kafka安装配置及操作(官方文档)http://kafka.apache.org/documentation/(有单节点多代理配置)
https://www.cnblogs.com/biehongli/p/7767710.html
w3school
https://www.w3cschool.cn/apache_kafka/apache_kafka_introduction.html

点击javadoc即可
官方文档附带的javadoc
http://kafka.apache.org/21/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html
kafka的前言知识:
1:Kafka是什么?
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。kafka是一个生产-消费模型。
Producer:生产者,只负责数据生产,生产者的代码可以集成到任务系统中。
数据的分发策略由producer决定,默认是defaultPartition Utils.abs(key.hashCode) % numPartitions
Broker:当前服务器上的Kafka进程,俗称拉皮条。只管数据存储,不管是谁生产,不管是谁消费。
在集群中每个broker都有一个唯一brokerid,不得重复。
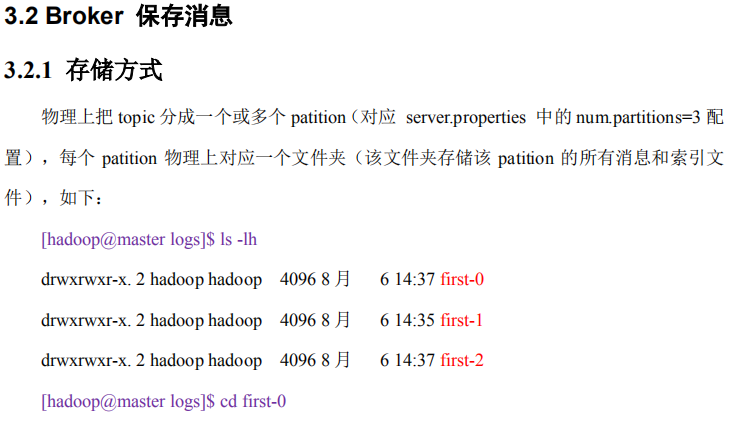
Topic:目标发送的目的地,这是一个逻辑上的概念,落到磁盘上是一个partition的目录。partition的目录中有多个segment组合(index,log)
一个Topic对应多个partition[0,1,2,3],一个partition对应多个segment组合。一个segment有默认的大小是1G。
每个partition可以设置多个副本(replication-factor 1),会从所有的副本中选取一个leader出来。所有读写操作都是通过leader来进行的。
特别强调,和mysql中主从有区别,mysql做主从是为了读写分离,在kafka中读写操作都是leader。
ConsumerGroup:数据消费者组,ConsumerGroup可以有多个,每个ConsumerGroup消费的数据都是一样的。
可以把多个consumer线程划分为一个组,组里面所有成员共同消费一个topic的数据,组员之间不能重复消费。
2:Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
3:Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
4:Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
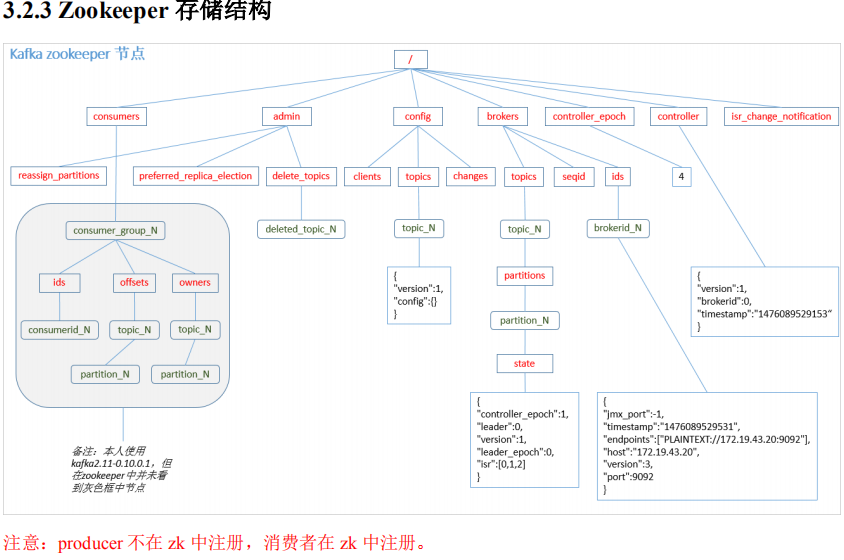
5:无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
6:Kafka核心组件:Topic :消息根据Topic进行归类;Producer:发送消息者;Consumer:消息接受者;broker:每个kafka实例(server);Zookeeper:依赖集群保存meta信息。
7:消息系统的核心作用就是三点:解耦,异步和并。
8:kafka生产数据时的分组策略?
默认是defaultPartition Utils.abs(key.hashCode) % numPartitions。
上文中的key是producer在发送数据时传入的,produer.send(KeyedMessage(topic,myPartitionKey,messageContent))。
9:kafka如何保证数据的完全生产?
ack机制:broker表示发来的数据已确认接收无误,表示数据已经保存到磁盘。
0:不等待broker返回确认消息。
1:等待topic中某个partition leader保存成功的状态反馈。
-1:等待topic中某个partition 所有副本都保存成功的状态反馈。
10:broker如何保存数据?
在理论环境下,broker按照顺序读写的机制,可以每秒保存600M的数据。主要通过pagecache机制,尽可能的利用当前物理机器上的空闲内存来做缓存。
当前topic所属的broker,必定有一个该topic的partition,partition是一个磁盘目录。partition的目录中有多个segment组合(index,log)。
11:如何保证kafka消费者消费数据是全局有序的?
伪命题,
如果要全局有序的,必须保证生产有序,存储有序,消费有序。由于生产可以做集群,存储可以分片,消费可以设置为一个consumerGroup,要保证全局有序,就需要保证每个环节都有序。只有一个可能,就是一个生产者,一个partition,一个消费者。这种场景和大数据应用场景相悖
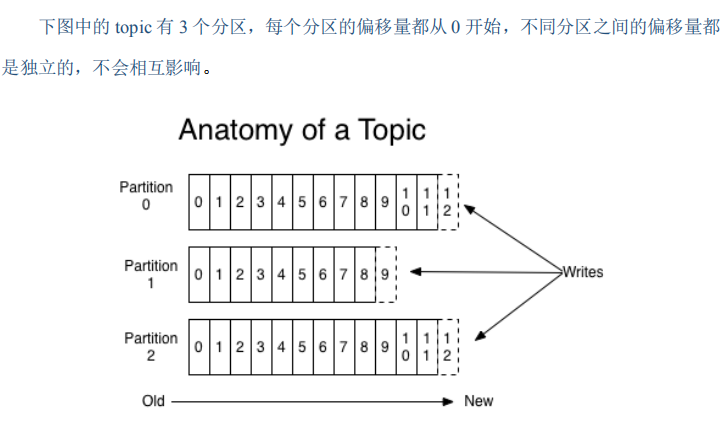
12:Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
13:Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
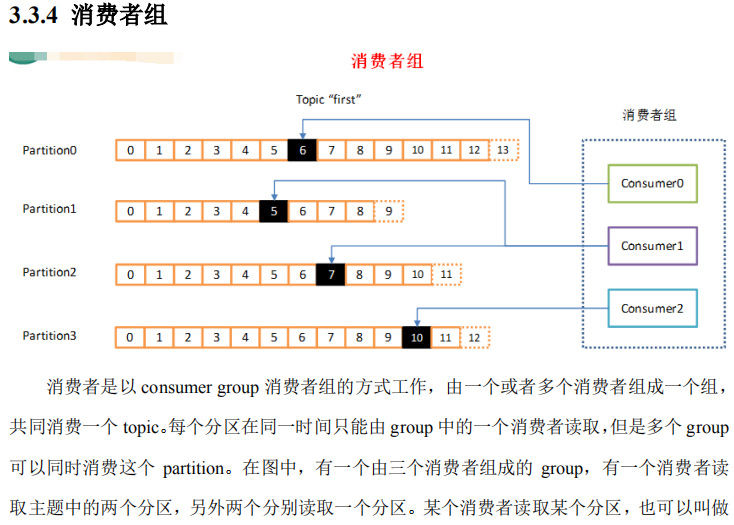
2:Consumer与topic关系?本质上kafka只支持Topic。
2.1:每个group中可以有多个consumer,每个consumer属于一个consumer group;
通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管。
2.2:对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer;
那么一个group中所有的consumer将会交错的消费整个Topic,每个group中consumer消息消费互相独立,我们可以认为一个group是一个"订阅"者。
2.3:在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);
一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。
2.4:kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
2.5:kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的。 3:Kafka消息的分发,Producer客户端负责消息的分发。
3.1:kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"/"partitions leader列表"等信息;
3.2:当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;
3.3:消息由producer直接通过socket发送到broker,中间不会经过任何"路由层",事实上,消息被路由到哪个partition上由producer客户端决定;
比如可以采用"random""key-hash""轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的。
3.4:在producer端的配置文件中,开发者可以指定partition路由的方式。
3.5:Producer消息发送的应答机制:
设置发送数据是否需要服务端的反馈,三个值0,1,-1。
0: producer不会等待broker发送ack。
1: 当leader接收到消息之后发送ack。
-1: 当所有的follower都同步消息成功后发送ack。
request.required.acks=0。 4:Consumer的负载均衡:
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力:
1:KafKa的官方网址:http://kafka.apache.org/
http://kafka.apache.org/downloads.ht
kafka_2.11-0.11.0.0.tgz

2.1.3 虚拟机准备
1)准备 3 台虚拟机
2)配置 ip 地址
3)配置主机名称
4)3 台主机分别关闭防火墙
[root@master hadoop]# chkconfig iptables off
或
ufw disable
2.1.4 安装 jdk
略
2.1.5 安装 Zookeeper
0)集群规划
在 master、node1 和 node2 三个节点上部署 Zookeeper。
1)解压安装
略
2.2 Kafka 集群部署
1)解压安装包
[hadoop@master software]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C ~/hadoop_home
2)修改解压后的文件名称
[hadoop@master module]$ mv kafka_2.11-0.11.0.0 kafka
3)在~/hadoop_home 目录下创建 logs 文件夹
[hadoop@master kafka]$ mkdir logs
4)修改配置文件
[hadoop@master kafka]$ cd config/
[hadoop@master config]$ vi server.properties
输入以下内容:
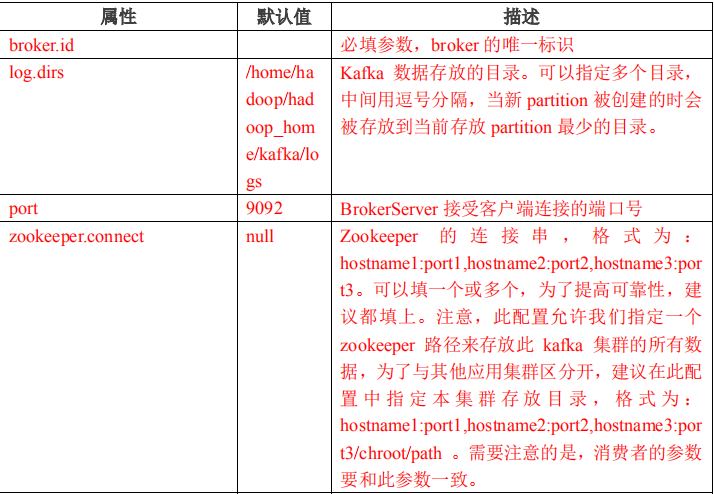
#broker 的全局唯一编号,不能重复
broker.id=0
#是否允许删除 topic
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的最大缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志存放的路径
log.dirs=~/hadoop_home/kafka/logs
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 集群地址
zookeeper.connect=master:2181,node1:2181,node2:2181
5)配置环境变量
[root@master module]# vi /etc/profile
#KAFKA_HOME
export KAFKA_HOME=~/hadoop_home/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@master module]# source ~/.profile
6 ) 分 别 在 node1 和 node2 上 修 改 配 置 文 件
/home/hadoop/hadoop_home/kafka/config/server.properties 中的 broker.id=1、broker.id=2
注:broker.id 不得重复
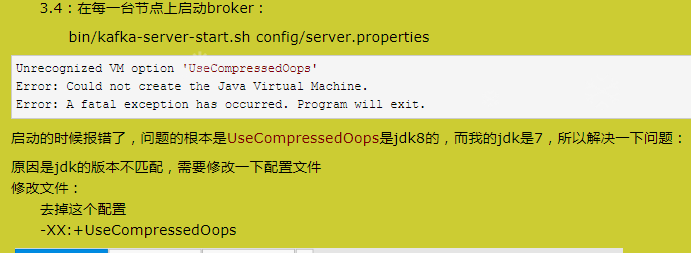
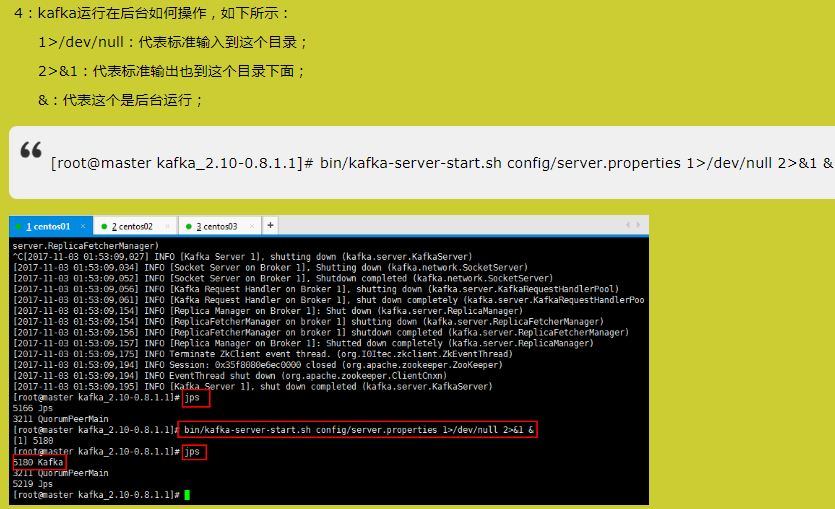
7)启动集群
依次在 master、node1、node2 节点上启动 kafka
注:前提启动 zookeeper
[hadoop@master kafka]$ kafka-server-start.sh config/server.properties &
[hadoop@node1 kafka]$ kafka-server-start.sh config/server.properties &
[hadoop@node2 kafka]$ kafka-server-start.sh config/server.properties &
9)关闭集群
[hadoop@master kafka]$ kafka-server-stop.sh stop
[hadoop@node1 kafka]$ kafka-server-stop.sh stop
[hadoop@node2 kafka]$ kafka-server-stop.sh stop
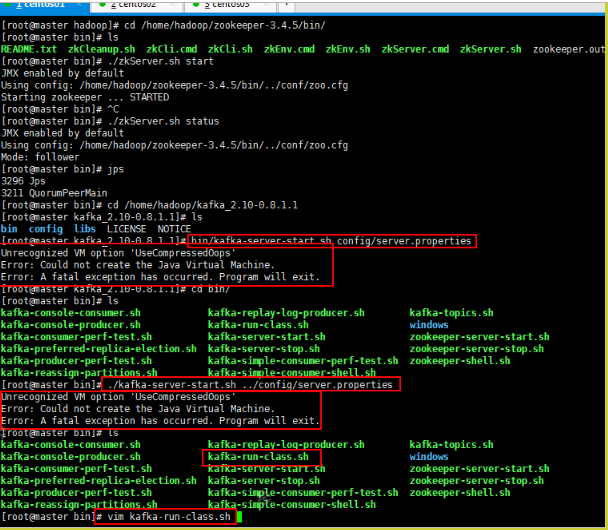
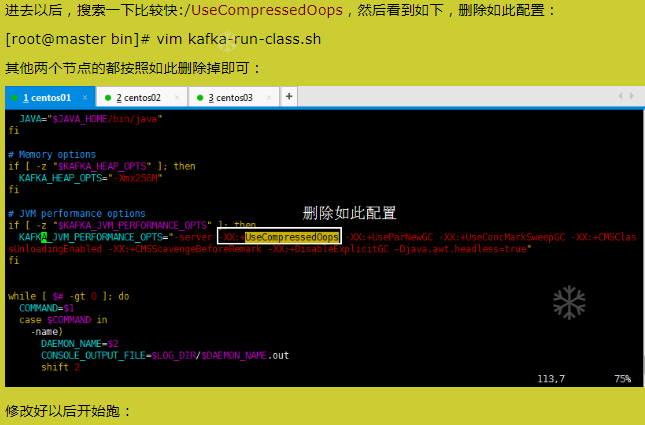
2.3 Kafka 命令行操作
1)查看当前服务器中的所有 topic
[hadoop@master kafka]$ kafka-topics.sh --zookeeper master:2181 --list
2)创建 topic
[hadoop@master kafka]$ kafka-topics.sh --zookeeper master:2181 --create
--replication-factor 3 --partitions 3 --topic first
选项说明:
--topic 定义 topic 名
--replication-factor 定义副本数
--partitions 定义分区数
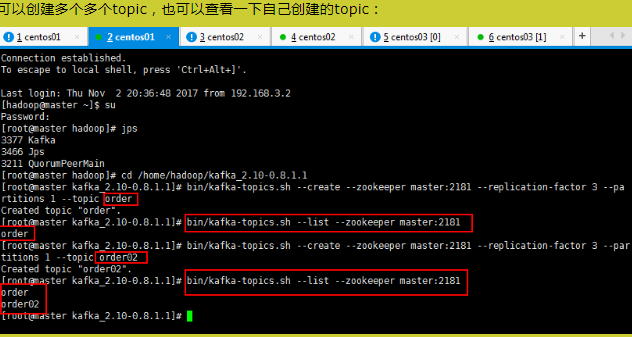
3)删除 topic
[hadoop@master kafka]$ kafka-topics.sh --zookeeper master:2181 --delete --topic first
需要 server.properties 中设置 delete.topic.enable=true 否则只是标记删除或者直接重启。

4)发送消息
[hadoop@master kafka]$ kafka-console-producer.sh --broker-list
master:9092,node1:9092,node2:9092 --topic first
>hello world
>yjsj hadoop
5)消费消息
[hadoop@node1 kafka]$ kafka-console-consumer.sh --zookeeper master:2181
--from-beginning --topic first
--from-beginning:会把 first 主题中以往所有的数据都读取出来。根据业务场景选择是
否增加该配置。
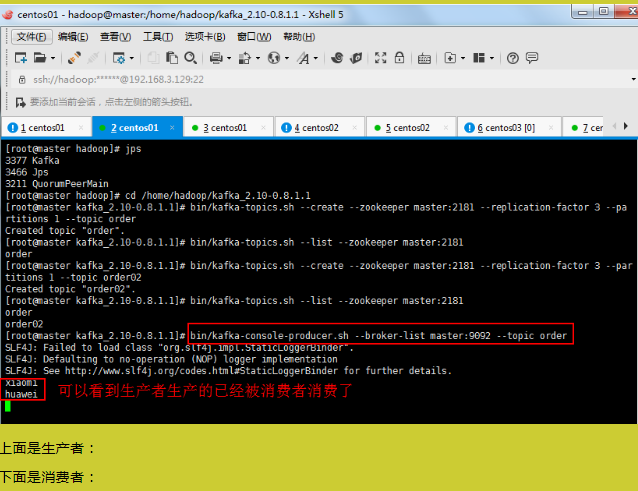
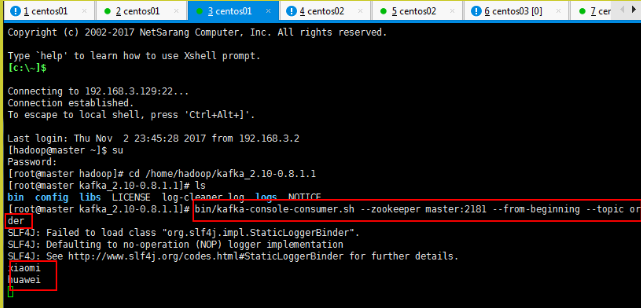
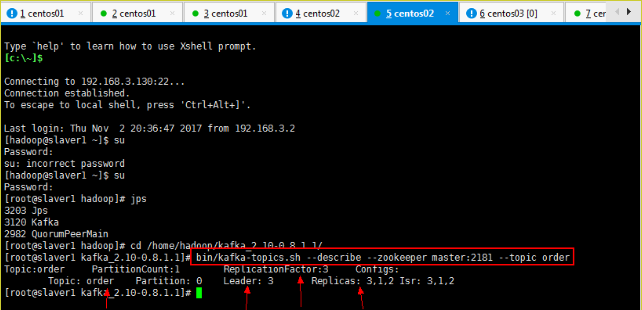
6)查看某个 Topic 的详情
[hadoop@master kafka]$ kafka-topics.sh --zookeeper master:2181 --describe --topic first
2.4 Kafka 配置信息
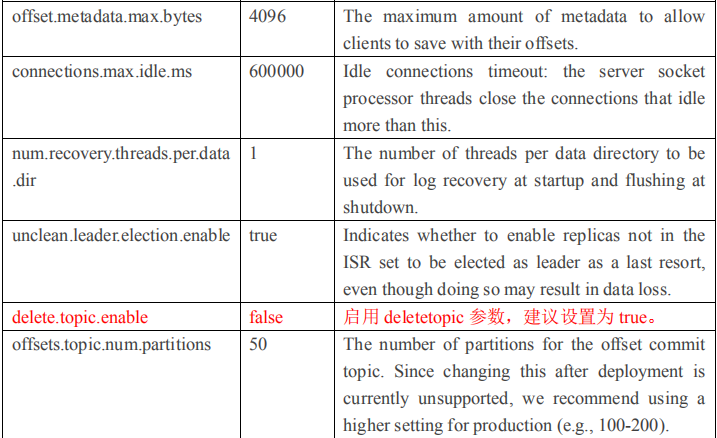
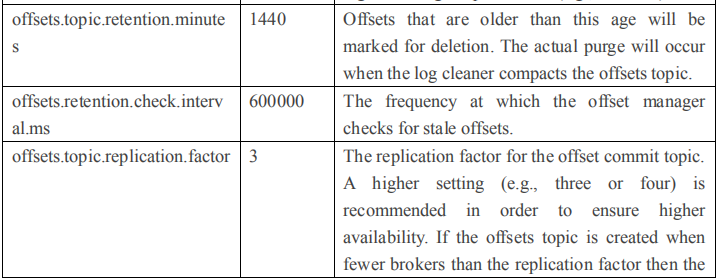
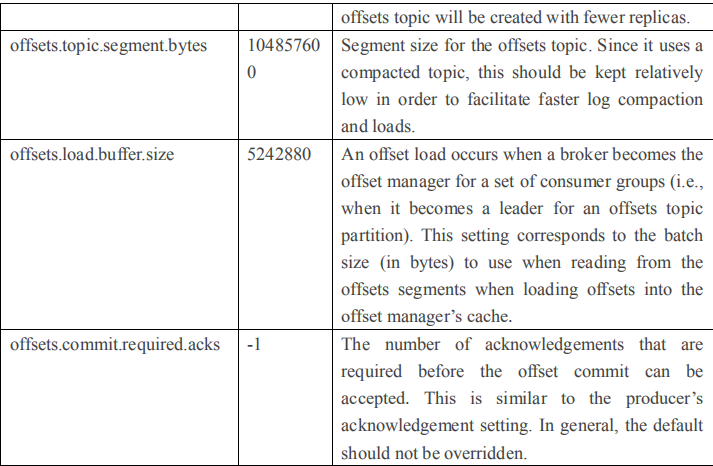
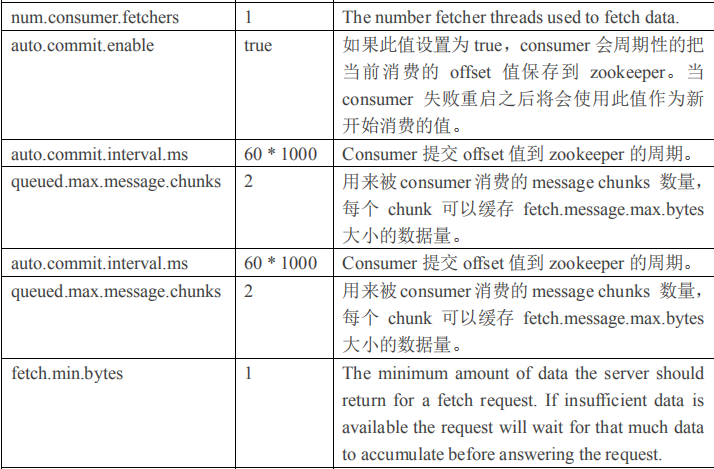
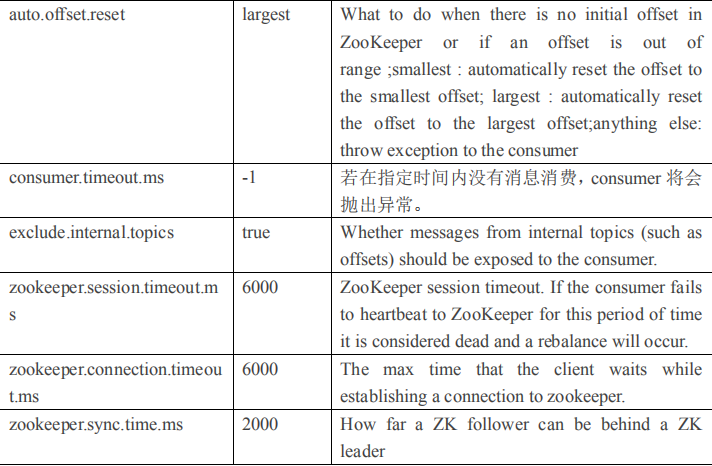
2.4.1 Broker 配置信息
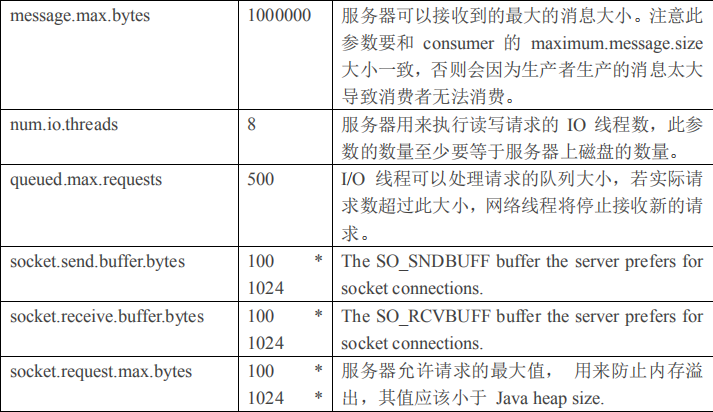

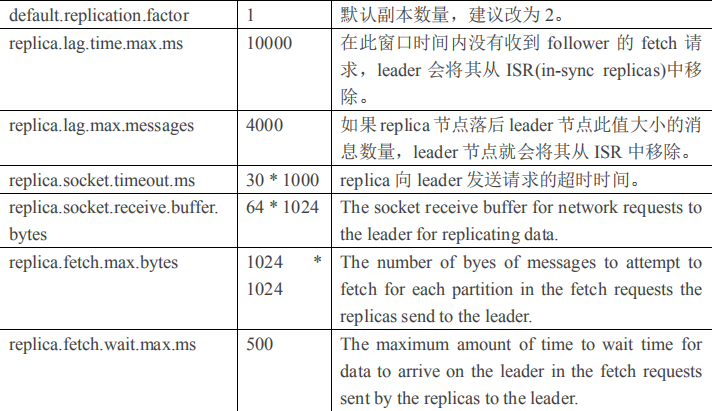
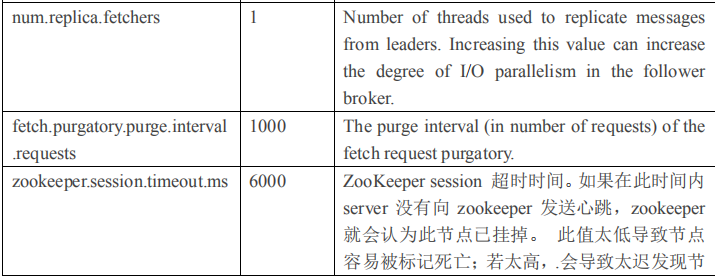
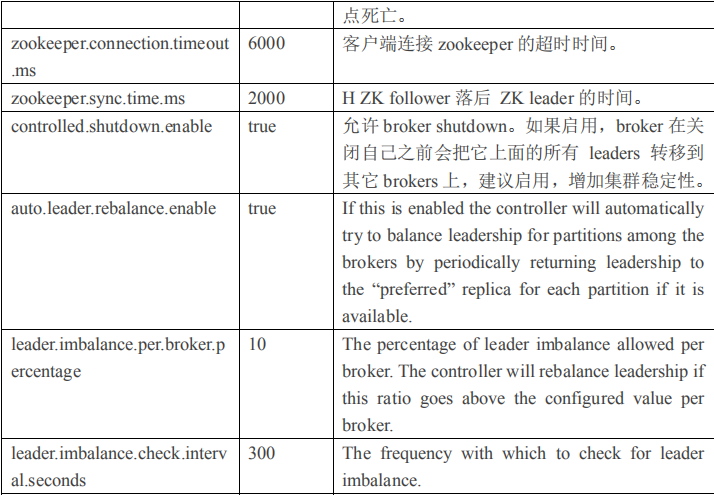
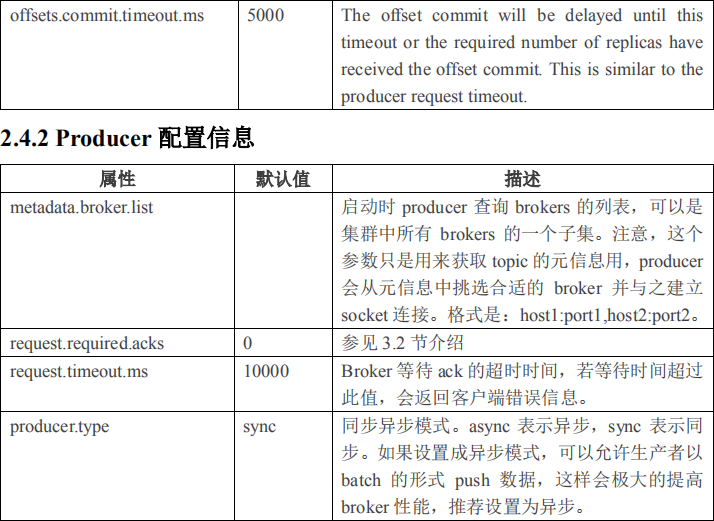
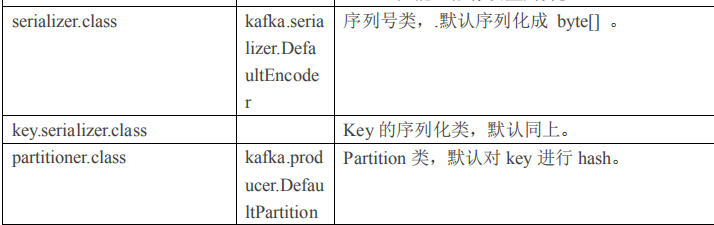

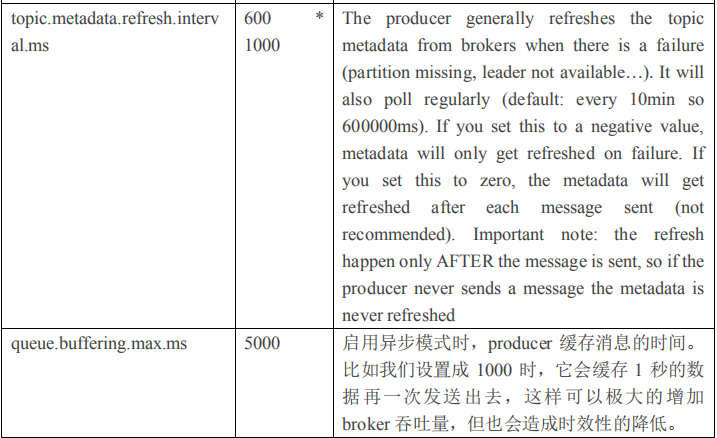
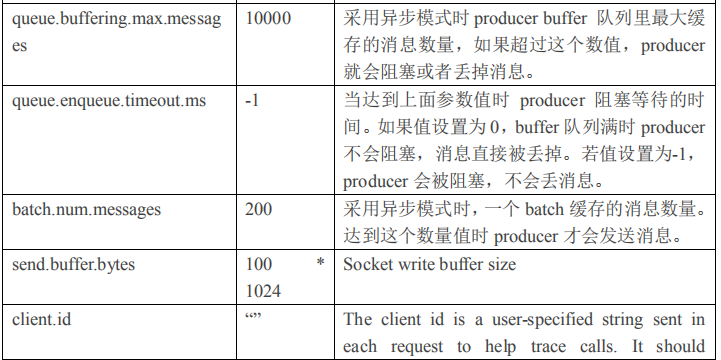
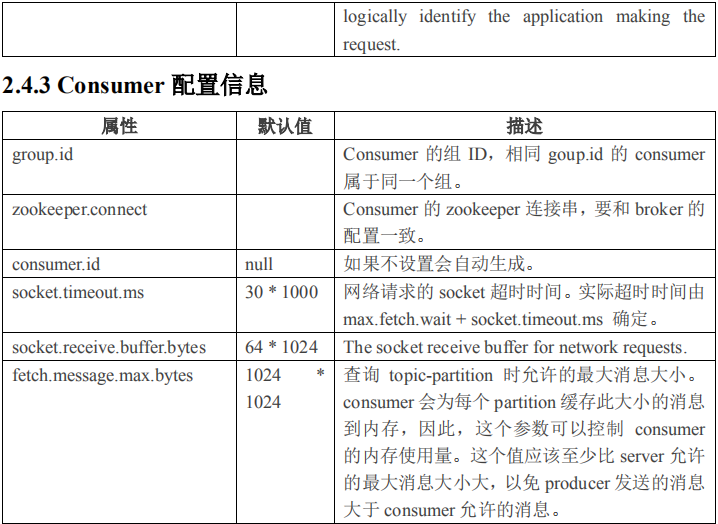

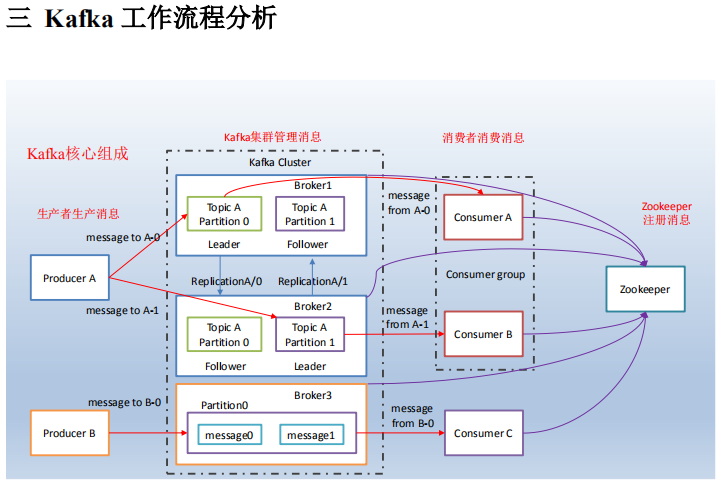








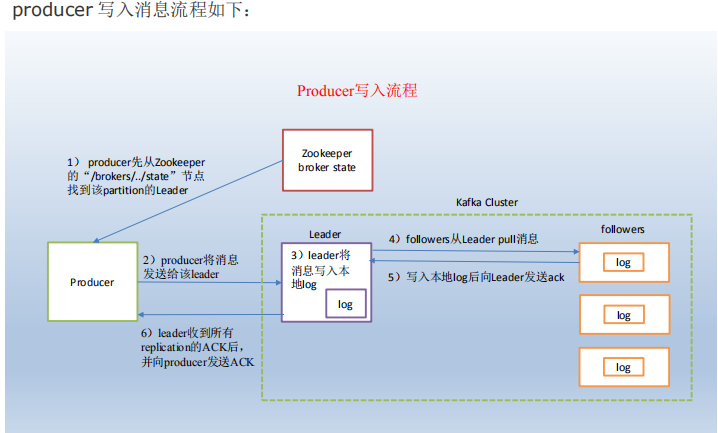
1)producer 先从 zookeeper 的 "/brokers/.../state"节点找到该 partition 的 leader
2)producer 将消息发送给该 leader
3)leader 将消息写入本地 log
4)followers 从 leader pull 消息,写入本地 log 后向 leader 发送 ACK
5)leader 收到所有 ISR 中的 replication 的 ACK 后,增加 HW(high watermark,最后 commit
的 offset)并向 producer 发送 ACK









kafka安装配置及操作(官方文档)http://kafka.apache.org/documentation/(有单节点多代理配置)的更多相关文章
- 【Phabricator】教科书一般的Phabricator安装教程(配合官方文档并带有踩坑解决方案)
随着一声惊雷和滂沱的大雨,我的Phabricator页面终于在我的学生机上跑了起来. 想起在这五个小时内踩过的坑甚如大学隔壁炮王干过的妹子,心里的成就感不禁油然而生. 接下来,我将和大家分享一下本人在 ...
- Spring Cloud官方文档中文版-Spring Cloud Config(上)-服务端(配置中心)
官方文档地址为:http://cloud.spring.io/spring-cloud-static/Dalston.SR2/#spring-cloud-feign 文中例子我做了一些测试在:http ...
- centos7安装oracle11g(根据oracle官方文档安装,解决图形界面安装问题)
一.系统及安装包 操作系统:centos 7.4 oracle版本:oracle 11g r2 二.centos环境配置 安装数据库所需要的软件包 [root@localhost data]# yum ...
- Spring 4 官方文档学习(十一)Web MVC 框架之约定优于配置
当返回一个ModelAndView时,可以使用其addObject(Object obj)方法,此时的约定是: An x.y.User instance added will have the nam ...
- SpringBoot系列: 所有配置属性和官方文档
Spring Boot 通用配置参数https://docs.spring.io/spring-boot/docs/current/reference/html/common-application- ...
- linux下安装mysql5.6(官方文档)
Using the MySQL Yum Repository / Installing MySQL on Linux Using the MySQL Yum Repository Chapter ...
- MyBatis3-topic-01 -安装/下载/官方文档 -执行输入一条已经映射的sql语句
mybatis XML 映射配置文件 (官方文档) -对象工厂(objectFactory) -配置环境(environments) -映射器(mappers) 本地IDEA搭建/测试步骤 创建数据库 ...
- 《Apache Velocity用户指南》官方文档
http://ifeve.com/apache-velocity-dev/ <Apache Velocity用户指南>官方文档 原文链接 译文连接 译者:小村长 校对:方腾飞 Qui ...
- HBase 官方文档
HBase 官方文档 Copyright © 2010 Apache Software Foundation, 盛大游戏-数据仓库团队-颜开(译) Revision History Revision ...
随机推荐
- Integer-->String String-->Integer
参考:http://blog.csdn.net/wangjolly/article/details/18354457 crane: String str="123";int a=0 ...
- Hashtable、HashMap
JDK1.6 API public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>, ...
- Linux 调优方案--ulimit命令
可以用ulimit -a 来显示当前的各种用户进程限制.下面把某linux用户的最大进程数设为10000个: ulimit -u 10240 对于需要做许多 socket 连接并使它们 ...
- GeoServer之SqlView
GeoServer之SqlView GeoServer中的新建图层中有一个配置新的SQL视图选项,即SqlView功能的入口. SqlView可以利用sql语句在geoserver中直接查询表中的几个 ...
- Linux下network提示Determining if ip address
转自:https://blog.csdn.net/ranran0224/article/details/73323925 Centos系统重启网络服务network 会提示Determining if ...
- nginx基本配置与参数说明-【转】
#运行用户 user nobody; #启动进程,通常设置成和cpu的数量相等 worker_processes 1; #全局错误日志及PID文件 #error_log logs/error.log; ...
- 如何设置tomcat,直接通过IP 访问
找到tomcat的主目录,进入conf文件夹,找到server.xml文件,并打开: 修改tomcat的监听端口为80端口: 在server.xml文件中找到: <Connector por ...
- jqgrid 自动换行
<style>.ui-jqgrid tr.jqgrow td { white-space: normal !important; height: auto; vertical-align: ...
- DDA算法
[DDA算法] Digital Differential Analyzer,DDA算法是一种线段扫描转换算法.(线段光栅化算法) DDA算法优缺点: 1.消除了直线方程中的乘法计算,而在x.y方向使用 ...
- solr的简单部署:在tomcat中启动slor
1,首先要下载solr 途径1: 官网网址: http://lucene.apache.org/ 与Lucene的官网是一个 途径2: 下载历史版本的网址: http://archive.apache ...