2.keras实现-->字符级或单词级的one-hot编码 VS 词嵌入
1. one-hot编码
# 字符集的one-hot编码 characters= '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVW XYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c' |

|
# keras实现单词级的one-hot编码 |
sequences = [[2, 3, 4, 1], 发现10个unique标记 word_index = {'pig': 1, 'zzh': 2, 'is': 3, 'a': 4, 'he': 5,
|
one-hot 编码的一种办法是 one-hot散列技巧(one-hot hashing trick)如果词表中唯一标记的数量太大而无法直接处理,就可以使用这种技巧。这种方法没有为每个单词显示的分配一个索引并将这些索引保存在一个字典中,而是将单词散列编码为固定长度的向量,通常用一个非常简单的散列函数来实现。 优点:节省内存并允许数据的在线编码(读取完所有数据之前,你就可以立刻生成标记向量) 缺点:可能会出现散列冲突 如果散列空间的维度远大于需要散列的唯一标记的个数,散列冲突的可能性会减小 |
|
import numpy as np samples = ['the cat sat on the mat the cat sat on the mat the cat sat on the mat','the dog ate my homowork'] |

|
2. 词嵌入
获取词嵌入的两种方法:
- 在完成主任务的同时学习词嵌入。在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,其学习方式与学习神经网络的权重相同。
- 在不同于待解决的机器学习任务上预计算好词嵌入,然后将其加载到模型中。这些词嵌入叫作预训练词嵌入
实验数据:imdb电影评论,我们添加了以下限制,将训练数据限定为200个样本(打乱顺序)。

| (1)使用embedding层学习词嵌入 | |
# 处理imdb原始数据的标签 |
len(texts)=25000 len(labels)=25000 |
# 对imdb原始数据的文本进行分词 |
sequence[0]
|
|
word_index = tokenizer.word_index |
#88592个unique单词 word_index
|
|
data = pad_sequences(sequences,maxlen=max_len) |
data.shape = (25000,100) data[0]
|
|
labels = np.asarray(labels) |
#asarray会跟着原labels的改变,算是浅拷贝吧, |
|
indices = np.arange(data.shape[0]) np.random.shuffle(indices) |
indices array([ 2501, 4853, 2109, ..., 2357, 22166, 12397]) |
#将data,label打乱顺序 |
x_val.shape,y_val.shape (10000, 100) (10000,) |
#2014年英文维基百科的预计算嵌入:Glove词嵌入(包含400000个单词) |
len(embeddings_index) 400000 |
#准备glove词嵌入矩阵 |
把数据集里面的单词在glove中找到对应的词向量,组成embedding_matrix, 若在glove中不存在,那就为0向量 |
#定义模型 |

|
model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['acc']) |
|
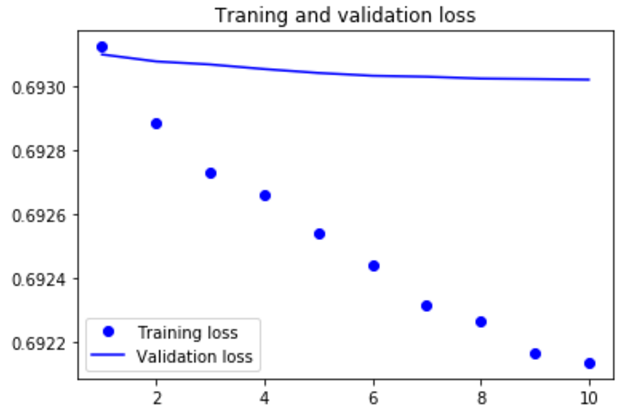
import matplotlib.pyplot as plt acc = history.history['acc'] |
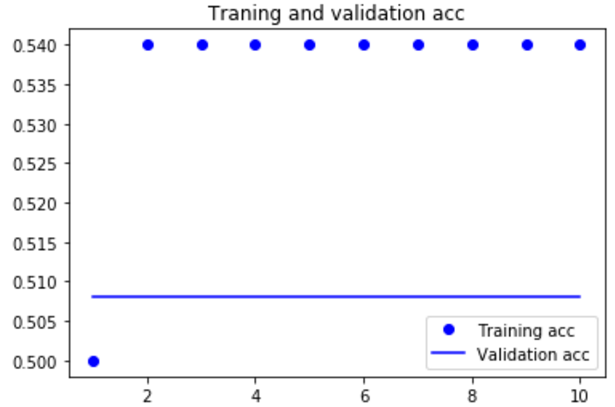
|
模型很快就开始过拟合,考虑到训练样本很少,这也很情有可原的 |


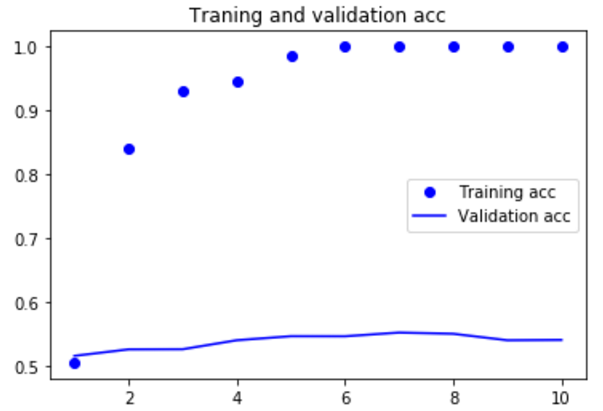
| (2)下面在不使用预训练词嵌入的情况下,训练相同的模型 | |
#定义模型 |

|
import matplotlib.pyplot as plt acc = history.history['acc'] |
|
#在测试集上评估模型 test_dir = os.path.join(imdb_dir,'test') labels = [] |
|
|
model.load_weights('pre_trained_glove_model.h5') model.evaluate(x=x_test,y=y_test) |
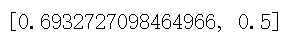 |
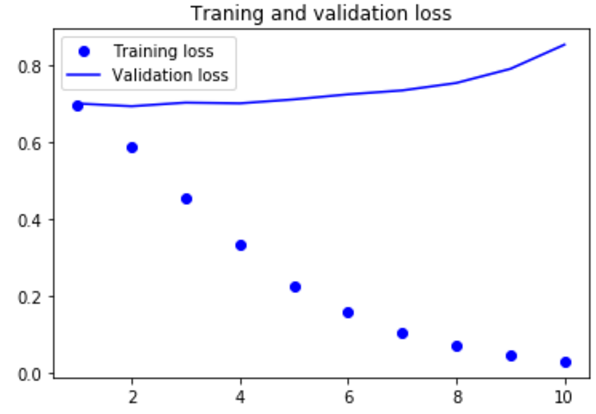
如果增加训练集样本的数量,可能使用词嵌入得到的效果会好很多。
2.keras实现-->字符级或单词级的one-hot编码 VS 词嵌入的更多相关文章
- 51nod图论题解(4级,5级算法题)
51nod图论题解(4级,5级算法题) 1805 小树 基准时间限制:1.5 秒 空间限制:131072 KB 分值: 80 难度:5级算法题 她发现她的树的点上都有一个标号(从1到n),这些树都在空 ...
- Linux学习笔记(三):系统执行级与执行级的切换
1.Linux系统与其它的操作系统不同,它设有执行级别.该执行级指定操作系统所处的状态.Linux系统在不论什么时候都执行于某个执行级上,且在不同的执行级上执行的程序和服务都不同,所要完毕的工作和所要 ...
- codewar代码练习1——8级晋升7级
最近发现一个不错的代码练习网站codewar(http://www.codewars.com).注册了一个账号,花了几天的茶余饭后时间做题,把等级从8级升到了7级.本文的目的主要介绍使用感受及相应题目 ...
- [数据库事务与锁]详解五: MySQL中的行级锁,表级锁,页级锁
注明: 本文转载自http://www.hollischuang.com/archives/914 在计算机科学中,锁是在执行多线程时用于强行限制资源访问的同步机制,即用于在并发控制中保证对互斥要求的 ...
- MySQL行级锁,表级锁,页级锁详解
页级:引擎 BDB. 表级:引擎 MyISAM , 理解为锁住整个表,可以同时读,写不行 行级:引擎 INNODB , 单独的一行记录加锁 表级,直接锁定整张表,在你锁定期间,其它进程无法对该表进行写 ...
- 行为级和RTL级的区别(转)
转自:http://hi.baidu.com/renmeman/item/5bd83496e3fc816bf14215db RTL级,registertransferlevel,指的是用寄存器这一级别 ...
- CSS 各类 块级元素 行级元素 水平 垂直 居中问题
元素的居中问题是每个初学者碰到的第一个大问题,在此我总结了下各种块级 行级 水平 垂直 的居中方法,并尽量给出代码实例. 首先请先明白块级元素和行级元素的区别 行级元素 一块级元素 1 水平居中: ( ...
- 【数据库】数据库的锁机制,MySQL中的行级锁,表级锁,页级锁
转载:http://www.hollischuang.com/archives/914 数据库的读现象浅析中介绍过,在并发访问情况下,可能会出现脏读.不可重复读和幻读等读现象,为了应对这些问题,主流数 ...
- MySQL中的行级锁,表级锁,页级锁
在计算机科学中,锁是在执行多线程时用于强行限制资源访问的同步机制,即用于在并发控制中保证对互斥要求的满足. 在数据库的锁机制中介绍过,在DBMS中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引 ...
随机推荐
- 深入理解 Neutron -- OpenStack 网络实现(3):VXLAN 模式
问题导读1.VXLAN 模式下,网络的架构跟 GRE 模式类似,他们的不同点在什么地方?2.网络节点的作用是什么?3.tap-xxx.qr-xxx是指什么? 接上篇:深入理解 Neutron -- O ...
- eclipse中改变默认的workspace的方法
1.File-->Switch Workspace-->Other 2.Window-->Preferences-->General-->Startup and Shui ...
- windows下php使用protobuf
1.下载protobufc https://github.com/google/protobuf/releases/download/v3.5.0/protoc-3.5.0-win32.zip解压后放 ...
- Hive学习之数据去重
insert overwrite table store select t.p_key,t.sort_word from ( select p_key, sort_word , row_number( ...
- 最小生成树(prime算法 & kruskal算法)和 最短路径算法(floyd算法 & dijkstra算法)
一.主要内容: 介绍图论中两大经典问题:最小生成树问题以及最短路径问题,以及给出解决每个问题的两种不同算法. 其中最小生成树问题可参考以下题目: 题目1012:畅通工程 http://ac.jobdu ...
- VC++ 学习笔记2 列表框添加字符串
向列表框添加字符串 现在知道两种方法 方法一:直接在需要添加内容地方输入下面代码 IDC_LIST1为需要添加列表框的ID号 改为你的 ((CListBox*)GetDlgItem(IDC_LIST ...
- iOS interface适配
- 【笔记】javascript权威指南-第二章-词法结构
词法结构 //本书是指:javascript权威指南 //以下内容摘记时间为:2013.7.28 字符集 UTF-8和UTF-16的区别?Unicode和UTF是什么关系?Unicode转义 ...
- undefined类型
undefined类型 只有一个特殊的值 undefined 在使用var声明变量但未对其加以初始化,这个变量的值就是undefined 值是undefined的情况: 1.显示声明并初始化变量值 ...
- DLRS(近三年深度学习应用于推荐系统论文汇总)
Recommender Systems with Deep Learning Improving Scalability of Personalized Recommendation Systems ...