2.2CUDA-Memory(存储)和bank-conflict
在CUDA基本概念介绍有简单介绍CUDA memory。这里详细介绍:
每一个线程拥有自己的私有存储器,每一个线程块拥有一块共享存储器(Shared memory);最后,grid中所有的线程都可以访问同一块全局存储器(global memory)。除此之外,还有两种可以被所有线程访问的只读存储器:常数存储器(constant memory)和纹理存储器(Texture memory),它们分别为不同的应用进行了优化。全局存储器、常数存储器和纹理存储器中的值在一个内核函数执行完成后将被继续保持,可以被同一程序中其也内核函数调用。
下表给出了这8种存储器的位置、缓存情况,访问权限及生存域
|
存储器 |
位置 |
拥有缓存 |
访问权限 |
变量生存周期 |
|
register |
GPU片内 |
N/A |
Device可读/写 |
与thread相同 |
|
Local memory |
板载显存 |
无 |
Device可读/写 |
与thread相同 |
|
Shared memory |
GPU片内 |
N/A |
Device可读/写 |
与block相同 |
|
Constant memory |
板载显存 |
有 |
Device可读,host可读写 |
可在程序中保持 |
|
Texture memory |
板载显存 |
有 |
Device可读,host可读写 |
可在程序中保持 |
|
Global memory |
板载显存 |
无 |
Device可读/写, host可读/写 |
可在程序中保持 |
|
Host memory |
Host内存 |
无 |
host可读/写 |
可在程序中保持 |
|
Pinned memory |
Host内存 |
无 |
host可读/写 |
可在程序中保持 |
kernel变量定义,使用范围和生命周期。
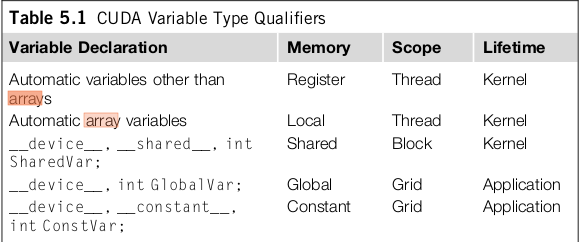
其中__shared__和__constant__前面的__device__声明是可以省略的
Global memory, 如果有一个thread修改啦global memory的值,其他的thread不能立即看到这个值的变化。需要终止这个kernel,然后lanuch一个新的kernel,这样新的kernel能看到global memory的变化。
Shared Memory(共享存储)
由于访问速度比Global快的多,比如向量加法,每次从in指针里面取内容都是从global里面取。比如矩阵乘法:
__global__ void MatrixMulKernel(int m, int n, int k, float* A, float*
B, float* C)
{
int Row = blockIdx.y*blockDim.y+threadIdx.y;
int Col= blockIdx.x*blockDim.x+threadIdx.x;
if ((Row < m) && (Col < k)) {
float Cvalue = 0.0;
for (int i = ; i < n; ++i)
/* A[Row, i] and B[i, Col] */
Cvalue += A[Row*n+i] * B[Col+i*k];
C[Row*k+Col] = Cvalue;
}
}
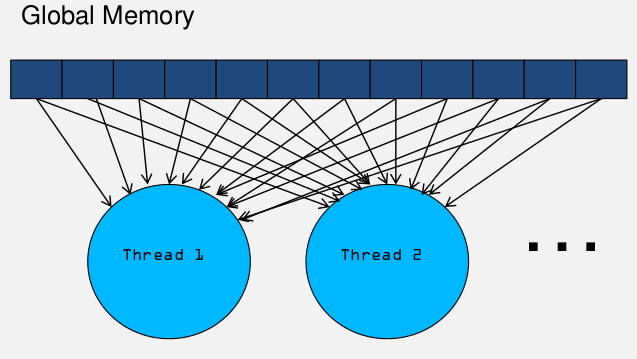
可以看到有很多值取拉多次,重复多次访问global memory。我们可以把需要用的数据保存在shared memory中,如下图:

减少啦访问的次数,而且访问shared memory 速度更快
总结一个公共的编程策略模型:
当我们在划分存储数据时经常划分成很多块,或者是tile,在这里称作 partition data or tile data.
1. 把partition data or tile data 保存在 shared memory里面。
2. 执行计算时,从shared memory里面取这些数据。
3. 上面的结束之后,拷贝shared memory的数据到global memory
合并访问
warp是调度和执行的基本单位,这个在上一篇中有提到,half-warp是存储器操作的基本单位,这两个非常重要。
到我们都知道每一个half-warp是16个thread.以tesla为例:
Tesla 的每个 SM 拥有 16KB 共享存储器,用于同一个线程块内的线程间通信。为了使一个 half-warp 内的线程能够在一个内核周期中并行访问,共享存储器被组织成 16 个 bank,
每个 bank 拥有1024Kb 的宽度,一个Int 4个Byte ,故每个 bank 可保存 256 个整形或单精度浮点数,或者说目前的bank 组织成了 256 行 16 列的矩阵

上图中shared memory的长度是256.
举例说明:
__shared__ int data[128];
那么data[0], data[1]...data[15] 会依次访问bank[0],bank[1]...bank[15].
而data[16] ...data[31] 又会以此访问bank0 ...bank15.
由于存取内存是half-warp=16,所以属于不同half-warp的thread不存在bank conflict.
因此,如果程序在存取 shared memory 的时候,使用以下的方式:
int number = data[base + tid]; (这个是连续访问的,和base没什么关系)
那就不会有任何 bank conflict,可以达到最高的效率。但是,如果是以下的方式:
int number = data[base + 4 * tid];
那么,thread 0 和 thread 4 就会存取到同一个 bank,thread1 和 thread 5 也是同 样,这样就会造成 bank conflict。在这个例子中,一个 half warp 的 16 个 threads 会有四个threads 存取同一个 bank,因此存取 share memory 的速度会变成原来的 1/4。
下面这种情况比较特殊:
int number = data[3].
大家都访问同一个bank的同一个数据的时候,就可以形成一个broadcast,那样就会把数据同时广播给16个thread,这样就可以合理利用shared memory的broadcast的机制。
解决bank conflict的策略
很多时候 shared memory 的 bank conflict 可以透过修改数据存放的方式来解决。例如,以下的程序:
data[tid] = global_data[tid];
...
int number = data[16 * tid];
会造成严重的 bank conflict,为了避免这个问题,可以把数据的排列方式稍加修改,把存取方式改成:
int row = tid / 16;
int column = tid % 16;
data[row * 17 + column] = global_data[tid];
...
int number = data[17 * tid];
这样就不会造成 bank conflict 了。
简单的说,矩阵中的数据是按照bank存储的,第i个数据存储在第i%16个bank中。一个block要访问shared memory,只要能够保证以其中相邻的16个线程一组访问thread,每个线程与bank是一一对应就不会产生bank conflict。否则会产生bankconflict,访存时间成倍增加,增加的倍数由一个bank最多被多少个thread同时访问决定。有一种极端情况,就是所有的16个thread同时访问同一bank时反而只需要一个访问周期,此时产生了一次广播。
下面有一些小技巧可以避免bank conflict 或者提高global存储器的访问速度
1. 尽量按行操作,需要按列操作时可以先对矩阵进行转置
2. 划分子问题时,使每个block处理的问题宽度恰好为16的整数倍,使得访存可以按照 s_data[tid]=i_data[tid]的形式进行
3. 使用对齐的数据格式,尽量使用nvidia定义的格式如float3,int2等,这些格式本身已经对齐。
4. 当要处理的矩阵宽度不是16的整数倍时,将其补为16的整数倍,或者用malloctopitch而不是malloc。
5. 利用广播,例如s_odata[tid] = tid%16 < 8 ? s_idata[tid] :s_idata[15];会产生8路的块访问冲突而用:
s_odata[tid]=s_idata[15];s_odata[tid]= tid%16 < 8 ? s_idata[tid] :s_data[tid]; 则不会产生块访问冲突
2.2CUDA-Memory(存储)和bank-conflict的更多相关文章
- 【并行计算-CUDA开发】CUDA bank conflict in shared memory
http://hi.baidu.com/pengkuny/item/c8070b388d75d481b611db7a 以前以为 shared memory 是一个万能的 L1 cache,速度很快,只 ...
- CUDA中Bank conflict冲突
转自:http://blog.csdn.net/smsmn/article/details/6336060 其实这两天一直不知道什么叫bank conflict冲突,这两天因为要看那个矩阵转置优化的问 ...
- mysql memory存储引擎简单测试
Auth: jin Date: 20140423 mysql> CREATE TABLE `t4` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` ...
- MySQL Memory 存储引擎浅析
原创文章,转载必需注明出处:http://www.cnblogs.com/wu-jian/ 前言 需求源自项目中的MemCache需求,開始想用MemCached(官方网站:http://memcac ...
- 关于一个GPGPU优化中Bank Conflict的讨论
出自OpenGPU: 关于去除bank conflict的一个例子程序
- MySQL三种InnoDB、MyISAM和MEMORY存储引擎对比
什么是存储引擎? MySQL中的数据用各种不同的技术存储在文件(或者内存)中.这些技术中的每一种技术都使用不同的存储机制.索引技巧.锁定水平并且最终提供广泛的不同的功能和能力.通过选择不同的技术,你能 ...
- 【并行计算-CUDA开发】关于共享内存(shared memory)和存储体(bank)的事实和疑惑
关于共享内存(shared memory)和存储体(bank)的事实和疑惑 主要是在研究访问共享内存会产生bank conflict时,自己产生的疑惑.对于这点疑惑,网上都没有相关描述, 不管是国内还 ...
- 【并行计算-CUDA开发】CUDA shared memory bank 冲突
CUDA SHARED MEMORY shared memory在之前的博文有些介绍,这部分会专门讲解其内容.在global Memory部分,数据对齐和连续是很重要的话题,当使用L1的时候,对齐问题 ...
- 转!!MySQL中的存储引擎讲解(InnoDB,MyISAM,Memory等各存储引擎对比)
MySQL中的存储引擎: 1.存储引擎的概念 2.查看MySQL所支持的存储引擎 3.MySQL中几种常用存储引擎的特点 4.存储引擎之间的相互转化 一.存储引擎: 1.存储引擎其实就是如何实现存储数 ...
- 转mysql存储引擎memory,ndb,innodb之选择
1 mysql的innodb和cluster的NDB引擎都支持事务,在有共同的特性外,也有不同之处:以mysql cluster NDB 7.3和MySQL 5.6之InnoDB为例:ndb7.3基于 ...
随机推荐
- 自助Linux之问题诊断工具strace
转 http://www.cnblogs.com/bangerlee/archive/2012/02/20/2356818.html 引言 “Oops,系统挂死了..." “Oops,程序 ...
- PHP 7 值得期待的新特性(下)
这是我们期待已久的 PHP 7 系列文章的第二篇.点此阅读 第一篇本文系 OneAPM 工程师编译整理. 也许你已经知道,重头戏 PHP 7 的发布将在今年到来!现在,让我们来了解一下,新版本有哪些新 ...
- python繁体中文到简体中文的转换
处理中文字符串遇到了繁体和简体中文的转换,python版: 1.下载zh_wiki.py及langconv zh_wiki.py:https://github.com/skydark/nstool ...
- Android ViewPager的每个页面的显示与销毁的时机
大家在用viewPager的时候要创建一个pagerAdapter对象,用于给viewPager设置页面的. viewPager里面有一个container容器. viewPager的容器缓存3个显示 ...
- android 在一个scrollView里面嵌套一个需要滑动的控件(listView、gridView)
package cn.via.dageeeOrderFood.widget; import android.content.Context; import android.graphics.Point ...
- MyEclipse server窗口 Could not create the view: An unexpected exception was thrown 错误解决
MyEclipse 打开后有时候莫名的在server窗口里抛出“Could not create the view: An unexpected exception was thrown”错误,解决办 ...
- [博弈]ZOJ3591 Nim
题意: 给了一串数,个数不超过$10^5$,这串数是通过题目给的一段代码来生成的 int g = S; ; i<N; i++) { a[i] = g; ) { a[i] = g = W; } = ...
- QPushButton 的checkable 属性
只有setCheckable(true),这个button才能发射 toggle(bool) 信号. 而toggle(bool)代表了button 按下,弹起的状态像0,1的切换开关.
- [转] Android自动化测试之使用java调用monkeyrunner(五)
Android自动化测试之使用java调用monkeyrunner 众所周知,一般情况下我们使用android中的monkeyrunner进行自动化测试时,使用的是python语言来写测试脚本.不过, ...
- 1650. Billionaires(线段树)
1650 简单题 线段树的单点更新 就是字符串神马的 有点小繁琐 开两个map 一个存城市 一个存名字 #include <iostream> #include<cstdio> ...