【Deep Learning】Hinton. Reducing the Dimensionality of Data with Neural Networks Reading Note
2006年,机器学习泰斗、多伦多大学计算机系教授Geoffery Hinton在Science发表文章,提出基于深度信念网络(Deep Belief Networks, DBN)可使用非监督的逐层贪心训练算法,为训练深度神经网络带来了希望。
如果说Hinton 2006年发表在《Science》杂志上的论文[1]只是在学术界掀起了对深度学习的研究热潮,那么近年来各大巨头公司争相跟进,将顶级人才从学术界争抢到工业界,则标志着深度学习真正进入了实用阶段,将对一系列产品和服务产生深远影响,成为它们背后强大的技术引擎。
目前,深度学习在几个主要领域都获得了突破性的进展:在语音识别领域,深度学习用深层模型替换声学模型中的混合高斯模型(Gaussian Mixture Model, GMM),获得了相对30%左右的错误率降低;在图像识别领域,通过构造深度卷积神经网络(CNN)[3],将Top5错误率由26%大幅降低至15%,又通过加大加深网络结构,进一步降低到11%;在自然语言处理领域,深度学习基本获得了与其他方法水平相当的结果,但可以免去繁琐的特征提取步骤。可以说到目前为止,深度学习是最接近人类大脑的智能学习方法。
深层模型的训练难度
浅层模型的局限性在于有限参数和计算单元,对复杂函数的表示能力有限,针对复杂分类问题其泛化能力受到一定的制约。深层模型恰恰可以克服浅层模型的这一弱点,然而应用反向传播和梯度下降来训练深层模型,就面临几个突出的问题:
- 梯局部最优。与浅层模型的代价函数不同,深层模型的每个神经元都是非线性变换,代价函数是高度非凸函数,采用梯度下降的方法容易陷入局部最优。
- 梯度弥散。使用反向传播算法传播梯度的时候,随着传播深度的增加,梯度的幅度会急剧减小,会导致浅层神经元的权重更新非常缓慢,不能有效学习。这样一来,深层模型也就变成了前几层相对固定,只能改变最后几层的浅层模型。
- 数据获取。深层模型的表达能力强大,模型的参数也相应增加。对于训练如此多参数的模型,小训练数据集是不能实现的,需要海量的有标记的数据,否则只能导致严重的过拟合(Over fitting)。
2006年,Hinton在《Science》上发表了一篇文章,掀起了深度学习在学术界和工业界的浪潮。这篇文章的两个主要观点是:
1、多隐藏层的人工神经网络具有优异的特征学习能力,学习到的特征对数据有更本质的刻画,从而有利于可视化或分类。
为什么要构造包含这么多隐藏层的深层网络结构呢?对于很多训练任务来说,特征具有天然的层次结构。以语音、图像、文本为例,层次结构大概如下表所示。
表1 几种任务领域的特征层次结构

以图像识别为例,图像的原始输入是像素,相邻像素组成线条,多个线条组成纹理,进一步形成图案,图案构成了物体的局部,直至整个物体的样子。不难发现,可以找到原始输入和浅层特征之间的联系,再通过中层特征,一步一步获得和高层特征的联系。想要从原始输入直接跨越到高层特征,无疑是困难的。
2、深度神经网络在训练上的难度,可以通过“逐层初始化”(Layer-wise Pre-training)来有效克服,文中给出了无监督的逐层初始化方法。
图7 逐层初始化的方法
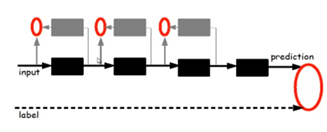
给定原始输入后,先要训练模型的第一层,即图中左侧的黑色框。黑色框可以看作是一个编码器,将原始输入编码为第一层的初级特征,可以将编码器看作模型的一种“认知”。为了验证这些特征确实是输入的一种抽象表示,且没有丢失太多信息,需要引入一个对应的解码器,即图中左侧的灰色框,可以看作模型的“生成”。为了让认知和生成达成一致,就要求原始输入通过编码再解码,可以大致还原为原始输入。因此将原始输入与其编码再解码之后的误差定义为代价函数,同时训练编码器和解码器。训练收敛后,编码器就是我们要的第一层模型,而解码器则不再需要了。这时我们得到了原始数据的第一层抽象。固定第一层模型,原始输入就映射成第一层抽象,将其当作输入,如法炮制,可以继续训练出第二层模型,再根据前两层模型训练出第三层模型,以此类推,直至训练出最高层模型。
逐层初始化完成后,就可以用有标签的数据,采用反向传播算法对模型进行整体有监督的训练了。这一步可看作对多层模型整体的精细调整。由于深层模型具有很多局部最优解,模型初始化的位置将很大程度上决定最终模型的质量。“逐层初始化”的步骤就是让模型处于一个较为接近全局最优的位置,从而获得更好的效果。
浅层模型和深层模型的对比
浅层模型有一个重要的特点,需要依靠人工经验来抽取样本的特征,模型的输入是这些已经选取好的特征,模型只用来负责分类和预测。在浅层模型中,最重要的往往不是模型的优劣,而是特征的选取的优劣。因此大多数人力都投入到特征的开发和筛选中来,不但需要对任务问题领域有深刻的理解,还要花费大量时间反复实验摸索,这也限制了浅层模型的效果。
事实上,逐层初始化深层模型也可以看作是特征学习的过程,通过隐藏层对原始输入的一步一步抽象表示,来学习原始输入的数据结构,找到更有用的特征,从而最终提高分类问题的准确性。在得到有效特征之后,模型整体训练也可以水到渠成。
【Deep Learning】Hinton. Reducing the Dimensionality of Data with Neural Networks Reading Note的更多相关文章
- Deep Learning 16:用自编码器对数据进行降维_读论文“Reducing the Dimensionality of Data with Neural Networks”的笔记
前言 论文“Reducing the Dimensionality of Data with Neural Networks”是深度学习鼻祖hinton于2006年发表于<SCIENCE > ...
- Reducing the Dimensionality of data with neural networks / A fast learing algorithm for deep belief net
Deeplearning原文作者Hinton代码注解 Matlab示例代码为两部分,分别对应不同的论文: . Reducing the Dimensionality of data with neur ...
- 一天一经典Reducing the Dimensionality of Data with Neural Networks [Science2006]
别看本文没有几页纸,本着把经典的文多读几遍的想法,把它彩印出来看,没想到效果很好,比在屏幕上看着舒服.若用蓝色的笔圈出重点,这篇文章中几乎要全蓝.字字珠玑. Reducing the Dimensio ...
- 【神经网络】Reducing the Dimensionality of Data with Neural Networks
这篇paper来做什么的? 用神经网络来降维.之前降维用的方法是主成分分析法PCA,找到数据集中最大方差方向.(附:降维有助于分类.可视化.交流和高维信号的存储) 这篇paper提出了一种非线性的PC ...
- Reducing the Dimensionality of Data with Neural Networks:神经网络用于降维
原文链接:http://www.ncbi.nlm.nih.gov/pubmed/16873662/ G. E. Hinton* and R. R. Salakhutdinov . Science. ...
- 论文阅读---Reducing the Dimensionality of Data with Neural Networks
通过训练多层神经网络可以将高维数据转换成低维数据,其中有对高维输入向量进行改造的网络层.梯度下降可以用来微调如自编码器网络的权重系数,但是对权重的初始化要求比较高.这里提出一种有效初始化权重的方法,允 ...
- Reducing the Dimensionality of Data with Neural Networks
****************内容加密中********************
- 【Deep Learning】一、AutoEncoder
Deep Learning 第一战: 完成:UFLDL教程 稀疏自编码器-Exercise:Sparse Autoencoder Code: 学习到的稀疏参数W1: 参考资料: UFLDL教程 稀疏自 ...
- 【Deep Learning】genCNN: A Convolutional Architecture for Word Sequence Prediction
作者:Mingxuan Wang.李航,刘群 单位:华为.中科院 时间:2015 发表于:acl 2015 文章下载:http://pan.baidu.com/s/1bnBBVuJ 主要内容: 用de ...
随机推荐
- 修改的select
慢慢修改: #include <winsock.h> #include <stdio.h> #include <string> #define PORT 5010 ...
- 1503: [NOI2004]郁闷的出纳员 (SBT)
1503: [NOI2004]郁闷的出纳员 http://www.lydsy.com/JudgeOnline/problem.php?id=1503 Time Limit: 5 Sec Memory ...
- linux系统yum方式安装htop命令[转]
CentOS下为yum加入rpmForge源,使用yum安装htop 为CentOS增加rpmForge软件源 wget http://pkgs.repoforge.org/rpmforge-rele ...
- iOS11新特性之LargeTitle
UI风格 在iOS 11中,系统APP使用了这种UI风格.这种风格最明显的变化就是使用了iOS 11的新特性--Large Title和新的SearchController. Demo GitHub: ...
- Fastjson是一个Java语言编写的高性能功能完善的JSON库。
简介 Fastjson是一个Java语言编写的高性能功能完善的JSON库. 高性能 fastjson采用独创的算法,将parse的速度提升到极致,超过所有json库,包括曾经号称最快的jackson. ...
- Oracle 12C -- shutdown CDB
SQL> select name,open_mode from v$pdbs; NAME OPEN_MODE ------------------------------ ---------- ...
- windows系统如何通过Xshell 客户端连接 linux系统(主要介绍ubuntu系统)
一. 1.查看ubuntu系统的ip地址:ifconfig 在window系统运行窗口下:ping ubuntu系统的IP地址:例如:ping 192.168.163.129 出现下述命令就是ping ...
- django性能优化缓存view详解
缓存提升性能: 1.通常的view会去数据库端执行相关的查询然后交由template渲染.数据库访问通常就是性能的瓶颈所在. 2.由于许多数据要很久才会变一次.两次连续的数据库访问通常返回的数据是一样 ...
- debian linux 下设置开机自启动
懒得写了,一张图简单明了.其实很简单,一开始没有加上nohup有点问题.现在问题已解决.
- Spring Security教程(四):自定义登录页
在前面的例子中,登陆页面都是用的Spring Security自己提供的,这明显不符合实际开发场景,同时也没有退出和注销按钮,因此在每次测试的时候都要通过关闭浏览器来注销达到清除session的效果. ...