爬虫四 selenium模块详细参数
selenium元素定位方法
一、访问页面并获取网页html
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)#browser.page_source是获取网页的全部html
browser.close()
二、查找元素(元素定位)
1、常用的八种查找元素的方法
find_element_by_name #通过元素的name属性来查找元素
find_element_by_id #通过元素id属性来查找元素
find_element_by_class_name #通过元素的class属性来查找元素
find_element_by_tag_name #通过元素的标签名称来查找元素
find_element_by_link_text #通过超文本链接上的文字来查找元素,查找的时候必须是完全匹配
find_element_by_partial_link_text #通过超文本链接上的部分文字来查找元素,查找的时候是模糊匹配
find_element_by_xpath #是xml path的简称,通过该方法可以查找到所有元素
find_element_by_css_selector #通过css样式来查找元素
注释:万能的查找元素方法find_element(匹配规则,匹配值)
当需要获取多个元素时,elements多个s就可以了,用法和上面类型
3、获取文本值,Id,位置,标签名,大小
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.text)#input.text文本值
print(input.id)#获取id
print(input.location)#获取位置
print(input.tag_name)#获取标签名
print(input.size)#获取大小
browser.close()
三、使用案例
1. By.tagName()
该方法可以通过元素的标签名称来查找元素。该方法跟之前两个方法的区别是,这个方法搜索到的元素通常不止一个,所以一般建议结合使用findElements方法来使用。比如我们现在要查找页面上有多少个button,就可以用button这个tagName来进行查找,代码如下:
public class SearchPageByTagName{
public static void main(String[] args){
WebDriver driver = new FirefoxDriver();
driver.get("http://www.forexample.com");
List<WebElement> buttons = driver.findElements(By.tagName("button"));
System.out.println(buttons.size()); //打印出button的个数
}}
单选框、复选框、文本框和密码框的元素标签都是input,此时单靠tagName无法准确地得到我们想要的元素,需要结合type属性才能过滤出我们要的元素。示例代码如下:
1 public class SearchElementsByTagName{
3 public static void main(String[] args){
5 WebDriver driver = new FirefoxDriver();
7 driver.get("http://www.forexample.com");
9 List<WebElement> allInputs = driver.findElements(By.tagName("input"));
11 //只打印所有文本框的值
13 for(WebElement e: allInputs){
15 if (e.getAttribute(“type”).equals(“text”)){
17 System.out.println(e.getText().toString()); //打印出每个文本框里的值
19
2. By.linkText()
这个方法比较直接,即通过超文本链接上的文字信息来定位元素,这种方式一般专门用于定位页面上的超文本链接。通常一个超文本链接会长成这个样子:
1 <a href="/intl/en/about.html">About Google</a>
1 public class SearchElementsByLinkText{
3 public static void main(String[] args){
5 WebDriver driver = new FirefoxDriver();
7 driver.get("http://www.forexample.com");
9 WebElement aboutLink = driver.findElement(By.linkText("About Google"));
11 aboutLink.click(); }}
3. By.partialLinkText()
这个方法是上一个方法的扩展。当你不能准确知道超链接上的文本信息或者只想通过一些关键字进行匹配时,可以使用这个方法来通过部分链接文字进行匹配。代码如下:
1 public class SearchElementsByPartialLinkText{
3 public static void main(String[] args){
5 WebDriver driver = new FirefoxDriver();
7 driver.get("http://www.forexample.com");
9 WebElement aboutLink = driver.findElement(By.partialLinkText("About"));
11 aboutLink.click();
13 }}
注意:使用这种方法进行定位时,可能会引起的问题是,当你的页面中不止一个超链接包含About时,findElement方法只会返回第一个查找到的元素,而不会返回所有符合条件的元素。如果你要想获得所有符合条件的元素,还是只能使用findElements方法。
4. By.xpath()
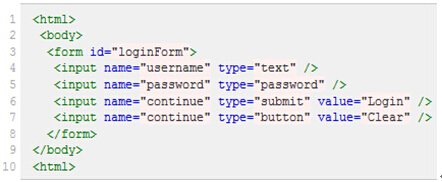
图(2)
1、绝对路径写法(只有一种),写法如下:
引用页面上的form元素(即源码中的第3行):/html/body/form[1]
注意:1. 元素的xpath绝对路径可通过firebug直接查询。
2. 一般不推荐使用绝对路径的写法,因为一旦页面结构发生变化,该路径也随之失效,必须重新写。
3. 绝对路径以单/号表示,而下面要讲的相对路径则以//表示,这个区别非常重要。另外需要多说一句的是,当xpath的路径以/开头时,表示让Xpath解析引擎从文档的根节点开始解析。当xpath路径以//开头时,则表示让xpath引擎从文档的任意符合的元素节点开始进行解析。而当/出现在xpath路径中时,则表示寻找父节点的直接子节点,当//出现在xpath路径中时,表示寻找父节点下任意符合条件的子节点,不管嵌套了多少层级.
2、相对路径的引用写法:
查找页面根元素://
查找页面上所有的input元素://input
查找页面上第一个form元素内的直接子input元素(即只包括form元素的下一级input元素,使用绝对路径表示,单/号)://form[1]/input
查找页面上第一个form元素内的所有子input元素(只要在form元素内的input都算,不管还嵌套了多少个其他标签,使用相对路径表示,双//号)://form[1]//input
查找页面上第一个form元素://form[1]
查找页面上id为loginForm的form元素://form[@id='loginForm']
查找页面上具有name属性为username的input元素://input[@name='username']
查找页面上id为loginForm的form元素下的第一个input元素://form[@id='loginForm']/input[1]
查找页面具有name属性为contiune并且type属性为button的input元素://input[@name='continue'][@type='button']
查找页面上id为loginForm的form元素下第4个input元素://form[@id='loginForm']/input[4]
3、示例:
WebElement password = driver.findElement(By.xpath("//*[@id='J_login_form']/dl/dt/input[@id='J_password']"));
WebElement password = driver.findElement(By.xpath("//*[@id='J_login_form']/*/*/input[@id='J_password']"));
4、模糊匹配查找
1、用contains包含关键字模糊匹配
1 driver.findElement(By.xpath(“//a[contains(@href, ‘logout’)]”));
这句话的意思是寻找页面中href属性值包含有logout这个单词的所有a元素。
2、用start-with开头关键字模糊匹配:
1 driver.findElement(By.xpath(“//a[starts-with(@rel, ‘nofo’)]));
这句的意思是寻找rel属性以nofo开头的a元素。其中@后面的rel可以替换成元素的任意其他属性
3、 用Text关键字,定位代码如下:
1 driver.findElement(By.xpath(“//*[text()=’退出’]));
这个方法可谓相当霸气啊。直接查找页面当中所有的退出二字,根本就不用知道它是个a元素了。这种方法也经常用于纯文字的查
4、如果知道超链接元素的文本内容,也可以混合使用
1 driver.findElement(By.xpath(“//a[contains(text(), ’退出’)]));
这种方式一般用于知道超链接上显示的部分或全部文本信息时,可以使用
最后,关于xpath这种定位方式,webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素,所以这是一个非常费时的操作,如果你的脚本中大量使用xpath做元素定位的话,将导致你的脚本执行速度大大降低,所以请慎用。
5. By.cssSelector()
前言:cssSelector这种元素定位方式跟xpath比较类似,但执行速度较快,而且各种浏览器对它的支持都相当到位,所以功能也是蛮强大的。
1、CssSelector常用定位
driver.findElement(By.cssSelector("input") #根据标签名称查找
driver.findElement(By.cssSelector("input#username"));#根据标签和#id查找
driver.findElement(By.cssSelector("#username"));#根据id查找
driver.findElement(By.cssSelector(".username"));#根据class属性查找.
driver.findElement(By.cssSelector(".username.**.***"));.#复合class查找
定位id为flrs的div元素,可以写成:#flrs 注:相当于xpath语法的//div[@id=’flrs’]
定位id为flrs下的a元素,可以写成 #flrs > a 注:相当于xpath语法的//div[@id=’flrs’]/a
定位id为flrs下的href属性值为/forexample/about.html的元素,可以写成: #flrs > a[href=”/forexample/about.html”]
如果需要指定多个属性值时,可以逐一加在后面,如#flrs > input[name=”username”][type=”text”]。
2、根据元素属性查找
eg: driver.findElement(By.cssSelector("input[name=username]"));属性名=属性值,id,class,等都可写成这种形式
driver.findElement(By.cssSelector("img[alt]"));存在属性。例如img元素存在alt属性
driver.findElement(By.cssSelector("input[type='submit'][value='Login']"));多属性
3、层级关系查找
cssSelector还有一个用处是定位使用了复合样式表的元素
<button id="J_sidebar_login" class="btn btn_big btn_submit" type="submit">登录</button>
cssSelector引用元素代码如下:
driver.findElement(By.cssSelector("button.btn.btn_big.btn_submit")
4、高级用法:利用^用于匹配一个前缀,$用于匹配一个后缀,*用于匹配任意字符。
匹配一个有id属性,并且id属性是以”id_prefix_”开头的超链接元素:a[id^='id_prefix_']
匹配一个有id属性,并且id属性是以”_id_sufix”结尾的超链接元素:a[id$='_id_sufix']
匹配一个有id属性,并且id属性中包含”id_pattern”字符的超链接元素:a[id*='id_pattern']
eg:driver.findElement(By.cssSelector(Input[id ^='ctrl']));匹配到id头部 如ctrl_12
driver.findElement(By.cssSelector(Input[id $='ctrl']));匹配到id尾部 如a_ctrl
driver.findElement(By.cssSelector(Input[id *= 'ctrl']));匹配到id中间如1_ctrl_12
5、牛逼查找方法
WebElement input= driver.findElement(By.cssSelector("form>span>input"));/#子元素查找
WebElement input= driver.findElement(By.cssSelector("form input"));#后代元素查找
WebElement span= driver.findElemet(By.cssSelector("form :first-child"));/#冒号前有空格,定位到form下所有级别的第一个子元素,第一个后代元素
WebElement span= driver.findElemet(By.cssSelector("form input:first-child"));//冒号前无空格,定位到form下所有级别的第一个input元素
WebElement span= driver.findElemet(By.cssSelector("form>span:first-child"));/#冒号前无空格,定位到form直接子元素中的第一个span元素
WebElement userName = driver.findEleme(By.cssSelector("form :last-child"));#冒号前有空格,定位到form下所有级别的最后一个子元素
WebElement userName = driver.findElemet(By.cssSelector("form#form :nth-child(2)"));#冒号前有空格,定位到form下所有级别的第二个子元素,2可以改变
4、总结:
1. 当页面元素有id属性时,最好尽量用id来定位。但由于现实项目中很多程序员其实写的代码并不规范,会缺少很多标准属性,这时就只有选择其他定位方法。
2. xpath很强悍,但定位性能不是很好,所以还是尽量少用。如果确实少数元素不好定位,可以选择xpath或cssSelector。
3. 当要定位一组元素相同元素时,可以考虑用tagName或name。
4. 当有链接需要定位时,可以考虑linkText或partialLinkText方式。
5、CSS locator比XPath locator速度快,但是CSS locator没有XPath locator定位准确
爬虫四 selenium模块详细参数的更多相关文章
- 爬虫四 selenium模块
一.介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作, ...
- 爬虫之selenium模块
Selenium 简介 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟 ...
- 三: 爬虫之selenium模块
一 selenium模块 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. selenium最初是一个自动化测试工具, ...
- 3、爬虫之selenium模块
一 selenium模块 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. selenium最初是一个自动化测试工具, ...
- 03 爬虫之selenium模块
selenium模块 1.概念,了解selenium 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. seleniu ...
- 爬虫之 selenium模块
selenium模块 阅读目录 一 介绍 二 安装 三 基本使用 四 选择器 五 等待元素被加载 六 元素交互操作 七 其他 八 项目练习 一 介绍 selenium最初是一个自动化测试工具,而爬 ...
- 网络爬虫之Selenium模块和Xpath表达式+Lxml解析库的使用
实际生产环境下,我们一般使用lxml的xpath来解析出我们想要的数据,本篇博客将重点整理Selenium和Xpath表达式,关于CSS选择器,将另外再整理一篇! 一.介绍: selenium最初是一 ...
- 爬虫之selenium模块;无头浏览器的使用
一,案例 爬取站长素材中的图片:http://sc.chinaz.com/tupian/gudianmeinvtupian.html import requests from lxml import ...
- 爬虫五 Beautifulsoup模块详细
一.基本使用 from bs4 import BeautifulSoup htmlCharset = "GB2312" soup=BeautifulSoup(html_doc,'l ...
随机推荐
- Atitit atiMail atiDns新特性 v2 q39
Atitit atiMail atiDns新特性 v2 q39 V1 实现了基础的功能 V2 重构..使用自然语言的方式 c.According_to_the_domain_name(&quo ...
- android studio - 隐藏编辑器上面的导航条
菜单栏-“View”-"Navigation Bar"
- 没有局域网环境,全是公网IP可以做LVS吗,该如何做了!请大家赐教!
没有局域网环境,全是公网IP可以做LVS吗,该如何做了!请大家赐教! 由 wjjava 在 周四, -- : 提交 LVS集群 现在有3台服务器,各有一个公网IP地址.IP地址形式如下: IP1:12 ...
- http加密原理
HTTPS原理 客户端向服务器发送请求 服务器向客户端发送自己的证书 客户端验证证书的有效性(是否是可信用机构CA颁发的证书,如果不是则提出警告)并对比里面信息是否正确,不通过则立刻断开连接 向服务器 ...
- 使用Crypto++库的CBC模式实现加密
//***************************************************************************** //@File Name : scsae ...
- Yarn源码分析之MapReduce作业中任务Task调度整体流程(一)
v2版本的MapReduce作业中,作业JOB_SETUP_COMPLETED事件的发生,即作业SETUP阶段完成事件,会触发作业由SETUP状态转换到RUNNING状态,而作业状态转换中涉及作业信息 ...
- Ocelot + IdentityServer4 坑自己
现像是 connect/userinfo 可以访问 但是api都提示401 后面发现是在appsettings.json "Options": {"Authority&q ...
- GCD - Extreme (II) for(i=1;i<N;i++) for(j=i+1;j<=N;j++) { G+=gcd(i,j); } 推导分析+欧拉函数
/** 题目:GCD - Extreme (II) 链接:https://vjudge.net/contest/154246#problem/O 题意: for(i=1;i<N;i++) for ...
- JetNuke笔记 ( by quqi99 )
http://blog.csdn.net/quqi99/article/details/1624223 ———————————————————————————————————————————————— ...
- php对gzip文件或者字符串解压实例参考
要采集一个网站,目标站采用了gzip压缩传输网页,本来应该只要发送一个http头 Accept-Encoding: identity或者干脆不发送这个头等,就可以使目标站返回没有经过gzip压缩的页面 ...