scrapy微信爬虫使用总结
scrapy+selenium+Chrome+微信公众号爬虫
概述
1、微信公众号爬虫思路:
2、scrapy框架图
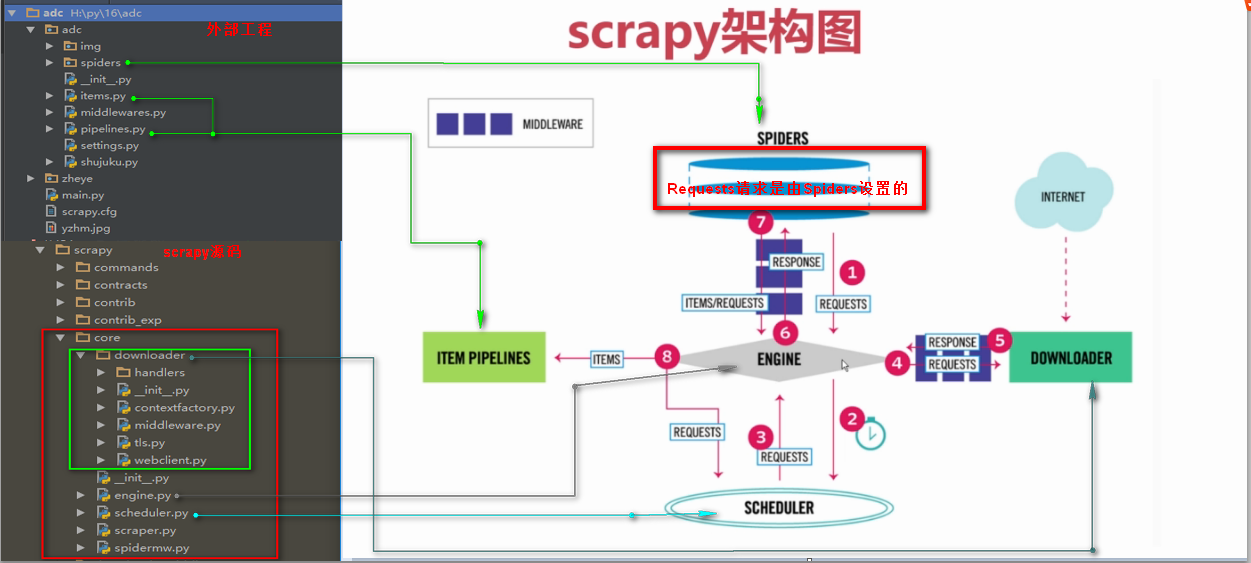
3、scrapy经典教程
参考:
4、其它
参考:
实践
1、环境的安装
- selenium安装(pip install selenium)
- chromedriver安装(注意与chrome版本兼容问题)
- beautifulsoup4
- scrapy
- MongoDB、pymongo
MongoDB:
具体命令如下:
python连接MongoDB,需安装pip install mongoengine
启动:
sudo ./mongod --port 27017 dbpath "/software/mongodb-4.0.0/data/db" --logpath "/software/mongodb-4.0.0/log/mongodb.log" --logappend --replSet rs0
Windows下MongoDB数据导出:
mongodump --port 27017 -d wechat -o D:\MongoDB
Linux下MongoDB数据导入:
./mongorestore -h 127.0.0.1 --port 27017 -d wechat --drop /software/mongodb-4.0.0/wechat
数据导入时注意:
Do you run mongo in replica set, i.e., mongod --replSet rs0?
If yes, please remember to run in your mongo shell the command: rs.initiate()
参考:
2、cookie获取
selenium进行登录验证,保存cookies,为scrapy做准备。
3、爬虫
- cookies:scrapy spider初始化函数调用Chromedriver,并获取cookies
- 定位:spider初始化函数利用Chromedriver定位到需要抓取的页面
- 解析:parse函数处理Chromedriver自动定scrapy爬虫利用selenium实现用户登录和cookie传递位的页面信息,以及下一页URL
- 保存:scrapy配置MongoDB保存数据
参考:
scrapy爬虫利用selenium实现用户登录和cookie传递
4、django调用爬虫
5、django构建搜索引擎,搜索爬过的信息
参考:
环境配置:
elasticsearch-rtf安装、pip install mongo-connector、pip install mongo-connector[elastic5]、pip install elastic2-doc-manager
MongoDB数据同步到elasticsearch:
mongo-connector -m localhost:27017 -t localhost:9200 -d elastic2_doc_manager
其它问题
1、selenium在新页面定位元素问题
参考:
解决Selenium弹出新页面无法定位元素问题(Unable to locate element)
3、在管道中关闭爬虫
spider.crawler.engine.close_spider(spider, 'bandwidth_exceeded')
scrapy微信爬虫使用总结的更多相关文章
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- Scrapy创建爬虫项目
1.打开cmd命令行工具,输入scrapy startproject 项目名称 2.使用pycharm打开项目,查看项目目录 3.创建爬虫,打开CMD,cd命令进入到爬虫项目文件夹,输入scrapy ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- 【Python爬虫实战】微信爬虫
所谓微信爬虫,即自动获取微信的相关文章信息的一种爬虫.微信对我们的限制是很多的,所以我们需要采取一些手段解决这些限制主要包括伪装浏览器.使用代理IP等方式http://weixin.sogou.com ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- Adobe Illustrator CS6 界面文字按钮太小,高分屏win10PS/AI等软件界面字太小解决方法
Adobe Illustrator CS6 界面文字按钮太小,高分屏win10PS/AI等软件界面字太小解决方法 Adobe App Scaling on High DPI Displays (FIX ...
- Centos7下PHP的卸载与安装nginx
Centos7下PHP的卸载与安装nginx CentOS上PHP完全卸载,想把PHP卸载干净,直接用yum的remove命令是不行的,需要查看有多少rpm包,然后按照依赖顺序逐一卸载. 1.首先查看 ...
- python之路----logging模块
函数式简单配置 import logging logging.debug('debug message') #bug logging.info('info message') #信息 logging. ...
- 20145324王嘉澜《网络对抗技术》MSF基础应用
实践目标 •掌握metasploit的基本应用方式 •掌握常用的三种攻击方式的思路. 实验要求 •一个主动攻击,如ms08_067 •一个针对浏览器的攻击,如ms11_050 •一个针对客户端的攻击, ...
- 20165310 java_blog_week2
2165310 <Java程序设计>第2周学习总结 教材学习内容总结 了解Java变量 重点学习Boolean变量和类型转换规则 学习数组定义.使用方式 区别: int [] a,b [] ...
- 把json的字符串变为json对象
如{"tag":"sendcode","data":{"phone":"18880488738"}} ...
- MVC 学习
基础概念学习:http://www.cnblogs.com/meetyy/p/3451933.html 路由:http://www.cnblogs.com/meetyy/p/3453189.html ...
- Python3基础 list remove 删除元素
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- Django组件(二) Django之Form
Forms组件概述 forms组件 -Django提供的用语数据校验和模板渲染的组件 -在项目中创建一个py文件 -1 写一个类继承Form -2 在类中写属性,写的属性,就是要校验的字段 -3 使用 ...
- Wireshark 捕捉本地数据 --WinPcap切换NPcap
Wireshark默认匹配安装的是WinPcap,但是WinPcap有个缺点,不能抓取本地回环数据 NPcap是在WinPcap的基础上进行优化开发的,可以抓取本地数据 如果已安装WinPcap的请卸 ...