keras—多层感知器MLP—IMDb情感分析
import urllib.request
import os
import tarfile
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
import re
def rm_tags(text):
re_tag=re.compile(r'<[^>]+>')
return re_tag.sub('',text)
def read_files(filetype):
path="C:/Users/admin/.keras/aclImdb/"
file_list=[]
positive_path=path+filetype+"/pos/"
for f in os.listdir(positive_path):
file_list+=[positive_path+f]
negative_path=path+filetype+"/pos/"
for f in os.listdir(negative_path):
file_list+=[negative_path+f]
print('read',filetype,'files:',len(file_list))
all_labels=([]*+[]*)
all_texts=[]
for fi in file_list:
with open(fi,encoding='utf8') as file_input:
all_texts+=[rm_tags(" ".join(file_input.readlines()))]
return all_labels,all_texts
y_train,train_text=read_files("train")
y_test,test_text=read_files("test")
print(train_text[])
print(y_train[])
token=Tokenizer(num_words=)
token.fit_on_texts(train_text)
print(token.document_count)
print(token.word_index)
x_train_seq=token.texts_to_sequences(train_text)
x_test_seq=token.texts_to_sequences(test_text)
print(train_text[])
print(x_train_seq[])
x_train=sequence.pad_sequences(x_train_seq,maxlen=)
x_test=sequence.pad_sequences(x_test_seq,maxlen=)
print('before pad_sequences lenfth=',len(x_train_seq[]))
print(x_train_seq[])
print('after pad_sequences lenfth=',len(x_train[]))
print(x_train[])
from keras.models import Sequential
from keras.layers import Dense,Dropout,Flatten,Activation
from keras.layers.embeddings import Embedding
model=Sequential()
model.add(Embedding(output_dim=,
input_dim=,
input_length=))
model.add(Dropout(0.2))
#model.add(SimpleRNN(units=))
model.add(Flatten())
model.add(Dense(units=,
activation='relu'))
model.add(Dropout(0.35))
model.add(Dense(units=,
activation='sigmoid'))
print(model.summary())
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history=model.fit(x=x_train,y=y_train,batch_size=,
epochs=,verbose=,
validation_split=0.2)
scores=model.evaluate(x_test,y_test,verbose=)
print('accuracy',scores[])
predict=model.predict_classes(x_test)
print("prediction[:10]",predict[:])
predict_classes=predict.reshape(-)
print(predict_classes[:])
SentimentDict = {: '正面的', : '负面的'}
def display_test_Sentiment(i):
print(test_text[i])
print('label真实值:', SentimentDict[y_test[i]],
'预测结果:', SentimentDict[predict_classes[i]])
display_test_Sentiment()
input_text='''
I saw this film with my -year-old a couple weeks ago. While there's plenty about which to gripe, here's one of
my biggest problems: I can't stand this constant CGI-heavy everything-must-be-a-sequel-or- a- remake era of film
making. It's making movie makers lazy.
'''
input_seq=token.texts_to_sequences([input_text])
len(input_seq[])
print(input_seq[])
pad_input_seq=sequence.pad_sequences(input_seq,maxlen=)
len(pad_input_seq[])
print(pad_input_seq[])
predict_result=model.predict_classes(pad_input_seq)
print(predict_result)
print(predict_result[][])
print(SentimentDict[predict_result[][]])
def predict_review(input_text):
input_seq=token.texts_to_sequences([input_text])
pad_input_seq=sequence.pad_sequences(input_seq,maxlen=)
predict_result=model.predict_classes(pad_input_seq)
print(SentimentDict[predict_result[][]]) predict_review('''
They poured on the whole "LeFou is gay" thing a bit thick for my taste. It was the only thing that added levity to the movie (despite how much fun it should have been already), but it seemed a bit cheap. I'm not going to apologize for wanting more for my LGBTQ characters than to be just the comic relief.
''')

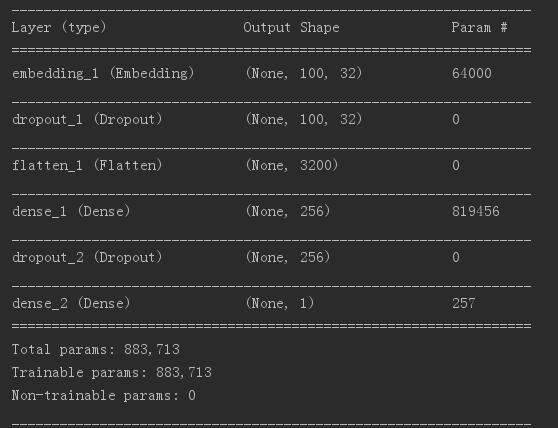
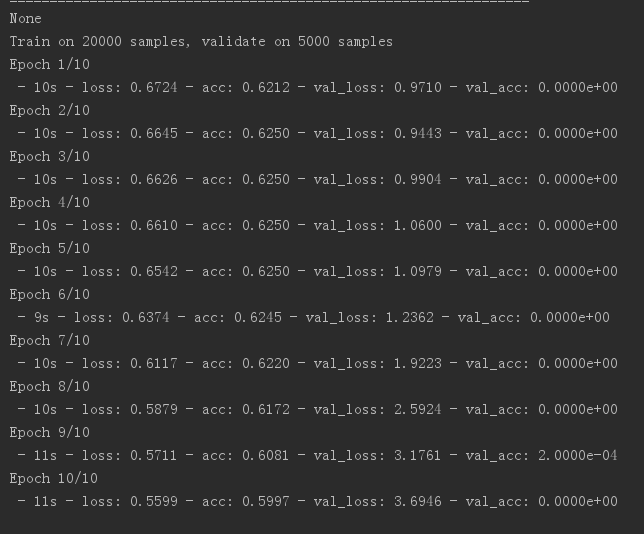
验证的准确率为0问题待解决
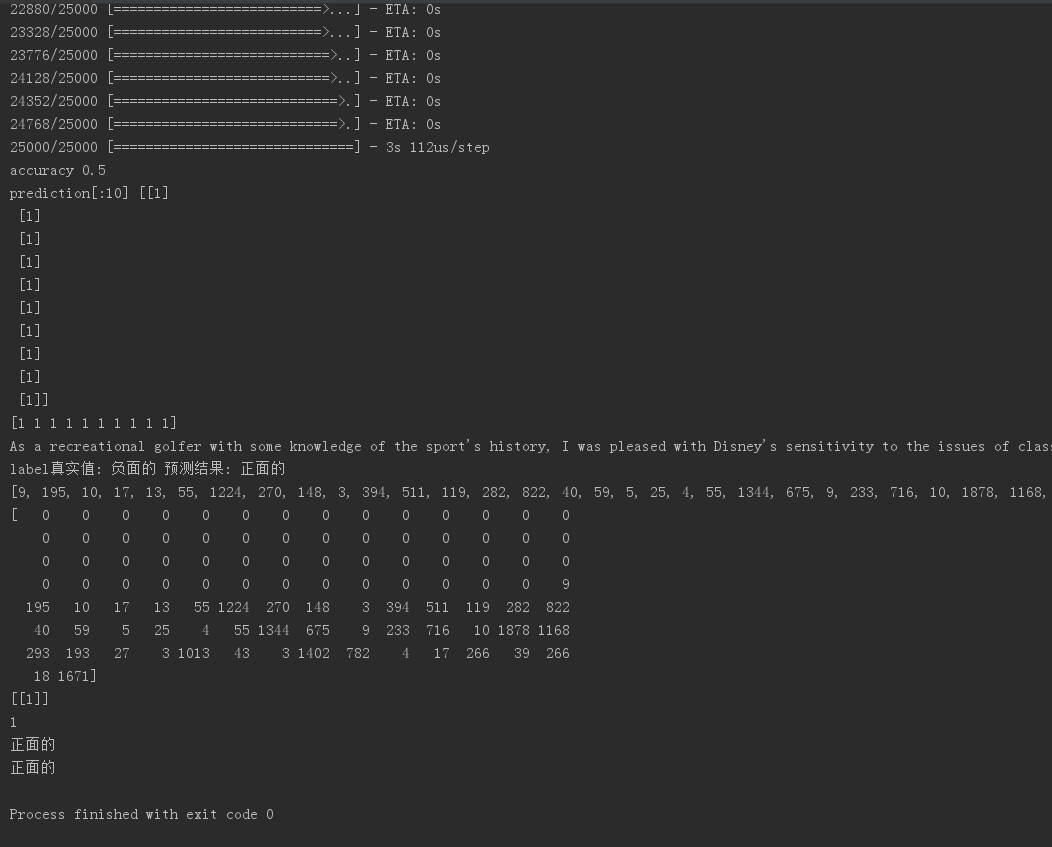
keras—多层感知器MLP—IMDb情感分析的更多相关文章
- keras—多层感知器MLP—MNIST手写数字识别
一.手写数字识别 现在就来说说如何使用神经网络实现手写数字识别. 在这里我使用mind manager工具绘制了要实现手写数字识别需要的模块以及模块的功能: 其中隐含层节点数量(即神经细胞数量)计算 ...
- 4.2tensorflow多层感知器MLP识别手写数字最易懂实例代码
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: https://www.cnblogs.com/bclshuai/p/11380657.html 1.1 多层感知器MLP(m ...
- "多层感知器"--MLP神经网络算法
提到人工智能(Artificial Intelligence,AI),大家都不会陌生,在现今行业领起风潮,各行各业无不趋之若鹜,作为技术使用者,到底什么是AI,我们要有自己的理解. 目前,在人工智能中 ...
- TFboy养成记 多层感知器 MLP
内容总结与莫烦的视频. 这里多层感知器代码写的是一个简单的三层神经网络,输入层,隐藏层,输出层.代码的目的是你和一个二次曲线.同时,为了保证数据的自然,添加了mean为0,steddv为0.05的噪声 ...
- MLPclassifier,MLP 多层感知器的的缩写(Multi-layer Perceptron)
先看代码(sklearn的示例代码): from sklearn.neural_network import MLPClassifier X = [[0., 0.], [1., 1.]] y = [0 ...
- 神经网络与机器学习 笔记—多层感知器(MLP)
多层感知器(MLP) Rosenblatt感知器和LMS算法,都是单层的并且是单个神经元构造的神经网络,他们的局限性是只能解决线性可分问题,例如Rosenblatt感知器一直没办法处理简单异或问题.然 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- 使用TensorFlow v2.0构建多层感知器
使用TensorFlow v2.0构建一个两层隐藏层完全连接的神经网络(多层感知器). 这个例子使用低级方法来更好地理解构建神经网络和训练过程背后的所有机制. 神经网络概述 MNIST 数据集概述 此 ...
- Spark Multilayer perceptron classifier (MLPC)多层感知器分类器
多层感知器分类器(MLPC)是基于前馈人工神经网络(ANN)的分类器. MLPC由多个节点层组成. 每个层完全连接到网络中的下一层. 输入层中的节点表示输入数据. 所有其他节点,通过输入与节点的权重w ...
随机推荐
- Mybatis学习(4)输入映射、输出映射、动态sql
一.输入映射: 通过parameterType指定输入参数的类型,类型可以是简单类型.hashmap.pojo的包装类型 1) 传递pojo的包装对象 需求是:完成用户信息的综合查询,传入的查询条件复 ...
- Makefile | Linux嵌入式编程 使用详细图解
针对的是对Makefile一点都不会的小白哦! 练习之前我们要做好准备: (1):第一步创建一个目录,因为实验过程中生成的文件会很多,不要把你系统里的文件搞得乱七八糟. [cjj@bogon ~]$ ...
- tomcat 乱码问题
页面提交都是utf8编码进后台,但是后台入库有些中文数据是正常,有些是乱码,可以完全排除数据库层面的问题 比较一下正常和异常的http请求,一个是Get,一个是Post, 原因就找到了 tomcat4 ...
- 1108 Finding Average (20 分)
1108 Finding Average (20 分) The basic task is simple: given N real numbers, you are supposed to calc ...
- IaaS,PaaS,SaaS 的区别和联系
原文:http://www.ruanyifeng.com/blog/2017/07/iaas-paas-saas.html 越来越多的软件,开始采用云服务. 云服务只是一个统称,可以分成三大类. Ia ...
- [UE4]蓝图Get Control Rotation获取人物角色朝向,设置默认人物相机,朝向与controller绑定
具体应用:控制人物移动方向 也可以使用“CombineRotators”将角色控制器Z轴旋转90°,然后再取正面方向,达到跟“Get Right Vector”一样的效果: 设置关联人物朝向使用控制器 ...
- Parallel I/O and Columnar Storage
Parallel I/O and Columnar Storage We begin with a high level overview of the system while follow up ...
- MySQL数据库储存引擎Inoodb一--记录储存结构
在开文我先说明一下,接下来的数据库知识文章都是在微信公众号“我们都是小青蛙”学习然后在通过自己的理解进行书写的.有兴趣的朋友可以去关注这个微信公众号.话不多说,我们在日常使用数据库进行数据持 久化的时 ...
- 并发基础(二) Thread类的API总结
Thread 类是java中的线程类,提供给用户用于创建.操作线程.获取线程的信息的类.是java线程一切的基础,掌握这个类是非常必须的,先来看一下它的API: 1.字段摘要 static int M ...
- jmeter-noguimodel
jmeter -Dthreads= -n -t ~/Desktop/image-controller.jmx -l myimage/out -e -o myimage/log -j myimage/r ...