Hadoop压缩之CompressionCodecFactory
1.CompressionCodecFactory简介
当在读取一个压缩文件的时候,可能并不知道压缩文件用的是哪种压缩算法,那么无法完成解压任务。在Hadoop中,CompressionCodecFactory通过使用其getCodec()方法,可以通过文件扩展名映射到一个与其对应的CompressionCodec类,如README.txt.gz通过getCodec()方法后,GipCodec类。关于Hadoop的压缩,可以参考我的博文《Hadoop压缩》http://www.cnblogs.com/robert-blue/p/4155710.html
实例:使用由文件扩展名推断而来的codec来对文件进行解压缩
package cn.roboson.codec; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionInputStream; /*
* 通过CompressionCodeFactory推断CompressionCodec
* 1.先从本地上传一个.gz后缀的文件到Hadoop
* 2.通过文件后缀推断出所用的压缩算法
* 3.解压上传的压缩文件到统一个目录下
*/
public class StreamCompressor02 { public static void main(String[] args) { Configuration conf = new Configuration();
conf.addResource("core-site.xml"); try {
FileSystem fs = FileSystem.get(conf); //本地文件
String localsrc="/home/roboson/桌面/README.txt.gz";
Path localPath= new Path(localsrc); //目的处路径
String hadoopdsc="/roboson/README.txt.gz";
Path hadoopPath = new Path(hadoopdsc); //复制前/roboson目录下的文件列表
FileStatus[] files = fs.listStatus(new Path("/roboson/"));
System.out.println("复制前:");
for (FileStatus fileStatus : files) {
System.out.println(fileStatus.getPath());
} //复制本地文件到Hadoop文件系统中
fs.copyFromLocalFile(localPath,hadoopPath); //复制后/roboson目录下的文件列表
files = fs.listStatus(new Path("/roboson/"));
System.out.println("复制后:");
for (FileStatus fileStatus : files) {
System.out.println(fileStatus.getPath());
} //获得一个CompressionCodecFactory实例来推断哪种压缩算法
CompressionCodecFactory facotry = new CompressionCodecFactory(conf); //通过CompressionCodecFactory推断出一个压缩类,用于解压
CompressionCodec codec =facotry.getCodec(hadoopPath);
if(codec==null){
System.out.println("没有找到该类压缩");
System.exit(1);
} /*
* 1.CompressionCodecFactory的removeSuffix()用来返回一个文件名,这个文件名==压缩文件的后缀名去掉
* 如README.txt.gz调用removeSuffix()方法后,返回的是README.txt
*
* 2.CompressionCodec的getDefaultExtension()方法返回的是一个压缩算法的压缩扩展名,如gzip的是.gz
*/
String uncodecUrl=facotry.removeSuffix(hadoopdsc, codec.getDefaultExtension());
System.out.println("压缩算法的生成文件的扩展名:"+codec.getDefaultExtension());
System.out.println("解压后生成的文件名:"+uncodecUrl); //在Hadoop中创建解压后的文件
FSDataOutputStream out = fs.create(new Path(uncodecUrl)); //创建输入数据流,并用CompressionCodec的createInputStream()方法,将输入数据流中读取的数据解压
FSDataInputStream in = fs.open(new Path(hadoopdsc));
CompressionInputStream codecIn = codec.createInputStream(in); //将输入数据流写入到 输出数据流
IOUtils.copyBytes(codecIn, out, conf,true); //解压后/roboson目录下的文件列表
files = fs.listStatus(new Path("/roboson/"));
System.out.println("解压后");
for (FileStatus fileStatus : files) {
System.out.println(fileStatus.getPath());
} //查看解压后的内容
System.out.println("解压后的内容:");
in=fs.open(new Path(uncodecUrl));
IOUtils.copyBytes(in,System.out, conf,true);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
运行结果:
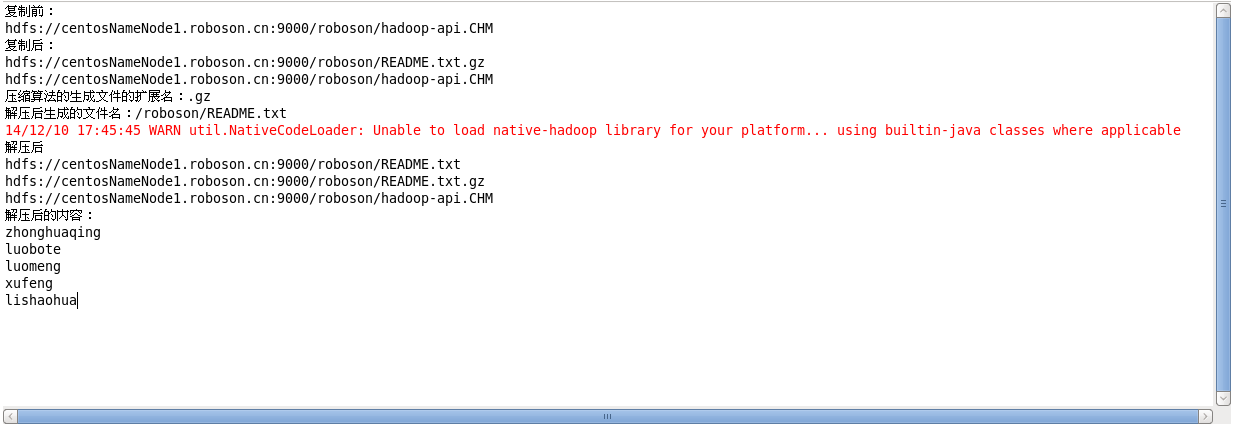
2.原生类库
什么是 原生类库?就是本地类库(native),例如,Java也有实现的压缩和解压,但是如上所示,用到的gzip并非java实现,而是Linux系统自带的,我们都知道gzip是Linux中常用的压缩工具。Hadoop本身包含有32位和64位Linux构建的压缩代码库(位于lib/native目录)。对于其它平台,需要根据Hadoop wiki的指令更具需要来编译代码库。

可以通过Java系统的java.library.path属性来指定原生代码库。bin文件夹中的hadoop脚本可以设置这个属性。默认情况下,Hadoop会根据自身运行的平台搜索原生代码库,如果找到相应的代码库就会自动加载。所以,无需为了使用原声代码库而修改任何设置。还有为了性能,最好使用原生类库来实现压缩和解压缩,因为效率更高!Hadoop中的压缩哪些是原生实现的,哪些是Java实现的?
| 压缩格式 | Java实现 | 原生实现 |
| DEFLATE | 是 | 是 |
| gzip | 是 | 是 |
| gzip2 | 是 | 否 |
| LZO | 否 |
是 |
Hadoop压缩之CompressionCodecFactory的更多相关文章
- hadoop压缩框架
一般来说,计算机处理的数据都存在一些冗余度,同时数据中间,尤其是相邻数据间存在着相关性,所以可以通过一些有别于原始编码的特殊编码方式来保存数据,使数据占用的存储空间比较小,这个过程一般叫压缩.和压缩对 ...
- hadoop压缩配置
为何要使用压缩,压缩可以是文件的大小减小很多,节省空间:另外压缩后的文件在传输时更节省带宽. 所需软件: 1)lzo 2)hadoop-lzo 3)maven 安装编译: 1)lzo wget htt ...
- [Compression] Hadoop 压缩
0. 说明 Hadoop 压缩介绍 && 压缩格式总结 && 压缩编解码器测试 1. 介绍 [文件压缩的好处] 文件压缩的好处如下: 减少存储文件所需要的磁盘空间 加速 ...
- Hadoop压缩的图文教程
近期由于Hadoop集群机器硬盘资源紧张,有需求让把 Hadoop 集群上的历史数据进行下压缩,开始从网上查找的都是关于各种压缩机制的对比,很少有关于怎么压缩的教程(我没找到..),再此特记录下本次压 ...
- Hadoop压缩
为什幺要压缩? 压缩会提高计算速度?这是因为mapreduce计算会将数据文件分散拷贝到所有datanode上,压缩可以减少数据浪费在带宽上的时间,当这些时间大于压缩/解压缩本身的时间时,计算速度就会 ...
- 解读:hadoop压缩格式
Hadoop中用得比较多的4种压缩格式:lzo,gzip,snappy,bzip2.它们的优缺点和应用场景如下: 1). gzip压缩 优点:压缩率比较高,而且压缩/解压速度也比较快:hadoop本身 ...
- Hadoop压缩之MapReduce中使用压缩
1.压缩和输入分片 Hadoop中文件是以块的形式存储在各个DataNode节点中,假如有一个文件A要做为输入数据,给MapReduce处理,系统要做的,首先从NameNode中找到文件A存储在哪些D ...
- hadoop压缩和解压
最近有一个hadoop集群上的备份需求.源文件有几百G,如果直接复制太占用磁盘空间.将文件从hadoop集群下载到本地,压缩之后再上传到hadoop则太耗时间.于是想到能否直接在HDFS文件系统上进行 ...
- 查看hadoop压缩方式
bin/hadoop checknative 来查看我们编译之后的hadoop支持的各种压缩,如果出现openssl为false,那么就在线安装一下依赖包 bin/hadoop checknativ ...
随机推荐
- EntityFramework 常见用法汇总
1.Code First 启用存储过程映射实体 1 protected override void OnModelCreating(DbModelBuilder modelBuilder) 2 { 3 ...
- java 字符串排序
http://bbs.csdn.net/topics/280032929 大可不需要那样复杂了!(一)如果要排序的为字符串,如:String sortStr = "ACDFE"; ...
- php介绍
PHP 简介 PHP 是服务器端脚本语言. 您应当具备的基础知识 在继续学习之前,您需要对以下知识有基本的了解: HTML CSS 如果您希望首先学习这些项目,请在我们的 首页 访问这些教程. PHP ...
- Docker垃圾回收机制
由Docker垃圾回收机制引发的一场血案 AlstonWilliams 关注 2017.04.01 19:00* 字数 1398 阅读 253评论 0喜欢 0 今天早晨,在我还没睡醒的时候,我们团队中 ...
- sysbench基准测试工具使用
1.源码编译安装 源码下载地址(目前有0.4/0.5/1.0三个分支版本):https://github.com/akopytov/sysbench 编译安装: unzip sysbench-1.0. ...
- win7 wifi
win7 wifi the settings saved on this computer for the network do not match the requirements of the n ...
- Oracle的Spool导出数据
出自:http://wallimn.iteye.com/blog/472182 实践 只能在一个终端上的一个窗口中进行操作 第一步:连接oracle数据库 sqlplus qkp/mm_eft ...
- httpd 系统错误 无法启动此程序,因为计算机中丢失VCRUNTIME140.dll
说来话长的搭了一个discuz论坛,服务器是apache,我本地的是直接从官网下的(值得吐槽的是官网居然拿不提供编译版本么要从第三方网站获取,不知道为何....),对应apache之前是搭bug管理系 ...
- Excel 数字处理
说明 最近在做一个比较小型的网站,需要批量导入注册用户.用户的信息写在一张excel表格里面. 所以就需要读取excel.所以就记录下遇到的问题,以及以后查看. 相关技术 使用的POI解析Excel需 ...
- C#中的goto
int i = 9;if (i % 2 == 0) goto Found;else goto NoFound; NoFound: Console.WriteLine(i.ToSt ...