MySQL 5.7: Enhanced Multi-threaded slaves
http://geek.rohitkalhans.com/2013/09/enhancedMTS-deepdive.html 科学上网
Introduction
The infamous out of order commit problem
On Master we apply T1 and T2 in that order.
State0: x= 1, y= 1 T2: { y:= Read(x);
|
On the slave however these two transactions commit out of order (Say T2 and then T1).
State0: x= 1, y= 1 T1: { x:= Read(y);
|
As we see above the final state state 2 is different in the two cases. Needless to say that we need to control the transactions that can execute in parallel.
Controlled parallelization
The process of committing: On the slave we need to make sure that the transactions that we schedule for parallel execution will be the one which do not have conflicting read and write set. This is the only and the necessary requirement for the slave workers to work without conflicts. This also implies that if the transactions being executed in parallel do not have intersecting read and write sets, we don't care if they are committed out of order. Since MySQL uses lock based scheduling, all the transactions that have entered the prepared stage but not as yet committed will have disjoint read and write sets and hence can be executed in parallel.
Logical clock and commit parent
The pseudo code is as follows.
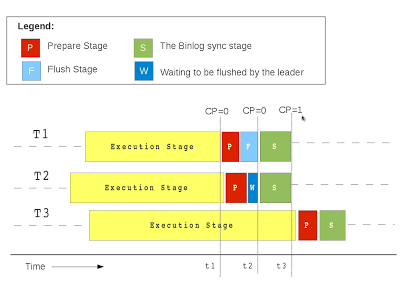
Another thing to note here is that the "group" of transactions that are being executed in parallel are not bounded by binlog commit group. There is a possibility that a transaction have entered the binlog prepare stage but could not make it to the current binlog group. Our approach takes care of such cases and makes sure that we relax the boundary of the group being executed in parallel on the slave.
Conclusion
This feature provides the great enhancement to the existing MySQL replication. To know more about the configuration options of this enhancement refer to this post.
This feature is available inMySQL 5.7.2 release. You can try it out and let us know the feedback.
About the author

Rohit Kalhans is a Software Development Engineer based out of Banglore India. His area of focus revolves around Row-based replication and Multi-threaded parallel slave. His interests include system programming, highly-available and scalable systems. In his free time, he plays guitar and piano and loves to write short stories and poems. More Information can be found on his homepage.
MySQL 5.7: Enhanced Multi-threaded slaves的更多相关文章
- MySQL复制配置(多主一从)
复制多主一从 replicaion 原理 复制有三个步骤:(分为三个线程 slave:io线程 sql线程 master:io线程) 1.master将改变记录到二进制日志(binary log)中( ...
- MySql集群FAQ----mysql主从配置与集群区别、集群中需要多少台计算机呢?为什么? 等
抽取一部分显示在这里,如下, What's the difference in using Clustervs using replication? 在复制系统中,一个MySQL主服务器会更新一个或多 ...
- MySQL数据很大的时候
众所周知,mysql在数据量很大的时候查询的效率是很低的,因为假如你需要 OFFSET 100000 LIMIT 5 这样的数据,数据库就需要跳过前100000条数据,才能返回给你你需要的5条数据.由 ...
- mysql 2006
1.在my.ini文件中添加或者修改以下两个变量:wait_timeout=2880000interactive_timeout = 2880000 关于两个变量的具体说明可以google或者看官方手 ...
- MySQL高可用架构:mysql+keepalived实现
系统环境及架构 #主机名 系统版本 mysql版本 ip地址 mysqlMaster <a href="https://www.linuxprobe.com/" title= ...
- MySQL之备份
MySQL备份和备份 备份/还原 冷备:需要停止当前正在运行mysqld,然后直接拷贝或打包数据文件. 半热备:mysqldump+binlog --适合数据量比较小的应用 在线热备:AB复制 --实 ...
- linux MySql 的主从复制部署
MySql 复制 mysql 复制:将某一台主机上的 Mysql 数据复制到其它主机(slaves)上,并重新执行一遍从而实现 当前主机上的 mysql 数据与(master)主机上数据保持一致的过程 ...
- java面试一日一题:讲对mysql的MVCC的理解
问题:请讲下对mysql中MVCC的理解 分析:这个问题要回答的是对MVCC的理解,以及MVCC解决了什么问题这几个方面入手. 回答要点: 主要从以下几点去考虑, 1.什么是MVCC? 2.MVCC用 ...
- BlackArch-Tools
BlackArch-Tools 简介 安装在ArchLinux之上添加存储库从blackarch存储库安装工具替代安装方法BlackArch Linux Complete Tools List 简介 ...
随机推荐
- Easy steps to create a System Tray Application with C# z
Hiding the C# application to the system tray is quiet straight forward. With a few line of codes in ...
- 【LeetCode 209】Minimum Size Subarray Sum
Given an array of n positive integers and a positive integer s, find the minimal length of a subarra ...
- Loadrunner模拟Json请求
一.loadrunner脚本创建 1.Insert - New step -选择Custom Request - web_custom_request 2.填入相应参数 3.生成脚本,并修改如下(参数 ...
- Flume OG 与 Flume NG 的区别
1.Flume OG:Flume original generation 即Flume 0.9.x版本 Flume NG:Flume next generation ,即Flume 1.x版本 ...
- Google Chart API 参考 中文版
Google Chart API 参考 中文版 文档信息 翻译: Cloudream ,最后修改:02/22/2008 06:11:08 英文版版权归 Google , 转载此中文版必须以链接形式注明 ...
- C语言——递归练习
1.炮弹一样的球状物体,能够堆积成一个金字塔,在顶端有一个炮弹,它坐落在一个4个炮弹组成的层面上,而这4个炮弹又坐落在一个9个炮弹组成的层面上,以此类推.写一个递归函数CannonBall,这个函数把 ...
- BITED数学建模七日谈之二:怎样阅读数学模型教材
今天进入我们数学建模七日谈的第二天:怎样阅读数学建模教材? 大家再学习数学建模这门课程或准备比赛的时候,往往都是从教材开始的,教材的系统性让我们能够很快,很深入地了解前人在数学模型方面已有的研究成果, ...
- oracle 10g
一.安装系统 首先安装Linux系统,根据Oracle官方文档的建议,在机器内存小于1G的情况下,swap分区大小应该设置为内存的2倍大,若内存大于2G则swap分区设置为与内存大小一样. 为防止Or ...
- 有趣的Node爬虫,数据导出成Excel
最近一直没更新了诶,因为学习Backbone好头痛,别问我为什么不继续AngularJs~因为2.0要出来了啊,妈蛋!好,言归正传,最近帮我的好基友扒数据,他说要一些股票债券的数据.我一听,那不就是要 ...
- POJ3126 Prime Path
http://poj.org/problem?id=3126 题目大意:给两个数四位数m, n, m的位数各个位改变一位0 —— 9使得改变后的数为素数, 问经过多少次变化使其等于n 如: 10331 ...