【基础知识】ActiveMQ基本原理
“来,根据你的了解说下 ActiveMQ 是什么。”
“这个简单,ActiveMQ 是一个 MOM,具体来说是一个实现了 JMS 规范的系统间远程通信的消息代理。它……”
“等等,先解释下什么是 MOM。”
“好。MOM 就是面向消息中间件(Message-oriented middleware),是用于以分布式应用或系统中的异步、松耦合、可靠、可扩展和安全通信的一类软件。MOM 的总体思想是它作为消息发送器和消息接收器之间的消息中介,这种中介提供了一个全新水平的松耦合。”
“JMS呢?”
成小胖是个追求极致的人,为了解释得更通俗易懂,索性搬来一块白板边画边说。
“JMS 叫做 Java 消息服务(Java Message Service),是 Java 平台上有关面向 MOM 的技术规范,旨在通过提供标准的产生、发送、接收和处理消息的 API 简化企业应用的开发,类似于 JDBC 和关系型数据库通信方式的抽象。”

“嗯,很好。下面的这些概念你也需要特别理解下”:
- Provider:纯 Java 语言编写的 JMS 接口实现(比如 ActiveMQ 就是)
- Domains:消息传递方式,包括点对点(P2P)、发布/订阅(Pub/Sub)两种
- Connection factory:客户端使用连接工厂来创建与 JMS provider 的连接
- Destination:消息被寻址、发送以及接收的对象
“你来说说这其中 P2P 和 Pub/Sub 的区别吧”
P2P (点对点)消息域使用 queue 作为 Destination,消息可以被同步或异步的发送和接收,每个消息只会给一个 Consumer 传送一次。
Consumer 可以使用 MessageConsumer.receive() 同步地接收消息,也可以通过使用MessageConsumer.setMessageListener() 注册一个 MessageListener 实现异步接收。
多个 Consumer 可以注册到同一个 queue 上,但一个消息只能被一个 Consumer 所接收,然后由该 Consumer 来确认消息。并且在这种情况下,Provider 对所有注册的 Consumer 以轮询的方式发送消息。
Pub/Sub(发布/订阅,Publish/Subscribe)消息域使用 topic 作为 Destination,发布者向 topic 发送消息,订阅者注册接收来自 topic 的消息。发送到 topic 的任何消息都将自动传递给所有订阅者。接收方式(同步和异步)与 P2P 域相同。
除非显式指定,否则 topic 不会为订阅者保留消息。当然,这可以通过持久化(Durable)订阅来实现消息的保存。这种情况下,当订阅者与 Provider 断开时,Provider 会为它存储消息。当持久化订阅者重新连接时,将会受到所有的断连期间未消费的消息。
“嗯,总结的很不错,上面的这些知识是学习 ActiveMQ 的理论基础,是必须要掌握的。”
“既然 JMS 是一个通用的规范,那么使用它创建应用程序肯定也有一个通用的步骤吧?”
“有的有的。要不您来说说这个通用步骤?就当我考考您,哈哈!”
答案:
- 获取连接工厂
- 使用连接工厂创建连接
- 启动连接
- 从连接创建会话
- 获取 Destination
- 创建 Producer,或
- 创建 Producer
- 创建 message
- 创建 Consumer,或发送或接收message发送或接收 message
- 创建 Consumer
- 注册消息监听器(可选)
- 发送或接收 message
- 关闭资源(connection, session, producer, consumer 等)
“现在你手写上面步骤对应的代码实现吧”
public class JMSDemo {
ConnectionFactory connectionFactory;
Connection connection;
Session session;
Destination destination;
MessageProducer producer;
MessageConsumer consumer;
Message message;
boolean useTransaction = false;
try {
Context ctx = new InitialContext();
connectionFactory = (ConnectionFactory) ctx.lookup("ConnectionFactoryName");
//使用ActiveMQ时:connectionFactory = new ActiveMQConnectionFactory(user, password, getOptimizeBrokerUrl(broker));
connection = connectionFactory.createConnection();
connection.start();
session = connection.createSession(useTransaction, Session.AUTO_ACKNOWLEDGE);
destination = session.createQueue("TEST.QUEUE");
//生产者发送消息
producer = session.createProducer(destination);
message = session.createTextMessage("this is a test");
//消费者同步接收
consumer = session.createConsumer(destination);
message = (TextMessage) consumer.receive(1000);
System.out.println("Received message: " + message);
//消费者异步接收
consumer.setMessageListener(new MessageListener() {
@Override
public void onMessage(Message message) {
if (message != null) {
doMessageEvent(message);
}
}
});
} catch (JMSException e) {
...
} finally {
producer.close();
session.close();
connection.close();
}
}
“还算不赖哈~ JMS 通用的规范咱们都聊完了,下面就来聊点 ActiveMQ 更具体点的东西咯。”
“要不我先基于自己的学习讲讲 ActiveMQ 的存储,您看看我哪里讲的不对或者遗漏的,可好?”
“行,那就开始吧。”
ActiveMQ 在 queue 中存储 Message 时,采用先进先出顺序(FIFO)存储。同一时间一个消息被分派给单个消费者,且只有当 Message 被消费并确认时,它才能从存储中删除。

对于持久化订阅者来说,每个消费者获得 Message 的副本。为了节省存储空间,Provider 仅存储消息的一个副本。持久化订阅者维护了指向下一个 Message 的指针,并将其副本分派给消费者。以这种方式实现消息存储,因为每个持久化订阅者可能以不同的速率消费 Message,或者它们可能不是全部同时运行。此外,因每个 Message 可能存在多个消费者,所以在它被成功地传递给所有持久化订阅者之前,不能从存储中删除。

“很好,上面这段知识非常重要。其实我们可以通过表格来更清晰地展示”
| 消息类型 | 是否持久化 | 是否有Durable订阅者 | 消费者延迟启动时,消息是否保留 | Broker重启时,消息是否保留 |
| Queue | N | - | Y | N |
| Queue | Y | - | Y | Y |
| Topic | N | N | N | N |
| Topic | N | Y | Y | N |
| Topic | Y | N | N | N |
| Topic | Y | Y | Y | Y |
虽然对以上特性做过实践对比,但是并没有想到去画一个表格出来使对比更加清晰易懂。
“你再说说 ActiveMQ 常用的存储方式吧。”
1.KahaDB
ActiveMQ 5.3 版本起的默认存储方式。KahaDB存储是一个基于文件的快速存储消息,设计目标是易于使用且尽可能快。它使用基于文件的消息数据库意味着没有第三方数据库的先决条件。
要启用 KahaDB 存储,需要在 activemq.xml 中进行以下配置:
<broker brokerName="broker" persistent="true" useShutdownHook="false">
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb" journalMaxFileLength="16mb"/>
</persistenceAdapter>
</broker>
2.AMQ
与 KahaDB 存储一样,AMQ存储使用户能够快速启动和运行,因为它不依赖于第三方数据库。AMQ 消息存储库是可靠持久性和高性能索引的事务日志组合,当消息吞吐量是应用程序的主要需求时,该存储是最佳选择。但因为它为每个索引使用两个分开的文件,并且每个 Destination 都有一个索引,所以当你打算在代理中使用数千个队列的时候,不应该使用它。
<persistenceAdapter>
<amqPersistenceAdapter
directory="${activemq.data}/kahadb"
syncOnWrite="true"
indexPageSize="16kb"
indexMaxBinSize="100"
maxFileLength="10mb" />
</persistenceAdapter>
3.JDBC
选择关系型数据库,通常的原因是企业已经具备了管理关系型数据的专长,但是它在性能上绝对不优于上述消息存储实现。事实是,许多企业使用关系数据库作为存储,是因为他们更愿意充分利用这些数据库资源。
<beans>
<broker brokerName="test-broker" persistent="true" xmlns="http://activemq.apache.org/schema/core">
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds"/>
</persistenceAdapter>
</broker>
<bean id="mysql-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost/activemq?relaxAutoCommit=true"/>
<property name="username" value="activemq"/>
<property name="password" value="activemq"/>
<property name="maxActive" value="200"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
</beans>
4.内存存储
内存消息存储器将所有持久消息保存在内存中。在仅存储有限数量 Message 的情况下,内存消息存储会很有用,因为 Message 通常会被快速消耗。在 activema.xml 中将 broker 元素上的 persistent 属性设置为 false 即可。
<broker brokerName="test-broker" persistent="false" xmlns="http://activemq.apache.org/schema/core">
<transportConnectors>
<transportConnector uri="tcp://localhost:61635"/>
</transportConnectors>
</broker>
“下面就根据我在工作中的经历,给你讲讲 ActiveMQ 的部署模式。”
1.单例模式
这个就不啰嗦了,略过。
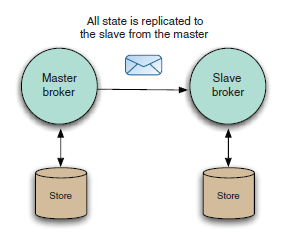
2.无共享主从模式
这是最简单的 Provider 高可用性的方案,主从节点分别存储 Message。从节点需要配置为连接到主节点,并且需要特殊配置其状态。
所有消息命令(消息,确认,订阅,事务等)都从主节点复制到从节点,这种复制发生在主节点对其接收的任何命令生效之前。并且,当主节点收到持久消息,会等待从节点完成消息的处理(通常是持久化到存储),然后再自己完成消息的处理(如持久化到存储)后,再返回对 Producer 的回执。
从节点不启动任何传输,也不能接受任何客户端或网络连接,除非主节点失效。当主节点失效后,从节点自动成为主节点,并且开启传输并接受连接。这是,使用 failover 传输的客户端就会连接到该新主节点。
Broker 连接配置如下:
failover://(tcp://masterhost:61616,tcp://slavehost:61616)?randomize=false
但是,这种部署模式有一些限制,
- 主节点只会在从节点连接到主节点时复制其活动状态,因此当从节点没有连接上主节点之前,任何主节点处理的 Message 或者消息确认都会在主节点失效后丢失。不过你可以通过在主节点设置 waitForSlave 来避免,这样就强制主节点在没有任何一个从节点连接上的情况下接受连接。
- 就是主节点只能有一个从节点,并且从节点不允许再有其他从节点。
- 把正在运行的单例配置成无共享主从,或者配置新的从节点时,你都要停止当前服务,修改配置后再重启才能生效。
在可以接受一些故障停机时间的情况下,可以使用该模式。
从节点配置:
<services>
<masterConnector remoteURI="tcp://remotehost:62001" userName="Rob" password="Davies"/>
</services>
此外,可以配置 shutdownOnMasterFailure 项,表示主节点失效后安全关闭,保证没有消息丢失,允许管理员维护一个新的从节点。
3.共享存储主从模式
允许多个代理共享存储,但任意时刻只有一个是活动的。这种情况下,当主节点失效时,无需人工干预来维护应用的完整性。另外一个好处就是没有从节点数的限制。
有两种细分模式:
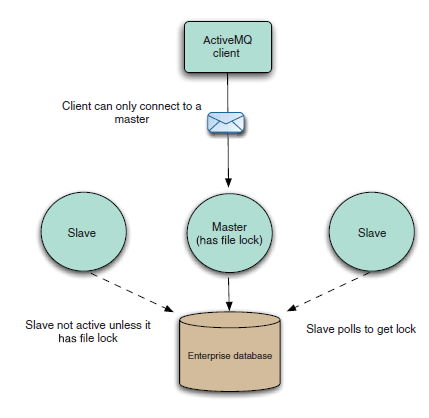
(1)基于数据库
它会获取一个表上的排它锁,以确保没有其他 ActiveMQ 代理可以同时访问数据库。其他未获得锁的代理则处于轮询状态,就会被当做是从节点,不会开启传输也不会接受连接。
(2)基于文件系统
需要获取分布式共享文件锁,linux 系统下推荐用 GFS2。

“再讲讲我所理解的 ActiveMQ 的网络连接”
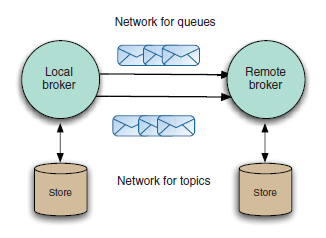
1.代理网络
支持将 ActiveMQ 消息代理链接到不同拓扑,这就是被人们熟知的代理网络。
ActiveMQ 网络使用存储和转发的概念,其中消息总是存储在本地代理中,然后通过网络转发到另一个代理。

当连接建立后,远程代理将把包含其所有持久和活动消费者目的地的信息传递给本地代理,本地代理根据信息决定远程代理感兴趣的 Message 并将它发送给远程代理。
如果希望网络是双向的,您可以使用网络连接器将远程代理配置为指向本地代理,或将网络连接器配置为双工,以便双向发送消息。
<networkConnectors>
<networkConnector uri="static://(tcp://backoffice:61617)"
name="bridge"
duplex="true"
conduitSubscriptions="true"
decreaseNetworkConsumerPriority="false">
</networkConnector>
</networkConnectors>
注意,配置的顺序很重要:
1.网络连接——需要在消息存储前建立好连接,对应 networkConnectors 元素
2.消息存储——需要在传输前配置好,对应 persistenceAdapter 元素
3.消息传输——最后配置,对应 transportConnectors 元素
2.网络发现
(1)动态发现
使用多播来支持网络动态发现。配置如下:
<networkConnectors> <networkConnector uri="multicast://default"/> </networkConnectors>
其中,multicast:// 中的默认名称表示该代理所属的组。因此使用此方式时,强烈推荐你使用一个独特的组名,避免你的代理连接到其他不相关代理。
(2)静态发现
静态发现接受代理 URI 列表,并将尝试按列表中确定的顺序连接到远程代理。
<networkConnectors> <networkConnector uri="static:(tcp://remote-master:61617,tcp://remote-slave:61617)"/> </networkConnectors>
相关配置如下:
- initialReconnectDelay:默认值1000,表示尝试连接前的时延。
- maxReconnectDelay:默认值30000,表示连接失败后到重新建立连接之间的时延,仅在 useExponentialBackOff 启用时生效。
- useExponentialBackOff:默认值 true,如果启用,表示每次失败后增加重建连接的时延。
- backOffMultiplier:默认值2,表示启用 useExponentialBackOff 后每次的时延增量需要注意的是,网络连接将始终尝试建立到远程代理的连接。
需要注意的是,网络连接将始终尝试建立到远程代理的连接。
(3)多连接场景
当网络负载高时,使用多连接很有意义。但是你需要确保不会重复传递消息,这可以通过过滤器来实现。
<networkConnectors>
<networkConnector uri="static://(tcp://remotehost:61617)"
name="queues_only"
duplex="true"
<excludedDestinations>
<topic physicalName=">"/>
</excludedDestinations>
</networkConnector>
<networkConnector uri="static://(tcp://remotehost:61617)"
name="topics_only"
duplex="true"
<excludedDestinations>
<queue physicalName=">"/>
</excludedDestinations>
</networkConnector>
</networkConnectors>
上面这些知识点虽然看起来很少,但却花了很多时间看了很多英文资料,同时反复实践才理解透的。
原文地址:http://www.cnblogs.com/cyfonly/p/6380860.html
【基础知识】ActiveMQ基本原理的更多相关文章
- RabbitMQ,Apache的ActiveMQ,阿里RocketMQ,Kafka,ZeroMQ,MetaMQ,Redis也可实现消息队列,RabbitMQ的应用场景以及基本原理介绍,RabbitMQ基础知识详解,RabbitMQ布曙
消息队列及常见消息队列介绍 2017-10-10 09:35操作系统/客户端/人脸识别 一.消息队列(MQ)概述 消息队列(Message Queue),是分布式系统中重要的组件,其通用的使用场景可以 ...
- 爬虫基础---HTTP协议理解、网页的基础知识、爬虫的基本原理
一.HTTP协议的理解 URL和URI 在学习HTTP之前我们需要了解一下URL.URI(精确的说明某资源的位置以及如果去访问它) URL:Universal Resource Locator 统一资 ...
- RabbitMQ基础知识
RabbitMQ基础知识 一.背景 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然 ...
- 转:RabbitMQ基础知识
RabbitMQ基础知识 一.背景 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然 ...
- 加密解密(7)*PKI基础知识(完整)
PKI 基础知识 摘要 本白皮书介绍了加密和公钥基本结构(PKI)的概念和使用 Microsoft Windows 2000 Server 操作系统中的证书服务的基础知识.如果您还不熟悉加密和公钥技术 ...
- android图形基础知识
Android核心分析(23)-----Andoird GDI之基本原理及其总体框架 2010-06-13 22:49 18223人阅读 评论(18) 收藏 举报 AndroidGDI基本框架 在An ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- Python爬虫(1):基础知识
爬虫基础知识 一.什么是爬虫? 向网站发起请求,获取资源后分析并提取有用数据的程序. 二.爬虫的基本流程 1.发起请求 2.获取内容 3.解析内容 4.保存数据 三.Request和Response ...
- IM开发基础知识补课(五):通俗易懂,正确理解并用好MQ消息队列
1.引言 消息是互联网信息的一种表现形式,是人利用计算机进行信息传递的有效载体,比如即时通讯网坛友最熟悉的即时通讯消息就是其具体的表现形式之一. 消息从发送者到接收者的典型传递方式有两种: 1)一种我 ...
- PHP面试(二):程序设计、框架基础知识、算法与数据结构、高并发解决方案类
一.程序设计 1.设计功能系统——数据表设计.数据表创建语句.连接数据库的方式.编码能力 二.框架基础知识 1.MVC框架基本原理——原理.常见框架.单一入口的工作原理.模板引擎的理解 2.常见框架的 ...
随机推荐
- 洛谷P4424 寻宝游戏 [HNOI/AHOI2018]
正解:思维题 解题报告: 传送门! 这题就是很思维题,,,想到辣实现麻油特别难,但难想到是真的TT 这题主要是要发现一个性质:&1无意义,&0相当于赋值为0,|1无意义,|1相当于赋值 ...
- scp sparkuser@spark02:/home/sparkuser/.ssh
文件计算机传送 命令格式:{scp} {计算机用户}@{计算机网络名称}:{目标计算机路径} scp sparkuser@spark02:/home/sparkuser/.ssh
- 【Pyton】【小甲鱼】正则表达式(一)
正则表达式学习: >>> import re >>> re.search(r'FishC','I love FishC.com!') <_sre.SRE_Ma ...
- mysql python pymysql模块 基本使用
我们都是通过MySQL自带的命令行客户端工具mysql来操作数据库,那如何在python程序中操作数据库呢? 这就用到了pymysql模块,该模块本质就是一个套接字客户端软件,使用前需要事先安装 pi ...
- java项目连接jdbc报错:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server
java项目连接jdbc报错:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not creat ...
- PHP操作Redis常用技巧
这篇文章主要介绍了PHP操作Redis常用技巧,结合实例形式总结分析了php针对redis的连接.认证.string.hash等操作技巧与注意事项,需要的朋友可以参考下 本文实例讲述了PHP操作Red ...
- 【Cocos2dx 3.3 Lua】剪裁结点ClippingNode
参考资料: http://shahdza.blog.51cto.com/2410787/1561937 http://blog.csdn.net/jackystudio/article/det ...
- XenServer:使用XenCenter开设VPS(多图完整版)
打铁要趁热,咱们接着来玩XenServer.昨天赵容用机房提供的KVM给服务器装了XenServer,今天我们来玩更有意思的:开小鸡.装好XenServer之后,访问我们的服务器IP,就可以看到Xen ...
- django登录功能(简单在POST请求)
第一 先在templates中创立index.html !DOCTYPE html> <head> <meta charset="UTF-8"> & ...
- DOM EVENT
属性 此事件发生在何时... onabort 图像的加载被中断. onblur 元素失去焦点. onchange 域的内容被改变. onclick 当用户点击某个对象时调用的事件句柄. ondblcl ...