【Python3 爬虫】14_爬取淘宝上的手机图片
现在我们想要使用爬虫爬取淘宝上的手机图片,那么该如何爬取呢?该做些什么准备工作呢?
首先,我们需要分析网页,先看看网页有哪些规律
打开淘宝网站http://www.taobao.com/
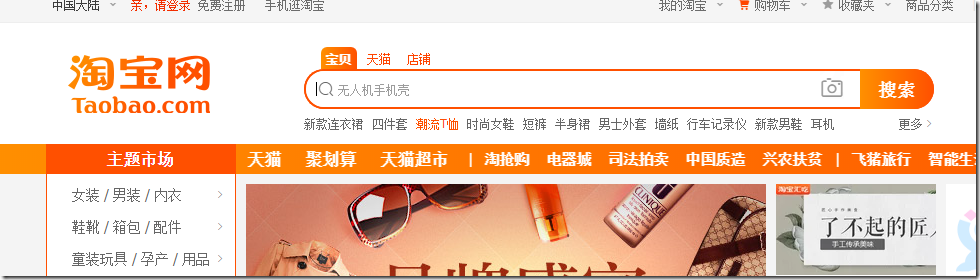
我们可以看到左侧是主题市场,将鼠标移动到【女装/男装/内衣】这一栏目,我们可以看到更细类的展示
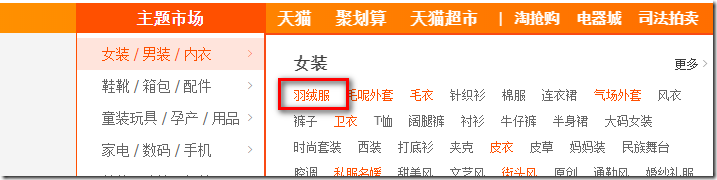
假如我们现在需要爬取【羽绒服】,那么我们进入到【羽绒服】衣服这个界面
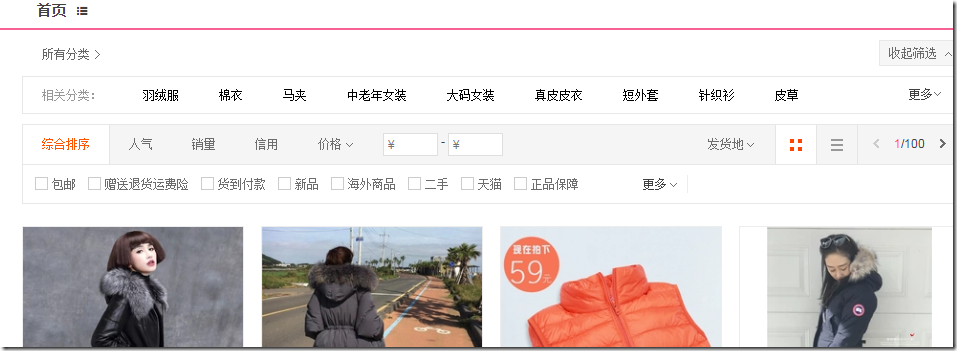
此时查看浏览器地址,我们可以看到

网址复制到word或者其他地方会发生url转码
我们可以选中【羽绒服模块的第1,2,3页进行网址对比】,对比结果如下:
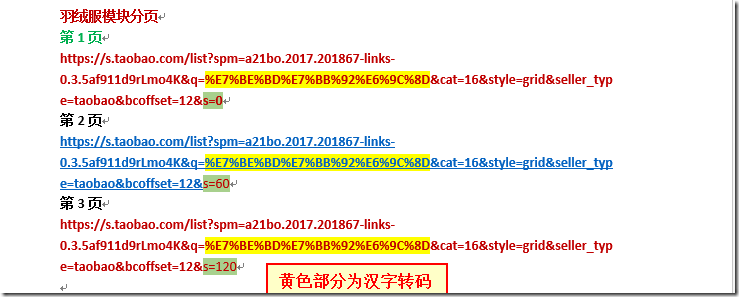
从上图我们可以看出:三页的s值都是相差60
然后我们再看下图片地址:
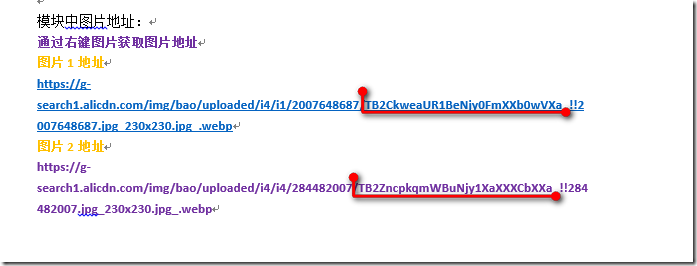
图片中标记的地方或许是两个图片最大的差别,于是打开源代码搜索
图片1搜索结果

图片2搜索结果

从两个网址我们发现了共同的特征:都是以"pic_url":"//开头,网址分析到此结束,那么我们接下来就写代码了。
代码如下:
import urllib.request
import re
#设置关键字
keywords = "羽绒服"
#quote函数进行url编码(屏蔽特殊的字符)
key = urllib.request.quote(keywords)
#设置User-Agent
headers=("User_Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0")
#自定义opener
opener = urllib.request.build_opener()
opener.addheaders = [headers]
urllib.request.install_opener(opener)
#循环遍历抓取
for i in range(0,2):
url = "https://s.taobao.com/list?spm=a21bo.2017.201867-links-0.3.5af911d9rLmo4K&q="+key+"&cat=16&style=grid&seller_type=taobao&bcoffset=12&s="+str(i*60)
#print(url)
content = urllib.request.urlopen(url).read().decode("utf-8","ignore")
rule = '"pic_url":"//(.*?)"' #正则匹配
imglist = re.compile(rule).findall(content) #获取图片列表
for j in range(0,len(imglist)):
img = imglist[j]
imgurl = "http://"+img
file = "D://source//img//"+str(i)+str(j)+".jpg"
urllib.request.urlretrieve(imgurl,filename=file)
爬取完毕后,我们可以打开D:\source\img查看
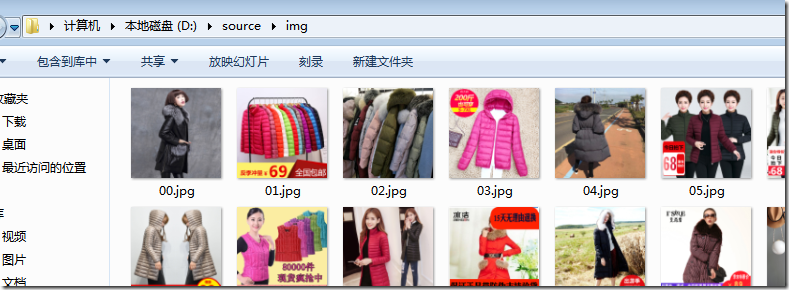
我们已经成功爬取,并且爬取的图片与页面上是一致的。
【Python3 爬虫】14_爬取淘宝上的手机图片的更多相关文章
- 甜咸粽子党大战,Python爬取淘宝上的粽子数据并进行分析
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 爬虫 爬取淘宝数据,本次采用的方法是:Selenium控制Chrome浏览 ...
- 学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫. 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周.基于以上原因固放弃python,选择java为语言来进行开发.等之后有时间再尝试pytho ...
- Python 002- 爬虫爬取淘宝上耳机的信息
参照:https://mp.weixin.qq.com/s/gwzym3Za-qQAiEnVP2eYjQ 一般看源码就可以解决问题啦 #-*- coding:utf-8 -*- import re i ...
- python 网路爬虫(二) 爬取淘宝里的手机报价并以价格排序
今天要写的是之前写过的一个程序,然后把它整理下,巩固下知识点,并对之前的代码进行一些改进. 今天要爬取的是淘宝里的关于手机的报价的信息,并按照自己想要价格来筛选. 要是有什么问题希望大佬能指出我的错误 ...
- 【Python爬虫案例学习】python爬取淘宝里的手机报价并以价格排序
第一步: 先分析这个url,"?"后面的都是它的关键字,requests中get函数的关键字的参数是params,post函数的关键字参数是data, 关键字用字典的形式传进去,这 ...
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- selenium跳过webdriver检测并爬取淘宝我已购买的宝贝数据
简介 上一个博文已经讲述了如何使用selenium跳过webdriver检测并爬取天猫商品数据,所以在此不再详细讲,有需要思路的可以查看另外一篇博文. 源代码 # -*- coding: utf-8 ...
随机推荐
- 关于MYSQL表记录字段换行符回车符处理
http://hualong.iteye.com/blog/1933023 今天遇到一个非常奇葩的问题,数据库表中明明有值却查询不不出来,而然一次从单元格中复制到sql中,发现右侧单引号换行了,我初步 ...
- Android日志打印类LogUtils,能够定位到类名,方法名以及出现错误的行数并保存日志文件
Android日志打印类LogUtils,能够定位到类名,方法名以及出现错误的行数并保存日志文件 在开发中,我们常常用打印log的方式来调试我们的应用.在Java中我们常常使用方法System.out ...
- AC日记——Magazine Ad codeforces 803d
803D - Magazine Ad 思路: 二分答案+贪心: 代码: #include <cstdio> #include <cstring> #include <io ...
- [jquery] 删除文章的时候弹出确认窗口
[<a href="{:U(GROUP_NAME . '/Category/delCate')}/id/{$v.id}" onclick='return del();'> ...
- openssl生成证书链多级证书
操作系统CentOS6.6 注:windows版本的Openssl无法做这个实验,由于所有编译的window版本openssl没有对openssl目录重新定向,导致在windows下找不到pki目录 ...
- Codeforces Round #406 (Div. 2) D. Legacy (线段树建图dij)
D. Legacy time limit per test 2 seconds memory limit per test 256 megabytes input standard input out ...
- 【矩阵乘法】图中长度为k的路径的计数
样例输入 4 2 0 1 1 0 0 0 1 0 0 0 0 1 1 0 0 0 样例输出 6 #include<cstdio> #include<vector> using ...
- 【平面图】【最小割】【最短路】【Heap-Dijkstra】bzoj1001 [BeiJing2006]狼抓兔子
http://wenku.baidu.com/view/8f1fde586edb6f1aff001f7d.html #include<cstdio> #include<queue&g ...
- 【树链剖分】【线段树】bzoj3083 遥远的国度
记最开始的根为root,换根之后,对于当前的根rtnow和询问子树U而言, ①rtnow==U,询问整棵树 ②fa[rtnow]==U,询问除了rtnow所在子树以外的整棵树 ③rtnow在U的子树里 ...
- [POI2008]Station
题目大意: 给定一棵n个结点的树,求一个点x作为根,使得所有结点到x的距离和最小. 思路: 树形DP. 首先考虑将1作为根的情况. 很显然我们可以用一遍O(n)的DFS预处理出每个结点所对应子树大小s ...