Mysql 语句执行顺序
1.这样一个问题,作为一个开发人员需要掌握数据库的哪些东西? 在开发中涉及到数据库,基本上只用到了sql语句,如何写sql以及对其进行优化就比较重要,那些mysql的厚本书籍针对的是DBA,我们只需要学习其中的sql就可以了。
2.既然会写sql是目标,那么怎么才能写好sql.学习下面几点:
1)Mysql的执行顺序,这个是写sql的核心,之前遇到的一些错误就是因为对其不了解;
2)如何进行多表查询,优化,这个是很重要的部分;
3)sql语句的函数,sql提供的函数方便了很多操作;
3.这篇对Mysql语句执行顺序的学习做了总结:
1)Mysql语法顺序,即当sql中存在下面的关键字时,它们要保持这样的顺序:
- select[distinct]
- from
- join(如left join)
- on
- where
- group by
- having
- union
- order by
- limit
2)Mysql执行顺序,即在执行时sql按照下面的顺序进行执行:
- from
- on
- join
- where
- group by
- having
- select
- distinct
- union
- order by
3)针对上面的Mysql语法顺序和执行顺序,循序渐进进行学习:
建立如下表格orders:
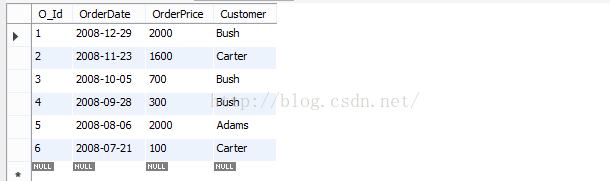
注:下面所有语句符合语法顺序(也不可能不符合,因为会报错^_^),只分析其执行顺序:(join和on属于多表查询,放在最后展示)
语句一:
- select a.Customer
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams'
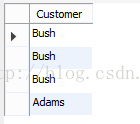
分析一:首先是from语句找到表格,然后根据where得到符合条件的记录,最后select出需要的字段,结果如下:
语句二groupby:groupby要和聚合函数一起使用
- select a.Customer,sum(a.OrderPrice)
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams'
- group by a.Customer
分析二:在from,where执行后,执行group by,同时也根据group by的字段,执行sum这个聚合函数。这样的话得到的记录对group by的字段来说是不重复的,结果如下:
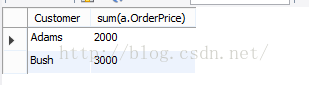
语句三having:
- select a.Customer,sum(a.OrderPrice)
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
分析三:由于where是在group之前执行,那么如何对group by的结果进行筛选,就用到了having,结果如下:
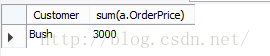
语句四distinct: (为测试,先把数据库中Adams那条记录的OrderPrice改为3000)
- select distinct sum(a.OrderPrice)
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1700
分析四:将得到一条记录(没有distinct,将会是两条同样的记录):

语句五union:完全是对select的结果进行合并(默认去掉重复的记录):
- select distinct sum(a.OrderPrice) As Order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1500
- union
- select distinct sum(a.OrderPrice) As Order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
分析五:默认去掉重复记录(想保留重复记录使用union all),结果如下:

语句六order by:
- select distinct sum(a.OrderPrice) As order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1500
- union
- select distinct sum(a.OrderPrice) As order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
- order by order1
分析:升序排序,结果如下:

语句七limit:
- select distinct sum(a.OrderPrice) As order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1500
- union
- select distinct sum(a.OrderPrice) As order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
- order by order1
- limit 1
分析七:取出结果中的前1条记录,结果如下:
语句八(上面基本讲完,下面是join 和 on):

- select distinct sum(a.OrderPrice) As order1,sum(d.OrderPrice) As order2
- from orders a
- left join (select c.* from Orders c) d
- on a.O_Id = d.O_Id
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1500
- union
- select distinct sum(a.OrderPrice) As order1,sum(e.OrderPrice) As order2
- from orders a
- left join (select c.* from Orders c) e
- on a.O_Id = e.O_Id
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
- order by order1
- limit 1
分析八:上述语句其实join on就是多连接了一张表,而且是两张一样的表,都是Orders。 执行过程是,在执行from关键字之后根据on指定的条件,把left join指定的表格数据附在from指定的表格后面,然后再执行where字句。
注:
1)使用distinct要写在所有要查询字段的前面,后面有几个字段,就代表修饰几个字段,而不是紧随distinct的字段;
2)group by执行后(有聚合函数),group by后面的字段在结果中一定是唯一的,也就不需要针对这个字段用distinct;
转载:https://blog.csdn.net/jintao_ma/article/details/51253356
Mysql 语句执行顺序的更多相关文章
- mysql 语句执行顺序问题
今天在写程序的时候,做分页查找时无意中,将计算数据库查询数量的语句,放到了limit之中,导致出现了bug. 所以发现以下问题: select count(1) from table limit 0, ...
- MySQL语句执行顺序
执行顺序:见:http://www.cnblogs.com/rollenholt/p/3776923.html 下面我们来具体分析一下查询处理的每一个阶段 FORM: 对FROM的左边的表和右边的表计 ...
- mysql语句执行顺序图示
- 关于sql和MySQL的语句执行顺序(必看!!!)
今天遇到一个问题就是mysql中insert into 和update以及delete语句中能使用as别名吗?目前还在查看,但是在查阅资料时发现了一些有益的知识,给大家分享一下,就是关于sql以及My ...
- (转)关于sql和MySQL的语句执行顺序(必看!!!)
原文:https://blog.csdn.net/u014044812/article/details/51004754 https://blog.csdn.net/j080624/article/d ...
- MySQL的语句执行顺序
MySQL的语句执行顺序 MySQL的语句一共分为11步,如下图所标注的那样,最先执行的总是FROM操作,最后执行的是LIMIT操作.其中每一个操作都会产生一张虚拟的表,这个虚拟的表作为一个处理的输入 ...
- 关于sql和MySQL的语句执行顺序
sql和mysql执行顺序,发现内部机制是一样的.最大区别是在别名的引用上. 一.sql执行顺序 (1) from (3) join (2) on (4) where (5) group by(开始使 ...
- python 3 mysql sql逻辑查询语句执行顺序
python 3 mysql sql逻辑查询语句执行顺序 一 .SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_t ...
- mysql优化必知(mysql的语句执行顺序)
MySQL的语句执行顺序 MySQL的语句一共分为11步,如下图所标注的那样,最先执行的总是FROM操作,最后执行的是LIMIT操作.其中每一个操作都会产生一张虚拟的表,这个虚拟的表作为一个处理的输入 ...
随机推荐
- 关于C语言中printf函数“输出歧视”的问题
目录 关于C语言中printf函数"输出歧视"的问题 问题描述 探索问题原因 另一种研究方法 问题结论 关于C语言中printf函数"输出歧视"的问题 问题描述 ...
- linux vmalloc和kmalloc
kmalloc是内核低端内存的分配,而vmalloc对应内核高端内存的分配.kmalloc()分配的内存处于3GB-high_memory之间,这一段内核空间与物理内存的映射. kmalloc保证分配 ...
- [USACO06DEC]牛的野餐Cow Picnic DFS
题目描述 The cows are having a picnic! Each of Farmer John's K (1 ≤ K ≤ 100) cows is grazing in one of N ...
- Ngnix,EA(Enterprise Architect)
nginx Nginx (engine x) 是一个高性能的HTTP和反向代理服务,也是一个IMAP/POP3/SMTP服务.Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点 ...
- Macaca,Maven,MVC框架
Macaca:Macaca是阿里开源的一套完整的自动化测试解决方案.同时支持PC和移动端测试,支持的语言有JS,Java,Python. Maven:java,Maven项目对象模型(POM),可以通 ...
- Android 给app加入百度地图
1.获取sha1值 (1)win+R进入cmd窗口 (2)输入以下代码 C:\SoftApplication\javajdk\jdk1.8.0_151\bin>keytool -list -v ...
- Android RecyclerView组件和 Spinner(下拉列表框)
1.RecyclerView <1>知识点介绍 RecyclerView 比 ListView 更高级且更具灵活性. 它是一个用于显示庞大数据集的容器,可通过保持有限数量的视图进行非常有效 ...
- CSS column 布局总结
有时候 第一列 底部会跑到顶部那里一部分.这时候应该这样. 在 每个 div前加上 display:inline-block
- HDOJ3085 Nightmare II 双向BFS
重构一遍就A了...但这样效率太低了...莫非都要重构???QWQ 每一秒男同志bfs3层,女同志bfs1层.注意扩展状态时,要判一下合不合法再扩展,而不是只判扩展的状态合不合法,否则有可能由非法的走 ...
- CDQZ Day1
#include<cassert> #include<cstdio> #include<vector> using namespace std; ,maxt=,ma ...