深度学习之卷积神经网络CNN
转自:https://blog.csdn.net/cxmscb/article/details/71023576
一、CNN的引入
在人工的全连接神经网络中,每相邻两层之间的每个神经元之间都是有边相连的。当输入层的特征维度变得很高时,这时全连接网络需要训练的参数就会增大很多,计算速度就会变得很慢。例如一张黑白的28*28的手写数字图片时,输入层的神经元就是784个,如下图所示:
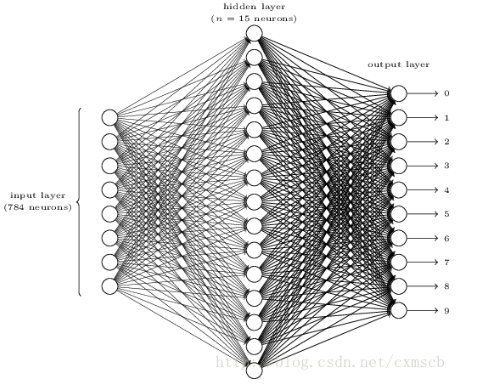
若在中间只使用一层隐藏层,参数w就有784*15=11760多个;若输入的是28*28带有颜色的RGB格式的手写数字图片,输入神经元就有28*28*3=2352个…….。这很容易看出使用全连接神经网络处理图像中的需要训练参数过多的问题。
而在卷积神经网络中,卷积层的神经元只与前一层的部分神经元节点相连,即他的神经元间的连接是非全连接的,且同一层中的某些神经元之间的连接的权重w和偏移b是共享的(即相同的),这样大量地减少了需要训练参数的数量。
卷积神经网络CNN的结构一般包含这几个层:
输入层:用于数据的输入
卷积层:使用卷积核进行特征提取和特征映射
激励层:由于卷积也是一种线性运算,因此需要增加非线性映射
池化层:进行下采样,对特征图稀疏处理,减少数据运算量。
全连接层:通常在CNN的尾部进行重新拟合,减少特征信息的损失
输出层:用于输出结果
当然中间还可以使用一些其他的功能层
归一化层(Batch Normailzation):在CNN中对特征的归一化
切分层:对某些(图片)数据的进行分区域的单独学习
融合层:对独立进行特征学习的分支进行融合
二、CNN的层次结构
输入层:
在CNN的输入层中,(图片)数据的输入格式与全连接神经网络的输入格式(一维向量)不太一样,CNN的输入层的输入格式保留了图片本身的结构。
对于黑白的28*28的图片,CNN的输入是一个28*28的二维神经元,如下图所示:

而对于RGB格式的28*28图片,CNN的输入则是一个3*28*28的三位神经元(RGB中的每一个颜色通道都有一个28*28的矩阵),如下图所示:

卷积层:
在卷积层中由几个重要的概念:
local receptive fields(感受视野)
shared weights(共享权值)
假设输入的是一个28*28的二维神经元,我们定义5*5的一个local receptive fields(感受视野),即隐藏层的神经元与输入层的5*5个神经元相连,这个5*5的区域就称为Local Receptive Fields,如下图所示:
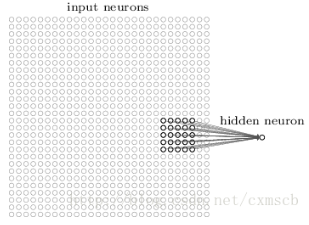
可类似看作:隐藏层中的神经元具有一个固定大小的感受视野去感受上一层的部分特征。在全连接神经网络中,隐藏层中的神经元的感受视野足够大乃至可以看到上一层的所有特征。
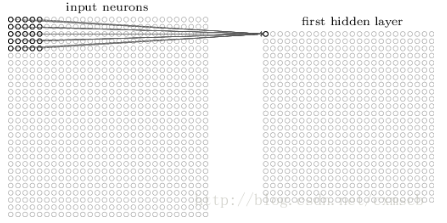
而在卷积神经网络中,隐藏层中的神经元的感受视野比较小,只能看到上一次的部分特征,上一层的其他特征可以通过平移感受视野来得到同一层的其他神经元,由同一层的其他神经元来看:

设移动的步长为1:从左到右扫描,每次移动1格,扫描完之后,再向下移动一格,再次从左到右扫描。
具体过程如动图所示:


可以看出 卷积层的神经元是只与前一层的部分神经元节点相连,每一条相连的线对应一个权重w。一个感受视野带有一个卷积核,我们将感受视野中的权重w矩阵称为卷积核;将感受视野对输入的扫描间隔称为步长(stride);当步长比较大时(stride>1),为了扫描到边缘的一些特征,感受野可能会“出界”。这时需要对边界扩充(pad),边界扩充可以设为0或其他值。步长和边界扩充值得大小由用户来定义。
卷积核得大小由用户来定义,即定义得感受视野得大小;卷积核得权重矩阵得值,便是卷积神经网络得参数,为了有一个偏移项,卷积核可附带一个偏移项b,他们得初值可以随机来生成,可通过训练进行变换。
因此感受野扫描时可以计算出下一层神经元得值为:

对下一层得所有神经元来说,他们从不同得位置去探测了上一层神经元得特征。
我们将通过一个带有卷积核得感受视野扫描生成下一层神经元矩阵称为一个feature map(特征映射图),如下图得右边便是一个feature map:
因此在同一个feature map上得神经元使用得卷积核是相同得,因此这些神经元shared weights,共享卷积核中得权值核附带得偏移。一个feature map对应一个卷积核,若我们使用3个不同得卷积核,可以输出3个feature map:(感受视野:5*5,步长stride:1)
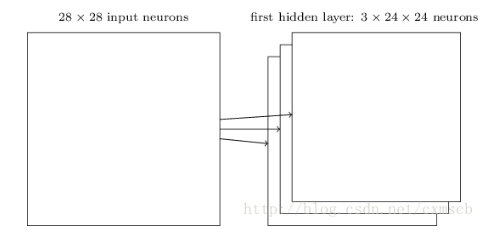
因此在CNN得卷积层,我们需要训练得参数大大地减少到了(5*5+1)*3=78个。
假设输入得是28*28得RGB图片,即输入得是一个3*28*28得二维神经元,这时卷积核得大小不只用长和宽来表示,还有深度,感受视野也对应得有了深度,如下图所示:
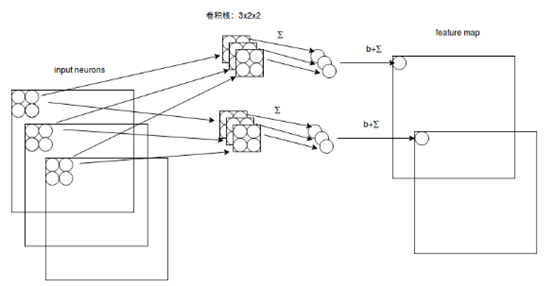
由图可知:感受视野:3*2*2;卷积核:3*2*2,深度为3;下一层得神经元得值为: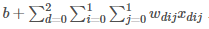
,卷积核得深度和感受视野得深度相同,都由输入数据来决定,长宽可由自己来设定,数目也可以由自己来设定,一个卷积核依然对应一个feature map。
注:“stride=1”表示在长和宽上得移动间隔都为1,即stride(width)=1且stride(height)=1
激励层:
激励层主要对卷积层得输出进行一个非线性映射,因为卷积层得计算还是一种线性计算,使用得激励函数一般为ReLu函数:
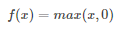
卷积层和激励层通常合并在一起称为“卷积层”。
池化层:
当输入经过卷积层时,若感受视野比较小,步长stride比较小,得到得feature map(特征图)还是比较大,可以通过池化层来对每一个feature
map进行降维操作,输出得深度还是不变得,依然为feature map得个数。
池化层也有一个“池化视野(filter)”来对feature map矩阵进行扫描,对“池化视野”中得矩阵值进行计算,一般有两种计算方式:
Max pooling:取“池化视野”矩阵中得最大值
Average pooling:取“池化视野”矩阵中得平均值
扫描得过程中同样会涉及扫描步长stride,扫描方式同卷积层一样,先从左到右扫描,结束则向下移动步长大小,再从左到右,如下图示例所示:
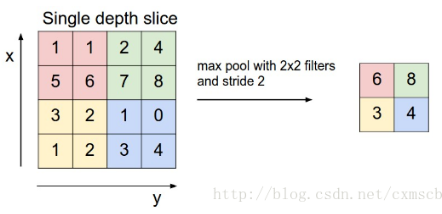
其中“池化视野”filter:2*2;步长stride:2。(注:“池化视野”为个人叫法)
最后可将3个24*24得feature map下采样得到得3个24*24的特征矩阵;
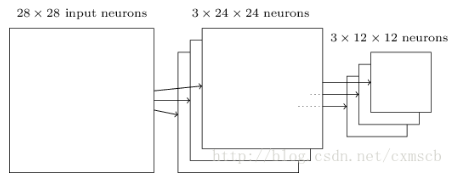
归一化层:
1、 Batch Normalization
Batch Normalization(批量归一化)实现了在神经网络层的中间进行预处理的操作,即在上一层的输入归一化处理后再进入网络的下一层,这样可有效地防止“梯度弥散”,加速网络训练。
Batch Normalization具体的算法如下图所示:

每次训练时,取batch_size大小的样本进行训练,在BN层中,将一个神经元看作一个特征,batch_size个样本在某个特征维度会有batch_size个值,然后在每个神经元xi维度上的进行这些样本的均值和方差,通过公式得到xi估计,再通过参数r和b进行线性映射得到没和神经元对应的输出yi。在BN层中,可以看出每一个神经元维度上,都会有一个参数r和b,他们同权重w一样可以通过训练进行优化。
在卷积神经网络中进行批量归一化时,一般对未进行ReLu激活的feature map进行批量归一化,输出后再作为激励层的输入,可达到调整激励函数偏导的作用。
一种做法是将feature map中的神经元作为特征维度,参数r和b的数量和则等于2*fmapwidth*fmaplength*fmapmin,这样做的化参数的数量会变得很多;
另一种做法是把一个feature map看作一个特征维度,一个feature map上的神经元共享这个feature map的参数r和b,参数r和b的数量和则等于2*fmapnum,计算均值和方差则在batch_size个训练样本在每一个feature map维度上的均值和方差。
注:fmapnum指的是一个样本的feature map数量,feature map跟神经元一样也有一定的排列排序。
Batch Normalization算法的训练过程和测试过程的区别:
在训练过程中,我们每次都会将batch_size数目大小的训练样本放入到CNN网络中进行训练,在BN层中自然可以得到计算输出所需要的均值和方差;
而在测试过程中,我们往往只会向CNN网络中输入一个测试样本,这是在BN层计算均值和方差会均为0,因为只有一个样本输入,因此BN层的输入也会出现很大的问题,从而导致CNN网络输出的错误,所以在测试过程中,我们需要借助训练集中所有样本在BN层归一化时每个维度上的均值和方差,当然为了计算方便,我们可以在batch_num次训练过程中,将每一次在BN层归一化时每个维度上的均值和方差进行相加,最后再进行求一次均值即可。
2、 Local Response Normlization
近邻归一化的归一化方法主要发生在不同的相邻的卷积核(经过ReLu之后)的输出之间,即输入是发生在不同的经过ReLu之后的feature map中。
LRN的公式如下:
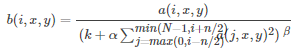
其中:

与BN的区别:BN依据mini batch的数据,近邻诡异仅需要自己来军顶,BN训练中有学习参数,BN归一化主要发生在不同的样本之间,LRN归一化主要发生在不同的卷积核的输出之间。
切分层:
在一些应用中,需要对图片进行切割,独立地对某一部分区域进行单独学习,这样可以对特定部分进行通过调整感受视野进行力度更大的学习。
融合层:
融合层可以对切分层进行融合,也可以对不同大小的卷积核学习到的特征进行融合。例如在GoogleLeNet中,使用多种分辨率的卷积核对目标特征进行学习,通过padding使得每一个feature map的长宽都一致,之后再将多个feature map在深度上拼接在一起:

融合的方法有几种,一种是特征矩阵之间的拼接级联,另一种是在特征矩阵进行运算(+,-,x,max,conv).
全连接层和输出层
全连接层主要对特征进行重新拟合,减少特征信息的丢失;输出层主要准备做好最后目标结果的输出。例如VGG的结构图,如下图所示:

典型的卷积神经网络
LeNet-5模型
第一个成功应用于数字是被的卷积神经网络模型(卷积层自带激励函数):

卷积层的卷积核边长都是5,步长都为1:池化层的窗口边长都为2,步长都为2.
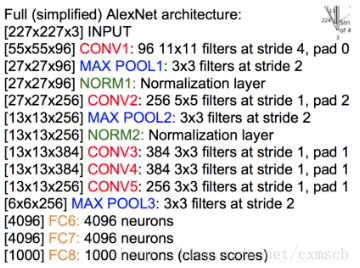
AlexNet模型
具体结构图:

从AlexNet的结构可发现:经典的卷积神经网络结构通常为:
AlexNet卷积层的卷积核边长为5或3,池化层的窗口边长为3,具体参数如图所示:
VGGNet模型
VGGNet模型和AlexNet模型在结构上没有多大变化,在卷积层部位增加了多个卷积层。AlexNet(上)和VGGNet(下)的对比如下图所示:
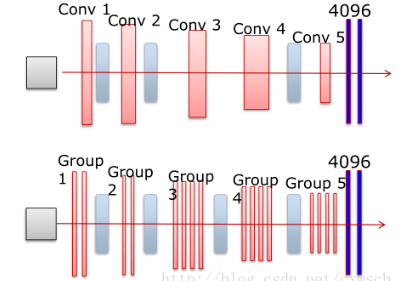
具体参数如图所示:其中CONV3-64:表示卷积核的长和宽为3,个数有64个;POOL2:表示池化窗口i的长和宽都为2,其他类似。

GoogleNet模型
使用了多个不同分辨率的卷积核,最后再对他们得到的feature map按深度融合在一起,结构如图:
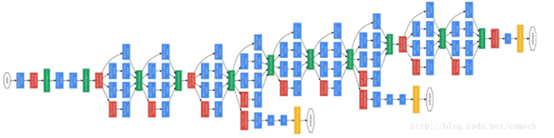
其中,有一些主要的模块称为Inception module,例如:

在Inception module中使用到了很多1*1的卷积核,使用1*1的卷积核,步长为1时,输入的feature map和输出的feature map长宽不会发生改变,但可以通过改变1*1的卷积核的数目,来达到减小feature map的厚度的效果,从而做到一些训练参数的减少。
GoogleNet还有一个特点就是他是全卷积结构(FCN)的,网络的最后没有使用全连接层,一方面这样可以减少参数的数目,不容易过拟合,一方面也带来了一些空间信息的丢失,代替全连接层的是全局平均池化的方法,思想是:为每一个类别输出一个feature map,再取每一个feature map上的平均值,作为最后的softmax层的输入。
ResNet模型
在前面的CNN模型中,都是将输入一层一层地传递下去(图左),当层次比较深时,模型不是很好训练。在ResNet模型中,它将底层学习到的特征核高层学习到的特征进行一个融合(加法运算,图右),这样反向传递时,导数传递得更快,减少梯度弥散得现象。
注意:F(X)得shaoe需要等于X得shape,这样才可以进行相加。

三、Tensorflow代码
主要得函数说明:
卷积层:
tf.nn.conv2d(input, filter, strides, padding,
use_cudnn_on_gpu=None, data_format=None, name=None)
参数说明:
data_format:表示输入得格式,有两种分别为:“NHWC”和“NCHW”,默认为“NHWC”
input:输入是一个4维格式得(图像)数据,数据得shape由data_format决定:当data_format为“NHWC”输入数据得shape表示为[batch,in_height,in_width,in_channels],分别表示训练时一个batch得图片数量,图片高度,图片宽度,图像通道数。当data_format为“NHWC”输入数据得shape表示为[batch, in_channels, in_height, in_width]
filter:卷积核是一个4维格式的数据:shape表示为:[height,width,in_channels, out_channels],分别表示卷积核的高、宽、深度(与输入的in_channels应相同)、输出 feature map的个数(即卷积核的个数)。
strides:表示步长:一个长度为4的一维列表,每个元素跟data_format互相对应,表示在data_format每一维上的移动步长。当输入的默认格式为:“NHWC”,则 strides = [batch , in_height , in_width, in_channels]。其中 batch 和 in_channels
要求一定为1,即只能在一个样本的一个通道上的特征图上进行移动,in_height , in_width表示卷积核在特征图的高度和宽度上移动的布长,即 strideheightstrideheight 和
stridewidthstridewidth 。
padding:表示填充方式:“SAME”表示采用填充的方式,简单地理解为以0填充边缘,当stride为1时,输入和输出的维度相同;“VALID”表示采用不填充的方式,多余地进行丢弃。具体公式:
池化层:
tf.nn.max_pool(
value, ksize,strides,padding,data_format=’NHWC’,name=None)
或者
tf.nn.avg_pool(…)
value:表示池化的输入:一个4维格式的数据,数据的
shape 由 data_format 决定,默认情况下shape 为[batch, height, width, channels]
其他参数与 tf.nn.cov2d 类型
ksize:表示池化窗口的大小:一个长度为4的一维列表,一般为[1, height, width, 1],因不想在batch和channels上做池化,则将其值设为1。
Batch
Nomalization层:
batch_normalization(
x,mean,variance,offset,scale, variance_epsilon,name=None)
mean 和 variance 通过
tf.nn.moments 来进行计算:
batch_mean, batch_var = tf.nn.moments(x,
axes = [0, 1, 2], keep_dims=True),注意axes的输入。对于以feature map 为维度的全局归一化,若feature map 的shape 为[batch, height, width, depth],则将axes赋值为[0, 1, 2]
x 为输入的feature map 四维数据,offset、scale为一维Tensor数据,shape 等于 feature
map 的深度depth。
深度学习之卷积神经网络CNN的更多相关文章
- 深度学习之卷积神经网络CNN及tensorflow代码实例
深度学习之卷积神经网络CNN及tensorflow代码实例 什么是卷积? 卷积的定义 从数学上讲,卷积就是一种运算,是我们学习高等数学之后,新接触的一种运算,因为涉及到积分.级数,所以看起来觉得很复杂 ...
- 深度学习之卷积神经网络CNN及tensorflow代码实现示例
深度学习之卷积神经网络CNN及tensorflow代码实现示例 2017年05月01日 13:28:21 cxmscb 阅读数 151413更多 分类专栏: 机器学习 深度学习 机器学习 版权声明 ...
- 深度学习之卷积神经网络(CNN)的应用-验证码的生成与识别
验证码的生成与识别 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10755361.html 目录 1.验证码的制 ...
- 深度学习之卷积神经网络(CNN)详解与代码实现(一)
卷积神经网络(CNN)详解与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10430073.html 目 ...
- 深度学习之卷积神经网络(CNN)详解与代码实现(二)
用Tensorflow实现卷积神经网络(CNN) 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10737065. ...
- 【转载】 深度学习之卷积神经网络(CNN)详解与代码实现(一)
原文地址: https://www.cnblogs.com/further-further-further/p/10430073.html ------------------------------ ...
- 【神经网络与深度学习】卷积神经网络(CNN)
[神经网络与深度学习]卷积神经网络(CNN) 标签:[神经网络与深度学习] 实际上前面已经发布过一次,但是这次重新复习了一下,决定再发博一次. 说明:以后的总结,还应该以我的认识进行总结,这样比较符合 ...
- 深度学习之卷积神经网络(CNN)
卷积神经网络(CNN)因为在图像识别任务中大放异彩,而广为人知,近几年卷积神经网络在文本处理中也有了比较好的应用.我用TextCnn来做文本分类的任务,相比TextRnn,训练速度要快非常多,准确性也 ...
- 深度学习FPGA实现基础知识10(Deep Learning(深度学习)卷积神经网络(Convolutional Neural Network,CNN))
需求说明:深度学习FPGA实现知识储备 来自:http://blog.csdn.net/stdcoutzyx/article/details/41596663 说明:图文并茂,言简意赅. 自今年七月份 ...
随机推荐
- Opportunity的chance of success的赋值逻辑
该字段的值和另外两个字段Sales Stage和Status都相关. 从下列function module CRM_OPPORT_H_PROB_SET_EC可看出,当status不为代码中的这些硬编码 ...
- 如何查找Fiori UI上某个字段对应的后台存储表的名称
今天微信群里有朋友问到这个问题. 如果是SAPGUI里的事务码,比如MM01,对于开发者来说这个任务非常容易完成. 比如我想知道下图"Sales Unit"这个字段的值到底保存在哪 ...
- pytorch 反向梯度计算问题
计算如下\begin{array}{l}{x_{1}=w_{1} * \text { input }} \\ {x_{2}=w_{2} * x_{1}} \\ {x_{3}=w_{3} * x_{2} ...
- 查看flash的版本
查看当前浏览器的flash版本: http://www.adobe.com/swf/software/flash/about/flashAbout_info_small.swf 针对谷歌浏览器 chr ...
- [luoguP3325][HNOI2012]矿场搭建
P3225 [HNOI2012]矿场搭建 题目描述 煤矿工地可以看成是由隧道连接挖煤点组成的无向图.为安全起见,希望在工地发生事故时所有挖煤点的工人都能有一条出路逃到救援出口处.于是矿主决定在某些挖煤 ...
- http://blog.csdn.net/hhhccckkk/article/details/9313999
http://blog.csdn.net/hhhccckkk/article/details/9313999
- Storm 出现 no jzmq in java.library.path
在真实环境中运行时,在log日志下,查看workpid日志发现出现该错误. 解决办法: 在conf/storm.yaml添加jzmq安装的路径, 我使用的默认安装在/usr/local/lib下 ja ...
- centos7下javac:未找到命令的问题
在linux下编译java程序,执行javac编译生成class文件时,在centos7终端输入如,javac hello.java 会提示未找到指令,但用java -verison测试环境变量 ...
- 中小学信息学奥林匹克竞赛-理论知识考点--IP地址
IP地址同身份证号一样,具有唯一性! 每个人都有一个唯一的标识:身份证号. 互联网中的计算机也一样,具有一个唯一的标识:IP地址. IP地址是一个32位的二进制数,通常被分割为4个“8位二进制数”(也 ...
- SuperSocket 学习
http://www.cnblogs.com/Anaren/p/6382841.html https://www.assetstore.unity3d.com/en/#!/content/21721 ...