关于join时显示no join predicate的那点事
我们偶尔,非常偶尔的情况下会在一个查询计划中看到这样的警告:
大红叉,好吓人啊!
把鼠标放上去一看显示这样的信息
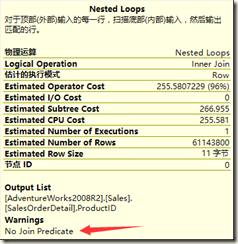
No join predicate
直译过来就是:没有连接谓词
在真实的生产环境下我们很少能看到这种警告,什么时候才出这种警告呢?当然就是~~~没有连接谓词(汗)的时候,也许这么解释起来很找打,但是真实情况就是这样。
我们知道,在sqlserver连接操作的时候,他的本质实际上就是生成一个笛卡尔积表,那么连接谓词就是在笛卡尔积表上进行筛选的条件
比如我们写如下的查询:
select sod.ProductID from sales.SalesOrderDetail sod
join production.product pd
on 1=1
可以看到,我在on的位置上只写了on 1=1,实际上这个查询等同于
select sod.productid from
sales.SalesOrderDetail sod ,production.product pd
where 1=1--或者where 1=1这个可以也是可以不加的
我们都知道上面两种写法只是生成了一个笛卡尔积表的全集
他们的执行计划生成是一模一样的,如下,可以注意一下上方显示的查询语句:

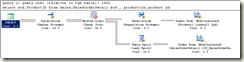
这时,因为两个表之间出现了没有任何可供连接的谓词,换句话说就是没有对笛卡尔积生成的表进行任何筛选,这种查询可能会带来巨大的性能损耗,所以发出了no join predicate的警告,而事实也是如此
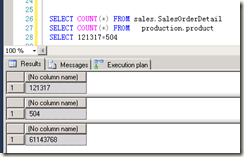
我们可以看到12W对500条数据的表做积后生成的数据量高达6KW条,可想而知这种查询的消耗有多么大,所以我们一般在查询中一定要注意在做表连接的时候避免这种写法,也许有人会说,谁会这么写查询?我只能说什么都可能发生 ,比如连接表时是以拼串的形式生成的sql语句,或者用我提到的第二种古老的写法进行的查询,都是有可能的。
OK,以上是对no join predicate警告的一个基本说明,但是今天我们的重点不在这里
我这篇文章想说的是:有一种情况下的警告出现的很奇怪,比如下面这个查询
SELECT sod.SalesOrderID,pd.Name FROM sales.SalesOrderDetail sod
INNER JOIN production.product2 pd
on sod.productid=pd.ProductID
where sod.productid=777
计划:
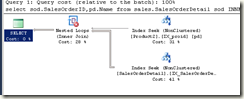
这个计划中就有无连接谓词警告,但是明明写了ON也有where条件,为什么还会生成这样的计划呢,我们来看一下它是怎么产生的:
我们以最开始的查询开始
注意:product 表就是AdventureWorks2008R2原生的产品表
SELECT sod.SalesOrderID,pd.Name FROM sales.SalesOrderDetail sod
INNER JOIN production.product pd
on sod.productid=pd.ProductID
where sod.productid=777
它的计划如下:
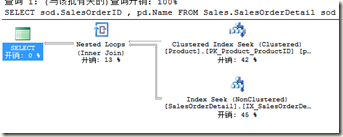
OK,没有任何的问题,那么我们假设有如下情况:product 表中的productID并不唯一,也就是说SalesOrderDetail 和product 的productid是多对多的情况,这种情况在生产环境中就相当常见了
所以我生成了如下的表:select * into Production.product2 from Production.product
我们知道,这样生成的表会把identify列一起生成,上面说过productid应该是不唯一的情况,所以我们把idenify属性去除(过程省略),并生成一个不唯一索引
为这说明之后发生的问题,我们再添加一个列,显示的是产品第一批订单发生的日期
alter table Production.product2 add firstorder int
update Production.product2 set firstorder=c.SalesOrderDetailID
from Production.product2 a
cross apply(select top 1 SalesOrderDetailID from Sales.SalesOrderDetail
where ProductID=a.ProductID order by ModifiedDate) c
再创建一个索引
create index IX_test on Production.product2 (productid,firstorder,name)
之后运行:
SELECT sod.SalesOrderID,pd.Name FROM sales.SalesOrderDetail sod
INNER JOIN production.product2 pd
on sod.productid=pd.ProductID
where sod.productid=777 option(recompile)
再查看执行计划
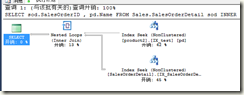
好的,还是没有任何问题出现,我们知道,查询计划的生成是依靠统计信息的,所以我们查看一下777这个键值的统计信息:
DBCC SHOW_STATISTICS("Production.product2",IX_test)

可以看出,777这个值显示为一个唯一值(或者说mssql通过统计信息认为777这个值也许,大概,可能是唯一的),之前我们说过,我们的场景是多对多,那我们开始生成重复数据,并且手动刷新统计信息:
insert into Production.product2 select * from Production.product2 where productid=777
update STATISTICS Production.product2 IX_test with fullscan—在sql2014中由于预估算法有改进,不用更新统计直接执行也可以重现,但是在直方图中就看不出来了
再看上面查询的计划
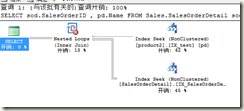
噢!变成没有谓词的提示了!
统计信息呢,变成这样了

这是为什么呢?
解释如下:我们知道,在查询处理的过程中,优化器对查询有一系列简化过程,比如代数代入,就是说在
on sod.productid=pd.ProductID
where sod.productid=777
这个条件下,会先通过productid=777把两个表符合条件的数据筛选出来(为什么是两个表,因为有sod.productid=pd.ProductID,所以常量参数直接传递了),之后再进行inner on的匹配
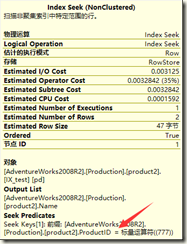
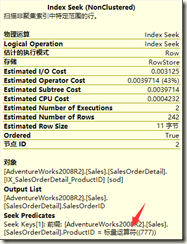
之前没有重复数据的时候,由于product表productid列为主键,给定键值只有一条数据,那么对SalesOrderDetail来说,输出的数据就是product表单条数据与SalesOrderDetail表的全部匹配数据
而把product进行重复插入后,mssql查觉到product表符合777的数据>1条了(见下图)
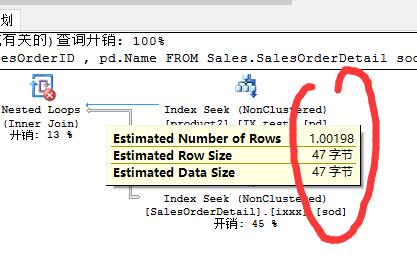
但是连接谓词列被指定常量777替换,但又没有其它的筛选条件,那么实际上查询等同于
SELECT sod.SalesOrderID,pd.Name FROM (select SalesOrderID from sales.SalesOrderDetail where productid=777) sod,
(select Name from production.product2 where productid=777) pd option(recompile)
同时,我们也知道,nest loop算法的伪码如下 :
我们知道,nest loop的伪码算法是这样的,它的时间复杂度为N*M(或者说左表行数*右表行数)
for each row in tb1 loop
for tb2 loop
If match tb2.key= tb1.key then pass the row on to the next step
If no match then discard the row
end loop
end loop
上面的查询写法就变成了两个子结果集直接进行积卡尔笛,但并没有任何可供比较的key值,于是产生了no join predicate警告
那么如果我换一个参数呢?比如productid=1的时候会是什么情况?
在本例中,由于SalesOrderDetail没有符合productid=1的数据,所以预估行数据就为1,这时不管product表有多少productid=1的数据,也表现为输出一对多的数据,所以也就没有显示出no join predicate警告。
其实可以说,如果查询计划里出现了no join predicate警告,就必须要看一下这个查询的业务逻辑是不是有问题,有可能是输出大量无效的垃圾数据,并且影响了性能 ,但是这个说法反过来说是不成立的,并不是说没有没有警告就没产生重复的垃圾数据。
例如在之前我建立的复合索引是包含了productid和firstorder列
那我查询的写法可能会这么写
SELECT sod.SalesOrderID ,
pd.Name
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.product2 pd ON
sod.salesorderdetailid= pd.firstorder and
sod.ProductID=pd.ProductID
WHERE pd.ProductID = 777 and pd.firstorder=28 option(recompile)
假设这两个表的数据量很大,且有相当多的数据,这时就有可能产生行数估值错误,出现无谓词警告,但是有可能业务逻辑并没有问题(在本例中没有出现这种情况,只是举例说明)
表不变,但当查询这么写的时候
SELECT sod.SalesOrderID ,
pd.Name
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.product2 pd ON
sod.ProductID=pd.ProductID
and sod.salesorderdetailid= pd.firstorder
WHERE pd.ProductID = 777-- and pd.firstorder=28
option(recompile)
因为两个数据子集除去productid被常量参数传递后不参与匹配后,还需要进一步对sod.salesorderdetailid= pd.firstorder进行匹配,这样不会出现无连接谓词警告,但是业务逻辑明显出现了问题,但我估计不会有人把上面查询修改写成下面这样吧……
当然在本篇文章中演示的案例数据量太小,并不能重现这种情况。有兴趣的同学可以扩大数据量测试一下。
结论
在进行连接时不管左表还是右表,只要有一个表可以产生一个唯一性数据(即nest loop的时间复杂度为1*M或者N*1),这种情况下即使写成没有连接谓词的形式,也不会产生警告符,但是只要结果为N*M,且没有任何可供匹配的连接谓词(可以被常量传递的谓词不算),则会产生警告。
我的确是在生产环境中实实在在遇到了这种情况
 ,由于涉及公司的业务就不把全部计划截出来了,但是可以告诉大家的是,在nested loop下方的那个数据表,其实就存在有类似(productid,firstorder)这样的一个复合索引,且数据具有唯一性,但是因为统计信息的问题预估行数变成了1.25行,于是产生了无连接谓词警告
,由于涉及公司的业务就不把全部计划截出来了,但是可以告诉大家的是,在nested loop下方的那个数据表,其实就存在有类似(productid,firstorder)这样的一个复合索引,且数据具有唯一性,但是因为统计信息的问题预估行数变成了1.25行,于是产生了无连接谓词警告
那么究竟这种警告到底需要不需要处理呢?我的看法是:看情况。
出现了警告,肯定是DBA需要关注的,但是不是所有的警告一定就是有问题。
这需要与业务方沟通,到底是业务逻辑出现了问题?还是需求如此?又或者只是一个生成计划时的误判?
如果只是统计信息误判断生成查询计划显示的警告,但业务逻辑没有混乱,从我自己遇到的情况看,并没有什么实质性的性能问题,可以忽略,如果您有什么不同见解可以与我联系
关于join时显示no join predicate的那点事的更多相关文章
- Nested Loops join时显示no join predicate原因分析以及解决办法
本文出处:http://www.cnblogs.com/wy123/p/6238844.html 最近遇到一个存储过程在某些特殊的情况下,效率极其低效, 至于底下到什么程度我现在都没有一个确切的数据, ...
- 使用COALESCE时注意left join为null的情况
1.使用COALESCE时,用到group by with cube,如果之前两个表left join时,有数据为null,就会使得查出的数据主键不唯一 例如: select COALESCE (c. ...
- left join 和 left outer join 的区别
left join 和 left outer join 的区别 通俗的讲: A left join B 的连接的记录数与A表的记录数同 A right join ...
- 小菜菜mysql练习解读分析2——查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )
“查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )” ——翻译为:课程表里面,存在01的信息,未必满足有02的课程情况 ...
- SQL JOIN\SQL INNER JOIN 关键字\SQL LEFT JOIN 关键字\SQL RIGHT JOIN 关键字\SQL FULL JOIN 关键字
SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据. Join 和 Key 有时为了得到完整的结果,我们需要从两个或更多的表中获取结果.我们就需要执行 join. 数据库中的表 ...
- hadoop 多表join:Map side join及Reduce side join范例
最近在准备抽取数据的工作.有一个id集合200多M,要从另一个500GB的数据集合中抽取出所有id集合中包含的数据集.id数据集合中每一个行就是一个id的字符串(Reduce side join要在每 ...
- Oracle 表的连接方式(1)-----Nested loop join和 Sort merge join
关系数据库技术的精髓就是通过关系表进行规范化的数据存储,并通过各种表连接技术和各种类型的索引技术来进行信息的检索和处理. 表的三种关联方式: nested loop:从A表抽一条记录,遍历B表查找匹配 ...
- MySQL的 inner join on 与 left join on
WHERE子句中使用的连接语句,在数据库语言中,被称为隐性连接.INNER JOIN……ON子句产生的连接称为显性连接. inner join:理解为“有效连接”,两张表中都有的数据才会显示left ...
- Oracle中join left,join right,inner join,(+) 等
Oracle中join left,join right,inner join,(+) 等 博客分类: Oracle 建表create table TEST1create table TEST1( ...
随机推荐
- 火焰图分析openresty性能瓶颈
注:本文操作基于CentOS 系统 准备工作 用wget从https://sourceware.org/systemtap/ftp/releases/下载最新版的systemtap.tar.gz压缩包 ...
- node服务的监控预警系统架构
需求背景 目前node端的服务逐渐成熟,在不少公司内部也开始承担业务处理或者视图渲染工作.不同于个人开发的简单服务器,企业级的node服务要求更为苛刻: 高稳定性.高可靠性.鲁棒性以及直观的监控和报警 ...
- vue2.0实践的一些细节
最近用vue2.0做了个活动.做完了回头发现,好像并没有太多的技术难点,而自己好像又做了比较久...只能说效率有待提升啊...简单总结了一些比较细节的点. 1.对于一些已知肯定会有数据的模块,先用一个 ...
- 【XSS】延长 XSS 生命期
XSS 的本质仍是一段脚本.和其他文档元素一样,页面关了一切都销毁.除非能将脚本蔓延到页面以外的地方,那样才能获得更长的生命力. 庆幸的是,从 DOM 诞生的那一天起,就已为我们准备了这个特殊的功能, ...
- Xshell 连接CentOS服务器解密
平台之大势何人能挡? 带着你的Net飞奔吧!http://www.cnblogs.com/dunitian/p/4822808.html Xshell生成密钥key(用于Linux 免密码登录)htt ...
- canvas与html5实现视频截图功能
这段时间一直在研究canvas,突发奇想想做一个可以截屏视频的功能,然后把图片拉去做表情包,哈哈哈哈哈哈~~ 制作方法: 1.在页面中加载视频 在使用canvas制作这个截图功能时,首先必须保证页面上 ...
- Java消息队列--ActiveMq 实战
1.下载安装ActiveMQ ActiveMQ官网下载地址:http://activemq.apache.org/download.html ActiveMQ 提供了Windows 和Linux.Un ...
- D3.js学习(六)
上节我们学习了如何绘制多条曲线, 以及给不同的曲线指定不同的坐标系.在这节当中,我们会对坐标轴标签相关的处理进行学习.首先,我们来想一个问题, 如何我们的x轴上的各个标签的距离比较近,但是标签名又比较 ...
- Yeoman 学习笔记
yoeman 简介:http://www.infoq.com/cn/news/2012/09/yeoman yeoman 官网: http://yeoman.io/ yeoman 是快速创建骨架应用程 ...
- linux下mono播放PCM音频
测试环境: Ubuntu 14 MonoDevelop CodeBlocks 1.建立一个共享库(shared library) 这里用到了linux下的音频播放库,alsa-lib. al ...