吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import cluster
from sklearn.metrics import adjusted_rand_score
from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7):
X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std)
return X,labels_true #密度聚类DBSCAN模型
def test_DBSCAN(*data):
X,labels_true=data
clst=cluster.DBSCAN()
predicted_labels=clst.fit_predict(X)
print("ARI:%s"% adjusted_rand_score(labels_true,predicted_labels))
print("Core sample num:%d"%len(clst.core_sample_indices_)) # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5)
# 调用 test_DBSCAN 函数
test_DBSCAN(X,labels_true)
def test_DBSCAN_epsilon(*data):
'''
测试 DBSCAN 的聚类结果随 eps 参数的影响
'''
X,labels_true=data
epsilons=np.logspace(-1,1.5)
ARIs=[]
Core_nums=[]
for epsilon in epsilons:
clst=cluster.DBSCAN(eps=epsilon)
predicted_labels=clst.fit_predict(X)
ARIs.append( adjusted_rand_score(labels_true,predicted_labels))
Core_nums.append(len(clst.core_sample_indices_))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,2,1)
ax.plot(epsilons,ARIs,marker='+')
ax.set_xscale('log')
ax.set_xlabel(r"$\epsilon$")
ax.set_ylim(0,1)
ax.set_ylabel('ARI') ax=fig.add_subplot(1,2,2)
ax.plot(epsilons,Core_nums,marker='o')
ax.set_xscale('log')
ax.set_xlabel(r"$\epsilon$")
ax.set_ylabel('Core_Nums') fig.suptitle("DBSCAN")
plt.show() # 调用 test_DBSCAN_epsilon 函数
test_DBSCAN_epsilon(X,labels_true)

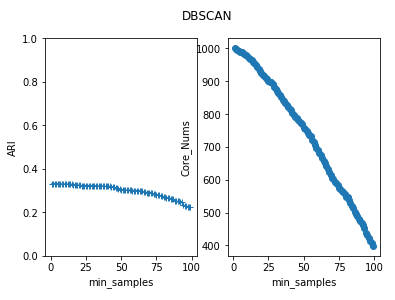
def test_DBSCAN_min_samples(*data):
'''
测试 DBSCAN 的聚类结果随 min_samples 参数的影响
'''
X,labels_true=data
min_samples=range(1,100)
ARIs=[]
Core_nums=[]
for num in min_samples:
clst=cluster.DBSCAN(min_samples=num)
predicted_labels=clst.fit_predict(X)
ARIs.append( adjusted_rand_score(labels_true,predicted_labels))
Core_nums.append(len(clst.core_sample_indices_)) ## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,2,1)
ax.plot(min_samples,ARIs,marker='+')
ax.set_xlabel( "min_samples")
ax.set_ylim(0,1)
ax.set_ylabel('ARI') ax=fig.add_subplot(1,2,2)
ax.plot(min_samples,Core_nums,marker='o')
ax.set_xlabel( "min_samples")
ax.set_ylabel('Core_Nums') fig.suptitle("DBSCAN")
plt.show() # 调用 test_DBSCAN_min_samples 函数
test_DBSCAN_min_samples(X,labels_true)
吴裕雄 python 机器学习——密度聚类DBSCAN模型的更多相关文章
- 吴裕雄 python 机器学习——层次聚类AgglomerativeClustering模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——支持向量机非线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——KNN回归KNeighborsRegressor模型
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from skle ...
- 吴裕雄 python 机器学习——KNN分类KNeighborsClassifier模型
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from skle ...
- 吴裕雄 python 机器学习——半监督学习LabelSpreading模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- 吴裕雄 python 机器学习——支持向量机线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np import matplotlib.pyplot as plt from sklearn import mixture from sklearn.metrics ...
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
随机推荐
- key things of ARC
[key things of ARC] 1.使用原则. 2.__weak变量的使用问题 3.__autoreleasing的使用问题 4.block中易造成的强引用环问题. 5.栈变量被初始化为nil ...
- EF添加和修改
(1)//添加操作 public bool addDate() { try { //声明上下文 a_context = new AEntities(); //声明数据模型实体 //执行代码时候会先验证 ...
- SpringBoot:阿里数据源配置、JPA显示sql语句、格式化JPA查询的sql语句
1 数据源和JPA配置 1.1 显示sql配置和格式化sql配置 者两个配置都是属于hibernate的配置,但是springdatajpa给我们简化了:所有hibernate的配置都在jpa下面的p ...
- 基于 EntityFramework 的数据库主从读写分离架构(1) - 原理概述和基本功能实现
回到目录,完整代码请查看(https://github.com/cjw0511/NDF.Infrastructure)中的目录: src\ NDF.Data.EntityFramew ...
- Oracle——创建和管理表
一.常见的数据库对象 对象 描述 表 基本的数据存储集合,由行和列组成 视图 从表中抽出的逻辑上相关的数据集合 序列 提供有规律的数值 索引 提高查询的效率 同以词 给对象起别名 二.Oracle 数 ...
- SpringMVC——映射请求参数
Spring MVC 通过分析处理方法的签名,将 HTTP 请求信息绑定到处理方法的相应人参中. @PathVariable @RequestParam @RequestHeader 等) Sprin ...
- 一、office web apps 部署
原文出处:http://www.cnblogs.com/yanweidie/p/4516164.html 原文出处:https://www.cnblogs.com/poissonnotes/p/323 ...
- javaweb dom4j解析xml文档
1.什么是dom4j dom4j是一个Java的XML API,是jdom的升级品,用来读写XML文件的.dom4j是一个十分优秀的JavaXML API,具有性能优异.功能强大和极其易使用的特点,它 ...
- 分组背包----HDU1712 ACboy needs your help
很简单的一道分组背包入门问题.不多解释了. #include <iostream> #include <cstdio> #include <cstring> usi ...
- ubuntu 下python安装及hello world
//@desn:ubuntu 下python安装及hello world //@desn:码字不宜,转载请注明出处 //@author:张慧源 <turing_zhy@163.com> ...