filter(timestamp__second__gte=31)
进阶操作
c、其他操作
# extra
#
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) # F
#
# from django.db.models import F
# models.Tb1.objects.update(num=F('num')+1) # Q
#
# 方式一:
# Q(nid__gt=10)
# Q(nid=8) | Q(nid__gt=10)
# Q(Q(nid=8) | Q(nid__gt=10)) & Q(caption='root')
# 方式二:
# con = Q()
# q1 = Q()
# q1.connector = 'OR'
# q1.children.append(('id', 1))
# q1.children.append(('id', 10))
# q1.children.append(('id', 9))
# q2 = Q()
# q2.connector = 'OR'
# q2.children.append(('c1', 1))
# q2.children.append(('c1', 10))
# q2.children.append(('c1', 9))
# con.add(q1, 'AND')
# con.add(q2, 'AND')
#
# models.Tb1.objects.filter(con) # 执行原生SQL
#
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [1])
# row = cursor.fetchone()
其他操作
d、连表操作(了不起的双下划线)
利用双下划线和 _set 将表之间的操作连接起来
class UserProfile(models.Model):
user_info = models.OneToOneField('UserInfo')
username = models.CharField(max_length=64)
password = models.CharField(max_length=64) def __unicode__(self):
return self.username class UserInfo(models.Model):
user_type_choice = (
(0, u'普通用户'),
(1, u'高级用户'),
)
user_type = models.IntegerField(choices=user_type_choice)
name = models.CharField(max_length=32)
email = models.CharField(max_length=32)
address = models.CharField(max_length=128) def __unicode__(self):
return self.name class UserGroup(models.Model): caption = models.CharField(max_length=64) user_info = models.ManyToManyField('UserInfo') def __unicode__(self):
return self.caption class Host(models.Model):
hostname = models.CharField(max_length=64)
ip = models.GenericIPAddressField()
user_group = models.ForeignKey('UserGroup') def __unicode__(self):
return self.hostname
表结构实例
user_info_obj = models.UserInfo.objects.filter(id=1).first()
print user_info_obj.user_type
print user_info_obj.get_user_type_display()
print user_info_obj.userprofile.password user_info_obj = models.UserInfo.objects.filter(id=1).values('email', 'userprofile__username').first()
print user_info_obj.keys()
print user_info_obj.values()
一对一操作
# 添加一对多
dic = {
"hostname": "名字1",
"ip": "192.168.1.1",
"user_group_id": 1, # 加对象则为"user_group"
}
models.Host.objects.create(**dic) # 正向查一对多
host_obj = models.Host.objects.all()
print(type(host_obj), # <class 'django.db.models.query.QuerySet'>
host_obj) # <QuerySet [<Host: 名字1>]>
for item in host_obj:
print(item.hostname)
print(item.user_group.caption)
print(item.user_group.user_info.values())
# <QuerySet [{'name': 'nick', 'user_type': 1, 'id': 1, 'email': '630571017@qq.com', 'address': '128号'}]> usergroup_obj = models.Host.objects.filter(user_group__caption='标题1')
print(usergroup_obj) # 反向查一对多
usergroup_obj = models.UserGroup.objects.get(id=1)
print(usergroup_obj.caption)
ret = usergroup_obj.host_set.all() # 所有关于id=1的host
print(ret) obj = models.UserGroup.objects.filter(host__ip='192.168.1.1').\
values('host__id', 'host__hostname')
print(obj) # <QuerySet [{'host__id': 1, 'host__hostname': '名字1'}]>
一对多操作
user_info_obj = models.UserInfo.objects.get(name='nick')
user_info_objs = models.UserInfo.objects.all() group_obj = models.UserGroup.objects.get(caption='CTO')
group_objs = models.UserGroup.objects.all() # 添加数据
#group_obj.user_info.add(user_info_obj)
#group_obj.user_info.add(*user_info_objs) # 删除数据
#group_obj.user_info.remove(user_info_obj)
#group_obj.user_info.remove(*user_info_objs) # 添加数据
#user_info_obj.usergroup_set.add(group_obj)
#user_info_obj.usergroup_set.add(*group_objs) # 删除数据
#user_info_obj.usergroup_set.remove(group_obj)
#user_info_obj.usergroup_set.remove(*group_objs) # 获取数据
#print group_obj.user_info.all()
#print group_obj.user_info.all().filter(id=1) # 获取数据
#print user_info_obj.usergroup_set.all()
#print user_info_obj.usergroup_set.all().filter(caption='CTO')
#print user_info_obj.usergroup_set.all().filter(caption='DBA') # 添加多对多
# userinfo_id_1 = models.UserInfo.objects.filter(id=1)
# usergroup_id_1 = models.UserGroup.objects.filter(id=1).first()
# usergroup_id_1.user_info.add(*userinfo_id_1)
多对多操作
扩展
a、自定义上传
def upload_file(request):
if request.method == "POST":
obj = request.FILES.get('fafafa')
f = open(obj.name, 'wb')
for chunk in obj.chunks():
f.write(chunk)
f.close()
return render(request, 'file.html')
自定义上传实例
b、Form上传文件实例
# HTML
<form method="post" action="/view1/" enctype="multipart/form-data">
<input type="file" name="ExcelFile" id="id_ExcelFile" />
<input type="submit" value="提交" />
</form>
# Form
class FileForm(forms.Form):
ExcelFile = forms.FileField()
# Models
from django.db import models
class UploadFile(models.Model):
userid = models.CharField(max_length = 30)
file = models.FileField(upload_to = './upload/')
date = models.DateTimeField(auto_now_add=True)
# Views
def UploadFile(request):
uf = AssetForm.FileForm(request.POST,request.FILES)
if uf.is_valid():
upload = models.UploadFile()
upload.userid = 1
upload.file = uf.cleaned_data['ExcelFile']
upload.save()
print upload.file
form上传文件实例
七、中间件(MiddleWare)
django 中的中间件(middleware),在django中,中间件其实就是一个类,在请求到来和结束后,django会根据自己的规则在合适的时机执行中间件中相应的方法。
在django项目的settings模块中,有一个 MIDDLEWARE_CLASSES 变量,其中每一个元素就是一个中间件。
什么是中间件?
官方的说法:中间件是一个用来处理Django的请求和响应的框架级别的钩子。它是一个轻量、低级别的插件系统,用于在全局范围内改变Django的输入和输出。每个中间件组件都负责做一些特定的功能。
但是由于其影响的是全局,所以需要谨慎使用,使用不当会影响性能。
说的直白一点中间件是帮助我们在视图函数执行之前和执行之后都可以做一些额外的操作,它本质上就是一个自定义类,类中定义了几个方法,Django框架会在请求的特定的时间去执行这些方法。
我们一直都在使用中间件,只是没有注意到而已,打开Django项目的Settings.py文件,看到下图的MIDDLEWARE配置项。
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
MIDDLEWARE配置项是一个列表,列表中是一个个字符串,这些字符串其实是一个个类,也就是一个个中间件。
我们之前已经接触过一个csrf相关的中间件了?我们一开始让大家把他注释掉,再提交post请求的时候,就不会被forbidden了,后来学会使用csrf_token之后就不再注释这个中间件了。
那接下来就学习中间件中的方法以及这些方法什么时候被执行。
补充:importlib模块
# 动态导入模块,通过字符串反射去导入模块
# my_md.py
class Person:
def __init__(self,name):
self.name = name # demo.py
s ="my_file.my_md"
import importlib
tmp = importlib.import_module(s)
lmj=tmp.Person("lmj")
print(lmj.name)
自定义中间件
中间件可以定义五个方法,分别是:(主要的是process_request和process_response)
- process_request(self,request)
- process_view(self, request, view_func, view_args, view_kwargs)
- process_template_response(self,request,response)
- process_exception(self, request, exception)
- process_response(self, request, response)
以上方法的返回值可以是None或一个HttpResponse对象,如果是None,则继续按照django定义的规则向后继续执行,如果是HttpResponse对象,则直接将该对象返回给用户。
自定义一个中间件示例
from django.utils.deprecation import MiddlewareMixin
class MD1(MiddlewareMixin):
def process_request(self, request):
print("MD1里面的 process_request")
def process_response(self, request, response):
print("MD1里面的 process_response")
return response
process_request
process_request有一个参数,就是request,这个request和视图函数中的request是一样的。
它的返回值可以是None也可以是HttpResponse对象。返回值是None的话,按正常流程继续走,交给下一个中间件处理,如果是HttpResponse对象,Django将不执行视图函数,而将相应对象返回给浏览器。
我们来看看多个中间件时,Django是如何执行其中的process_request方法的。
from django.utils.deprecation import MiddlewareMixin
class MD1(MiddlewareMixin):
def process_request(self, request):
print("MD1里面的 process_request")
class MD2(MiddlewareMixin):
def process_request(self, request):
print("MD2里面的 process_request")
pass
在settings.py的MIDDLEWARE配置项中注册上述两个自定义中间件:
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'middlewares.MD1', # 自定义中间件MD1
'middlewares.MD2' # 自定义中间件MD2
]
此时,我们访问一个视图,会发现终端中打印如下内容:
MD1里面的 process_request
MD2里面的 process_request
app01 中的 index视图
把MD1和MD2的位置调换一下,再访问一个视图,会发现终端中打印的内容如下:
MD2里面的 process_request
MD1里面的 process_request
app01 中的 index视图
看结果我们知道:视图函数还是最后执行的,MD2比MD1先执行自己的process_request方法。
在打印一下两个自定义中间件中process_request方法中的request参数,会发现它们是同一个对象。
由此总结一下:
- 中间件的process_request方法是在执行视图函数之前执行的。
- 当配置多个中间件时,会按照MIDDLEWARE中的注册顺序,也就是列表的索引值,从前到后依次执行的。
- 不同中间件之间传递的request都是同一个对象
多个中间件中的process_response方法是按照MIDDLEWARE中的注册顺序倒序执行的,也就是说第一个中间件的process_request方法首先执行,而它的process_response方法最后执行,最后一个中间件的process_request方法最后一个执行,它的process_response方法是最先执行。
process_response
它有两个参数,一个是request,一个是response,request就是上述例子中一样的对象,response是视图函数返回的HttpResponse对象。该方法的返回值也必须是HttpResponse对象。
给上述的M1和M2加上process_response方法:
from django.utils.deprecation import MiddlewareMixin
class MD1(MiddlewareMixin):
def process_request(self, request):
print("MD1里面的 process_request")
def process_response(self, request, response):
print("MD1里面的 process_response")
return response
class MD2(MiddlewareMixin):
def process_request(self, request):
print("MD2里面的 process_request")
pass
def process_response(self, request, response):
print("MD2里面的 process_response")
return response
访问一个视图,看一下终端的输出:
MD2里面的 process_request
MD1里面的 process_request
app01 中的 index视图
MD1里面的 process_response
MD2里面的 process_response
看结果可知:
process_response方法是在视图函数之后执行的,并且顺序是MD1比MD2先执行。(此时settings.py中 MD2比MD1先注册)
多个中间件中的process_response方法是按照MIDDLEWARE中的注册顺序倒序执行的,也就是说第一个中间件的process_request方法首先执行,而它的process_response方法最后执行,最后一个中间件的process_request方法最后一个执行,它的process_response方法是最先执行。
process_view
process_view(self, request, view_func, view_args, view_kwargs)
该方法有四个参数
request是HttpRequest对象。
view_func是Django即将使用的视图函数。 (它是实际的函数对象,而不是函数的名称作为字符串。)
view_args是将传递给视图的位置参数的列表.
view_kwargs是将传递给视图的关键字参数的字典。 view_args和view_kwargs都不包含第一个视图参数(request)。
Django会在调用视图函数之前调用process_view方法。
它应该返回None或一个HttpResponse对象。 如果返回None,Django将继续处理这个请求,执行任何其他中间件的process_view方法,然后在执行相应的视图。 如果它返回一个HttpResponse对象,Django不会调用适当的视图函数。 它将执行中间件的process_response方法并将应用到该HttpResponse并返回结果。
给MD1和MD2添加process_view方法:
from django.utils.deprecation import MiddlewareMixin
class MD1(MiddlewareMixin):
def process_request(self, request):
print("MD1里面的 process_request")
def process_response(self, request, response):
print("MD1里面的 process_response")
return response
def process_view(self, request, view_func, view_args, view_kwargs):
print("-" * 80)
print("MD1 中的process_view")
print(view_func, view_func.__name__)
class MD2(MiddlewareMixin):
def process_request(self, request):
print("MD2里面的 process_request")
pass
def process_response(self, request, response):
print("MD2里面的 process_response")
return response
def process_view(self, request, view_func, view_args, view_kwargs):
print("-" * 80)
print("MD2 中的process_view")
print(view_func, view_func.__name__)
访问index视图函数,看一下输出结果:
MD2里面的 process_request
MD1里面的 process_request
--------------------------------------------------------------------------------
MD2 中的process_view
<function index at 0x000001DE68317488> index
--------------------------------------------------------------------------------
MD1 中的process_view
<function index at 0x000001DE68317488> index
app01 中的 index视图
MD1里面的 process_response
MD2里面的 process_response
process_view方法是在process_request之后,视图函数之前执行的,执行顺序按照MIDDLEWARE中的注册顺序从前到后顺序执行的
process_exception
process_exception(self, request, exception)
该方法两个参数:
一个HttpRequest对象
一个exception是视图函数异常产生的Exception对象。
这个方法只有在视图函数中出现异常了才执行,它返回的值可以是一个None也可以是一个HttpResponse对象。如果是HttpResponse对象,Django将调用模板和中间件中的process_response方法,并返回给浏览器,否则将默认处理异常。如果返回一个None,则交给下一个中间件的process_exception方法来处理异常。它的执行顺序也是按照中间件注册顺序的倒序执行。
给MD1和MD2添加上这个方法:
from django.utils.deprecation import MiddlewareMixin
class MD1(MiddlewareMixin):
def process_request(self, request):
print("MD1里面的 process_request")
def process_response(self, request, response):
print("MD1里面的 process_response")
return response
def process_view(self, request, view_func, view_args, view_kwargs):
print("-" * 80)
print("MD1 中的process_view")
print(view_func, view_func.__name__)
def process_exception(self, request, exception):
print(exception)
print("MD1 中的process_exception")
class MD2(MiddlewareMixin):
def process_request(self, request):
print("MD2里面的 process_request")
pass
def process_response(self, request, response):
print("MD2里面的 process_response")
return response
def process_view(self, request, view_func, view_args, view_kwargs):
print("-" * 80)
print("MD2 中的process_view")
print(view_func, view_func.__name__)
def process_exception(self, request, exception):
print(exception)
print("MD2 中的process_exception")
如果视图函数中无异常,process_exception方法不执行。
想办法,在视图函数中抛出一个异常:
def index(request):
print("app01 中的 index视图")
raise ValueError("呵呵")
return HttpResponse("O98K")
在MD1的process_exception中返回一个响应对象:
class MD1(MiddlewareMixin):
def process_request(self, request):
print("MD1里面的 process_request")
def process_response(self, request, response):
print("MD1里面的 process_response")
return response
def process_view(self, request, view_func, view_args, view_kwargs):
print("-" * 80)
print("MD1 中的process_view")
print(view_func, view_func.__name__)
def process_exception(self, request, exception):
print(exception)
print("MD1 中的process_exception")
return HttpResponse(str(exception)) # 返回一个响应对象
看输出结果:
MD2里面的 process_request
MD1里面的 process_request
--------------------------------------------------------------------------------
MD2 中的process_view
<function index at 0x0000022C09727488> index
--------------------------------------------------------------------------------
MD1 中的process_view
<function index at 0x0000022C09727488> index
app01 中的 index视图
呵呵
MD1 中的process_exception
MD1里面的 process_response
MD2里面的 process_response
注意,这里并没有执行MD2的process_exception方法,因为MD1中的process_exception方法直接返回了一个响应对象。
process_template_response(用的比较少)
process_template_response(self, request, response)
它的参数,一个HttpRequest对象,response是TemplateResponse对象(由视图函数或者中间件产生)。
process_template_response是在视图函数执行完成后立即执行,但是它有一个前提条件,那就是视图函数返回的对象有一个render()方法(或者表明该对象是一个TemplateResponse对象或等价方法)。
class MD1(MiddlewareMixin):
def process_request(self, request):
print("MD1里面的 process_request")
def process_response(self, request, response):
print("MD1里面的 process_response")
return response
def process_view(self, request, view_func, view_args, view_kwargs):
print("-" * 80)
print("MD1 中的process_view")
print(view_func, view_func.__name__)
def process_exception(self, request, exception):
print(exception)
print("MD1 中的process_exception")
return HttpResponse(str(exception))
def process_template_response(self, request, response):
print("MD1 中的process_template_response")
return response
class MD2(MiddlewareMixin):
def process_request(self, request):
print("MD2里面的 process_request")
pass
def process_response(self, request, response):
print("MD2里面的 process_response")
return response
def process_view(self, request, view_func, view_args, view_kwargs):
print("-" * 80)
print("MD2 中的process_view")
print(view_func, view_func.__name__)
def process_exception(self, request, exception):
print(exception)
print("MD2 中的process_exception")
def process_template_response(self, request, response):
print("MD2 中的process_template_response")
return response
views.py中:
def index(request):
print("app01 中的 index视图") def render():
print("in index/render")
return HttpResponse("O98K")
rep = HttpResponse("OK")
rep.render = render
return rep
访问index视图,终端输出的结果:
MD2里面的 process_request
MD1里面的 process_request
--------------------------------------------------------------------------------
MD2 中的process_view
<function index at 0x000001C111B97488> index
--------------------------------------------------------------------------------
MD1 中的process_view
<function index at 0x000001C111B97488> index
app01 中的 index视图
MD1 中的process_template_response
MD2 中的process_template_response
in index/render
MD1里面的 process_response
MD2里面的 process_response
从结果看出:
视图函数执行完之后,立即执行了中间件的process_template_response方法,顺序是倒序,先执行MD1的,在执行MD2的,接着执行了视图函数返回的HttpResponse对象的render方法,返回了一个新的HttpResponse对象,接着执行中间件的process_response方法。
自用笔记:
1. 中间件概念
2. 如何自定义中间件
1. 按照格式要求写一个类
2. 把我们写好的类在settings.py注册到MIDDLEWARE配置项的列表中
3. 每一个中间件中五个可以被重写的方法:
1. process_request(self,request)
1. 何时执行
在urls.py之前执行
2. 执行的顺序
按照在列表中注册的顺序依次执行
3. 返回值
1. 返回None, 不错任何处理直接进行下一步
2. 返回响应对象, 直接跳出(后续中间件的process_request、不执行urls.py和views.py)返回响应
2. process_view(self, request, view_func, view_args, view_kwargs)
1. 执行时间:
在urls.py之后在执行真正的视图函数之前
2. 执行顺序
1. 按照在列表中注册的顺序依次执行
3. 返回值
1. 返回None, 放行
2. 返回响应对象,就直接跳出,倒序依次执行所有中间件的process_response方法
3. process_template_response(self,request,response)
4. process_exception(self, request, exception)
5. process_response(self, request, response)
1. 何时执行
在views.py返回响应对象之后执行
2. 执行的顺序
按照在列表中注册的倒序依次执行
3. 返回值
必须要有返回值,返回要是 响应对象
自用笔记
练习:一分钟内访问次数超五次的IP禁止访问
HISTORY = {}
BLACK_LIST = []
import datetime
class Throttle(MiddlewareMixin):
def process_request(self,request):
# 访问频率限制,每分钟不超过3次
# 拿到访问者的ip
now = datetime.datetime.now()
ip = request.META.get("REMOTE_ADDR")
if ip in BLACK_LIST:
return HttpResponse("滚~")
# 判断一下 当前 ip 有没有访问的history
if ip not in HISTORY:
HISTORY[ip] = {"last": now, "times": 0}
# 做访问次数的逻辑判断
if (now - HISTORY[ip]["last"]) < datetime.timedelta(seconds=60):
HISTORY[ip]["times"] += 1
else:
# 超过一分钟就清空之前的记录,重新计算
HISTORY[ip]["times"] = 0
HISTORY[ip]["last"] = now
# 判断
if HISTORY[ip]["times"] > 3:
BLACK_LIST.append(ip)
return HttpResponse("滚~")
中间件的执行流程
上一部分,我们了解了中间件中的5个方法,它们的参数、返回值以及什么时候执行,现在总结一下中间件的执行流程。
请求到达中间件之后,先按照正序执行每个注册中间件的process_reques方法,process_request方法返回的值是None,就依次执行,如果返回的值是HttpResponse对象,不再执行后面的process_request方法,而是执行当前对应中间件的process_response方法,将HttpResponse对象返回给浏览器。也就是说:如果MIDDLEWARE中注册了6个中间件,执行过程中,第3个中间件返回了一个HttpResponse对象,那么第4,5,6中间件的process_request和process_response方法都不执行,顺序执行3,2,1中间件的process_response方法。

process_request方法都执行完后,匹配路由,找到要执行的视图函数,先不执行视图函数,先执行中间件中的process_view方法,process_view方法返回None,继续按顺序执行,所有process_view方法执行完后执行视图函数。加入中间件3 的process_view方法返回了HttpResponse对象,则4,5,6的process_view以及视图函数都不执行,直接从最后一个中间件,也就是中间件6的process_response方法开始倒序执行。

process_template_response和process_exception两个方法的触发是有条件的,执行顺序也是倒序。总结所有的执行流程如下:


中间件版登录验证
中间件版的登录验证需要依靠session,所以数据库中要有django_session表。
urls.py
from django.conf.urls import url
from app01 import views urlpatterns = [
url(r'^index/$', views.index),
url(r'^login/$', views.login, name='login'),
]
views.py
from django.shortcuts import render, HttpResponse, redirect def index(request):
return HttpResponse('this is index') def home(request):
return HttpResponse('this is home') def login(request):
if request.method == "POST":
user = request.POST.get("user")
pwd = request.POST.get("pwd") if user == "Q1mi" and pwd == "":
# 设置session
request.session["user"] = user
# 获取跳到登陆页面之前的URL
next_url = request.GET.get("next")
# 如果有,就跳转回登陆之前的URL
if next_url:
return redirect(next_url)
# 否则默认跳转到index页面
else:
return redirect("/index/")
return render(request, "login.html")
login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>登录页面</title>
</head>
<body>
<form action="{% url 'login' %}">
<p>
<label for="user">用户名:</label>
<input type="text" name="user" id="user">
</p>
<p>
<label for="pwd">密 码:</label>
<input type="text" name="pwd" id="pwd">
</p>
<input type="submit" value="登录">
</form>
</body>
</html>
middlewares.py
class AuthMD(MiddlewareMixin):
white_list = ['/login/', ] # 白名单
balck_list = ['/black/', ] # 黑名单 def process_request(self, request):
from django.shortcuts import redirect, HttpResponse next_url = request.path_info
print(request.path_info, request.get_full_path()) if next_url in self.white_list or request.session.get("user"):
return
elif next_url in self.balck_list:
return HttpResponse('This is an illegal URL')
else:
return redirect("/login/?next={}".format(next_url))
在settings.py中注册
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'middlewares.AuthMD',
]
AuthMD中间件注册后,所有的请求都要走AuthMD的process_request方法。
访问的URL在白名单内或者session中有user用户名,则不做阻拦走正常流程;
如果URL在黑名单中,则返回This is an illegal URL的字符串;
正常的URL但是需要登录后访问,让浏览器跳转到登录页面。
注:AuthMD中间件中需要session,所以AuthMD注册的位置要在session中间的下方。
附:Django请求流程图
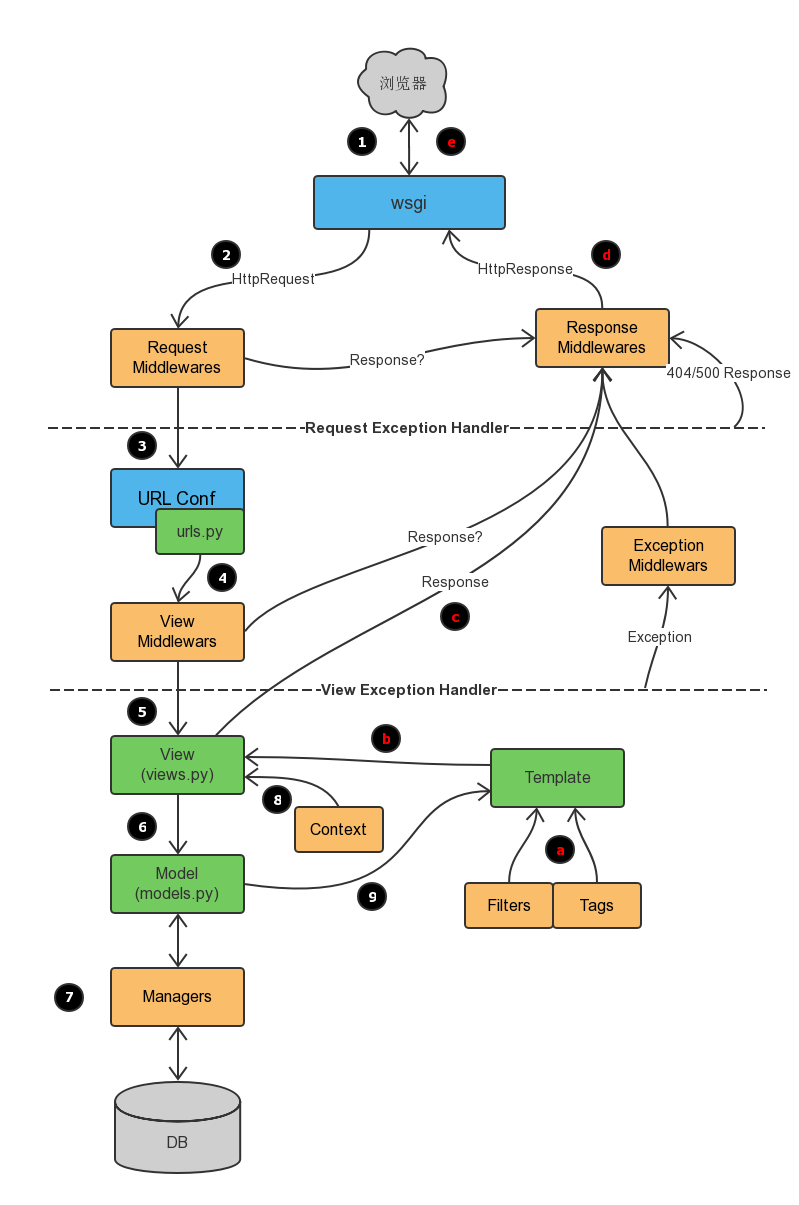
八、 Form
我们之前在HTML页面中利用form表单向后端提交数据时,都会写一些获取用户输入的标签并且用form标签把它们包起来。
与此同时我们在好多场景下都需要对用户的输入做校验,比如校验用户是否输入,输入的长度和格式等正不正确。如果用户输入的内容有错误就需要在页面上相应的位置显示对应的错误信息.。
Django form组件就实现了上面所述的功能。
总结一下,其实form组件的主要功能如下:
- 生成页面可用的HTML标签
- 对用户提交的数据进行校验
- 保留上次输入内容
使用form组件
views.py
先定义好一个LoginForm类。
from django import forms class LoginForm(forms.Form):
username = forms.CharField(min_length=6,label="用户名")
password = forms.CharField(min_length=3,label="密码") def login2(request):
if request.method == "POST":
form_obj = LoginForm(request.POST)
if form_obj.is_valid(): # 调用form提供的一个校验方法
# 验证成功
print(form_obj.cleaned_data) # 获取所有经过验证的数据
# 得到一个大字典,例如{'username': 'limengjie', 'password': 'limengjie123'}
# 验证成功后一般会有其他的操作,比如注册验证成功后,得到用户数据的干净数据后需要将数据入库
# models.User.objects.create(**form_obj.cleaned_data)
return HttpResponse("OK")
else:
# 用户填写的数据有错误
return render(request,"login2.html",{"form_obj":form_obj}) form_obj = LoginForm()
return render(request,"login2.html",{"form_obj":form_obj})
login2.html
一个简易的登录页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
.err{
color:red;
}
</style>
</head>
<body>
<form action="/login2/" method="post" novalidate>
{% csrf_token %}
<p>
{{ form_obj.username.label }}
{{ form_obj.username }}
<span class="err">{{ form_obj.username.errors.0 }}</span>
</p>
<p>
{{ form_obj.password.label }}
{{ form_obj.password }}
<span class="err">{{ form_obj.password.errors.0 }}</span>
</p>
<p>
<input type="submit" value="登录">
</p>
</form>
</body>
</html>
看网页效果发现 也验证了form的功能:
• 前端页面是form类的对象生成的 -->生成HTML标签功能
• 当用户名和密码输入为空或输错之后 页面都会提示 -->用户提交校验功能
• 当用户输错之后 再次输入 上次的内容还保留在input框 -->保留上次输入内容
Form常用字段与插件
创建Form类时,主要涉及到 【字段】 和 【插件】,字段用于对用户请求数据的验证,插件用于自动生成HTML;
initial
初始值,input框里面的初始值。
class LoginForm(forms.Form):
username = forms.CharField(
min_length=6,
label="用户名",
initial="用户名", # 设置默认值
error_messages={
"required": "不能为空",
"min_length": "用户名最少6位"
},
validators=[RegexValidator(r'^[^abc\s]+$', "用户名不符合社会主义核心价值观!"), ]
)
error_messages
重写错误信息。
password = forms.CharField(
min_length=3,
label="密码",
# 重写错误信息
error_messages={
"required": "不能为空",
"min_length": "密码最少3位"
},
)
widget
插件
password = forms.CharField(
min_length=3,
label="密码",
error_messages={
"required": "不能为空",
"min_length": "密码最少3位"
},
# widget插件。render_value:当报错时,输入框里的值是否保留
widget=forms.widgets.PasswordInput(
attrs={'class': 'c1'},
render_value=True
)
)
radioSelect
单radio值为字符串
gender = forms.fields.ChoiceField(
choices=((1, "男"), (2, "女"), (3, "保密")),
label="性别",
initial=3,
widget=forms.widgets.RadioSelect
)
单选Select
class LoginForm(forms.Form):
...
hobby = forms.fields.ChoiceField(
choices=((1, "篮球"), (2, "足球"), (3, "双色球"), ),
label="爱好",
initial=3,
widget=forms.widgets.Select
)
多选Select
class LoginForm(forms.Form):
...
hobby = forms.fields.MultipleChoiceField(
choices=((1, "篮球"), (2, "足球"), (3, "双色球"), ),
label="爱好",
initial=[1, 3],
widget=forms.widgets.SelectMultiple
)
单选checkbox
class LoginForm(forms.Form):
...
keep = forms.fields.ChoiceField(
label="是否记住密码",
initial="checked",
widget=forms.widgets.CheckboxInput
)
多选checkbox
class LoginForm(forms.Form):
...
hobby = forms.fields.MultipleChoiceField(
choices=((1, "篮球"), (2, "足球"), (3, "双色球"),),
label="爱好",
initial=[1, 3],
widget=forms.widgets.CheckboxSelectMultiple
)
关于choice的注意事项:(动态设置choice值的方法)
在使用选择标签时,需要注意choices的选项可以从数据库中获取
但是由于是静态字段 ***获取的值无法实时更新***
那么需要自定义构造方法从而达到此目的。
方式一:
# login2.html
<p>
{{ form_obj.hobby.label }}
{{ form_obj.hobby }}
<span class="err">{{ form_obj.hobby.errors.0 }}</span>
</p> # models.py
class Hobby(models.Model):
name = models.CharField(max_length=32) # views.py
hobby = forms.fields.MultipleChoiceField(
# choices=((1, "篮球"), (2, "足球"), (3, "双色球"),),
label="爱好",
error_messages={
"required": "不能为空"
},
widget=forms.widgets.SelectMultiple # 多选的select
# widget=forms.widgets.CheckboxInput # 单选的checkbox
# widget=forms.widgets.CheckboxSelectMultiple # 多选的checkbox
# widget=forms.widgets.Select # 单选的select
) def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
print(models.Hobby.objects.all().values_list("id", "name"))
# <QuerySet [(1, 'swim'), (2, 'basketball'), (3, 'football'), (4, 'pingpong'), (5, 'skipping')]>
self.fields["hobby"].choices = models.Hobby.objects.all().values_list("id", "name")
方式二:
from django import forms
from django.forms import fields
from django.forms import models as form_model class FInfo(forms.Form):
authors = form_model.ModelMultipleChoiceField(queryset=models.NNewType.objects.all()) # 多选
# authors = form_model.ModelChoiceField(queryset=models.NNewType.objects.all()) # 单选
Django Form所有内置字段
Field
required=True, 是否允许为空
widget=None, HTML插件
label=None, 用于生成Label标签或显示内容
initial=None, 初始值
help_text='', 帮助信息(在标签旁边显示)
error_messages=None, 错误信息 {'required': '不能为空', 'invalid': '格式错误'}
show_hidden_initial=False, 是否在当前插件后面再加一个隐藏的且具有默认值的插件(可用于检验两次输入是否一直)
validators=[], 自定义验证规则
localize=False, 是否支持本地化
disabled=False, 是否可以编辑
label_suffix=None Label内容后缀 CharField(Field)
max_length=None, 最大长度
min_length=None, 最小长度
strip=True 是否移除用户输入空白 IntegerField(Field)
max_value=None, 最大值
min_value=None, 最小值 FloatField(IntegerField)
... DecimalField(IntegerField)
max_value=None, 最大值
min_value=None, 最小值
max_digits=None, 总长度
decimal_places=None, 小数位长度 BaseTemporalField(Field)
input_formats=None 时间格式化 DateField(BaseTemporalField) 格式:2015-09-01
TimeField(BaseTemporalField) 格式:11:12
DateTimeField(BaseTemporalField)格式:2015-09-01 11:12 DurationField(Field) 时间间隔:%d %H:%M:%S.%f
... RegexField(CharField)
regex, 自定制正则表达式
max_length=None, 最大长度
min_length=None, 最小长度
error_message=None, 忽略,错误信息使用 error_messages={'invalid': '...'} EmailField(CharField)
... FileField(Field)
allow_empty_file=False 是否允许空文件 ImageField(FileField)
...
注:需要PIL模块,pip3 install Pillow
以上两个字典使用时,需要注意两点:
- form表单中 enctype="multipart/form-data"
- view函数中 obj = MyForm(request.POST, request.FILES) URLField(Field)
... BooleanField(Field)
... NullBooleanField(BooleanField)
... ChoiceField(Field)
...
choices=(), 选项,如:choices = ((0,'上海'),(1,'北京'),)
required=True, 是否必填
widget=None, 插件,默认select插件
label=None, Label内容
initial=None, 初始值
help_text='', 帮助提示 ModelChoiceField(ChoiceField)
... django.forms.models.ModelChoiceField
queryset, # 查询数据库中的数据
empty_label="---------", # 默认空显示内容
to_field_name=None, # HTML中value的值对应的字段
limit_choices_to=None # ModelForm中对queryset二次筛选 ModelMultipleChoiceField(ModelChoiceField)
... django.forms.models.ModelMultipleChoiceField TypedChoiceField(ChoiceField)
coerce = lambda val: val 对选中的值进行一次转换
empty_value= '' 空值的默认值 MultipleChoiceField(ChoiceField)
... TypedMultipleChoiceField(MultipleChoiceField)
coerce = lambda val: val 对选中的每一个值进行一次转换
empty_value= '' 空值的默认值 ComboField(Field)
fields=() 使用多个验证,如下:即验证最大长度20,又验证邮箱格式
fields.ComboField(fields=[fields.CharField(max_length=20), fields.EmailField(),]) MultiValueField(Field)
PS: 抽象类,子类中可以实现聚合多个字典去匹配一个值,要配合MultiWidget使用 SplitDateTimeField(MultiValueField)
input_date_formats=None, 格式列表:['%Y--%m--%d', '%m%d/%Y', '%m/%d/%y']
input_time_formats=None 格式列表:['%H:%M:%S', '%H:%M:%S.%f', '%H:%M'] FilePathField(ChoiceField) 文件选项,目录下文件显示在页面中
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹
required=True,
widget=None,
label=None,
initial=None,
help_text='' GenericIPAddressField
protocol='both', both,ipv4,ipv6支持的IP格式
unpack_ipv4=False 解析ipv4地址,如果是::ffff:192.0.2.1时候,可解析为192.0.2.1, PS:protocol必须为both才能启用 SlugField(CharField) 数字,字母,下划线,减号(连字符)
... UUIDField(CharField) uuid类型
django所有内置字段简述
校验
方式一,自定义一个规则函数给验证器调用:
from django import forms
from django.core.validators import RegexValidator
from django.core.exceptions import ValidationError # 自定义一个规则函数给验证器调用
def my_rule(value):
print(value) # 用户名abc
if "abc" in value:
# 数据校验不通过
raise ValidationError("不符合社会主义核心价值观!") class LoginForm(forms.Form):
username = forms.CharField(
min_length=6,
label="用户名",
initial="用户名", # 设置默认值
error_messages={
"required": "不能为空",
"min_length": "用户名最少6位"
},
# validators=[RegexValidator(r'^[^abc\s]+$', "用户名不符合社会主义核心价值观!"), ],
validators=[my_rule, ] # 使用自定义的规则函数
)
方式二,自定义验证规则
phone = forms.CharField(
min_length=11,
max_length=11,
error_messages={
"required": "手机号不能为空",
"min_length": "手机号应该是11位",
"max_length": "手机号应该是11位",
},
validators=[RegexValidator(r'^1[356789][0-9]{9}$', "手机格式不正确")]
)
或者:
# 自定义验证规则
def mobile_validate(value):
mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}$')
if not mobile_re.match(value):
raise ValidationError('手机号码格式错误') class LoginForm(forms.Form):
phone = forms.CharField(
min_length=11,
max_length=11,
error_messages={
"required": "手机号不能为空",
"min_length": "手机号应该是11位",
"max_length": "手机号应该是11位",
},
validators=[mobile_validate, ],
)
方式三(局部钩子),重写clean_%s函数(%s是相关字段名)
# 第三种验证方式,重写clean_%s函数(%s是相关字段名)
def clean_username(self): value = self.cleaned_data.get("username")
if "abc" in value:
raise ValidationError("不符合社会主义核心价值观!")
else:
return value
补充(全局钩子):两个字段值的比较(如注册过程中,密码的确认校验)
def clean(self):
pwd = self.cleaned_data.get("pwd")
re_pwd = self.cleaned_data.get("re_pwd") if pwd != re_pwd:
self.add_error("re_pwd", "两次输入的密码不一致!")
# 两次输入的密码不一致
raise ValidationError("两次输入的密码不一致!")
else:
return self.cleaned_data
自用笔记:
1. form表单能做的事儿:
1. 帮你生成HTML(form表单中获取用户输入的标签)
2. 帮你做数据有效性的校验,汇总错误信息
3. 保持用户之前输入的数据
2. 用法
1. 创建一个form类
from django import forms
class RegForm(forms.Form):
username = forms.Charfield(...) 2. 使用RegForm类
1. 模板中使用:
生成一个form_obj对象 form_obj = RegForm()
1. {{ form_obj.as_p }} 2. form_obj.username
2. 后端中使用:
生成一个form_obj对象 form_obj = RegForm(request.POST) form_obj.is_valid() ---> 帮我们做校验的方法 form_obj.cleaned_data --> 获取经过校验的数据
3. 常用的字段和参数
4. 自定义校验规则
1. 正则表达式
from django.core.validators import RegexValidator phone = forms.CharField(
...
validators=[RegexValidator(r'^1[356789][0-9]{9}$', "手机格式不正确"), ]
)
2. 自定义函数
from django.core.exceptions import ValidationError username = forms.CharField(
...
validators=[zhangzhao, ...]
) 3. 局部钩子
def clean_字段名(self):
# 1. 一旦不符合我订的校验规则,要抛出ValidationError
# 2. 符合校验规则 的话 一定一定一定要value返回 4. 全局的钩子
def clean(self):
self.cleaned_data ---> 经过前面每个字段独立校验的所有符合要求的数据
self.add_error("字段名", "错误提示信息")
# 1. 一旦不符合我订的校验规则,要抛出ValidationError # 2. 符合校验规则 的话 一定一定一定要cleaned_data返回
补充进阶
应用Bootstrap样式
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>login2</title>
<link rel="stylesheet" href="/static/bootstrap-3.3.7/css/bootstrap.min.css">
<style>
.help-block {
color: red;
}
</style>
</head>
<body>
<div class="container">
<div class="row">
<form action="/login2/" method="post" novalidate class="form-horizontal">
{% csrf_token %} {# 一个字段form-group=标签+主体+补充信息 #}
{# 用户名 #}
<div class="form-group">
{# 字段的标签 #}
<label for="{{ form_obj.username.id_for_label }}" class="control-label col-md-2">
{{ form_obj.username.label }}
</label>
{# 字段的主体 #}
<div class="col-md-10">
{{ form_obj.username }}
{# 字段的补充信息 #}
<span class="help-block">{{ form_obj.username.errors.0 }}</span>
</div>
</div> {# 密码 #}
<div class="form-group">
{# 字段的标签 #}
<label for="{{ form_obj.pwd.id_for_label }}" class="control-label col-md-2">
{{ form_obj.pwd.label }}
</label>
{# 字段的主体 #}
<div class="col-md-10">
{{ form_obj.pwd }}
{# 字段的补充信息 #}
<span class="help-block">{{ form_obj.pwd.errors.0 }}</span>
</div>
</div> {# 确认密码 #}
<div class="form-group">
{# 字段的标签 #}
<label for="{{ form_obj.re_pwd.id_for_label }}" class="control-label col-md-2">
{{ form_obj.re_pwd.label }}
</label>
{# 字段的主体 #}
<div class="col-md-10">
{{ form_obj.re_pwd }}
{# 字段的补充信息 #}
<span class="help-block">{{ form_obj.re_pwd.errors.0 }}</span>
</div>
</div> {# 性别 #}
<div class="form-group">
{# 字段的标签,注:无for属性 #}
<label class="control-label col-md-2">
{{ form_obj.gender.label }}
</label>
{# 字段的主体 #}
<div class="col-md-10">
<div class="radio">
{% for radio in form_obj.gender %}
<label for="{{ radio.id_for_label }}">
{{ radio.tag }}{{ radio.choice_label }}
</label>
{% endfor %}
</div>
</div>
</div> {# 爱好 #}
{# <div class="form-group">#}
{# 字段的标签,注:无for属性 #}
{# <label class="control-label col-md-2">#}
{# {{ form_obj.hobby.label }}#}
{# </label>#}
{# 字段的主体 #}
{# <div class="col-md-10">#}
{# <select multiple class="form-control">#}
{# {% for item in form_obj.hobby %}#}
{# <option>{{ item }}</option>#}
{# {% endfor %}#}
{# </select>#}
{# </div>#}
{# </div>#} {# 提交 #}
<div class="form-group">
<div class="col-md-offset-2 col-md-10">
<button type="submit" class="btn btn-default">注册</button>
</div>
</div> </form>
</div>
</div>
<script src="/static/jquery-3.3.1.min.js"></script>
<script src="/static/bootstrap-3.3.7/js/bootstrap.min.js"></script>
</body>
</html>
bootstrap-HTML示例
批量添加样式
可通过重写form类的init方法来实现。
class LoginForm(forms.Form):
username = forms.CharField(
min_length=8,
label="用户名",
initial="张三",
error_messages={
"required": "不能为空",
"invalid": "格式错误",
"min_length": "用户名最短8位"
}
... def __init__(self, *args, **kwargs):
super(LoginForm, self).__init__(*args, **kwargs)
for field in iter(self.fields):
self.fields[field].widget.attrs.update({
'class': 'form-control'
})
批量添加样式示例
九、 认证系统(auth)
我们在开发一个网站的时候,无可避免的要设计、实现网站的用户系统。此时我们需要实现包括但不限于用户注册、用户登录、用户认证、注销、修改密码等功能,这还真是个麻烦的事情呢。
Django作为一个完美主义者的终极框架,当然也会想到用户的这些痛点。它内置了强大的用户认证系统--auth,它默认使用 auth_user 表来存储用户数据。
注:在INSTALLED_APPS中添加'django.contrib.auth'使用该APP, auth模块默认是已经启用.
model
from django.contrib.auth.models import User # 数据库中该表名为auth_user.
CREATE TABLE "auth_user" (
"id" integer NOT NULL PRIMARY KEY AUTOINCREMENT,
"password" varchar(128) NOT NULL, "last_login" datetime NULL,
"is_superuser" bool NOT NULL,
"first_name" varchar(30) NOT NULL,
"last_name" varchar(30) NOT NULL,
"email" varchar(254) NOT NULL,
"is_staff" bool NOT NULL,
"is_active" bool NOT NULL,
"date_joined" datetime NOT NULL,
"username" varchar(30) NOT NULL UNIQUE
)
auth模块
from django.contrib import auth
auth中提供了许多实用方法:
authenticate()
提供了用户认证功能,即验证用户名以及密码是否正确,一般需要username 、password两个关键字参数。
如果认证成功(用户名和密码正确有效),便会返回一个 User 对象。
authenticate()会在该 User 对象上设置一个属性来标识后端已经认证了该用户,且该信息在后续的登录过程中是需要的。
用法:
# 用户输入有效性校验
# 认证用户的密码是否有效, 若有效则返回代表该用户的user对象, 若无效则返回None.
# 该方法不检查is_active标志位.
user = authenticate(username=username, password=password)
login(HttpRequest, user)
该函数接受一个HttpRequest对象,以及一个经过认证的User对象。
该函数实现一个用户登录的功能。它本质上会在后端为该用户生成相关session数据。
用法:
from django.contrib.auth import authenticate # 登录
def my_login(request):
if request.method == "POST":
username = request.POST.get("username")
password = request.POST.get("password")
# 用户输入有效性校验
# 认证用户的密码是否有效, 若有效则返回代表该用户的user对象, 若无效则返回None.
# 该方法不检查is_active标志位.
user = authenticate(username=username, password=password)
if user:
# 内置的login方法
# 生成Session数据,存一下user_id 然后把sessionid写入Cookie
# 后续每一次请求来的时候,AuthenticationMiddleware中的process_request方法中
# 会取到user_id,进而取到user对象,然后添加到request.user属性中 --> request.user = user
# 后续我们都可以通过request.user拿到当前的登陆用户对象
auth.login(request, user)
return redirect('/home/')
return render(request, "login.html")
logout(request)
该函数接受一个HttpRequest对象,无返回值。
当调用该函数时,当前请求的session信息会全部清除。该用户即使没有登录,使用该函数也不会报错。
用法:
# 注销
def logout(request):
# 调用auth内置的注销方法
auth.logout(request)
return redirect("/login/")
is_authenticated()
用来判断当前请求是否通过了认证。
用法:
def my_view(request):
if not request.user.is_authenticated():
return redirect('%s?next=%s' % (settings.LOGIN_URL, request.path))
login_requierd()
auth 给我们提供的一个装饰器工具,用来快捷的给某个视图添加登录校验。
用法:
from django.contrib.auth.decorators import login_required # 登陆后显示的个人主页
@login_required
def home(request):
return render(request, "home.html")
若用户没有登录,则会跳转到django默认的 登录URL '/accounts/login/ ' 并传递当前访问url的绝对路径 (登陆成功后,会重定向到该路径)。
如果需要自定义登录的URL,则需要在settings.py文件中通过LOGIN_URL进行修改。
示例:
LOGIN_URL = '/login/' # 这里配置成你项目登录页面的路由
create_user()
auth 提供的一个创建新用户的方法,需要提供必要参数(username、password)等。
用法:
注意:这里的UserInfo是用户扩展了auth_user表后的结果,使用前需导入
# myauth是app名
from myauth.models import UserInfo
然后书写注册新建用户的代码:
# 注册
def register(request):
if request.method == "POST":
username = request.POST.get("username")
password = request.POST.get("password")
# 新建普通用户
# 不存储用户密码明文而是存储一个Hash值
UserInfo.objects.create_user(username=username, password=password)
return render(request, "register.html")
create_superuser()
auth 提供的一个创建新的超级用户的方法,需要提供必要参数(username、password、email)等。
用法:
from django.contrib.auth.models import User
user = User.objects.create_superuser(username='用户名',password='密码',email='邮箱',...)
check_password(password)
auth 提供的一个检查密码是否正确的方法,需要提供当前请求用户的密码。
密码正确返回True,否则返回False。
用法:
is_ok = user.check_password('密码') #True/False
set_password(password)
auth 提供的一个修改密码的方法,接收 要设置的新密码 作为参数。
注意:设置完一定要调用用户对象的save方法!!!
用法:
# 在数据库修改密码
user_obj.set_password(new_pwd)
# 修改密码后一定要手动保存
user_obj.save()
一个修改密码示例
# 修改密码
@login_required
def change_password(request):
# 修改密码一定是先登录验证成功后的用户
user_obj = request.user
err_msg = ""
if request.method == "POST":
old_pwd = request.POST.get("old_pwd")
new_pwd = request.POST.get("new_pwd")
repeat_pwd = request.POST.get("repeat_pwd")
# 检测旧密码是否正确
if user_obj.check_password(old_pwd):
# 旧密码检测通过后,则执行如下:
if new_pwd == repeat_pwd:
# 在数据库修改密码
user_obj.set_password(new_pwd)
# 修改密码后一定要手动保存
user_obj.save()
return redirect('/login/')
elif not new_pwd:
err_msg = "密码不可为空"
else:
err_msg = "两次密码输入不一致"
else:
err_msg = "原密码校验不通过"
content = {
'err_msg': err_msg
}
return render(request, 'change_password.html', {'content': content})
auth模块实现修改密码示例
User对象的属性
User对象属性:username, password(必填项)password用哈希算法保存到数据库
is_staff : 用户是否拥有网站的管理权限.
is_active : 是否允许用户登录, 设置为 False,可以在删除用户的前提下禁止 用户 登录。
扩展默认的auth_user表
这内置的认证系统这么好用,但是auth_user表字段都是固定的那几个,我在项目中没法拿来直接使用啊!
比如,我想要加一个存储用户手机号的字段,怎么办?
聪明的你可能会想到新建另外一张表然后通过一对一和内置的auth_user表关联,这样虽然能满足要求但是有没有更好的实现方式呢?
答案是当然有了。
我们可以通过继承内置的 AbstractUser 类,来定义一个自己的Model类。
这样既能根据项目需求灵活的设计用户表,又能使用Django强大的认证系统了。
models.py
from django.db import models
from django.contrib.auth.models import AbstractUser class UserInfo(AbstractUser):
"""
用户信息表
"""
phone = models.CharField(max_length=11)
注意:
按上面的方式扩展了内置的auth_user表之后,一定要在settings.py中告诉Django,我现在使用我新定义的UserInfo表来做用户认证。写法如下:
settings.py
# 引用Django自带的User表,继承使用时需要设置,myauth是app名
AUTH_USER_MODEL = "myauth.UserInfo"
再次注意:
一旦我们指定了新的认证系统所使用的表,我们就需要重新在数据库中创建该表,而不能继续使用原来默认的auth_user表了。
自用笔记:(扩展了auth_user表,新表名为UserInfo)
from django.shortcuts import render, redirect, HttpResponse
from django.contrib import auth
from myauth.models import UserInfo # 扩展后的表
from django.contrib.auth.models import User # 默认的表 # 注册
def register(request):
if request.method == "POST":
username = request.POST.get("username")
password = request.POST.get("password")
# 新建普通用户
# 不存储用户密码明文而是存储一个Hash值
UserInfo.objects.create_user(username=username, password=password)
return render(request, "register.html") from django.contrib.auth import authenticate # 登录
def my_login(request):
if request.method == "POST":
username = request.POST.get("username")
password = request.POST.get("password")
# 用户输入有效性校验
# 认证用户的密码是否有效, 若有效则返回代表该用户的user对象, 若无效则返回None.
# 该方法不检查is_active标志位.
user = authenticate(username=username, password=password)
print(user)
print(type(user))
"""
limengjie
<class 'myauth.models.UserInfo'>
"""
if user:
# 内置的login方法
# 生成Session数据,存一下user_id 然后把sessionid写入Cookie
# 后续每一次请求来的时候,AuthenticationMiddleware中的process_request方法中
# 会取到user_id,进而取到user对象,然后添加到request.user属性中 --> request.user = user
# 后续我们都可以通过request.user拿到当前的登陆用户对象
auth.login(request, user)
return redirect('/home/')
return render(request, "login.html") from django.contrib.auth.decorators import login_required # 登陆后显示的个人主页
@login_required
def home(request):
return render(request, "home.html") # 注销
def logout(request):
# 调用auth内置的注销方法
auth.logout(request)
return redirect("/login/") # 修改密码
@login_required
def change_password(request):
# 修改密码一定是先登录验证成功后的用户
user_obj = request.user
err_msg = ""
if request.method == "POST":
old_pwd = request.POST.get("old_pwd")
new_pwd = request.POST.get("new_pwd")
repeat_pwd = request.POST.get("repeat_pwd")
# 检测旧密码是否正确
if user_obj.check_password(old_pwd):
# 旧密码检测通过后,则执行如下:
if new_pwd == repeat_pwd:
# 在数据库修改密码
user_obj.set_password(new_pwd)
# 修改密码后一定要手动保存
user_obj.save()
return redirect('/login/')
elif not new_pwd:
err_msg = "密码不可为空"
else:
err_msg = "两次密码输入不一致"
else:
err_msg = "原密码校验不通过"
content = {
'err_msg': err_msg
}
return render(request, 'change_password.html', {'content': content})
登录,注销,注册,修改密码示例源码
十、 跨站请求伪造(csrf)
django为用户实现防止跨站请求伪造的功能,通过中间件 django.middleware.csrf.CsrfViewMiddleware 来完成。而对于django中设置防跨站请求伪造功能有分为全局和局部。
全局:
中间件 django.middleware.csrf.CsrfViewMiddleware
局部:
- @csrf_protect,为当前函数强制设置防跨站请求伪造功能,即便settings中没有设置全局中间件。
- @csrf_exempt,取消当前函数防跨站请求伪造功能,即便settings中设置了全局中间件。
注:from django.views.decorators.csrf import csrf_exempt,csrf_protect
在Django1.10中,为了防止BREACH攻击,对cookie-form类型的csrf做了一点改进,即在cookie和form中的token值是不相同的
应用
1、普通表单
veiw中设置返回值:
return render(request, 'xxx.html', data) html中设置Token:
{% csrf_token %}
2、Ajax
对于传统的form,可以通过表单的方式将token再次发送到服务端,而对于ajax的话,使用如下方式。
# view.py from django.template.context import RequestContext
# Create your views here. def test(request): if request.method == 'POST':
print request.POST
return HttpResponse('ok')
return render_to_response('app01/test.html',context_instance=RequestContext(request))
views.py
# text.html <!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
{% csrf_token %} <input type="button" onclick="Do();" value="Do it"/> <script src="/static/plugin/jquery/jquery-1.8.0.js"></script>
<script src="/static/plugin/jquery/jquery.cookie.js"></script>
<script type="text/javascript">
var csrftoken = $.cookie('csrftoken'); function csrfSafeMethod(method) {
// these HTTP methods do not require CSRF protection
return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method));
}
$.ajaxSetup({
beforeSend: function(xhr, settings) {
if (!csrfSafeMethod(settings.type) && !this.crossDomain) {
xhr.setRequestHeader("X-CSRFToken", csrftoken);
}
}
});
function Do(){ $.ajax({
url:"/app01/test/",
data:{id:1},
type:'POST',
success:function(data){
console.log(data);
}
}); }
</script>
</body>
</html>
text.html
更多:https://docs.djangoproject.com/en/dev/ref/csrf/#ajax
十一、 分页
Django内置分页器
from django.shortcuts import render
from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger L = []
for i in range(999):
L.append(i) def index(request):
current_page = request.GET.get('p') paginator = Paginator(L, 10)
# per_page: 每页显示条目数量
# count: 数据总个数
# num_pages:总页数
# page_range:总页数的索引范围,如: (1,10),(1,200)
# page: page对象
try:
posts = paginator.page(current_page)
# has_next 是否有下一页
# next_page_number 下一页页码
# has_previous 是否有上一页
# previous_page_number 上一页页码
# object_list 分页之后的数据列表
# number 当前页
# paginator paginator对象
except PageNotAnInteger:
posts = paginator.page(1)
except EmptyPage:
posts = paginator.page(paginator.num_pages)
return render(request, 'index.html', {'posts': posts})
views.py
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<ul>
{% for item in posts %}
<li>{{ item }}</li>
{% endfor %}
</ul> <div class="pagination">
<span class="step-links">
{% if posts.has_previous %}
<a href="?p={{ posts.previous_page_number }}">Previous</a>
{% endif %}
<span class="current">
Page {{ posts.number }} of {{ posts.paginator.num_pages }}.
</span>
{% if posts.has_next %}
<a href="?p={{ posts.next_page_number }}">Next</a>
{% endif %}
</span> </div>
</body>
</html>
html
from django.shortcuts import render
from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger class CustomPaginator(Paginator):
def __init__(self, current_page, max_pager_num, *args, **kwargs):
"""
:param current_page: 当前页
:param max_pager_num:最多显示的页码个数
:param args:
:param kwargs:
:return:
"""
self.current_page = int(current_page)
self.max_pager_num = max_pager_num
super(CustomPaginator, self).__init__(*args, **kwargs) def page_num_range(self):
# 当前页面
# self.current_page
# 总页数
# self.num_pages
# 最多显示的页码个数
# self.max_pager_num
print(1)
if self.num_pages < self.max_pager_num:
return range(1, self.num_pages + 1)
print(2)
part = int(self.max_pager_num / 2)
if self.current_page - part < 1:
return range(1, self.max_pager_num + 1)
print(3)
if self.current_page + part > self.num_pages:
return range(self.num_pages + 1 - self.max_pager_num, self.num_pages + 1)
print(4)
return range(self.current_page - part, self.current_page + part + 1) L = []
for i in range(999):
L.append(i) def index(request):
current_page = request.GET.get('p')
paginator = CustomPaginator(current_page, 11, L, 10)
# per_page: 每页显示条目数量
# count: 数据总个数
# num_pages:总页数
# page_range:总页数的索引范围,如: (1,10),(1,200)
# page: page对象
try:
posts = paginator.page(current_page)
# has_next 是否有下一页
# next_page_number 下一页页码
# has_previous 是否有上一页
# previous_page_number 上一页页码
# object_list 分页之后的数据列表
# number 当前页
# paginator paginator对象
except PageNotAnInteger:
posts = paginator.page(1)
except EmptyPage:
posts = paginator.page(paginator.num_pages) return render(request, 'index.html', {'posts': posts})
扩展内置分页:views.py
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body> <ul>
{% for item in posts %}
<li>{{ item }}</li>
{% endfor %}
</ul> <div class="pagination">
<span class="step-links">
{% if posts.has_previous %}
<a href="?p={{ posts.previous_page_number }}">Previous</a>
{% endif %} {% for i in posts.paginator.page_num_range %}
<a href="?p={{ i }}">{{ i }}</a>
{% endfor %} {% if posts.has_next %}
<a href="?p={{ posts.next_page_number }}">Next</a>
{% endif %}
</span> <span class="current">
Page {{ posts.number }} of {{ posts.paginator.num_pages }}.
</span> </div>
</body>
</html>
扩展内置分页:html
自用笔记:
views.py部分
from django.core.paginator import Paginator,EmptyPage,PageNotAnInteger def book_list(request):
data = models.Book.objects.all()
current_page = request.GET.get("page")
page_obj = Paginator(data,10)
try:
book_list = page_obj.page(current_page)
# has_next 是否有下一页
# next_page_number 下一页页码
# has_previous 是否有上一页
# previous_page_number 上一页页码
# object_list 分页之后的数据列表
# number 当前页
# paginator paginator对象
except PageNotAnInteger:
book_list = page_obj.page(1)
except EmptyPage:
book_list = page_obj.page(page_obj.num_pages) return render(
request,
"book_list.html",
{"book_list":book_list}
)
Django自带分页器views.py部分
HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>书籍列表</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" href="/static/bootstrap/css/bootstrap.min.css">
</head>
<body>
<div class="container">
<table class="table table-striped">
<caption>书籍列表</caption>
<thead>
<tr>
<td>序号</td>
<td>书籍名称</td>
<td>创建时间</td>
</tr>
</thead>
<tbody>
{% for book in book_list %}
<tr>
<th>{{ forloop.counter }}</th>
<th>{{ book.title }}</th>
<th>{{ book.create_time|date:"Y-m-d H:i:s" }}</th>
</tr>
{% endfor %} </tbody>
</table>
{# 内置分页器实例 #}
<nav aria-label="Page navigation">
<ul class="pagination">
{% if book_list.has_previous %}
<li>
<a href="/book_list/?page={{ book_list.previous_page_number }}" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{% else %}
<li class="disabled">
<a aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{% endif %}
<li class="active"><a href="#">{{ book_list.number }}</a></li>
{% if book_list.has_next %}
<li>
<a href="/book_list/?page={{ book_list.next_page_number }}" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
{% else %}
<li class="disabled">
<a aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
{% endif %}
搜索框
<p>
<label>搜索<input type="text" id="search_page"></label>
<button id="search_btn" class="btn-primary">跳转</button>
</p>
</ul>
</nav>
</div>
<script src="/static/jquery-3.3.1.min.js"></script>
<script>
$(document).ready(function () {
$("#search_btn").click(function () {
search_num = $("#search_page").val();
new_href = "/book_list/?page=" + search_num;
location.href = new_href;
})
})
</script>
</body>
</html>
Django自带分页器HTML部分
自定义分页器
分页功能在每个网站都是必要的,对于分页来说,其实就是根据用户的输入计算出应该在数据库表中的起始位置。
1、设定每页显示数据条数
2、用户输入页码(第一页、第二页...)
3、根据设定的每页显示条数和当前页码,计算出需要取数据表的起始位置
4、在数据表中根据起始位置取值,页面上输出数据
需求又来了,需要在页面上显示分页的页面。如:[上一页][1][2][3][4][5][下一页]
1、设定每页显示数据条数
2、用户输入页码(第一页、第二页...)
3、设定显示多少页号
4、获取当前数据总条数
5、根据设定显示多少页号和数据总条数计算出,总页数
6、根据设定的每页显示条数和当前页码,计算出需要取数据表的起始位置
7、在数据表中根据起始位置取值,页面上输出数据
8、输出分页html,如:[上一页][1][2][3][4][5][下一页]
# 总结,分页时需要做三件事: 1、创建处理分页数据的类
2、根据分页数据获取数据
3、输出分页HTML
# 即:[上一页][1][2][3][4][5][下一页]
自用笔记:
(面条式)views.py中书写
from django.shortcuts import render
from . import models def book_list(request):
# 1、把所有数据都去出来,体验很差,不是我们要的结果,先统计总数据条数
show_data = models.Book.objects.all()
total_num = show_data.count()
# 2、定义每一页取指定的条数,如显示10条,按索引取值[0:10],实现动态取值
# show_data = models.Book.objects.all()[0:10]
per_page_data_num = 10
# 3、向用户获取页数,在URL中配置正则或通过设置?page=10两个方式查询,
# 这里采用后者通过GET方法取值,并且设置默认值为1,即为首页
try:
current_page = request.GET.get('page',1)
except Exception as e:
current_page = 1
# 4、取值均为字符型,需转换为整形以备后续计算使用
current_page = int(current_page)
# 5、定义分页器最多显示多少个页码,(当前页码高亮并居中,左右两边相同页码)
# 因此最好使用奇数
show_page_num = 11
# 6、分液器中,当前页码左右两边的页码数
half_show_page_num = show_page_num // 2
# 7、所有数据需要多少页码,divmod函数返回整数和余数
total_page,more = divmod(total_num,per_page_data_num)
# 8*、如果有余数,就把页码数+1
if more:
total_page += 1
# 9*、若当前页码数小于1,默认展示首页
if current_page < 1:
current_page = 1
# 10*、若当前页码数大于总页码数,默认展示最后一页的数据
if current_page > total_page:
current_page = total_page # 11、根据当前取值,计算分页器需要展示的页码范围start_page,end_page值(这里需要用上half和current值)
if current_page - half_show_page_num <=1:
start_page = 1
end_page = show_page_num
elif current_page + half_show_page_num >= total_page:
start_page = current_page - half_show_page_num + 1
end_page = total_page
else:
start_page = current_page - half_show_page_num
end_page = current_page + half_show_page_num # 测试:首页,当前页,尾页三个数值
print(start_page,current_page,end_page) # 12、当前页码应该展示的书籍数据,按照第2步的设计要求(这里需要用上current_page和per_page_data_num)
"""
第一页:[0:10],列表切片顾头不顾尾,实际数值范围为0~9
第二页:[10:20],10~19
...
第n页:[(n-1)*每页显示数据条数:n*每页显示数据条数]
"""
book_list = show_data[(current_page-1)*per_page_data_num:current_page*per_page_data_num]
# 13、生成分页的页码
"""
<li><a href="#">1</a></li>
<li><a href="#">2</a></li>
<li><a href="#">3</a></li>
<li><a href="#">4</a></li>
<li><a href="#">5</a></li>
"""
li_list = []
# 添加首页
li_list.append('<li><a href="/book_list/?page=1">首页</a></li>')
# 添加上一页
if current_page <= 1: # 若当前页没有“上一页"的值时
prev_li = '<li class="disabled"><a><span aria-hidden="true">«</span></a></li>'
else:
prev_li = '<li><a href="/book_list/?page={0}"><span aria-hidden="true">«</span></a></li>'.format(current_page - 1)
li_list.append(prev_li)
# 分页器的正体
for i in range(start_page,end_page+1): # range取值,顾头不顾尾,取尾页值需+1
# 当前页码高亮显示
if i == current_page:
tmp = '<li class="active"><a href="/book_list/?page={0}">{0}</a></li>'.format(i)
else:
tmp = '<li><a href="/book_list/?page={0}">{0}</a></li>'.format(i)
li_list.append(tmp)
# 添加下一页
if current_page >= total_page: # 若当前页没有“下一页"的值时
next_li = '<li class="disabled"><a><span aria-hidden="true">»</span></a></li>'
else:
next_li = '<li><a href="/book_list/?page={0}"><span aria-hidden="true">»</span></a></li>'.format(current_page + 1)
li_list.append(next_li)
# 添加尾页
li_list.append('<li><a href="/book_list/?page={0}">尾页</a></li>'.format(total_page)) # 将生成的li标签,拼接成大的字符串
pagination_html = ''.join(li_list) return render(
request,
'book_list.html',
{'book_list':book_list,'pagination_html':pagination_html}
)
面条式
(封装式)utils(项目根目录创建python文件包)-->my_pagination.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/06/25 19:30
# @Author : MJay_Lee
# @File : my_pagination.py
# @Contact : limengjiejj@hotmail.com class Pagination:
"""
使用说明:
from utils import mypage
page_obj = mypage.Page(total_num, current_page, 'publisher_list')
publisher_list = data[page_obj.data_start:page_obj.data_end]
page_html = page_obj.page_html() 为了显示效果,show_page_num最好使用奇数
"""
def __init__(self,total_num,current_page,url_prefix,per_page_data_num=10,show_page_num=11):
""" :param total_num: 数据的总条数
:param per_page_data_num: 每一页显示多少条数据
:param current_page: 当前访问的页码
:param url_prefix: a标签的URL前缀,如’book_list‘或'publisher_list'
:param show_page_num: 页面上最多显示多少个页码
""" self.total_num = total_num
self.url_prefix = url_prefix self.per_page_data_num = per_page_data_num
self.show_page_num = show_page_num # 通过初始化传入的值计算得到的值
self.half_show_page_num = self.show_page_num // 2
# 当前数据总共需要多少页码
total_page,more = divmod(self.total_num,self.per_page_data_num)
# 如果有余数,就把页码数+1
if more:
total_page += 1
self.total_page = total_page
# 对传进来的值进行有效性校验
try:
current_page = int(current_page)
except Exception as e:
current_page = 1 # 若当前页码数小于1,默认展示首页
if current_page < 1:
current_page = 1
# 若当前页码数大于总页码数,默认展示最后一页的数据
if current_page > self.total_page:
current_page = total_page
self.current_page = current_page # 根据当前取值,计算分页器需要展示的页码范围
if self.current_page - self.half_show_page_num <= 1:
start_page = 1
end_page = show_page_num
elif self.current_page + self.half_show_page_num >= total_page:
start_page = self.current_page - self.half_show_page_num + 1
end_page = total_page
else:
start_page = self.current_page - self.half_show_page_num
end_page = self.current_page + self.half_show_page_num
self.start_page = start_page
self.end_page = end_page @property
def data_start(self):
# 返回当前页应该从哪开始切数据
return (self.current_page -1) * self.per_page_data_num @property
def data_end(self):
# 返回当前页应该切到哪里为止
return self.current_page * self.per_page_data_num def page_tool_html(self):
li_list = []
# 添加首页
li_list.append('<li><a href="/{}/?page=1">首页</a></li>'.format(self.url_prefix))
# 添加上一页
if self.current_page <= 1: # 若当前页没有“上一页"的值时
prev_li = '<li class="disabled"><a><span aria-hidden="true">«</span></a></li>'
else:
prev_li = '<li><a href="/{0}/?page={1}"><span aria-hidden="true">«</span></a></li>'.format(self.url_prefix,self.current_page - 1)
li_list.append(prev_li)
# 分页器的正体
for i in range(self.start_page, self.end_page + 1): # range取值,顾头不顾尾,取尾页值需+1
# 当前页码高亮显示
if i == self.current_page:
tmp = '<li class="active"><a href="/{0}/?page={1}">{1}</a></li>'.format(self.url_prefix,i)
else:
tmp = '<li><a href="/{0}/?page={1}">{1}</a></li>'.format(self.url_prefix,i)
li_list.append(tmp)
# 添加下一页
if self.current_page >= self.total_page: # 若当前页没有“下一页"的值时
next_li = '<li class="disabled"><a><span aria-hidden="true">»</span></a></li>'
else:
next_li = '<li><a href="/{0}/?page={1}"><span aria-hidden="true">»</span></a></li>'.format(self.url_prefix,self.current_page + 1)
li_list.append(next_li)
# 添加尾页
li_list.append('<li><a href="/{0}/?page={1}">尾页</a></li>'.format(self.url_prefix,self.total_page)) # 将生成的li标签,拼接成大的字符串
pagination_html = ''.join(li_list)
return pagination_html
my_pagination.py
views.py引用自定义分页器:
# 自定义分页器
def book_list(request):
# 1、把所有数据都去出来,体验很差,不是我们要的结果,先统计总数据条数
show_data = models.Book.objects.all()
total_num = show_data.count() # 2、向用户获取页数,在URL中配置正则或通过设置?page=10两个方式查询,
# 这里采用后者通过GET方法取值,并且设置默认值为1,即为首页
current_page = request.GET.get('page',1) # 3、调用自定义的分页器
page_obj = my_pagination.Pagination(total_num,current_page,'book_list') # 4、当前页码应该展示的数据内容
book_list = show_data[page_obj.data_start:page_obj.data_end] # 5、生成分页器
page_html = page_obj.page_tool_html() return render(
request,
'book_list.html',
{'book_list':book_list,'pagination_html':page_html}
)
引用自定义分页器
HTML部分
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>书籍列表</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" href="/static/bootstrap/css/bootstrap.min.css">
</head>
<body>
<div class="container">
<table class="table table-striped">
<caption>书籍列表</caption>
<thead>
<tr>
<td>序号</td>
<td>书籍名称</td>
<td>创建时间</td>
</tr>
</thead>
<tbody>
{% for book in book_list %}
<tr>
<th>{{ forloop.counter }}</th>
<th>{{ book.title }}</th>
<th>{{ book.create_time|date:"Y-m-d H:i:s" }}</th>
</tr>
{% endfor %} </tbody>
</table>
{# 自定义分页器方式 #}
<nav aria-label="Page navigation">
<ul class="pagination">
{{ pagination_html|safe }}
<p>
<label>搜索<input type="text" id="search_page"></label>
<button id="search_btn" class="btn-primary">跳转</button>
</p>
</ul>
</nav>
</div>
<script src="/static/jquery-3.3.1.min.js"></script>
<script>
$(document).ready(function () {
$("#search_btn").click(function () {
search_num = $("#search_page").val();
new_href = "/book_list/?page=" + search_num;
location.href = new_href;
})
})
</script>
</body>
</html>
自定义分页器HTML部分
十二、 Cookie
Cookie的由来
大家都知道HTTP协议是无状态的。
无状态的意思是每次请求都是独立的,它的执行情况和结果与前面的请求和之后的请求都无直接关系,它不会受前面的请求响应情况直接影响,也不会直接影响后面的请求响应情况。
一句有意思的话来描述就是人生只如初见,对服务器来说,每次的请求都是全新的。
状态可以理解为客户端和服务器在某次会话中产生的数据,那无状态的就以为这些数据不会被保留。会话中产生的数据又是我们需要保存的,也就是说要“保持状态”。因此Cookie就是在这样一个场景下诞生。
什么是Cookie
Cookie具体指的是一段小信息,它是服务器发送出来存储在浏览器上的一组组键值对,下次访问服务器时浏览器会自动携带这些键值对,以便服务器提取有用信息。
Cookie的原理
cookie的工作原理是:由服务器产生内容,浏览器收到请求后保存在本地;当浏览器再次访问时,浏览器会自动带上Cookie,这样服务器就能通过Cookie的内容来判断这个是“谁”了。
查看Cookie
我们使用Chrome浏览器,打开开发者工具。

Django中操作Cookie
获取Cookie
request.COOKIES['key']
request.get_signed_cookie(key, default=RAISE_ERROR, salt='', max_age=None)
参数:
- default: 默认值
- salt: 加密盐
- max_age: 后台控制过期时间
设置Cookie
rep = HttpResponse(...) 或 rep = render(request, ...) rep.set_cookie(key,value,...)
rep.set_signed_cookie(key,value,salt='加密盐',...)
参数:
- key, 键
- value='', 值
- max_age=None, 超时时间
- expires=None, 超时时间(IE requires expires, so set it if hasn't been already.)
- path='/', Cookie生效的路径,/ 表示根路径,特殊的:根路径的cookie可以被任何url的页面访问
- domain=None, Cookie生效的域名
- secure=False, https传输
- httponly=False 只能http协议传输,无法被JavaScript获取(不是绝对,底层抓包可以获取到也可以被覆盖)
由于cookie保存在客户端的电脑上,所以,JavaScript和jquery也可以操作cookie。
<script src='/static/js/jquery.cookie.js'></script>
$.cookie("list_pager_num", 30,{ path: '/' });
删除Cookie
def logout(request):
rep = redirect("/login/")
rep.delete_cookie("login") # 删除用户浏览器上之前设置的usercookie值
return rep
自用笔记:
Cookie
1. 下定义:
保存在浏览器端的键值对
2. 用处:
1. 登录
2. 记住密码/7天免登录
3. 用户浏览习惯(每页显示10条)
4. 简单的投票限制
3. Django操作Cookie
1. 设置Cookie
req = HttpResponse("OK")
req.set_cookie("key", "value")
# 设置加盐的cookie
req.set_signed_cookie("key", "value", salt="shanghais1hao", max_age=秒) 2. 获取Cookie
request.COOKIES --> 大字典 request.COOKIES["key"]
request.COOKIES.get("key", "")
# 获取加盐的Cookie
request.get_signed_cookie("key", default="", salt="shanghais1hao") 3. 删除Coookie
req.delete_cookie("key")
自用笔记
一个登录校验实例(FBV+cookie)
HTML
home.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body> <h1>这是home页面,你登陆成功才能看到!!!</h1> <a href="/logout/">注销</a>
</body>
</html>
home HTML
login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body> <form action="{{ request.get_full_path }}" method="post">
{% csrf_token %}
<p>用户名:<input type="text" name="username"></p>
<p>密码:<input type="password" name="pwd"></p>
<p><input type="submit" value="登录"></p>
<p style="color:red">{{ err_msg }}</p>
</form> </body>
</html>
login HTML
views.py
from functools import wraps
# 定义一个检测是否登陆的装饰器
def check_login(func): @wraps(func)
def inner(request,*args,**kwargs):
# 另外一种写法:args[0]可单独提取出来,作为request的形参 # 判断一下请求体里面有没有cookie键值对
# 未加盐方式
# login_flag = request.COOKIES.get("login","") # cookie版
# 加盐方式
# default=""可避免无值情况的异常抛出
login_flag = request.get_signed_cookie("login",default="",salt="加盐")
if login_flag.upper() == "OK":
# 已登陆的用户
return func(request,*args,**kwargs)
else:
# 获取当前访问的URL
# url = request.path_info
# 或者完整URL信息,包含参数
url = request.get_full_path()
print("decorator_url:",url)
return redirect("/login/?next={}".format(url))
return inner # FBV+cookie实现登录
@csrf_exempt
def login(request):
if request.method == "POST":
username = request.POST.get("username")
pwd = request.POST.get("pwd") if username == "lmj" and pwd == "lmj123":
# 登陆成功
# 在返回响应的时候设置一下 cookie
# 获取next的参数,得到接下来要跳转到哪里去
url = request.GET.get("next") # 能取到参数 依赖于???
print("login_url",url)
if not url:
url = "/home/"
rep = redirect(url)
# rep.set_cookie("login", "ok")
rep.set_signed_cookie("login", "ok", salt="加盐", max_age=5)
return rep
return render(request, "login.html") from django.utils.decorators import method_decorator # home主页
@method_decorator(check_login,name="get")
class Home(views.View): # @method_decorator(check_login)
def get(self,request):
return render(request,"home.html")
views.py
十三、 Session
Session的由来
Cookie虽然在一定程度上解决了“保持状态”的需求,但是由于Cookie本身最大支持4096字节,以及Cookie本身保存在客户端,可能被拦截或窃取,因此就需要有一种新的东西,它能支持更多的字节,并且他保存在服务器,有较高的安全性。这就是Session。
问题来了,基于HTTP协议的无状态特征,服务器根本就不知道访问者是“谁”。那么上述的Cookie就起到桥接的作用。
我们可以给每个客户端的Cookie分配一个唯一的id,这样用户在访问时,通过Cookie,服务器就知道来的人是“谁”。然后我们再根据不同的Cookie的id,在服务器上保存一段时间的私密资料,如“账号密码”等等。
总结而言:Cookie弥补了HTTP无状态的不足,让服务器知道来的人是“谁”;但是Cookie以文本的形式保存在本地,自身安全性较差;所以我们就通过Cookie识别不同的用户,对应的在Session里保存私密的信息以及超过4096字节的文本。
另外,上述所说的Cookie和Session其实是共通性的东西,不限于语言和框架。
Django中Session相关方法
# 获取、设置、删除Session中数据
request.session['k1']
request.session.get('k1',None)
request.session['k1'] = 123
request.session.setdefault('k1',123) # 存在则不设置
del request.session['k1'] # 所有 键、值、键值对
request.session.keys()
request.session.values()
request.session.items()
request.session.iterkeys()
request.session.itervalues()
request.session.iteritems() # 会话session的key
request.session.session_key # 将所有Session失效日期小于当前日期的数据删除
request.session.clear_expired() # 检查会话session的key在数据库中是否存在
request.session.exists("session_key") # 删除当前会话的所有Session数据
request.session.delete()
# 删除当前的会话数据并删除会话的Cookie。
request.session.flush()
这用于确保前面的会话数据不可以再次被用户的浏览器访问
例如,django.contrib.auth.logout() 函数中就会调用它。 # 设置会话Session和Cookie的超时时间
request.session.set_expiry(value)
* 如果value是个整数,session会在些秒数后失效。
* 如果value是个datatime或timedelta,session就会在这个时间后失效。
* 如果value是0,用户关闭浏览器session就会失效。
* 如果value是None,session会依赖全局session失效策略。
自用笔记:
Session
1. 下定义:
保存在服务端的键值对,依赖于Cookie
2. 用处:
1. 登录
2. 保存手机验证码/验证码
3. 保存购物车数据
...
3. Django操作Session 1. 设置Session
1. request.session["key"] = "value"
2. request.session.set_expiry(秒/日期对象/时间间隔对象/0/None)
3. request.session.setdefault("k1", "v1") 2. 获取Session数据
1. request.session.get("k1", "")
2. request.session["k1"] 3. request.session.keys()
4. request.session.values()
5. request.session.items()
6. request.session.iterkeys()
7. request.session.itervalues()
8. request.session.iteritems() 3. 删除Session
1. request.session.flush() --> 多用于注销
2. request.session.delete() 4. 手动清除早已经过期的session数据
request.session.clear_expired() 5. 相关配置项(写在settings.py中的)
1.每次请求都更新Session失效时间
SESSION_SAVE_EVERY_REQUEST = True
2. SESSION_COOKIE_AGE = 1209600 # 设置Cookie超时时间 3. SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key
4. 其他:
SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径(默认)
SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名(默认)
SESSION_COOKIE_SECURE = False # 是否Https传输cookie(默认)
SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输(默认)
session自用笔记
Session流程解析

Session版登陆验证
from functools import wraps
# 定义一个检测是否登陆的装饰器
def check_login(func): @wraps(func)
def inner(request,*args,**kwargs):
# 另外一种写法:args[0]可单独提取出来,作为request的形参 # 判断一下请求体里面有没有cookie键值对
# 未加盐方式
# login_flag = request.COOKIES.get("login","") # cookie版
login_flag = request.session.get("login","") # session版
# 加盐方式
# default=""可避免无值情况的异常抛出
# login_flag = request.get_signed_cookie("login",default="",salt="加盐")
if login_flag.upper() == "OK":
# 已登陆的用户
return func(request,*args,**kwargs)
else:
# 获取当前访问的URL
# url = request.path_info
# 或者完整URL信息,包含参数
url = request.get_full_path()
print("decorator_url:",url)
return redirect("/login/?next={}".format(url))
return inner # CBV+session实现登陆
class Login_cbv(views.View):
def get(self, request):
return render(request, "login.html") def post(self, request):
if request.method == "POST":
username = request.POST.get("username")
pwd = request.POST.get("pwd") if username == "lmj" and pwd == "lmj123":
# 登录成功
request.session["login"] = "ok"
# 0,关闭浏览器窗口则需重新验证
request.session.set_expiry(0)
return redirect("/home/")
else:
return render(request,"login.html",{"err_msg":"账户或密码错误"}) from django.utils.decorators import method_decorator # home主页
@method_decorator(check_login,name="get")
class Home(views.View): # @method_decorator(check_login)
def get(self,request):
return render(request,"home.html") # 删除cookie,注销功能
def logout(request):
rep = redirect("/login/")
rep.delete_cookie("login") # 删除用户浏览器上之前设置的cookie值
return rep
session版验证
Django中的Session配置
Django中默认支持Session,其内部提供了5种类型的Session供开发者使用。settings.py中设置配置项。
1. 数据库Session
SESSION_ENGINE = 'django.contrib.sessions.backends.db' # 引擎(默认) 2. 缓存Session
SESSION_ENGINE = 'django.contrib.sessions.backends.cache' # 引擎
SESSION_CACHE_ALIAS = 'default' # 使用的缓存别名(默认内存缓存,也可以是memcache),此处别名依赖缓存的设置 3. 文件Session
SESSION_ENGINE = 'django.contrib.sessions.backends.file' # 引擎
SESSION_FILE_PATH = None # 缓存文件路径,如果为None,则使用tempfile模块获取一个临时地址tempfile.gettempdir() 4. 缓存+数据库
SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db' # 引擎 5. 加密Cookie Session
SESSION_ENGINE = 'django.contrib.sessions.backends.signed_cookies' # 引擎 其他公用设置项:
SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串(默认)
SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径(默认)
SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名(默认)
SESSION_COOKIE_SECURE = False # 是否Https传输cookie(默认)
SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输(默认)
SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)(默认)
SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期(默认)
SESSION_SAVE_EVERY_REQUEST = False # 是否每次请求都保存Session,默认修改之后才保存(默认)
session配置项
CBV中加装饰器相关
CBV实现的登录视图
# CBV+session实现登陆
class Login_cbv(views.View):
def get(self, request):
"""
处理GET请求,显示页面
:param request:
:return:
"""
return render(request, "login.html") def post(self, request):
"""
处理POST请求,请求数据处理相关
:param request:
:return:
"""
if request.method == "POST":
username = request.POST.get("username")
pwd = request.POST.get("pwd") if username == "lmj" and pwd == "lmj123":
# 登录成功
# 生成随机字符串
# 写浏览器cookie -> session_id: 随机字符串
# 写到服务端session:
# {
# "随机字符串": {'user':'lmj'}
# }
request.session["login"] = "ok"
# 0,关闭浏览器窗口则需重新验证
request.session.set_expiry(0)
next_url = request.GET.get("next")
if next_url:
return redirect(next_url)
else:
return redirect("/home/")
else:
return render(request,"login.html",{"err_msg":"账户或密码错误"})
要在CBV视图中使用我们上面的check_login装饰器,有以下三种方式:
先在当前views.py中导入模块:
from django.utils.decorators import method_decorator
1. 加在CBV视图的get或post方法上
from django.utils.decorators import method_decorator # home主页
class Home(views.View): def dispatch(self, request, *args, **kwargs):
return super(Home, self).dispatch(request, *args, **kwargs) @method_decorator(check_login)
def get(self,request):
return render(request,"home.html") @method_decorator(check_login)
def post(self,request):
print("Home View POST method")
return redirect("/home/")
CBV视图的GET或POST方法上
2. 加在dispatch方法上
因为CBV中首先执行的就是dispatch方法,所以这么写相当于给get和post方法都加上了登录校验。
# home主页
class Home(views.View): # @method_decorator(check_login)
def dispatch(self, request, *args, **kwargs):
return super(Home, self).dispatch(request, *args, **kwargs) def get(self,request):
return render(request,"home.html") def post(self,request):
print("Home View POST method")
return redirect("/home/")
加在dispatch方法上
3. 直接加在视图类上,但method_decorator必须传 name 关键字参数
如果get方法和post方法都需要登录校验的话就写两个装饰器。
from django.utils.decorators import method_decorator # home主页
@method_decorator(check_login, name="get")
@method_decorator(check_login, name="post")
class Home(views.View): def dispatch(self, request, *args, **kwargs):
return super(Home, self).dispatch(request, *args, **kwargs) def get(self,request):
return render(request,"home.html") def post(self,request):
print("Home View POST method")
return redirect("/home/")
直接加在视图类上
补充
CSRF Token相关装饰器在CBV只能加到dispatch方法上
备注:
- csrf_protect,为当前函数强制设置防跨站请求伪造功能,即便settings中没有设置全局中间件。
- csrf_exempt,取消当前函数防跨站请求伪造功能,即便settings中设置了全局中间件。
示例:
from django.views.decorators.csrf import csrf_exempt, csrf_protect
class HomeView(View):
@method_decorator(csrf_exempt)
def dispatch(self, request, *args, **kwargs):
return super(HomeView, self).dispatch(request, *args, **kwargs)
def get(self, request):
return render(request, "home.html")
def post(self, request):
print("Home View POST method...")
return redirect("/index/")
CSRF TOKEN装饰器示例
跟数据库的操作一样,在Django中不同缓存方式的使用方法是一致的,想要改变缓存的类型只需要改变上述相应配置即可。
十四、 缓存
由于Django是动态网站,所有每次请求均会去数据进行相应的操作,当程序访问量大时,耗时必然会更加明显,最简单解决方式是使用:缓存,缓存将一个某个views的返回值保存至内存或者memcache中,5分钟内再有人来访问时,则不再去执行view中的操作,而是直接从内存或者Redis中之前缓存的内容拿到,并返回。
Django中提供了6种缓存方式:
- 开发调试
- 内存
- 文件
- 数据库
- Memcache缓存(python-memcached模块)
- Memcache缓存(pylibmc模块)
和数据库类似,缓存的具体操作都是一样的,使用不同的方式只需要将配置改掉即可
1、配置
a、开发调试
# 此为开始调试用,实际内部不做任何操作
# 配置:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.dummy.DummyCache', # 引擎
'TIMEOUT': 300, # 缓存超时时间(默认300,None表示永不过期,0表示立即过期)
'OPTIONS':{
'MAX_ENTRIES': 300, # 最大缓存个数(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
},
'KEY_PREFIX': '', # 缓存key的前缀(默认空)
'VERSION': 1, # 缓存key的版本(默认1)
'KEY_FUNCTION' 函数名 # 生成key的函数(默认函数会生成为:【前缀:版本:key】)
}
} # 自定义key
def default_key_func(key, key_prefix, version):
"""
Default function to generate keys. Constructs the key used by all other methods. By default it prepends
the `key_prefix'. KEY_FUNCTION can be used to specify an alternate
function with custom key making behavior.
"""
return '%s:%s:%s' % (key_prefix, version, key) def get_key_func(key_func):
"""
Function to decide which key function to use. Defaults to ``default_key_func``.
"""
if key_func is not None:
if callable(key_func):
return key_func
else:
return import_string(key_func)
return default_key_func
开发调试
b、内存
# 此缓存将内容保存至内存的变量中
# 配置:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'LOCATION': 'unique-snowflake',
}
} # 注:其他配置同开发调试版本
内存
c、文件
# 此缓存将内容保存至文件
# 配置: CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': '/var/tmp/django_cache',
}
}
# 注:其他配置同开发调试版本
文件
d、数据库
# 此缓存将内容保存至数据库
# 配置:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache',
'LOCATION': 'my_cache_table', # 数据库表
}
}
# 注:执行创建表命令 python manage.py createcachetable
数据库
e、Memcache缓存(python-memcached模块)
# 此缓存使用python-memcached模块连接memcache
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': '127.0.0.1:11211',
}
}
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': 'unix:/tmp/memcached.sock',
}
}
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': [
'172.19.26.240:11211',
'172.19.26.242:11211',
]
}
}
f、Memcache缓存(pylibmc模块)
# 此缓存使用pylibmc模块连接memcache
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache',
'LOCATION': '127.0.0.1:11211',
}
}
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache',
'LOCATION': '/tmp/memcached.sock',
}
}
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache',
'LOCATION': [
'172.19.26.240:11211',
'172.19.26.242:11211',
]
}
}
2、应用
a. 全站使用
使用中间件,经过一系列的认证等操作,如果内容在缓存中存在,则使用FetchFromCacheMiddleware获取内容并返回给用户,当返回给用户之前,判断缓存中是否已经存在,如果不存在则UpdateCacheMiddleware会将缓存保存至缓存,从而实现全站缓存
MIDDLEWARE = [
'django.middleware.cache.UpdateCacheMiddleware',
# 其他中间件...
'django.middleware.cache.FetchFromCacheMiddleware',
]
CACHE_MIDDLEWARE_ALIAS = ""
CACHE_MIDDLEWARE_SECONDS = ""
CACHE_MIDDLEWARE_KEY_PREFIX = ""
b. 单独视图缓存
方式一:
from django.views.decorators.cache import cache_page @cache_page(60 * 15)
def my_view(request):
... 方式二:
from django.views.decorators.cache import cache_page urlpatterns = [
url(r'^foo/([0-9]{1,2})/$', cache_page(60 * 15)(my_view)),
]
c、局部视图使用
a. 引入TemplateTag
{% load cache %}
b. 使用缓存
{% cache 5000 缓存key %}
缓存内容
{% endcache %}
注:如果出现多个url匹配同一个view函数的情况,缓存机制会根据每一个不同的url做单独的缓存
更多:猛击这里
十五、AJAX及序列化
什么是 JSON ?
- JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation)
- JSON 是轻量级的文本数据交换格式
- JSON 独立于语言 *
- JSON 具有自我描述性,更易理解
* JSON 使用 JavaScript 语法来描述数据对象,但是 JSON 仍然独立于语言和平台。JSON 解析器和 JSON 库支持许多不同的编程语言。
请求头ContentType
ContentType指的是请求体的编码类型,常见的类型共有3种:
1 application/x-www-form-urlencoded
这应该是最常见的 POST 提交数据的方式了。浏览器的原生 <form> 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据。请求类似于下面这样(无关的请求头在本文中都省略掉了):
POST http://www.example.com HTTP/1.1
Content-Type: application/x-www-form-urlencoded;charset=utf-8 user=yuan&age=22
2 multipart/form-data
这又是一个常见的 POST 数据提交的方式。我们使用表单上传文件时,必须让 <form> 表单的 enctype 等于 multipart/form-data。直接来看一个请求示例:
POST http://www.example.com HTTP/1.1
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA ------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="user" yuan
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
这个例子稍微复杂点。首先生成了一个 boundary 用于分割不同的字段,为了避免与正文内容重复,boundary 很长很复杂。然后 Content-Type 里指明了数据是以 multipart/form-data 来编码,本次请求的 boundary 是什么内容。消息主体里按照字段个数又分为多个结构类似的部分,每部分都是以 --boundary 开始,紧接着是内容描述信息,然后是回车,最后是字段具体内容(文本或二进制)。如果传输的是文件,还要包含文件名和文件类型信息。消息主体最后以 --boundary-- 标示结束。关于 multipart/form-data 的详细定义,请前往 rfc1867 查看。
这种方式一般用来上传文件,各大服务端语言对它也有着良好的支持。
上面提到的这两种 POST 数据的方式,都是浏览器原生支持的,而且现阶段标准中原生 <form> 表单也只支持这两种方式(通过 <form> 元素的 enctype 属性指定,默认为 application/x-www-form-urlencoded。其实 enctype 还支持 text/plain,不过用得非常少)。
随着越来越多的 Web 站点,尤其是 WebApp,全部使用 Ajax 进行数据交互之后,我们完全可以定义新的数据提交方式,给开发带来更多便利。
3 application/json
application/json 这个 Content-Type 作为响应头大家肯定不陌生。实际上,现在越来越多的人把它作为请求头,用来告诉服务端消息主体是序列化后的 JSON 字符串。由于 JSON 规范的流行,除了低版本 IE 之外的各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理 JSON 的函数,使用 JSON 不会遇上什么麻烦。
JSON 格式支持比键值对复杂得多的结构化数据,这一点也很有用。记得我几年前做一个项目时,需要提交的数据层次非常深,我就是把数据 JSON 序列化之后来提交的。不过当时我是把 JSON 字符串作为 val,仍然放在键值对里,以 x-www-form-urlencoded 方式提交。
啥都别多说了,上图吧!

合格的json对象:
["one", "two", "three"]
{ "one": 1, "two": 2, "three": 3 }
{"names": ["张三", "李四"] }
[ { "name": "张三"}, {"name": "李四"} ]
不合格的json对象:
{ name: "张三", 'age': 32 } // 属性名必须使用双引号
[32, 64, 128, 0xFFF] // 不能使用十六进制值
{ "name": "张三", "age": undefined } // 不能使用undefined
{ "name": "张三",
"birthday": new Date('Fri, 26 Aug 2011 07:13:10 GMT'),
"getName": function() {return this.name;} // 不能使用函数和日期对象
}
stringify与parse方法
JavaScript中关于JSON对象和字符串转换的两个方法:
JSON.parse(): 用于将一个 JSON 字符串转换为 JavaScript 对象
JSON.parse('{"name":"lmj"}');
JSON.parse('{name:"lmj"}') ; // 错误
JSON.parse('[18,undefined]') ; // 错误
JSON.stringify(): 用于将 JavaScript 值转换为 JSON 字符串。
JSON.stringify({"name":"lmj"})
和XML的比较
JSON 格式于2001年由 Douglas Crockford 提出,目的就是取代繁琐笨重的 XML 格式。
JSON 格式有两个显著的优点:书写简单,一目了然;符合 JavaScript 原生语法,可以由解释引擎直接处理,不用另外添加解析代码。所以,JSON迅速被接受,已经成为各大网站交换数据的标准格式,并被写入ECMAScript 5,成为标准的一部分。
XML和JSON都使用结构化方法来标记数据,下面来做一个简单的比较。
用XML表示中国部分省市数据如下:
<?xml version="1.0" encoding="utf-8"?>
<country>
<name>中国</name>
<province>
<name>黑龙江</name>
<cities>
<city>哈尔滨</city>
<city>大庆</city>
</cities>
</province>
<province>
<name>广东</name>
<cities>
<city>广州</city>
<city>深圳</city>
<city>珠海</city>
</cities>
</province>
<province>
<name>台湾</name>
<cities>
<city>台北</city>
<city>高雄</city>
</cities>
</province>
<province>
<name>新疆</name>
<cities>
<city>乌鲁木齐</city>
</cities>
</province>
</country>
XML格式
用JSON表示如下:(推荐)
{
"name": "中国",
"province": [{
"name": "黑龙江",
"cities": {
"city": ["哈尔滨", "大庆"]
}
}, {
"name": "广东",
"cities": {
"city": ["广州", "深圳", "珠海"]
}
}, {
"name": "台湾",
"cities": {
"city": ["台北", "高雄"]
}
}, {
"name": "新疆",
"cities": {
"city": ["乌鲁木齐"]
}
}]
}
JSON格式
由上面的两端代码可以看出,JSON 简单的语法格式和清晰的层次结构明显要比 XML 容易阅读,并且在数据交换方面,由于 JSON 所使用的字符要比 XML 少得多,可以大大得节约传输数据所占用得带宽。
AJAX
AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步的Javascript和XML”。即使用Javascript语言与服务器进行异步交互,传输的数据为XML(当然,传输的数据不只是XML)。
AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容。(这一特点给用户的感受是在不知不觉中完成请求和响应过程)
AJAX 不需要任何浏览器插件,但需要用户允许JavaScript在浏览器上执行。
- 同步交互:客户端发出一个请求后,需要等待服务器响应结束后,才能发出第二个请求;
- 异步交互:客户端发出一个请求后,无需等待服务器响应结束,就可以发出第二个请求。
补充:
AJAX
1、AJAX是什么
前端向后端发送请求的方式 2、前端向后端发送请求的方式
1、直接在浏览器地址栏输入URL访问 -->GET
2、点击a标签跳转到指定页面 -->GET
3、form表单 -->GET/POST
4、AJAX -->GET/POST
示例
页面输入两个整数,通过AJAX传输到后端计算出结果并返回。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>AJAX局部刷新实例</title>
</head>
<body> <input type="text" id="i1">+
<input type="text" id="i2">=
<input type="text" id="i3">
<input type="button" value="AJAX提交" id="b1"> <script src="/static/jquery-3.2.1.min.js"></script>
<script>
$("#b1").on("click", function () {
$.ajax({
url:"/ajax_add/",
type:"GET",
data:{"i1":$("#i1").val(),"i2":$("#i2").val()},
success:function (data) {
$("#i3").val(data);
}
})
})
</script>
</body>
</html>
HTML部分
from django.shortcuts import render
from django.http import JsonResponse def ajax_demo1(request):
return render(request, "ajax_demo1.html") def ajax_add(request):
i1 = int(request.GET.get("i1"))
i2 = int(request.GET.get("i2"))
ret = i1 + i2
return JsonResponse(ret, safe=False)
views.py
urlpatterns = [
...
url(r'^ajax_add/', views.ajax_add),
url(r'^ajax_demo1/', views.ajax_demo1),
...
]
urls.py
AJAX常见应用情景
搜索引擎根据用户输入的关键字,自动提示检索关键字。
还有一个很重要的应用场景就是注册时候的用户名的查重。
其实这里就使用了AJAX技术!当文件框发生了输入变化时,使用AJAX技术向服务器发送一个请求,然后服务器会把查询到的结果响应给浏览器,最后再把后端返回的结果展示出来。
- 整个过程中页面没有刷新,只是刷新页面中的局部位置而已!
- 当请求发出后,浏览器还可以进行其他操作,无需等待服务器的响应!

当输入用户名后,把光标移动到其他表单项上时,浏览器会使用AJAX技术向服务器发出请求,服务器会查询名为lemontree7777777的用户是否存在,最终服务器返回true表示名为lemontree7777777的用户已经存在了,浏览器在得到结果后显示“用户名已被注册!”。
- 整个过程中页面没有刷新,只是局部刷新了;
- 在请求发出后,浏览器不用等待服务器响应结果就可以进行其他操作;
AJAX的优缺点
优点:
- AJAX使用JavaScript技术向服务器发送异步请求;
- AJAX请求无须刷新整个页面;
- 因为服务器响应内容不再是整个页面,而是页面中的部分内容,所以AJAX性能高;
缺点:
- 服务端数据处理压力增加
jQuery实现的AJAX
最基本的jQuery发送AJAX请求示例:
ajax_test.html:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>ajax test</title>
<script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script>
</head>
<body>
<button id="ajaxtest">AJAX 测试</button>
<script>
$("#ajaxtest").click(function () {
$.ajax({
url: "/ajax_test/",
type: "POST",
data: {username: "lmj", password: 123},
success: function (ret) {
alert(ret)
}
})
})
</script>
</body>
</html>
views.py:
from django.shortcuts import HttpResponse def ajax_test(request):
user_name = request.POST.get("username")
password = request.POST.get("password")
print(user_name, password)
return HttpResponse("OK")
$.ajax参数
data参数中的键值对,如果值值不为字符串或数字,需要使用JSON.stringfy()将其转换成字符串类型。
$("#b1").on("click", function () {
// 点击b1按钮触发事件
$.ajax({
// ajax请求发送的路由对象
url:"/ajax_add/",
// ajax请求发送的方式,GET或POST
type:"GET",
// ajax请求的数据
data:{"i1":$("#i1").val(),"i2":$("#i2").val(),"hehe": JSON.stringify([1, 2, 3])},
// ajax请求数据成功返回的内容
success:function (ret) {
// 请求被正常响应时自动执行的回调函数
$("#i3").val(ret);
}
})
})
原生JS实现AJAX
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body> <button id="b1">点我 发送 JS 版AJAX请求</button> <script>
let b1Ele = document.getElementById("b1");
b1Ele.onclick = function () {
// 1. 生成xmlHttp对象
let xmlHttp = new XMLHttpRequest();
// 2. 调用xmlHttp的open方法设置请求相关配置项
xmlHttp.open("POST", "/ajax_js/", true);
// 3. 设置请求头
xmlHttp.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
// 4. 调用send方法发送数据
xmlHttp.send("username=张曌&age=16");
// 5. 处理返回的响应
xmlHttp.onreadystatechange = function () {
if (xmlHttp.readyState === 4 && xmlHttp.status === 200) {
alert(xmlHttp.responseText);
}
}; } </script>
</body>
</html>
原生JS实现AJAX
AJAX请求如何设置csrf_token
方式1
通过获取隐藏的input标签中的csrfmiddlewaretoken值,放置在data中发送。
$.ajax({
url: "/cookie_ajax/",
type: "POST",
data: {
"username": "Q1mi",
"password": 123456,
"csrfmiddlewaretoken": $("[name = 'csrfmiddlewaretoken']").val() // 使用JQuery取出csrfmiddlewaretoken的值,拼接到data中
},
success: function (data) {
console.log(data);
}
})
获取隐藏的input标签中的csrfmiddlewaretoken值
方式2
通过获取返回的cookie中的字符串 放置在请求头中发送。
注意:需要引入一个jquery.cookie.js插件。(依赖于jquery)
$.ajax({
url: "/cookie_ajax/",
type: "POST",
headers: {"X-CSRFToken": $.cookie('csrftoken')}, // 从Cookie取csrf_token,并设置ajax请求头
data: {"username": "Q1mi", "password": 123456},
success: function (data) {
console.log(data);
}
})
获取返回的cookie中的kv值取csrf_token
方式3(一劳永逸)
写好自定义方法,js文件命名为ajax_setup.js(依赖于jquery)
每次项目使用AJAX时导入即可(推荐)
/*
* create by Mjay_Lee in 2018-06-27
* this is used to get csrf_token access for AJAX
* PS: This file rely on jQuery source file
*/ function getCookie(name) {
var cookieValue = null;
if (document.cookie && document.cookie !== '') {
var cookies = document.cookie.split(';');
for (var i = 0; i < cookies.length; i++) {
var cookie = jQuery.trim(cookies[i]);
// Does this cookie string begin with the name we want?
if (cookie.substring(0, name.length + 1) === (name + '=')) {
cookieValue = decodeURIComponent(cookie.substring(name.length + 1));
break;
}
}
}
return cookieValue;
}
var csrftoken = getCookie('csrftoken'); function csrfSafeMethod(method) {
// these HTTP methods do not require CSRF protection
return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method));
} $.ajaxSetup({
beforeSend: function (xhr, settings) {
if (!csrfSafeMethod(settings.type) && !this.crossDomain) {
xhr.setRequestHeader("X-CSRFToken", csrftoken);
}
}
});
ajax_setup
AJAX上传文件
注意:请求数据需转用表单对象。
$("#b1").click(function () {
// 先生成一个表单对象
var formData = new FormData();
// 向form表单对象添加键值对数据
formData.append("f1", $("#i1")[0].files[0]);
formData.append("name", "张曌");
$.ajax({
url: "/upload/",
type: "POST",
processData: false, // 告诉jQuery不要去处理发送的数据
contentType: false, // 告诉jQuery不要去设置Content-Type请求头
data: formData,
success:function (data) {
console.log(data)
}
})
});
练习(用户名是否已被注册)
功能介绍
在注册表单中,当用户填写了用户名后,把光标移开后,会自动向服务器发送异步请求。服务器返回这个用户名是否已经被注册过。
案例分析
- 页面中给出注册表单;
- 在username input标签中绑定onblur事件处理函数。
- 当input标签失去焦点后获取 username表单字段的值,向服务端发送AJAX请求;
- django的视图函数中处理该请求,获取username值,判断该用户在数据库中是否被注册,如果被注册了就返回“该用户已被注册”,否则响应“该用户名可以注册”。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>register</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<style>
.error {
color: red;
}
</style>
</head>
<body> <p>
用户名:<input type="text" id="i1">
<span class="error" id="s1"></span>
</p>
<p>
密码:<input type="password" id="i2">
</p>
<p>
<button id="b1">注册</button>
</p> <script src="/static/jquery-3.3.1.min.js"></script>
<script src="/static/setupAjax.js"></script>
<script>
$("#i1").on("input", function () {
$("#s1").text("");
// 只要i1这个标签失去焦点,我就要 把用户填写的值 往后端发送AJAX请求
var value = $(this).val();
$.ajax({
url: "/check_name/",
type: "POST",
data: {name: value},
success:function (data) {
console.log(data);
if (data.code){
// 用户名已存在!
$("#s1").text(data.errMsg);
}
}
})
}) </script>
</body>
</html>
注册验证HTML
def register(request):
return render(request, "register.html") def check_name(request):
if request.method == "POST":
ret = {"code": 0}
username = request.POST.get("name")
# 去数据库中查询是否有这个username对应的数据
is_exist = models.User.objects.filter(name=username)
if is_exist:
# 数据库中有这个用户名对应的数据
# 这个用户名已经存在不能再使用
ret = {"code": 1, "errMsg": "用户名已存在!"}
return JsonResponse(ret)
注册验证views.py
补充:AJAX登陆验证成功后跳转其他页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
<p>
用户名:<input type="text" id="i1">
<span class="error" id="s1"></span>
</p>
<p>
密码:<input type="password" id="i2">
</p>
<p>
<button id="b1">登录</button>
</p> <script src="/static/jquery-3.3.1.min.js"></script>
<script src="/static/setupAjax.js"></script>
<script>
$("#b1").click(function () {
var name = $("#i1").val();
var pwd = $("#i2").val();
$.ajax({
url: "/login/",
type: "POST",
data: {name: name, pwd: pwd},
success:function (data) {
if (!data.code){
// 登陆成功
location.href = data.data;
}
}
})
})
</script>
</body>
</html>
登录验证HTML
def login(request):
if request.method == "POST":
ret = {"code": 0}
name = request.POST.get("name")
pwd = request.POST.get("pwd")
ok = models.User.objects.filter(name=name, pwd=pwd)
if not ok:
ret["code"] = 1
ret["data"] = "用户名或密码错误"
else:
ret["data"] = "http://www.baidu.com"
return JsonResponse(ret)
return render(request, "login.html")
登陆验证views.py
序列化:Django内置的serializers
def books(request):
# 收到请求成功返回的标志
ret = {"code": 0}
book_list = models.Book.objects.all()
from django.core import serializers
data = serializers.serialize("json", book_list)
# 收到请求后,返回成功处理结果
ret["data"] = data
return JsonResponse(ret)
序列化补充:
关于Django中的序列化主要应用在将数据库中检索的数据返回给客户端用户,特别的Ajax请求一般返回的为Json格式。
1. serializers
from django.core import serializers
ret = models.BookType.objects.all()
data = serializers.serialize("json", ret)
2. json.dumps
import json
#ret = models.BookType.objects.all().values('caption')
ret = models.BookType.objects.all().values_list('caption')
ret=list(ret)
result = json.dumps(ret)
由于json.dumps时无法处理datetime日期,所以可以通过自定义处理器来做扩展,如:
import json
from datetime import date
from datetime import datetime class JsonCustomEncoder(json.JSONEncoder): def default(self, field): if isinstance(field, datetime):
return o.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(field, date):
return o.strftime('%Y-%m-%d')
else:
return json.JSONEncoder.default(self, field) # ds = json.dumps(d, cls=JsonCustomEncoder)
作为时间的处理
补充一个sweetalert插件示例

一个sweetalert示例:
$("#b55").click(function () {
swal({
title: "你确定要删除吗?",
text: "删除可就找不回来了哦!",
type: "warning",
showCancelButton: true, // 是否显示取消按钮
confirmButtonClass: "btn-danger", // 确认按钮的样式类
confirmButtonText: "删除", // 确认按钮文本
cancelButtonText: "取消", // 取消按钮文本
closeOnConfirm: false, // 点击确认按钮不关闭弹框
showLoaderOnConfirm: true // 显示正在删除的动画效果
},
function () {
var deleteId = 2;
$.ajax({
url: "/delete_book/",
type: "post",
data: {"id": deleteId},
success: function (data) {
if (data.code === 0) {
swal("删除成功!", "你可以准备跑路了!", "success");
} else {
swal("删除失败", "你可以再尝试一下!", "error")
}
}
})
});
})
十六、 信号
Django中提供了“信号调度”,用于在框架执行操作时解耦。通俗来讲,就是一些动作发生的时候,信号允许特定的发送者去提醒一些接受者。
1、Django内置信号
Model signals
pre_init # django的modal执行其构造方法前,自动触发
post_init # django的modal执行其构造方法后,自动触发
pre_save # django的modal对象保存前,自动触发
post_save # django的modal对象保存后,自动触发
pre_delete # django的modal对象删除前,自动触发
post_delete # django的modal对象删除后,自动触发
m2m_changed # django的modal中使用m2m字段操作第三张表(add,remove,clear)前后,自动触发
class_prepared # 程序启动时,检测已注册的app中modal类,对于每一个类,自动触发
Management signals
pre_migrate # 执行migrate命令前,自动触发
post_migrate # 执行migrate命令后,自动触发
Request/response signals
request_started # 请求到来前,自动触发
request_finished # 请求结束后,自动触发
got_request_exception # 请求异常后,自动触发
Test signals
setting_changed # 使用test测试修改配置文件时,自动触发
template_rendered # 使用test测试渲染模板时,自动触发
Database Wrappers
connection_created # 创建数据库连接时,自动触发
对于Django内置的信号,仅需注册指定信号,当程序执行相应操作时,自动触发注册函数:
from django.core.signals import request_finished
from django.core.signals import request_started
from django.core.signals import got_request_exception from django.db.models.signals import class_prepared
from django.db.models.signals import pre_init, post_init
from django.db.models.signals import pre_save, post_save
from django.db.models.signals import pre_delete, post_delete
from django.db.models.signals import m2m_changed
from django.db.models.signals import pre_migrate, post_migrate from django.test.signals import setting_changed
from django.test.signals import template_rendered from django.db.backends.signals import connection_created def callback(sender, **kwargs):
print("xxoo_callback")
print(sender,kwargs) xxoo.connect(callback)
# xxoo指上述导入的内容
2、自定义信号
a. 定义并注册信号
# 自定制信号
import django.dispatch
pizza_done = django.dispatch.Signal(providing_args=["toppings", "size"]) def callback(sender, **kwargs):
print("self-define")
print(sender, kwargs) pizza_done.connect(callback)
b. 触发信号
from 路径 import pizza_done pizza_done.send(sender='seven',toppings=123, size=456)
由于内置信号的触发者已经集成到Django中,所以其会自动调用,而对于自定义信号则需要开发者在任意位置触发。
更多:猛击这里
十七、admin
django amdin是django提供的一个后台管理页面,给管理页面提供完善的html和css,使得你在通过Model创建完数据库表之后,就可以对数据进行增删改查。
Django 提供了基于 web 的管理工具。
Django 自动管理工具是 django.contrib 的一部分。你可以在项目的 settings.py 中的 INSTALLED_APPS 看到它:
# Application definition INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
"app01" # 用户自定义注册的内容
]
django.contrib是一套庞大的功能集,它是Django基本代码的组成部分。
激活管理工具
通常我们在生成项目时会在 urls.py 中自动设置好,
from django.conf.urls import url
from django.contrib import admin urlpatterns = [
url(r'^admin/', admin.site.urls), ]
当这一切都配置好后,Django 管理工具就可以运行了。
使用管理工具
启动开发服务器,然后在浏览器中访问 http://127.0.0.1:8000/admin/,得到登陆界面,你可以通过命令 python manage.py createsuperuser 来创建超级用户。
为了让 admin 界面管理某个数据模型,我们需要先注册该数据模型到 admin
from django.db import models
class Author(models.Model):
name=models.CharField( max_length=32)
age=models.IntegerField()
def __str__(self):
return self.name
class Publish(models.Model):
name=models.CharField( max_length=32)
email=models.EmailField()
def __str__(self):
return self.name
class Book(models.Model):
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
publisher=models.ForeignKey(to="Publish")
authors=models.ManyToManyField(to='Author')
def __str__(self):
return self.title
admin的定制
在admin.py中只需要讲Model中的某个类注册,即可在Admin中实现增删改查的功能,如
admin.site.register(models.UserInfo)
但是,这种方式比较简单,如果想要进行更多的定制操作,需要利用ModelAdmin进行操作,如:
方式一:
class UserAdmin(admin.ModelAdmin):
list_display = ('user', 'pwd',) admin.site.register(models.UserInfo, UserAdmin) # 第一个参数可以是列表 方式二:
@admin.register(models.UserInfo) # 第一个参数可以是列表
class UserAdmin(admin.ModelAdmin):
list_display = ('user', 'pwd',)
ModelAdmin中提供了大量的可定制功能,如
1. list_display,列表时,定制显示的列。
@admin.register(models.UserInfo)
class UserAdmin(admin.ModelAdmin):
list_display = ('user', 'pwd', 'xxxxx') def xxxxx(self, obj):
return "xxxxx"
2. list_display_links,列表时,定制列可以点击跳转。
@admin.register(models.UserInfo)
class UserAdmin(admin.ModelAdmin):
list_display = ('user', 'pwd', 'xxxxx')
list_display_links = ('pwd',)
3. list_filter,列表时,定制右侧快速筛选。
4. list_select_related,列表时,连表查询是否自动select_related
5. list_editable,列表时,可以编辑的列
@admin.register(models.UserInfo)
class UserAdmin(admin.ModelAdmin):
list_display = ('user', 'pwd','ug',)
list_editable = ('ug',)
6. search_fields,列表时,模糊搜索的功能
@admin.register(models.UserInfo)
class UserAdmin(admin.ModelAdmin): search_fields = ('user', 'pwd')
7. date_hierarchy,列表时,对Date和DateTime类型进行搜索
@admin.register(models.UserInfo)
class UserAdmin(admin.ModelAdmin): date_hierarchy = 'ctime'
8 inlines,详细页面,如果有其他表和当前表做FK,那么详细页面可以进行动态增加和删除
class UserInfoInline(admin.StackedInline): # TabularInline
extra = 0
model = models.UserInfo class GroupAdminMode(admin.ModelAdmin):
list_display = ('id', 'title',)
inlines = [UserInfoInline, ]
9 action,列表时,定制action中的操作
@admin.register(models.UserInfo)
class UserAdmin(admin.ModelAdmin): # 定制Action行为具体方法
def func(self, request, queryset):
print(self, request, queryset)
print(request.POST.getlist('_selected_action')) func.short_description = "中文显示自定义Actions"
actions = [func, ] # Action选项都是在页面上方显示
actions_on_top = True
# Action选项都是在页面下方显示
actions_on_bottom = False # 是否显示选择个数
actions_selection_counter = True
from django.contrib import admin # Register your models here. from .models import * class BookInline(admin.StackedInline): # TabularInline
extra = 0
model = Book class BookAdmin(admin.ModelAdmin): list_display = ("title",'publishDate', 'price',"foo","publisher")
list_display_links = ('publishDate',"price")
list_filter = ('price',)
list_editable=("title","publisher")
search_fields = ('title',)
date_hierarchy = 'publishDate'
preserve_filters=False def foo(self,obj): return obj.title+str(obj.price) # 定制Action行为具体方法
def func(self, request, queryset):
print(self, request, queryset)
print(request.POST.getlist('_selected_action')) func.short_description = "中文显示自定义Actions"
actions = [func, ]
# Action选项都是在页面上方显示
actions_on_top = True
# Action选项都是在页面下方显示
actions_on_bottom = False # 是否显示选择个数
actions_selection_counter = True change_list_template="my_change_list_template.html" class PublishAdmin(admin.ModelAdmin):
list_display = ('name', 'email',)
inlines = [BookInline, ] admin.site.register(Book, BookAdmin) # 第一个参数可以是列表
admin.site.register(Publish,PublishAdmin)
admin.site.register(Author)
一个栗子
更多:https://docs.djangoproject.com/en/1.11/ref/contrib/admin/
以下为实际测试项目,随笔手录
Django项目步骤
python 3.6
django 1.1.13
学员管理系统 表结构: 班级表
- id
- className 学生表
- id
- studentname
- className(外键关联班级表) 老师表
- id
- teachername
- 班级(多对多) 步骤:
1、新建项目sms0614,(可同时新建一个应用myapp01)
2、新建数据库sms0614
-- Django ORM配置开始--
3、让Django链接数据库,在与项目名sms0614同名的文件夹中
找到settings.py
先注销默认的sqlite数据库配置
# DATABASES = {
# 'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
# }
# }
自定义新的mysql数据库配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'sms0614',
'HOST': '127.0.0.1',
'PORT': 3306,
'USER': 'root',
'PASSWORD': ''
}
}
4、django默认使用的是MySQLdb模块连接数据库,需要自定义新的模块
在与项目名sms0614同名的文件夹中,找到__init__.py
写入以下代码
import pymysql
pymysql.install_as_MySQLdb()
5、激活app
在settings.py中,因为项目初建时默认同时新建了一个应用,关键是判断是否是已添加'myapp01.apps.Myapp01Config'
# Application definition INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'myapp01.apps.Myapp01Config',
]
(目前阶段,为了测试方便,可注释csrf中间件)
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
6、在app01中的models.py中新建模型,必须继承models.Model类
from django.db import models # 班级表
class Class(models.Model):
id = models.AutoField(primary_key=True)
className = models.CharField(max_length=64) def __str__(self):
return self.className # 学生表
class Student(models.Model):
id = models.AutoField(primary_key=True)
studentName = models.CharField(max_length=64)
# 外键关联班级表
classes = models.ForeignKey(to=Class) def __str__(self):
return self.studentName # 老师表
class Teacher(models.Model):
id = models.AutoField(primary_key=True)
teacherName = models.CharField(max_length=64)
# 多对多关系
classes = models.ManyToManyField(to=Class) def __str__(self):
return self.teacherName 7、将项目中模板的修改记录,并到数据库中执行
python manage.py makemigrations
python manage.py migrate 在urls.py中配置路由:
from myapp01 import views urlpatterns = [
url(r'^admin/', admin.site.urls), # 以上匹配不成功时,则默认引导至此页面
url(r'^$',views.hello_page)
] 在应用文件myapp01中,找到视图views,设置业务逻辑函数:
from django.shortcuts import HttpResponse,render,redirect def hello_page(request):
return HttpResponse("success") 最后在终端pycharm的终端,Terminal中输入
python manage.py runserver 127.0.0.1:8000
或者点右上角的绿色三角标启动项目
启动无报错后,即表示正常
接着在浏览器上输入127.0.0.1:8000,页面返回字符串"success" -- Django ORM配置结束-- -- Django 页面测试开始--
8、配置静态文件
新建static文件夹,将css,js,图片等置入其中
在与项目同名的sms0614文件夹中,找到settings.py
在文件最后添加如下代码,表示配置了静态文件的路径
STATIC_URL = '/static/'
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static'),
] *9、在urls.py中增加路由:
url(r'^class_list/', views.class_list),
*10、在templates文件夹中,增加class_list.html页面
11、在views.py中,增加业务逻辑:
def class_list(request):
return render(request,"class_list.html") 至此,浏览器输入127.0.0.1:8000/class_list/,即可访问class_list.html页面
-- Django 页面测试结束-- *代表项目搭建好了之后,修改操作基本都是在操作路由系统和业务逻辑,以及重新修饰templates来展现你要表达的内容
学员管理系统
@admin.register(models.UserInfo)
class UserAdmin(admin.ModelAdmin): search_fields = ('user', 'pwd')
Django全面讲解(2/2)的更多相关文章
- Day16 Django深入讲解
参考博客: http://www.cnblogs.com/yuanchenqi/articles/6083427.html http://www.cnblogs.com/yuanchenqi/arti ...
- django中的事务管理
在讲解之前首先来了解一下数据库中的事务. 什么是数据库中的事务? 热心网友回答: ():事务(Transaction)是并发控制的单位,是用户定义的一个操作序列.这些操作要么都做,要么都不做,是一个不 ...
- Django+xadmin打造在线教育平台(六)
九.课程章节信息 9.1.模板和urls 拷贝course-comments.html 和 course-video.html放入 templates目录下 先改course-video.html,同 ...
- WEB框架本质和第一个Django实例
Web框架本质 我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端. 这样我们就可以自己实现Web框架了. 总的来说:Web框架的本质就是浏览 ...
- 【Python全栈-后端开发】嵩天老师-Django
嵩天老师-Python云端系统开发入门教程(Django) 视频地址:https://www.bilibili.com/video/av19801429 课前知识储备: 一.课程介绍: 分久必合.合久 ...
- Python高级进阶(二)Python框架之Django写图书管理系统(LMS)
正式写项目准备前的工作 Django是一个Web框架,我们使用它就是因为它能够把前后端解耦合而且能够与数据库建立ORM,这样,一个Python开发工程师只需要干自己开发的事情就可以了,而在使用之前就我 ...
- django---APIView源码分析
django---APIView源码分析 前言:APIView基于View 看这部分内容一定要懂django-CBV里的内容 在django-CBV源码分析中,我们是分析的from django.vi ...
- S16课件
Python之路,Day1 - Python基础1 介绍.基本语法.流程控制 Python之路,Day2 - Python基础2 列表.字典.集合 Python之路,Day3 - Python基础3 ...
- (33)关于django中路由自带的admin + 建表关系的讲解
admin是django自带的后台管理,在初始的时候就默认配置好了 当输入ip地址的时候后面跟admin,就会登陆管理员的后台,这个是django自带的,可以快速管理数据表(增删改查) PS:ip地址 ...
随机推荐
- python __new__()分析
我们来看下下面类中对__new__()方法的实现: class Demo(object): def __init__(self): print '__init__() called...' def _ ...
- cf1037E. Trips(图论 set)
题意 题目链接 Sol 倒着考虑!倒着考虑!倒着考虑! 显然,一个能成为答案的子图一定满足,其中任意节点的度数\(>= k\) 那么倒着维护就只用考虑删除操作,如果一个点不合法的话就把它删掉,然 ...
- Makefile一 头文件及库搜索路径
头文件及库搜索路径 头文件的搜索路径: 头文件的搜索规则是:找到就使用,停止继续往下寻找 1: #include “mytest.h” 搜索的顺序为: (1)先搜索当前目录 (2)然后搜索编译时 -I ...
- Java Struts2 (三)
一.国际化概念(了解) 1.什么是国际化 软件的国际化:软件开发时,要使它能同时应对世界不同地区和国家的访问,并针对不同地区和国家的访问,提供相应的.符合来访者阅读习惯的页面或数据. 2.什么需要国际 ...
- VMWARE错误-"VirtualInfrastructure.Utils.ClientsXml"的类型初始值设定项引发异常
异常信息:"VirtualInfrastructure.Utils.ClientsXml"的类型初始值设定项引发异常. 解决方案:以管理员的身份运行客户程序
- Android SQLite案例
重点掌握execSQL()和rawQuery()方法,rawQuery()方法用于执行select语句. SQLiteOpenHelper,实现了onCreate和onUpgrade方法. 第一次创建 ...
- ArrayList排序Sort()方法(转)
//使用Sort方法,可以对集合中的元素进行排序.Sort有三种重载方法,声明代码如下所//示. public void Sort(); //使用集合元素的比较方式进行排序 public void S ...
- Tomcat的运行模式
tomcat的三种运行模式 tomcat Tomcat Connector的三种不同的运行模式性能相差很大,有人测试过的结果如下: 这三种模式的不同之处如下: ●BIO: 一个线程处理一个请求.缺 ...
- 安装skype for business server组件 报错“未满足先决条件”和安装KB2982006补丁提示“此更新不适用于你的计算机”
安装skype for business server组件 报错“未满足先决条件” 上网经查询发现是没有安装KB2982006-x64 更新补丁 去官网上找这个补丁,发现这个补丁要热更新啥的,还要写邮 ...
- QT写hello world 以及信号槽机制
QT是一个C++的库,不仅仅有GUI的库.首先写一个hello world吧.敲代码,从hello world 写起. #include<QtGui/QApplication> #incl ...