drop解决过拟合的情况
用到的训练数据集:sklearn数据集
可视化工具:tensorboard,这儿记录了loss值(预测值与真实值的差值),通过loss值可以判断训练的结果与真实数据是否吻合
过拟合:训练过程中为了追求完美而导致问题
过拟合的情况:蓝线为实际情况,在误差为10的区间,他能够表示每条数据。
橙线为训练情况,为了追求0误差,他将每条数据都关联起来,但是如果新增一些点(+),他就不能去表示新增的点了

训练得到的值和实际测试得到的值相比,训练得到的loss更小,但它与实际不合,并不是loss值越小就越好
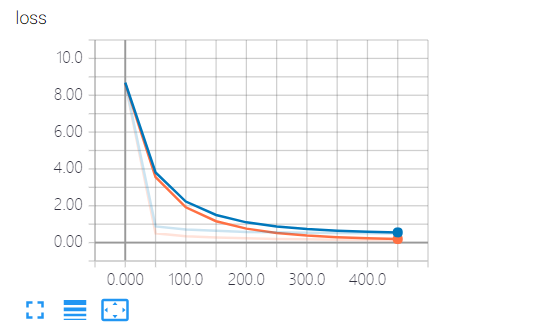

drop处理过拟合后:

代码:
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer # load data
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y) # 转换格式
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) def add_layer(inputs, in_size, out_size, layer_name, active_function=None):
"""
:param inputs:
:param in_size: 行
:param out_size: 列 , [行, 列] =矩阵
:param active_function:
:return:
"""
with tf.name_scope('layer'):
with tf.name_scope('weights'):
W = tf.Variable(tf.random_normal([in_size, out_size]), name='W') #
with tf.name_scope('bias'):
b = tf.Variable(tf.zeros([1, out_size]) + 0.1) # b是一行数据,对应out_size列个数据
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.matmul(inputs, W) + b
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob=keep_prob)
if active_function is None:
outputs = Wx_plus_b
else:
outputs = active_function(Wx_plus_b)
tf.summary.histogram(layer_name + '/outputs', outputs) # 1.2.记录outputs值,数据直方图
return outputs # define placeholder for inputs to network
keep_prob = tf.placeholder(tf.float32) # 不被dropout的数量
xs = tf.placeholder(tf.float32, [None, 64]) # 8*8
ys = tf.placeholder(tf.float32, [None, 10]) # add output layer
l1 = add_layer(xs, 64, 50, 'l1', active_function=tf.nn.tanh)
prediction = add_layer(l1, 50, 10, 'l2', active_function=tf.nn.softmax) # the loss between prediction and really
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1]))
tf.summary.scalar('loss', cross_entropy) # 字符串类型的标量张量,包含一个Summaryprotobuf 1.1记录标量(展示到直方图中 1.2 )
# training
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.Session()
merged = tf.summary.merge_all() # 2.把所有summary节点整合在一起,只需run一次,这儿只有cross_entropy
sess.run(tf.initialize_all_variables()) train_writer = tf.summary.FileWriter('log/train', sess.graph) # 3.写入
test_writer = tf.summary.FileWriter('log/test', sess.graph) # cmd cd到log目录下,启动 tensorboard --logdir=log\ # start training
for i in range(500):
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5}) # keep_prob训练时保留50%, 当这儿为1时,代表不drop任何数据,(没处理过拟合问题)
if i % 50 == 0:
# 4. record loss
train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1}) # tensorboard记录保留100%的数据
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1})
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i) print("Record Finished !!!")
drop解决过拟合的情况的更多相关文章
- 过拟合是什么?如何解决过拟合?l1、l2怎么解决过拟合
1. 过拟合是什么? https://www.zhihu.com/question/264909622 那个英文回答就是说h1.h2属于同一个集合,实际情况是h2比h1错误率低,你用h1来训练, ...
- tensorflow学习之路---解决过拟合
''' 思路:1.调用数据集 2.定义用来实现神经元功能的函数(包括解决过拟合) 3.定义输入和输出的数据4.定义隐藏层(函数)和输出层(函数) 5.分析误差和优化数据(改变权重)6.执行神经网络 ' ...
- L1与L2正则化的对比及多角度阐述为什么正则化可以解决过拟合问题
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- 解决谷歌浏览器在F12情况下自动断点问题(Paused in debugger)
解决谷歌浏览器在F12情况下自动断点问题(Paused in debugger) 最近在使用谷歌浏览器在调试js脚本的时候,每次按F12,再刷新页面,都会跳出如上图所示的图标,自动进入断点调试.如果不 ...
- 把cookie以json形式返回,用js来set cookie.(解决手机浏览器未知情况下获取不到cookie)
.继上一篇随笔,链接点我,解决手机端cookie的问题. .上次用cookie+redis实现了session,并且手机浏览器可能回传cookies有问题,所以最后用js取出cookie跟在请求的ur ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- RabbitMQ 使用QOS(服务质量)+Ack机制解决内存崩溃的情况
当消息有几万条或者几十万条的时候,如果消费的方式不对,会造成内存崩溃的情况 一:consumer 1. 短链接:basicget 独自去获取message... request 的方式去获取,断开式. ...
- 深度学习中 --- 解决过拟合问题(dropout, batchnormalization)
过拟合,在Tom M.Mitchell的<Machine Learning>中是如何定义的:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
随机推荐
- HDU1070:Milk
Milk Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- CTF-练习平台-Misc之 Linux基础1
十四.Linux基础1 下载打开文件,解压后发下是一个没有后缀名的文件,添加后缀名为txt,搜索关键词“KEY”,发现flag Linux???不存在的!
- (dfs痕迹清理兄弟篇)bfs作用效果的后效性
dfs通过递归将每种情景分割在不同的时空,但需要对每种情况对后续时空造成的痕迹进行清理(这是对全局变量而言的,对形式变量不需要清理(因为已经被分割在不同时空)) bfs由于不是利用递归则不能分割不同的 ...
- 【HAOI2014】贴海报
弱省中的弱省……原题: Bytetown城市要进行市长竞选,所有的选民可以畅所欲言地对竞选市长的候选人发表言论.为了统一管理,城市委员会为选民准备了一个张贴海报的electoral墙.张贴规则如下:1 ...
- 如何查看Eclipse的数字版的版本(转)
为什么叫数字版的版本,因为Eclipse软件里显示的是文字版的版本,比如我现在的就是Version: Indigo Release.这在下载插件的时候很不方便. 如何查看文字版的版本信息:打开Ecli ...
- android 学习过程中登陆失效的个人理解
今天在学习的过程中,要做登陆失效的功能,所以就找了些资料.好好看了一下.研究了一番,慢慢的做出来了! 比方:你在一个手机端登陆了账号,在另外的一个手机端也登陆了账号,此时.前一个手机端的账号会提示登陆 ...
- UOJ 188 【UR #13】Sanrd——min_25筛
题目:http://uoj.ac/problem/188 令 \( s(n,j)=\sum\limits_{i=1}^{n}[min_i>=p_j]f(j) \) ,其中 \( min_i \) ...
- npm 发包的简易流程
发包的简易流程: https://www.jianshu.com/p/ea64fd01679c 错误集锦: npm publish error: 403. You do not have permi ...
- js往div里添加table
$("#div").append("<table><tr align='center'>" +"<td >&quo ...
- maven教程基础
一.Maven介绍 我们在开发项目的过程中,会使用一些开源框架.第三方的工具等等,这些都是以jar包的方式被项目所引用,并且有些jar包还会依赖其他的jar包,我们同样需要添加到项目中,所有这些相关的 ...