scrapy学习-爬取天天基金网基金列表
描述
爬取http://fundact.eastmoney.com/banner/pg.html#ln网站的数据,
要求:爬取所有基金(有27页)的基金代码、基金名称、单位净值、日期、日增长率、近1周、近1月、近3月、近6月、近1年、近2年、近3年、今年来、成立来和手续费|起购金额。将爬取的数据放入mariaDB数据库中。
环境描述
python 3.6.3
scrapy 1.4.0
步骤记录
创建scrapy项目
进入打算放代码的地方(F:\myPycharm_ws),创建项目funds,执行命令:
scrapy startproject funds
创建好项目后,查看会发现生成一些文件,这里对相关文件做下说明
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
接下来就可以使用pycharm打开项目进行开发了
设置在pycharm下运行scrapy项目
step 1:在funds项目里创建一个py文件(项目的任何地方都行)
from scrapy import cmdline
cmdline.execute("scrapy crawl fundsList".split())
step 2:配置 Run --> Edit Configurations (本人测试,不配置该步骤,也可运行)
运行方式:直接运行该.py文件即可。
分析如何获取数据
由于通过ajax请求即可获取到列表的全部结构化数据,所以我决定通过谷歌浏览器分析得到请求数据的url:
(参考:https://www.jianshu.com/p/1e35bcb1cf21)
通过分析,发现接口:https://fundapi.eastmoney.com/fundtradenew.aspx?ft=pg&sc=1n&st=desc&pi=1&pn=100&cp=&ct=&cd=&ms=&fr=&plevel=&fst=&ftype=&fr1=&fl=0&isab=
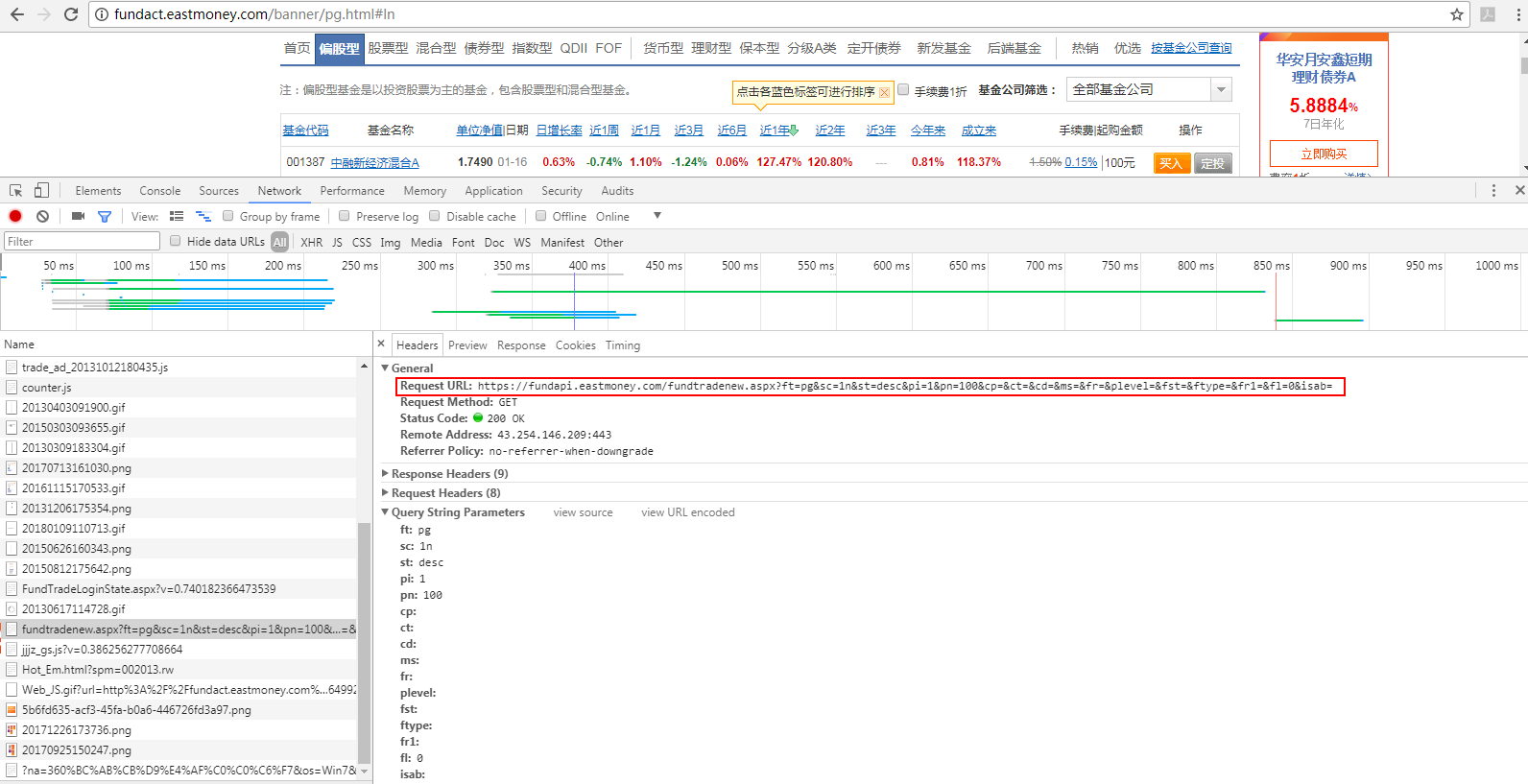
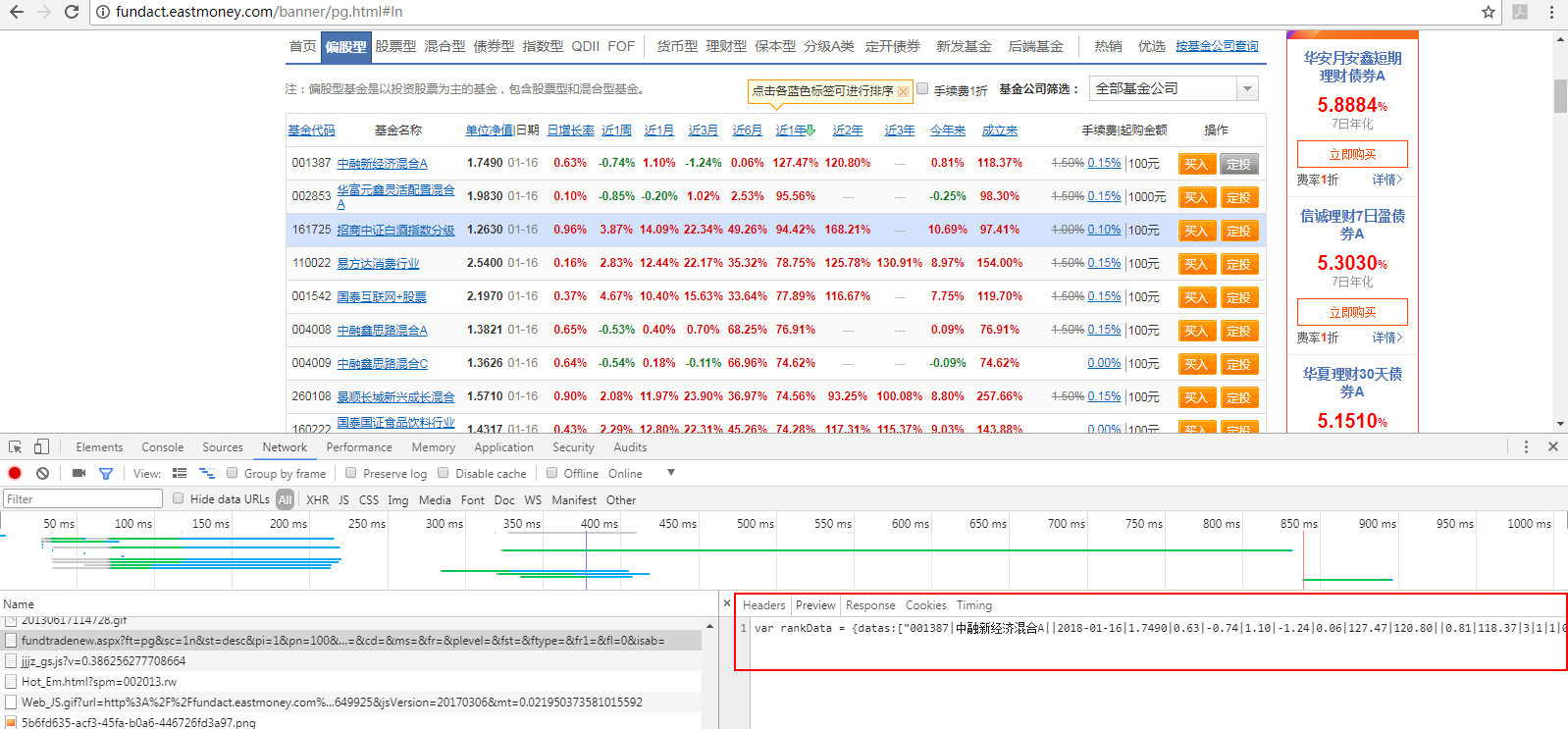
查看,接口返回的数据,发现并非直接是一个json,而是形如这样的:我们只需取出datas项就行

OK,那我直接请求获取这个接口的数据即可。
编写代码
step 1:设置item
class FundsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field() # 基金代码
name = scrapy.Field() # 基金名称
unitNetWorth = scrapy.Field() # 单位净值
day = scrapy.Field() # 日期
dayOfGrowth = scrapy.Field() # 日增长率
recent1Week = scrapy.Field() # 最近一周
recent1Month = scrapy.Field() # 最近一月
recent3Month = scrapy.Field() # 最近三月
recent6Month = scrapy.Field() # 最近六月
recent1Year = scrapy.Field() # 最近一年
recent2Year = scrapy.Field() # 最近二年
recent3Year = scrapy.Field() # 最近三年
fromThisYear = scrapy.Field() # 今年以来
fromBuild = scrapy.Field() # 成立以来
serviceCharge = scrapy.Field() # 手续费
upEnoughAmount = scrapy.Field() # 起够金额
pass
step 2:编写spider
import scrapy
import json
from scrapy.http import Request
from funds.items import FundsItem
class FundsSpider(scrapy.Spider):
name = 'fundsList' # 唯一,用于区别Spider。运行爬虫时,就要使用该名字
allowed_domains = ['fund.eastmoney.com'] # 允许访问的域
# 初始url。在爬取从start_urls自动开始后,服务器返回的响应会自动传递给parse(self, response)方法。
# 说明:该url可直接获取到所有基金的相关数据
# start_url = ['http://fundact.eastmoney.com/banner/pg.html#ln']
# custome_setting可用于自定义每个spider的设置,而setting.py中的都是全局属性的,当你的scrapy工程里有多个spider的时候这个custom_setting就显得很有用了
# custome_setting = {
#
# }
# spider中初始的request是通过调用 start_requests() 来获取的。 start_requests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成 Request 。
# 重写start_requests也就不会从start_urls generate Requests了
def start_requests(self):
url = 'https://fundapi.eastmoney.com/fundtradenew.aspx?ft=pg&sc=1n&st=desc&pi=1&pn=3000&cp=&ct=&cd=&ms=&fr=&plevel=&fst=&ftype=&fr1=&fl=0&isab='
requests = []
request = scrapy.Request(url,callback=self.parse_funds_list)
requests.append(request)
return requests
def parse_funds_list(self,response):
datas = response.body.decode('UTF-8')
# 取出json部门
datas = datas[datas.find('{'):datas.find('}')+1] # 从出现第一个{开始,取到}
# 给json各字段名添加双引号
datas = datas.replace('datas', '\"datas\"')
datas = datas.replace('allRecords', '\"allRecords\"')
datas = datas.replace('pageIndex', '\"pageIndex\"')
datas = datas.replace('pageNum', '\"pageNum\"')
datas = datas.replace('allPages', '\"allPages\"')
jsonBody = json.loads(datas)
jsonDatas = jsonBody['datas']
fundsItems = []
for data in jsonDatas:
fundsItem = FundsItem()
fundsArray = data.split('|')
fundsItem['code'] = fundsArray[0]
fundsItem['name'] = fundsArray[1]
fundsItem['day'] = fundsArray[3]
fundsItem['unitNetWorth'] = fundsArray[4]
fundsItem['dayOfGrowth'] = fundsArray[5]
fundsItem['recent1Week'] = fundsArray[6]
fundsItem['recent1Month'] = fundsArray[7]
fundsItem['recent3Month'] = fundsArray[8]
fundsItem['recent6Month'] = fundsArray[9]
fundsItem['recent1Year'] = fundsArray[10]
fundsItem['recent2Year'] = fundsArray[11]
fundsItem['recent3Year'] = fundsArray[12]
fundsItem['fromThisYear'] = fundsArray[13]
fundsItem['fromBuild'] = fundsArray[14]
fundsItem['serviceCharge'] = fundsArray[18]
fundsItem['upEnoughAmount'] = fundsArray[24]
fundsItems.append(fundsItem)
return fundsItems
step 3:配置settings.py
custome_setting可用于自定义每个spider的设置,而setting.py中的都是全局属性的,当你的scrapy工程里有多个spider的时候这个custom_setting就显得很有用了。
但是我目前项目暂时只有一个爬虫,所以暂时使用setting.py设置spider。
设置了DEFAULT_REQUEST_HEADERS(本次爬虫由于是请求接口,该项不配置也可)
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Cookie':'st_pvi=72856792768813; UM_distinctid=1604442b00777b-07f0a512f81594-5e183017-100200-1604442b008b52; qgqp_b_id=f10107e9d27d5fe2099a361a52fcb296; st_si=08923516920112; ASP.NET_SessionId=s3mypeza3w34uq2zsnxl5azj',
'Host':'fundapi.eastmoney.com',
'Referer':'http://fundact.eastmoney.com/banner/pg.html',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
}
设置ITEM_PIPELINES
ITEM_PIPELINES = {
'funds.pipelines.FundsPipeline': 300,
}
pipelines.py,将数据写入我本地数据库里
import pymysql.cursors
class FundsPipeline(object):
def process_item(self, item, spider):
# 连接数据库
connection = pymysql.connect(host='localhost',
user='root',
password='123',
db='test',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
sql = "INSERT INTO funds(code,name,unitNetWorth,day,dayOfGrowth,recent1Week,recent1Month,recent3Month,recent6Month,recent1Year,recent2Year,recent3Year,fromThisYear,fromBuild,serviceCharge,upEnoughAmount)\
VALUES('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" % (
item['code'], item['name'], item['unitNetWorth'], item['day'], item['dayOfGrowth'], item['recent1Week'], \
item['recent1Month'], item['recent3Month'], item['recent6Month'], item['recent1Year'], item['recent2Year'],
item['recent3Year'], item['fromThisYear'], item['fromBuild'], item['serviceCharge'], item['upEnoughAmount'])
with connection.cursor() as cursor:
cursor.execute(sql) # 执行sql
connection.commit() # 提交到数据库执行
connection.close()
return item
错误处理
ModuleNotFoundError: No module named 'pymysql'
解决办法:(参考:https://stackoverflow.com/questions/33446347/no-module-named-pymysql)
pip install PyMySQL
1366, "Incorrect string value: '\xE6\x99\xAF\xE9\xA1\xBA...' for column 'name' at row 1"
即:入库的中文是乱码
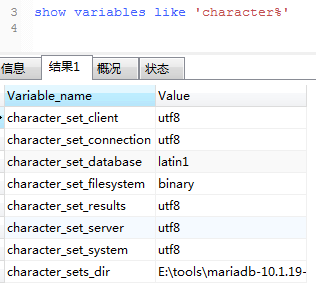
查看数据库编码,为latin1。
解决办法:
alter table funds convert to character set utf8
scrapy学习-爬取天天基金网基金列表的更多相关文章
- Scrapy实战篇(七)之爬取爱基金网站基金业绩数据
本篇我们以scrapy+selelum的方式来爬取爱基金网站(http://fund.10jqka.com.cn/datacenter/jz/)的基金业绩数据. 思路:我们以http://fund.1 ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- 【Scrapy(四)】scrapy 分页爬取以及xapth使用小技巧
scrapy 分页爬取以及xapth使用小技巧 这里以爬取www.javaquan.com为例: 1.构建出下一页的url: 很显然通过dom树,可以发现下一页所在的a标签 2.使用scrapy的 ...
- Java学习-042-获取目录文件列表(当前,级联)
以下三个场景,在我们日常的测试开发中经常遇到: 软件自动化测试,在进行参数测试时,我们通常将所有相似功能的参数文件统一放在一个目录中,在自动化程序启动的时候,获取资源参数文件夹中所有参数文件,然后解析 ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
- 如何提高scrapy的爬取效率
提高scrapy的爬取效率 增加并发: 默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置 ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
随机推荐
- 序列化表单为json对象,datagrid带额外参提交一次查询 后台用Spring data JPA 实现带条件的分页查询 多表关联查询
查询窗口中可以设置很多查询条件 表单中输入的内容转为datagrid的load方法所需的查询条件向原请求地址再次提出新的查询,将结果显示在datagrid中 转换方法看代码注释 <td cols ...
- c#冒泡排序算法和快速排序算法
依次比较相邻的两个数,将小数放在前面,大数放在后面. 第1趟: 首先比较第1个和第2个数,将小数放前,大数放后.然后比较第2个数和第3个数,将小数放前,大数放后,如此继续,直至比较最后两个数,将小数放 ...
- js省市区级联选择联动
<!DOCTYPE html> <html lang="zh-cn"> <head> <meta http-equiv="Con ...
- 【CodeForces 660D】Number of Parallelograms(n个点所能组成的最多平行四边形数量)
You are given n points on a plane. All the points are distinct and no three of them lie on the same ...
- MySql Connector/c++8中JSON处理Demo
#include <iostream> #include <vector> #include <mysqlx/xdevapi.h> using std::cout; ...
- ubuntu系统快速搭建开发环境
1.免密登陆 1.1 原理 ssh协议中用到了对称加密和非对称加密,如果不了解可以百度一下,原理引用一下这篇博客 在ssh中,非对称加密被用来在会话初始化阶段为通信双方进行会话密钥的协商.由于非对称加 ...
- JavaScript文本框焦点事件
效果图如下: <!-- 当文本框获得焦点时候,如果文本框内容是 请输入搜索关键字 清空文本框,输入内容变黑色 --> <!-- 当文本框失去焦点时候,如果文本框无内容,则添加灰色的 ...
- Python起源与发展
Python的创始人为吉多*范罗苏姆(Gudio van Rossum) 1.1989年的圣诞节期间,吉多*范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的解释程序,作为ABC语言的一种继承. 2. ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- windows程序内部运行机制
Windows程序内部运行机制 2007-10-21 19:52 1010人阅读 评论(0) 收藏 举报 windowsvc++applicationcallbackwinapistructure W ...