7.Python3标准库--文件系统
''' Python的标准库中包含大量工具,可以处理文件系统中的文件,构造和解析文件名,还可以检查文件内容。 处理文件的第一步是要确定处理的文件的名字。Python将文件名表示为简单的字符串,另外还提供了一些工具,可以由os.path中平台独立的标准组成部分构造文件名 pathlib模块提供了一个面向对象API来处理文件系统路径。使用这个模块而不是os.path可以提供更大的便利,因为它会在更高抽象层中完成处理 用os中的listdir函数可以列出一个文件目录中的内容,或者使用glob模块建立一个文件名列表 glob使用的文件名模式匹配还可以通过fnmatch直接提供,从而可以在其他上下文中使用 明确文件名之后,可以用os.stat和stat中的常量来检查其他特性,如权限或者文件大小 应用需要随机访问文件时,利用linecache可以很容易地按行号进行读取。不过文件的内容在缓存中维护,因此要当心内存消耗 有些情况下,需要创建草稿文件来临时保存数据,或者将一个数据移动到永久位置之前需要用临时文件存储,此时tempfile就很有用。 它提供了一些类,可以安全而稳妥地创建临时文件和目录。可以保证文件名和目录名是唯一的,其中包含随机的组成部分,因此不容易出错。 程序经常需要把文件作为一个整体来处理,而不考虑其内容。shutil模块包含了一些高级文件操作,如复制文件和目录,以及创建或者解压缩文件归档。 filecmp模块通过查看文件和目录包含的字节来完成文件和目录的比较,不过不需要有关其格式的任何特殊知识。 内置的file类可以用于读写本地文件系统上可见的文件。不过通过read和write函数接口访问大文件的时候,程序的性能可能会受到影响。 因为文件从磁盘移动到应用可见的内存时,这两个操作都会涉及多次数据复制。 使用mmap可以告诉操作系统使用其虚拟内存子系统,将文件的内容直接映射到程序可以访问的内存,从而避免操作系统与file对象内部缓冲区之间的复制步骤 如果文本数据中使用了非ASCII字符,那么通常会采用一种Unicode数据格式保存。 由于标准file句柄假设文本文件的各个字节分别表示一个字符,所以读取使用多字节编码的Unicode文本,需要额外的处理。 codecs模块会自动处理编码和解码,所以在很多情况下,完全可以使用一个非ASCII文件而无须对程序做任何其他修改 io模块提供的类用来实现Python基于文件的输入和输出。 如果测试代码依赖于从文件中读写数据,那么对于这些测试代码,io提供了一个基于内存的流对象,它就像一个文件,只不过不驻留在磁盘上。 '''
(一)os.path:平台独立的文件名管理
''' 利用os.path模块中包含的函数,很容易编写代码来处理多个平台上的文件 '''
1.解析路径
import os.path
'''
os.path中的第一组函数可以用来将表示文件名的字符串解析为文件名的各个组成部分。
这些函数并不要求路径真正存在:它们只是处理字符串。
'''
# os.sep:路径各部分之间的分隔符,例如/或者\
print(os.sep) # \
# os.extsep:文件与文件扩展名之间的分隔符
print(os.extsep) # .
# os.pardir:路径中表示目录树上一级的部分
print(os.pardir) # ..
# os.curdir:路径中表示当前目录的部分
print(os.curdir) # .
# split函数:将路径分解为两个部分,返回包含结果的元组
print(os.path.split(r"C:\python37")) # ('C:\\', 'python37')
print(os.path.split(r"C:\python37\python.exe")) # ('C:\\python37', 'python.exe')
# split函数的两部分,分别等价于dirname和basename
print(os.path.dirname(r"C:\python37"), "--", os.path.basename(r"C:\python37")) # C:\ -- python37
print(os.path.dirname(r"C:\python37\python.exe"), "--", os.path.basename(r"C:\python37\python.exe")) # C:\python37 -- python.exe
'''
可以看到是以最后一个目录分隔符为基准的,C:\\aaa\\bbb\\ccc\\ddd, --> C:\\aaa\\bbb\\ccc ddd
'''
# 还有一个splitext函数,和split类似,但是是以扩展名分隔符为基准的
# 既然是以扩展名为基准,那么必须是文件才会有意义。
print(os.path.splitext(r"C:\python37")) # ('C:\\python37', '')
# 可以看到这里是个目录,因此得到('C:\\python37', '')。
# 但是之前也说过,这些函数不要求文件真的存在,而是把当成字符串像文件名一样处理
# 表示C盘下有一个python3.7文件,.7表示扩展名
print(os.path.splitext(r"C:\python3.7")) # ('C:\\python3', '.7')
print(os.path.splitext(r"C:\python37\python.exe")) # ('C:\\python37\\python', '.exe')
# 如果有多个扩展名分隔符,比如linux下的gz包,那么一最后一个扩展名分隔符为基准
print(os.path.splitext(r"C:\python37\hadoop.tar.gz")) # ('C:\\python37\\hadoop.tar', '.gz')
# 还记得os.path.split吗?是以目录分隔符为基准的,用它来分解会有什么效果呢
print(os.path.split(r"C:\python37\hadoop.tar.gz")) # ('C:\\python37', 'hadoop.tar.gz')
# commonprefix去一个路径列表作为参数,并且返回一个字符串,表示所有路径都出现的公共前缀
path = [r"C:\Go", r"C:\MinGW", r"C:\python37"]
print(os.path.commonprefix(path)) # C:\
print(os.path.commonprefix(path+[r"F:\\mmp"])) # 这里返回了一个空字符串
# 不过还有一个隐藏的问题
path = [r"C:\1\2\3", r"C:\1\2\4", r"C:\1\23\5"]
# 注意这里打印的是C:\1\2,所以这个函数没有考虑路径分隔符,是真的当成是字符串来处理,r"C:\1\23\5",把23没有作为整体处理
print(os.path.commonprefix(path)) # C:\1\2
# 那如何避免这种情况呢?可以使用commonpath,专门是解决这种情况的
print(os.path.commonpath(path)) # C:\1
2.建立路径
import os.path
'''
除了分解现有的路径,还经常需要从其他字符串建立路径。要将多个路径组成部分结合为一个值,可以使用join
'''
print(os.path.join("a", "b", "c")) # a\b\c
# ~表示家目录,expanduser可以自动识别
print(os.path.expanduser("~")) # C:\Users\EDZ
print(os.path.join(os.path.expanduser("~"), "666", "1.text")) # C:\Users\EDZ\666\1.text
# expandvars更为通用,因为它会扩展路径中出现的所有变量
import os
os.environ["Sherry"] = "啊,雪莉"
print(os.path.expandvars(r"C:\python\$Sherry")) # C:\python\啊,雪莉
3.规范化路径
import os.path ''' 使用join或利用嵌入变量由单独的字符串组合路径时,得到的路径最后可能会有多余的分隔符或相对路径部分。使用normalpath可以清除这些内容 ''' print(os.path.normpath(r"one\..\two\.\three")) # two\three # 把相对路径转换为绝对路径,可以使用abspath path = r"C:\python37\Lib\asyncio\..\.." print(os.path.abspath(path)) # C:\python37
4.文件时间
import os.path
import time
'''
除了处理文件路径,os.path还包括一些用于获取文件属性的函数,类似于os.stat函数返回的结果
'''
# os.path.getatime返回文件的访问时间,a:access
print(time.strftime("%Y-%m-%d %X", time.localtime(os.path.getatime(__file__)))) # 2019-03-20 11:46:58
# os.path.getmtime返回文件的修改时间,m:modify
print(time.strftime("%Y-%m-%d %X", time.localtime(os.path.getmtime(__file__)))) # 2019-03-20 11:46:58
# os.path.getctime返回文件的创建时间,c:create
print(time.strftime("%Y-%m-%d %X", time.localtime(os.path.getctime(__file__)))) # 2019-03-19 17:17:52
# 返回的是一个时间戳,需要使用time.localtime转换为时间元祖,然后再用strftime转成字符串的格式
5.测试文件
import os.path ''' 程序在遇到一个路径时,需要知道这个路径到底一个文件、目录还是一个符号链接,以及这个路径到底存在与否。 os.path包含了一些用于测试这些条件的函数 ''' file = r"C:\python37\Lib\asyncio\base_events.py" dir = r"C:\python37\Lib\asyncio" # 是否是绝对路径 print(os.path.isabs(file)) # True # 判断是否是一个文件 print(os.path.isfile(file)) # True print(os.path.isfile(dir)) # False # 判断是否是一个目录 print(os.path.isdir(file)) # False print(os.path.isdir(dir)) # True # 判断是否是一个链接 print(os.path.islink(file)) # False # 判断是否是一个挂载 print(os.path.ismount(file)) # False # 判断是否存在 print(os.path.exists(file)) # True
(二)pathlib:文件系统路径作为对象
''' pathlib模块提供了一个面向对象的API来解析、建立、测试、和处理文件名和路径,而不是使用底层字符串操作 '''
1.路径表示
''' pathlib包含一些类来管理使用POSIX标准或Windows语法格式化的文件系统路径。 这个模块包含一些纯类,会处理字符串但是不会与实际的文件系统交互,另外还包含了一些具体类,它们扩展了API,以包含可以反映或修改本地文件系统上数据的操作。 纯类,PurePosixPath和PureWindowsPath可以在任意操作系统上实例化和使用,因为它们只处理文件名或者目录名。 要实例化一个具体的类来处理真正的文件系统,需要使用Path得到一个具体的PosixPath或WindowsPath,这取决于具体的平台 '''
2.建立路径
import pathlib
'''
要实例化一个新路径,可以提供一个字符串作为第一个参数。
'''
posix = pathlib.PurePosixPath("/usr")
windows = pathlib.PureWindowsPath("/usr")
print(posix, type(posix)) # /usr <class 'pathlib.PurePosixPath'>
print(windows, type(windows)) # \usr <class 'pathlib.PureWindowsPath'>
print(posix / 'local') # /usr/local
print(windows / 'local') # \usr\local
# joinpath可以将多个path进行组合,返回一个新的对象
print(posix.joinpath("local", "spark")) # /usr/local/spark
print(windows.joinpath("local", "spark")) # \usr\local\spark
# with_name和with_suffix可以将对文件名或者扩展名进行替换
ind = pathlib.PureWindowsPath(r"C:\python37\lib\asyncio\__init__.py")
print(ind) # C:\python37\lib\asyncio\__init__.py
print(ind.with_name("啊啊啊.py")) # C:\python37\lib\asyncio\啊啊啊.py
print(ind.with_suffix(".pyd")) # C:\python37\lib\asyncio\__init__.pyd
3.解析路径
import pathlib
'''
以前我们获取路径可以通过os.path.dirname,但是使用pathlib更简单
关于Path这个类,不光这个类,PureWindowsPath,PurePosixPath都是继承自PurePath,我们直接使用Path就可以了,会自动帮我们检测平台
'''
path = pathlib.Path(r"C:\python37\Lib\asyncio\base_events.py")
print(path.parts) # ('C:\\', 'python37', 'Lib', 'asyncio', 'base_events.py')
for up in path.parents:
print(up)
r'''
C:\python37\Lib\asyncio
C:\python37\Lib
C:\python37
C:\
'''
# 文件名
print(path.name) # base_events.py
# 后缀名
print(path.suffix) # .py
# 文件名除了后缀的部分
print(path.stem) # base_events
4.创建具体路径
import pathlib ''' 可以由字符串参数创建具体Path类的实例,字符串参数可能指示文件系统中一个文件、目录或符号链接的名字。 这个类还提供了很多的便利方法,可以使用常用位置(当前工作目录或者用户的主目录)建立路径实例,这些常用位置可能会改变 ''' print(pathlib.Path.home()) # C:\Users\EDZ print(pathlib.Path.cwd()) # C:\Users\EDZ\Desktop\satori\data_processing\python3标准库\6.文件系统 # 也可以传入一个路径得到Path实例 p = pathlib.Path(r"C:\python37\Lib\asyncio\base_events.py") print(p) # C:\python37\Lib\asyncio\base_events.py # parent获取上一级 print(p.parent) # C:\python37\Lib\asyncio print(p.parent.parent) # C:\python37\Lib
5.目录内容
import pathlib
'''
可以使用3个方法来访问目录列表以及发现文件系统中的文件名
'''
p = pathlib.Path(r"C:\python37\Lib\site-packages\scipy\_lib")
# iterdir方法可以获取包含所有文件名的生成器
print(p.iterdir()) # <generator object Path.iterdir at 0x00000000021E4138>
for f in p.iterdir():
print(f)
r'''
C:\python37\Lib\site-packages\scipy\_lib\decorator.py
C:\python37\Lib\site-packages\scipy\_lib\messagestream.cp37-win_amd64.pyd
C:\python37\Lib\site-packages\scipy\_lib\setup.py
C:\python37\Lib\site-packages\scipy\_lib\six.py
C:\python37\Lib\site-packages\scipy\_lib\tests
C:\python37\Lib\site-packages\scipy\_lib\_ccallback.py
C:\python37\Lib\site-packages\scipy\_lib\_ccallback_c.cp37-win_amd64.pyd
C:\python37\Lib\site-packages\scipy\_lib\_fpumode.cp37-win_amd64.pyd
C:\python37\Lib\site-packages\scipy\_lib\_gcutils.py
C:\python37\Lib\site-packages\scipy\_lib\_numpy_compat.py
C:\python37\Lib\site-packages\scipy\_lib\_testutils.py
C:\python37\Lib\site-packages\scipy\_lib\_test_ccallback.cp37-win_amd64.pyd
C:\python37\Lib\site-packages\scipy\_lib\_threadsafety.py
C:\python37\Lib\site-packages\scipy\_lib\_tmpdirs.py
C:\python37\Lib\site-packages\scipy\_lib\_util.py
C:\python37\Lib\site-packages\scipy\_lib\_version.py
C:\python37\Lib\site-packages\scipy\_lib\__init__.py
C:\python37\Lib\site-packages\scipy\_lib\__pycache__
'''
# glob可以传入参数,进行匹配
# *表示任意长度的任意字符,因此*.pyd表示扩展名为pyd的文件
for f in p.glob(r"*.pyd"):
print(f)
'''
C:\python37\Lib\site-packages\scipy\_lib\messagestream.cp37-win_amd64.pyd
C:\python37\Lib\site-packages\scipy\_lib\_ccallback_c.cp37-win_amd64.pyd
C:\python37\Lib\site-packages\scipy\_lib\_fpumode.cp37-win_amd64.pyd
C:\python37\Lib\site-packages\scipy\_lib\_test_ccallback.cp37-win_amd64.pyd
'''
# rglob表示递归搜索,对于glob,如果是文件夹,那么显然是不匹配的。因为一个我们找的是文件,目录从本质上就不匹配
# 但如果是rglob,那么会这个文件夹打开,继续查找
p = pathlib.Path(r"C:\python37\Lib\site-packages\pandas")
for f in p.glob("__init__.py"):
print(f)
r'''
C:\python37\Lib\site-packages\pandas\__init__.py
'''
for f in p.rglob("__init__.py"):
print(f)
r'''
C:\python37\Lib\site-packages\pandas\__init__.py
C:\python37\Lib\site-packages\pandas\api\__init__.py
C:\python37\Lib\site-packages\pandas\api\extensions\__init__.py
C:\python37\Lib\site-packages\pandas\api\types\__init__.py
C:\python37\Lib\site-packages\pandas\compat\__init__.py
C:\python37\Lib\site-packages\pandas\compat\numpy\__init__.py
C:\python37\Lib\site-packages\pandas\computation\__init__.py
C:\python37\Lib\site-packages\pandas\core\__init__.py
C:\python37\Lib\site-packages\pandas\core\arrays\__init__.py
C:\python37\Lib\site-packages\pandas\core\computation\__init__.py
C:\python37\Lib\site-packages\pandas\core\dtypes\__init__.py
C:\python37\Lib\site-packages\pandas\core\groupby\__init__.py
C:\python37\Lib\site-packages\pandas\core\indexes\__init__.py
C:\python37\Lib\site-packages\pandas\core\reshape\__init__.py
C:\python37\Lib\site-packages\pandas\core\sparse\__init__.py
C:\python37\Lib\site-packages\pandas\core\tools\__init__.py
C:\python37\Lib\site-packages\pandas\core\util\__init__.py
C:\python37\Lib\site-packages\pandas\errors\__init__.py
C:\python37\Lib\site-packages\pandas\formats\__init__.py
C:\python37\Lib\site-packages\pandas\io\__init__.py
C:\python37\Lib\site-packages\pandas\io\clipboard\__init__.py
C:\python37\Lib\site-packages\pandas\io\formats\__init__.py
C:\python37\Lib\site-packages\pandas\io\json\__init__.py
C:\python37\Lib\site-packages\pandas\io\msgpack\__init__.py
C:\python37\Lib\site-packages\pandas\io\sas\__init__.py
C:\python37\Lib\site-packages\pandas\plotting\__init__.py
C:\python37\Lib\site-packages\pandas\tests\__init__.py
C:\python37\Lib\site-packages\pandas\tests\api\__init__.py
C:\python37\Lib\site-packages\pandas\tests\categorical\__init__.py
C:\python37\Lib\site-packages\pandas\tests\computation\__init__.py
C:\python37\Lib\site-packages\pandas\tests\dtypes\__init__.py
C:\python37\Lib\site-packages\pandas\tests\extension\__init__.py
C:\python37\Lib\site-packages\pandas\tests\extension\base\__init__.py
C:\python37\Lib\site-packages\pandas\tests\extension\category\__init__.py
C:\python37\Lib\site-packages\pandas\tests\extension\decimal\__init__.py
C:\python37\Lib\site-packages\pandas\tests\extension\json\__init__.py
C:\python37\Lib\site-packages\pandas\tests\frame\__init__.py
C:\python37\Lib\site-packages\pandas\tests\generic\__init__.py
C:\python37\Lib\site-packages\pandas\tests\groupby\__init__.py
C:\python37\Lib\site-packages\pandas\tests\groupby\aggregate\__init__.py
C:\python37\Lib\site-packages\pandas\tests\indexes\__init__.py
C:\python37\Lib\site-packages\pandas\tests\indexes\datetimes\__init__.py
C:\python37\Lib\site-packages\pandas\tests\indexes\interval\__init__.py
C:\python37\Lib\site-packages\pandas\tests\indexes\period\__init__.py
C:\python37\Lib\site-packages\pandas\tests\indexes\timedeltas\__init__.py
C:\python37\Lib\site-packages\pandas\tests\indexing\__init__.py
C:\python37\Lib\site-packages\pandas\tests\indexing\interval\__init__.py
C:\python37\Lib\site-packages\pandas\tests\internals\__init__.py
C:\python37\Lib\site-packages\pandas\tests\io\__init__.py
C:\python37\Lib\site-packages\pandas\tests\io\formats\__init__.py
C:\python37\Lib\site-packages\pandas\tests\io\json\__init__.py
C:\python37\Lib\site-packages\pandas\tests\io\msgpack\__init__.py
C:\python37\Lib\site-packages\pandas\tests\io\parser\__init__.py
C:\python37\Lib\site-packages\pandas\tests\io\sas\__init__.py
C:\python37\Lib\site-packages\pandas\tests\plotting\__init__.py
C:\python37\Lib\site-packages\pandas\tests\reshape\__init__.py
C:\python37\Lib\site-packages\pandas\tests\reshape\merge\__init__.py
C:\python37\Lib\site-packages\pandas\tests\scalar\__init__.py
C:\python37\Lib\site-packages\pandas\tests\scalar\interval\__init__.py
C:\python37\Lib\site-packages\pandas\tests\scalar\period\__init__.py
C:\python37\Lib\site-packages\pandas\tests\scalar\timedelta\__init__.py
C:\python37\Lib\site-packages\pandas\tests\scalar\timestamp\__init__.py
C:\python37\Lib\site-packages\pandas\tests\series\__init__.py
C:\python37\Lib\site-packages\pandas\tests\series\indexing\__init__.py
C:\python37\Lib\site-packages\pandas\tests\sparse\__init__.py
C:\python37\Lib\site-packages\pandas\tests\sparse\frame\__init__.py
C:\python37\Lib\site-packages\pandas\tests\sparse\series\__init__.py
C:\python37\Lib\site-packages\pandas\tests\tools\__init__.py
C:\python37\Lib\site-packages\pandas\tests\tseries\__init__.py
C:\python37\Lib\site-packages\pandas\tests\tseries\offsets\__init__.py
C:\python37\Lib\site-packages\pandas\tests\tslibs\__init__.py
C:\python37\Lib\site-packages\pandas\tests\util\__init__.py
C:\python37\Lib\site-packages\pandas\tools\__init__.py
C:\python37\Lib\site-packages\pandas\tseries\__init__.py
C:\python37\Lib\site-packages\pandas\types\__init__.py
C:\python37\Lib\site-packages\pandas\util\__init__.py
C:\python37\Lib\site-packages\pandas\_libs\__init__.py
C:\python37\Lib\site-packages\pandas\_libs\tslibs\__init__.py
'''
6.读写文件
import pathlib
'''
每个Path实例都包含一些方法来处理所指示文件的内容。
要直接获取内容,可以使用read_bytes或read_text。写入文件可以使用write_bytes或者write_text
可以使用open方法打开文件并保留文件句柄,而不是像内置的open函数传入文件名
'''
# 文件名可以不存在
f = pathlib.Path("1.txt")
f.write_bytes(bytes("假如有一天我变得淫荡,请记住我曾经清纯的模样", encoding="utf-8"))
print(f.read_text(encoding="utf-8")) # 假如有一天我变得淫荡,请记住我曾经清纯的模样
7.文件类型
import pathlib
'''
Path实例包含一些方法来检查路径指示的文件的类型。
'''
p1 = pathlib.Path(r"C:\python37\Lib\site-packages\pandas\__init__.py")
p2 = pathlib.Path(r"C:\python37\Lib\site-packages\pandas")
# 首先我们获取的p1、p2都是Path类的实例,可以转化为字符串,变成了普通路径。
print(f"是否是文件: {p1.is_file()}, {p2.is_file()}") # 是否是文件: True, False
print(f"是否是目录: {p1.is_dir()}, {p2.is_dir()}") # 是否是目录: False, True
print(f"是否是符号链接: {p1.is_symlink()}, {p2.is_symlink()}") # 是否是符号链接: False, False
print(f"是否是FIFO文件: {p1.is_fifo()}, {p2.is_fifo()}") # 是否是FIFO文件: False, False
print(f"是否是块设备: {p1.is_block_device()}, {p2.is_block_device()}") # 是否是块设备: False, False
print(f"是否是字符设备: {p1.is_char_device()}, {p2.is_char_device()}") # 是否是字符设备: False, False
print(f"是否存在: {p1.exists()}, {p2.exists()}") # 是否存在: True, True
8.文件属性
import pathlib
'''
可以使用方法stat和lstat来访问文件的有关详细信息(lstat用于检查一个可能是符号链接的目标的状态)。
这些方法生成的结果分别与os.stat和os.lstat相同
'''
p = pathlib.Path(r"C:\python37\Lib\asyncio\base_events.py")
info = p.stat()
print(info.st_size) # 70496
print(oct(info.st_mode)) # 0o100666
print(info.st_dev) # 2350909250
print(info.st_uid) # 0
# 如果想更简单地访问文件所有者的信息,则可以使用owner和group,但是这两个函数不支持Windows
# touch可以创建一个文件
p = pathlib.Path("satori.txt")
# 类似于Linux下的touch,可以创建一个相应的文件
p.touch()
# 文件存在之后可以更新修改时间和权限
9.权限
import pathlib ''' 可以使用方法stat和lstat来访问文件的有关详细信息(lstat用于检查一个可能是符号链接的目标的状态)。 这些方法生成的结果分别与os.stat和os.lstat相同 ''' p = pathlib.Path(r"C:\python37\Lib\asyncio\base_events.py") print(oct(p.stat().st_mode)) # 0o100666 p.chmod(0o444) print(oct(p.stat().st_mode)) # 0o100444
10.删除
import pathlib ''' 可以通过rmdir删除一个空目录,如果不存在会报错,存在但是不为空也会报错 '''
(三)glob:文件名模式匹配
''' 尽管glob模块的API很小,但是这个模块的功能很强大。只要程序需要查找文件系统中名字与某个模式匹配的一组文件,就可以使用这个模块。 要创建一个文件名列表,要求其中各个文件名都有某个特定的扩展名、前缀或者中间都有某个共同的字符串,就可以使用glob模块,而不用编写定制代码来扫描目录内容。 glob的模式规则与re模块使用的正则表达式不同,实际上,glob的模式遵循标准Unix路径扩展规则。只是用几个特殊字符来实现两个不同的通配符和字符区间。 '''
1.示例数据
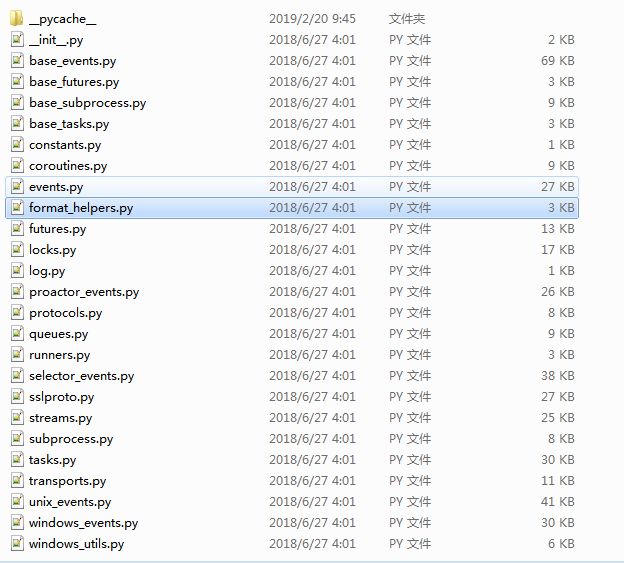
2.通配符
import glob import pprint print(glob.glob(r"C:\python37\Lib\asyncio")) # ['C:\\python37\\Lib\\asyncio'] # 查找以C:\python37\Lib\asyncio开头的目录或文件,*表示任意个任意字符 pprint.pprint(glob.glob(r"C:\python37\Lib\asyncio\*")) r''' ['C:\\python37\\Lib\\asyncio\\base_events.py', 'C:\\python37\\Lib\\asyncio\\base_futures.py', 'C:\\python37\\Lib\\asyncio\\base_subprocess.py', 'C:\\python37\\Lib\\asyncio\\base_tasks.py', 'C:\\python37\\Lib\\asyncio\\constants.py', 'C:\\python37\\Lib\\asyncio\\coroutines.py', 'C:\\python37\\Lib\\asyncio\\events.py', 'C:\\python37\\Lib\\asyncio\\format_helpers.py', 'C:\\python37\\Lib\\asyncio\\futures.py', 'C:\\python37\\Lib\\asyncio\\locks.py', 'C:\\python37\\Lib\\asyncio\\log.py', 'C:\\python37\\Lib\\asyncio\\proactor_events.py', 'C:\\python37\\Lib\\asyncio\\protocols.py', 'C:\\python37\\Lib\\asyncio\\queues.py', 'C:\\python37\\Lib\\asyncio\\runners.py', 'C:\\python37\\Lib\\asyncio\\selector_events.py', 'C:\\python37\\Lib\\asyncio\\sslproto.py', 'C:\\python37\\Lib\\asyncio\\streams.py', 'C:\\python37\\Lib\\asyncio\\subprocess.py', 'C:\\python37\\Lib\\asyncio\\tasks.py', 'C:\\python37\\Lib\\asyncio\\transports.py', 'C:\\python37\\Lib\\asyncio\\unix_events.py', 'C:\\python37\\Lib\\asyncio\\windows_events.py', 'C:\\python37\\Lib\\asyncio\\windows_utils.py', 'C:\\python37\\Lib\\asyncio\\__init__.py', 'C:\\python37\\Lib\\asyncio\\__pycache__'] ''' # C:\python37\Lib\asyncio\*表示查找以C:\python37\Lib\asyncio开头的文件或目录 # 后面又加了一个*,那么C:\python37\Lib\asyncio\*只能是目录了,查找C:\python37\Lib\asyncio里面的目录里面的文件或目录 # 查找的肯定是__pycache__,因为C:\python37\Lib\asyncio下面只有这一个目录, pprint.pprint(glob.glob(r"C:\python37\Lib\asyncio\*\*")) ''' ['C:\\python37\\Lib\\asyncio\\__pycache__\\base_events.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\base_futures.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\base_subprocess.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\base_tasks.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\constants.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\coroutines.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\events.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\format_helpers.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\futures.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\locks.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\log.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\proactor_events.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\protocols.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\queues.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\runners.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\selector_events.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\sslproto.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\streams.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\subprocess.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\tasks.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\transports.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\windows_events.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\windows_utils.cpython-37.pyc', 'C:\\python37\\Lib\\asyncio\\__pycache__\\__init__.cpython-37.pyc'] '''
3.单字符通配符
import glob
'''
问号(?)也是一个通配符,匹配任意单个字符
'''
for name in glob.glob(r"C:\python37\Lib\asyncio\?????.py"):
print(name)
r'''
C:\python37\Lib\asyncio\locks.py
C:\python37\Lib\asyncio\tasks.py
'''
4.字符区间
import glob
'''
如果使用字符区间而不是问号,则可以匹配多个字符中的任意一个,类似于正则表达式里面的正则区间
'''
for name in glob.glob(r"C:\python37\Lib\asyncio\lo[a-z].py"):
print(name) # C:\python37\Lib\asyncio\log.py
可以看到glob模块和pathlib.Path实例下的glob方法差不多
(四)fnmatch:Unix式glob模式匹配
''' fnmatch模块用于根据glob模式(如Unix shell所使用的的模式)比较文件名 '''
1.简单匹配
import fnmatch
'''
fnmatch将一个文件名与一个模式进行比较,并返回一个布尔值,指示二者是否匹配。
如果操作系统使用一个区分大小写的文件系统,则这个比较就是区分大小写的
?:匹配一个任意字符
*:匹配任意个任意字符
[sequence]:匹配出现在sequence里面的一个字符
[!sequence]:匹配没有出现在sequence里面的一个字符
'''
# 虽说是用来匹配文件名的,但是我匹配普通的字符串也是可以的
print(fnmatch.fnmatch("abcde", "*")) # True
print(fnmatch.fnmatch("abcde", "abc?")) # False
print(fnmatch.fnmatch("abcde", "abc??")) # True
print(fnmatch.fnmatch("abcde", "[a-z]????")) # True
print(fnmatch.fnmatch("aaa", "aaa*")) # True
# 可以看到默认是大小写不敏感的
print(fnmatch.fnmatch("Aaa", "aaa")) # True
# 如果我想区分大小写呢?可以使用fnmatchcase
print(fnmatch.fnmatchcase("Aaa", "aaa")) # False
import os
for name in os.listdir(r"C:\python37\Lib\asyncio"):
if fnmatch.fnmatch(name, "base_*.py"):
print(name)
'''
base_events.py
base_futures.py
base_subprocess.py
base_tasks.py
'''
2.过滤
import fnmatch import os from pprint import pprint ''' 要测试一个文件名序列,可以使用filter,会返回与模式参数匹配的文件名列表 ''' f = os.listdir(r"C:\python37\Lib\asyncio") pprint(f) ''' ['base_events.py', 'base_futures.py', 'base_subprocess.py', 'base_tasks.py', 'constants.py', 'coroutines.py', 'events.py', 'format_helpers.py', 'futures.py', 'locks.py', 'log.py', 'proactor_events.py', 'protocols.py', 'queues.py', 'runners.py', 'selector_events.py', 'sslproto.py', 'streams.py', 'subprocess.py', 'tasks.py', 'transports.py', 'unix_events.py', 'windows_events.py', 'windows_utils.py', '__init__.py', '__pycache__'] ''' print(fnmatch.filter(f, "base_*.py")) ''' ['base_events.py', 'base_futures.py', 'base_subprocess.py', 'base_tasks.py'] '''
3.转换模式
import fnmatch ''' 在内部,fnmatch将glob模式转换为一个正则表达式,并使用re模块比较文件名和模式。 translate函数是将glob模式转换为正则表达式的公共API ''' pattern = "base_*.py" print(fnmatch.translate(pattern)) # (?s:base_.*\.py)\Z
(五)linecache:高效的读取文本文件
''' 处理Python源文件时,Python标准库的其他部分用到了linecache模块。 缓存实现将在内存中保存文件的内容(解析为单独的行)。 这个API通过索引一个list来返回所请求的行,与反复地读取文件并解析文本来查找需要的文本相比,这样可以节省时间。 这个模块在查找同一个文件中的多行时尤其有用,比如为一个错误报告生成一个跟踪记录(traceback) '''
1.测试数据
# C:\python37\Lib\asyncio\base_futures.py
'''
__all__ = ()
import concurrent.futures._base
import reprlib
from . import format_helpers
Error = concurrent.futures._base.Error
CancelledError = concurrent.futures.CancelledError
TimeoutError = concurrent.futures.TimeoutError
class InvalidStateError(Error):
"""The operation is not allowed in this state."""
# States for Future.
_PENDING = 'PENDING'
_CANCELLED = 'CANCELLED'
_FINISHED = 'FINISHED'
def isfuture(obj):
"""Check for a Future.
This returns True when obj is a Future instance or is advertising
itself as duck-type compatible by setting _asyncio_future_blocking.
See comment in Future for more details.
"""
return (hasattr(obj.__class__, '_asyncio_future_blocking') and
obj._asyncio_future_blocking is not None)
def _format_callbacks(cb):
"""helper function for Future.__repr__"""
size = len(cb)
if not size:
cb = ''
def format_cb(callback):
return format_helpers._format_callback_source(callback, ())
if size == 1:
cb = format_cb(cb[0][0])
elif size == 2:
cb = '{}, {}'.format(format_cb(cb[0][0]), format_cb(cb[1][0]))
elif size > 2:
cb = '{}, <{} more>, {}'.format(format_cb(cb[0][0]),
size - 2,
format_cb(cb[-1][0]))
return f'cb=[{cb}]'
def _future_repr_info(future):
# (Future) -> str
"""helper function for Future.__repr__"""
info = [future._state.lower()]
if future._state == _FINISHED:
if future._exception is not None:
info.append(f'exception={future._exception!r}')
else:
# use reprlib to limit the length of the output, especially
# for very long strings
result = reprlib.repr(future._result)
info.append(f'result={result}')
if future._callbacks:
info.append(_format_callbacks(future._callbacks))
if future._source_traceback:
frame = future._source_traceback[-1]
info.append(f'created at {frame[0]}:{frame[1]}')
return info
'''
2.读取特定行
import linecache
'''
我们常用的序列的索引是从0开始的,但是linecache模块读取的文件行号是从1开始的
'''
# 表示读取C:\python37\Lib\asyncio\base_futures.py文件的第1行
print(linecache.getline(r"C:\python37\Lib\asyncio\base_futures.py", 1))
'''
__all__ = ()
'''
# 注意到这里有一个空行。因为我们在读取该行的时候,会自动将结尾的换行符也读取进来了。而Python的print函数自带换行符,因此会多出一个空行。
# 如果行号的范围超过了文件中的合法行号,那么会返回一个空字符串。
# 可以看看源码
'''
def getline(filename, lineno, module_globals=None):
lines = getlines(filename, module_globals)
if 1 <= lineno <= len(lines):
return lines[lineno-1]
else:
return ''
'''
# 同理读取一个不存在的文件也是一样的
print("%r" % linecache.getline("少年少女战国无双", 666)) # ''
3.读取Python源文件
import linecache
'''
由于生成traceback跟踪记录时linecache使用得非常频繁,其关键特性是能够指定模块的基名在导入路径中查找Python源模块
'''
module_line = linecache.getline("linecache.py", 3)
print(module_line)
'''
This is intended to read lines from modules imported -- hence if a filename
'''
file_src = linecache.__file__
print(file_src) # C:\python37\lib\linecache.py
# 如果linecache中的缓存填充代码在当前目录中无法找到指定名的文件,那么它会到sys.path中查找指定名的模块
# 除此之外,还有一个getlines,可以获取所有行,以列表的形式返回
print(linecache.getlines(r"C:\python37\Lib\asyncio\base_futures.py")[0: 10])
r'''
['__all__ = ()\n', '\n', 'import concurrent.futures._base\n', 'import reprlib\n', '\n', 'from . import format_helpers\n', '\n', 'Error = concurrent.futures._base.Error\n', 'CancelledError = concurrent.futures.CancelledError\n', 'TimeoutError = concurrent.futures.TimeoutError\n']
'''
print("".join(linecache.getlines(r"C:\python37\Lib\asyncio\base_futures.py")))
'''
__all__ = ()
import concurrent.futures._base
import reprlib
from . import format_helpers
Error = concurrent.futures._base.Error
CancelledError = concurrent.futures.CancelledError
TimeoutError = concurrent.futures.TimeoutError
class InvalidStateError(Error):
"""The operation is not allowed in this state."""
# States for Future.
_PENDING = 'PENDING'
_CANCELLED = 'CANCELLED'
_FINISHED = 'FINISHED'
def isfuture(obj):
"""Check for a Future.
This returns True when obj is a Future instance or is advertising
itself as duck-type compatible by setting _asyncio_future_blocking.
See comment in Future for more details.
"""
return (hasattr(obj.__class__, '_asyncio_future_blocking') and
obj._asyncio_future_blocking is not None)
def _format_callbacks(cb):
"""helper function for Future.__repr__"""
size = len(cb)
if not size:
cb = ''
def format_cb(callback):
return format_helpers._format_callback_source(callback, ())
if size == 1:
cb = format_cb(cb[0][0])
elif size == 2:
cb = '{}, {}'.format(format_cb(cb[0][0]), format_cb(cb[1][0]))
elif size > 2:
cb = '{}, <{} more>, {}'.format(format_cb(cb[0][0]),
size - 2,
format_cb(cb[-1][0]))
return f'cb=[{cb}]'
def _future_repr_info(future):
# (Future) -> str
"""helper function for Future.__repr__"""
info = [future._state.lower()]
if future._state == _FINISHED:
if future._exception is not None:
info.append(f'exception={future._exception!r}')
else:
# use reprlib to limit the length of the output, especially
# for very long strings
result = reprlib.repr(future._result)
info.append(f'result={result}')
if future._callbacks:
info.append(_format_callbacks(future._callbacks))
if future._source_traceback:
frame = future._source_traceback[-1]
info.append(f'created at {frame[0]}:{frame[1]}')
return info
'''
(六)tempfile:临时文件系统对象
''' 想要安全的创建名字唯一的临时文件,以防止被试图破坏应用或窃取数据的人猜出,这很有难度。 tempfile模块提供了多个函数来安全创建临时文件系统资源。 TemporaryFile函数打开并返回一个未命名的文件,NamedTemporaryFile打开并返回命名文件,SpooledTemporaryFile在将文件写入磁盘之前会先将其保存在内存中,TemporaryDirectory是一个上下文管理器,上下文关闭时会删除这个目录 '''
1.临时文件
import tempfile
'''
如果应用需要临时文件来存储数据,而不需要与其他程序共享这些文件,则应当使用TemporaryFile函数来创建文件。
这个函数会创建一个文件,而且如果平台支持,它会立即断开这个新文件的链接。
这样一来,其他程序就不可能找到或者打开这个文件,因为文件系统表中根本没有这个文件的引用。
对于TemporaryFile函数创建的文件,不论通过调用close函数,还是结合使用上下文管理器API和with语句,关闭文件时都会自动删除这个临时文件
'''
# mode:默认是w+b
with tempfile.TemporaryFile(mode="w+", encoding="utf-8") as tmp:
print(tmp) # <tempfile._TemporaryFileWrapper object at 0x0000000002372A20>
# 随机生成的名字,但是我们是不需要指定名字的
print(tmp.name) # C:\Users\EDZ\AppData\Local\Temp\tmpr5_ubktu
print(tmp.mode) # w+
with tempfile.TemporaryFile(mode="w+", encoding="utf-8") as tmp:
tmp.write("这是一个临时文件,里面存储了内容")
# 注意文件写完之后,指针移到了末尾,要想读取的话,需要将指针移到行首
tmp.seek(0)
print(tmp.read()) # 这是一个临时文件,里面存储了内容
2.命名文件
import tempfile
import pathlib
'''
有些情况下,可能非常需要一个命名的临时文件。对于跨多个进程甚至主机的应用来说,为文件命名是在应用的不同部分之间传递文件的最简单的办法
NamedTemporaryFile函数会创建一个文件,但不会断开它的链接,所以会保留它的文件名(用name属性访问)
'''
with tempfile.NamedTemporaryFile() as tmp:
print(tmp.name) # C:\Users\EDZ\AppData\Local\Temp\tmp3gg7iiir
f = pathlib.Path(tmp.name)
print(f.exists()) # True
# 句柄关闭后,文件将被删除
print(f.exists()) # False
3.假脱机文件
import tempfile
'''
如果临时文件中包含的数据相对较少,则使用SpooledTemporaryFile函数可能更高效,因为它使用一个io.BytesIO或io.StringIO缓冲区在内存中保存内容,直到数据达到一个阈值大小。
当数据量超过这个阈值时,数据将滚动并写入磁盘,然后用常规的TemporaryFile替换这个缓冲区
'''
with tempfile.SpooledTemporaryFile(max_size=40, mode="w+", encoding="utf-8") as f:
for i in range(4):
f.write("这一行会被反复不断地写哦")
print(f._rolled, f._file)
'''
False <_io.StringIO object at 0x00000000021E90D8>
False <_io.StringIO object at 0x00000000021E90D8>
False <_io.StringIO object at 0x00000000021E90D8>
True <tempfile._TemporaryFileWrapper object at 0x0000000002972BA8>
'''
# 如果要显示地将缓冲区里面的数据写入磁盘,可以调用rollover或者fileno函数
4.临时目录
import tempfile ''' 需要多个临时文件时,可能更方便的做法是用TemporaryDirectory创建一个临时目录,并打开目录中的所有文件 ''' # 不常用
5.临时文件位置
import tempfile ''' 在创建临时文件,可以指定dir,即临时文件的生成路径。如果没有指定dir的话,那么临时文件的存储路径会根据当前平台的不同而不同。 tempfile模块包含两个函数,可以用来查询运行时使用的设置 ''' # 返回包含所有临时文件的默认目录 print(tempfile.gettempdir()) # C:\Users\EDZ\AppData\Local\Temp # 返回新文件和目录名的字符串前缀 print(tempfile.gettempprefix()) # tmp
(七)shutil:高层文件操作
''' shutil模块包括一些高层文件操作,如赋值和归档 '''
1.复制文件
import shutil ''' copyfile将源文件的内容复制到目标文件,如果没有权限写目标文件,则会产生一个IOError ''' # copyfile(源文件,目的文件) shutil.copyfile(r"C:\python37\Lib\asyncio\base_futures.py", "copy_base_futures.py") ''' 这个函数底层是使用copyfileobj,copyfileobj接收的是文件句柄。 因此copyfile这个函数会打开输入文件进行读取,所以某些特殊文件(如Unix的设备节点)不可以通过copyfile复制为新的特殊文件。 ''' # copy(源文件, 目的文件或者目录) ''' 对于copyfile来说,必须是文件。如果目的文件我们指定了一个目录(比如temp),得到的依旧是一个名为temp的文件 但是对于copy来说,如果目的文件我们指定了一个目录,那么会将文件拷贝到这个目录里面去,新的文件名和源文件名一致。但如果目录不存在那么和copyfile是一样的。 ''' shutil.copy(r"C:\python37\Lib\asyncio\base_futures.py", r"666") # 如果存在名为666的目录,那么会在666目录中创建一个名为base_futures.py的文件。如果不存在,那么会在当前目录创建一个名为666的文件 # 如果是copy的话,那么无论666这个目录存在与否,都是在当前目录创建一个名为666的文件 # copy2:和copy类似,只不过copy只是拷贝文件内容,copy2除了拷贝文件内容还会拷贝文件的访问和修改时间。 # 得到的文件和源文件的所有特性都相同
2.复制文件元数据
import shutil ''' 默认地,在Unix下创建一个新文件时,它会根据当前用户的unmask接收权限。 要把权限从一个文件复制到另外一个文件,可以使用copymode 要为文件复制其他元数据,可以使用copystat '''
3.处理目录树
import shutil ''' shutil包含3个函数来处理目录树。 要把一个目录从一个位置复制到另外一个位置,可以使用copytree,这个函数会递归遍历目录树,将文件复制到目标位置。目标目录必须不存在,存在会报错 ''' # 别看我目的目录指定的文件的格式,但是还是会创建一个目录,只不过这个目录就叫做aa.py shutil.copytree(r"C:\python37\Lib\asyncio", r"aa.py") # 如果要把一个文件或者目录移动到另外一个位置,可以使用move # 类似于Unix下的mv命令,如果源和目标都在同一个文件夹中,那么属于重命名。如果不在,那么会先将源文件复制到目标文件,然后再删除源文件 # 这里不再演示
4.查找文件
import shutil
'''
which函数会扫描一个路径以查找一个命名文件。
典型的用法是在环境变量PATH定义的shell搜索路径中查找一个可执行程序。
'''
print(shutil.which("go")) # C:\Go\bin\go.EXE
print(shutil.which("python")) # C:\Python37\python.EXE
print(shutil.which("aaa")) # None
# 除此之外还可以指定路径,如果不指定路径,那么默认是os.environ("PATH")
# 但是查找文件可以使用之前说到的pathlib
import pathlib
p = pathlib.Path(r"C:\python37\Lib\site-packages\pandas")
for name in p.rglob("frame.py"):
print(name)
r'''
C:\python37\Lib\site-packages\pandas\core\frame.py
C:\python37\Lib\site-packages\pandas\core\sparse\frame.py
'''
5.归档
import shutil
'''
Python的标准库包含很多模块来管理归档文件,如tarfile和zipfile。
另外shutil中也提供了很多更高层的函数来创建和解压归档文件。
get_archive_formats函数可以查看当前系统上支持的所有格式的名字和描述
'''
for name, format in shutil.get_archive_formats():
print(name, ":", format)
'''
bztar : bzip2'ed tar-file
gztar : gzip'ed tar-file
tar : uncompressed tar file
xztar : xz'ed tar-file
zip : ZIP file
'''
# 支持的格式取决于有哪些模块和底层库。因此根据这个例子在哪里运行,它的输出可能会有所变化。
# 可以使用make_archive函数来创建一个新的归档文件,说白了就是压缩包。
# shutil.make_archive(压缩的文件或目录, 压缩的格式, 存放的路径)
shutil.make_archive(r"C:\python37\Lib\asyncio", "zip", r"C:\python37")
# 表示将C:\python37\Lib\asyncio下面的所有文件打包成zip格式放到C:\Users目录下
# 除此之外,还可以对一个压缩包进行解包
# shutil.unpack_archive(压缩包的名字, 解压到的位置)
6.文件系统空间
import shutil
'''
完成一个长时间运行、可能耗尽可用空间的操作之前,最好先检查本地文件系统,来看看有多少可用的空间,这会很有用。
disk_usage函数会返回一个元组,包括总空间、当前正在使用的空间、以及未用的空间(自由空间)
'''
total_bytes, used_bytes, free_bytes = shutil.disk_usage("C:")
print(total_bytes/1024/1024/1024) # 99.99999618530273
print(used_bytes/1024/1024/1024) # 44.406620025634766
print(free_bytes/1024/1024/1024) # 55.59337615966797
# 除此之外可以使用psutil这个模块
import psutil
# 可以看到,帮我们把所用比例都算出来了,目前用了百分之44.4
print(psutil.disk_usage("C:")) # sdiskusage(total=107374178304, used=47681261568, free=59692916736, percent=44.4)
8.filecmp:比较文件
''' filecmp模块提供了一些函数和一个类,来比较文件系统上的文件和目录 '''
1.比较文件
import filecmp
'''
cmp函数用来比较文件系统上的两个文件
filecmp.cmp("file1", "file2", shallow=False)
比较两个文件是否一致,shallow参数告诉cmp函数,除了文件的元数据外,是否还要查看文件的内容。
shallow参数默认为True,表示浅比较,会使用os.stat函数得到的信息来完成,如果结果是一样的那么就认为是一样的文件。
因此对于同时创建的大小相同的文件,即使内容不同,也会认为是相同的文件。
指定shallow为False,表示不进行浅比较,除了文件的元数据之外,还要比较文件的内容,只有都相同才会认为这两个文件是相同的
'''
2.比较目录
import filecmp ''' 前面介绍的函数更适合完成相对简单的比较,。对于大目录树的递归或者比较更完整的分析,dircmp更有用。 ''' dc = filecmp.dircmp(r"C:\python37\Lib\asyncio", r"C:\python37\Lib\asyncio") # 可以使用report方法带引两个目录的报告 dc.report() # 但是不会比较子目录,如果想比较子目录的话,可以使用另一个方法 dc.report_full_closure()
(九)mmap:内存映射文件
''' 建立一个文件的内存映射将使用操作系统虚拟内存来直接访问文件系统上的数据,而不是使用常规的I/O函数访问数据。 内存映射通常可以提高I/O性能,因为使用内存映射时,不需要对每一个访问都建立一个单独的系统调用,也不需要你在缓冲区之间复制数据。实际上内核和用户应用都能直接访问内存。 内存映射文件可以看做是可修改的字符串或类似文件的对象,这取决于具体的需要。 映射文件支持一般文件的API方法,如close、flush、read、readline、seek、tell、write。他还支持字符串的API,提供切片等特性以及类似find的方法 '''
1·.读文件
import mmap
'''
使用mmap函数可以创建一个内存映射文件。第一个参数是文件描述符,可能来自file对象的fileno方法,也可能来自os.open。
调用者在调用mmap方法之前负责打开文件,不再需要文件时要负责将其关闭。
mmap函数的第二个参数是要映射的文件部分的大小(以字节为单位)。如果这个值为0,则映射整个文件,如果这个大小大于文件的当前大小,则会扩展该文件。
注意:Windows不支持长度为0的映射
'''
'''
这两个平台都支持一个可选的参数access。使用ACCESS_READ表示只读访问;ACCESS_WRITE表示“写通过(write-through)”,即对内存的赋值直接写入文件;
ACCESS_COPY表示“写时赋值(copy-on-write)”, 堆内存的赋值不会写入文件
'''
with open(r"C:\python37\Lib\asyncio\sslproto.py", "r", encoding="utf-8") as f:
with mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ) as m:
print("first 10 bytes via read:", m.read(10)) # first 10 bytes via read: b'import col'
print("first 10 bytes via slice:", m[: 10]) # first 10 bytes via slice: b'import col'
print("2nd 10 bytes via read:", m.read(10)) # 2nd 10 bytes via read: b'lections\r\n'
r'''
可以看到既可以通过切片访问,也可以通过read访问。通过read访问,会使得指针移动,但是切片无论何时都是从头读取,并且对文件指针的移动没有任何影响。
在这个例子中:第一次读取,指针向前移动10个字节,然后由切片操作,对文件指针无影响
切片操作之后,再调用read会给出文件的11~20个字节。
'''
2.写文件
import mmap
'''
要建立内存映射文件来接收更新,映射之前首先要使用模式r+(而不是w,w的话直接清空了)打开文件以便完成追加。然后可以使用任何可以改变数据的API方法。
'''
with open("1.txt", "r+", encoding="utf-8") as f:
with mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_WRITE) as m:
print(m.read()) # b'**pandas** is a Python package'
m.seek(0)
loc = m.find(b"Python")
m[loc: loc+len("Python")] = b"pYTHON"
print(m.read()) # b'**pandas** is a pYTHON package'
# 复制模式
# 使用访问设置ACCESS_COPY是不会把修改写入磁盘上的文件
# 只需要把ACCESS_WRITE改成ACCESS_COPY即可
3.正则表达式
import mmap
'''
由于内存映射文件就类似于一个字符串,因此也常与其他处理字符串的模块一起使用,比如正则表达式。
with mmap.mmap() as m:
re.match(pattern, repl, m)
'''
(十)codecs:字符串编码和解码
''' codecs模块提供了流接口和文件接口来完成文本数据不同表示之间的转换。通常用于处理Unicode文本,不过也提供了其他编码来满足其他用途 '''
1.Unicode入门
''' cpython 3.x区分了文件和字节串。bytes实例使用一个8位字节值序列。与之不同,str串在内部作为一个Unicode码点序列来管理。 码点用2字节或者4字节表示,这取决于编译Python时指定的选项。 输出str值时,会使用某种标准极值编码,以后可以将这个字节序列重构为同样的文本串。编码值的字节不一定与码点值完全相同,编码只是定义了两个值集之间转换的一种方式。 读取Unicode数据时还需要知道编码,这样才能把接收到的字节转换为Unicode类使用的内部表示。 ''' # 编码 ''' 要了解编码,最好的方法就是采用不同方式对相同的串进行编码,并查看所生成的不同字节的序列 '''
2.处理文件
import codecs
'''
处理I/O操作时,编码和解码字符串尤为总要。不论是写至一个文件、套接字、还是其他流,数据都必须使用适当的编码。
一般来讲,所有文本数据在读取时都需要由其字节表示解码,写数据时则需要从内部值编码为一种特定的表示。
程序可以显示地编码和解码数据,不过取决于所用的编码,要想确定是否已经读取了足够的字节来充分解码数据,这可能并不容易。
codecs提供了一些类来管理数据编码和解码,所以应用不再需要做这个工作
codecs提供的最简单的接口可以替代内置open函数。这个新版本的函数与内置函数open的做法很相似,不过增加了两个参数来指定编码和所需要的错误处理技术
'''
with codecs.open("1.txt", "r", encoding="utf-8") as f:
print(f.read())
'''
فيينا اول مايو 2017 ( شينخوا ) وصف وزير الخارجية النمساوى سيباستيان كورتس
الوضع الحالي فى ليبيا بانه "لا يزال سيئا للغاية"،
وذلك خلال زيارة قام بها اليوم الاثنين هناك، وفقا لوكالة انباء الصحافة النمساوية
'''
3.字节序
import codecs ''' 在不同计算机系统之间传输数据时(可能会直接复制一个文件,或者使用网络通信来完成传输),多字节编码(如utf-8,utf-16)会带来一个问题。 不同系统中使用的高字节和低字节的顺序不同。数据的这个特性被称为字节序,这取决硬件体系结构等因素,还取决于操作系统和应用开发人员做出的选择。 通常没有办法提前知道给定的一组数据要使用哪一个字节序,所以多字节编码还包含一个字节序标志(Byte-Order Marker, BOM),这个标志出现在编码输出的前几个字节 '''
4.错误处理
import codecs ''' 前面几节指出,读写Unicode文件时需要知道所使用的编码。正确地设置编码很重要,有以下几个原因: 首先,如果读文件时没有正确地配置编码,就无法正确地解释数据,数据有可能被破坏或者无法正常解码。 其次,并不是所有的Unicode字符都能用任意编码表示,所以写文件时使用了错误的编码,就会产生一个错误,可能丢失数据 类似于str的encode方法和bytes的decode方法,codecs也使用了同样的5个错误处理选项, strict 如果数据无法转换,将产生一个异常 replace 将无法编码的数据替换为一个特殊的标志字符 ignore 跳过数据 xmlcharrefreplace xml字符,仅适用于编码 backslashreplace 转义序列,仅适用于编码 '''
5编码转换
import codecs
import io
'''
尽管大多数应用都在内部处理str数据,将数据解码或编码作为I/O操作的一部分,但有些情况下,可能需要改变文件的编码而不继续坚持这种中间数据格式,这可能很有用
EncodedFile取一个使用某种编码打开的文件句柄,用一个类包装这个文件句柄,有I/O操作时它会把数据转换为另一种编码。
'''
output = io.BytesIO()
data = "سيباستيان كورتس".encode("utf-8")
encoded_file = codecs.EncodedFile(output, data_encoding="utf-8", file_encoding="utf-8")
encoded_file.write(data)
print(output.getvalue())
print(output.getvalue().decode("utf-8"))
r'''
b'\xd8\xb3\xd9\x8a\xd8\xa8\xd8\xa7\xd8\xb3\xd8\xaa\xd9\x8a\xd8\xa7\xd9\x86 \xd9\x83\xd9\x88\xd8\xb1\xd8\xaa\xd8\xb3'
سيباستيان كورتس
'''
# file_encoding:打开文件句柄所用的编码
# data_encoding:通过read和write调用传递数据时所用的编码
(十一)io:文本、十进制和原始流I/O工具
''' io模块在解释器内置的open函数之上实现了一些类来完成基于文件的输入和输出操作。 这些类得到了适当的分解,从而可以针对不同的用途重新组合--例如,支持向一个网络套接字写Unicode数据 '''
1.内存中的流
import io
'''
StringIO提供了一种很便利的方式,可以使用文件API处理内存中的文本。
有些情况下,与其他的一些字符串连接技术相比,使用StringIO构造大字符串可以提供更好的性能。
内存中的流缓冲区对测试也很有用,写入磁盘上真正的文件并不会减慢测试套件的速度
'''
# 创建一个缓存
output = io.StringIO()
# 写入数据
output.write("hello,")
output.write("world")
# 获取数据
print(output.getvalue()) # hello,world
# 关闭缓存
output.close()
# 除了StringIO,还有一个BytesIO,用法一样的,只不过前者传入字符串,后者传入字节。
output = io.BytesIO()
data1 = bytes("蛤蛤蛤蛤", encoding="utf-8")
data2 = bytes("嗝", encoding="utf-8")
output.write(data1)
output.write(data2)
print(output.getvalue()) # b'\xe8\x9b\xa4\xe8\x9b\xa4\xe8\x9b\xa4\xe8\x9b\xa4\xe5\x97\x9d'
print(str(output.getvalue(), encoding="utf-8")) # 蛤蛤蛤蛤嗝
2.为文本数据包装字节流
import io
'''
原始字节流(如套接字)可以被包装为一个层来处理串编码和解码,从而可以更容易地用于处理文本数据。
TextIOWrapper类支持读写,write_through参数会禁用缓冲,并且立即将写至包装器的所有数据刷新到底层缓冲区
'''
output = io.BytesIO()
wrapper = io.TextIOWrapper(output,
encoding="utf-8",
write_through=True)
wrapper.write("哈哈哈")
wrapper.write("嗝")
print(output.getvalue()) # b'\xe5\x93\x88\xe5\x93\x88\xe5\x93\x88\xe5\x97\x9d'
# 可以直接使用wrapper代替output,当然最后还是写到output里面
7.Python3标准库--文件系统的更多相关文章
- 8.Python3标准库--数据持久存储与交换
''' 持久存储数据以便长期使用包括两个方面:在对象的内存中表示和存储格式之间来回转换数据,以及处理转换后数据的存储区. 标准库包含很多模块可以处理不同情况下的这两个方面 有两个模块可以将对象转换为一 ...
- 1.Python3标准库--前戏
Python有一个很大的优势便是在于其拥有丰富的第三方库,可以解决很多很多问题.其实Python的标准库也是非常丰富的,今后我将介绍一下Python的标准库. 这个教程使用的书籍就叫做<Pyth ...
- Python3 标准库
Python3标准库 更详尽:http://blog.csdn.net/jurbo/article/details/52334345 文本 string:通用字符串操作 re:正则表达式操作 diff ...
- python023 Python3 标准库概览
Python3 标准库概览 操作系统接口 os模块提供了不少与操作系统相关联的函数. >>> import os >>> os.getcwd() # 返回当前的工作 ...
- 比较两个文件的异同Python3 标准库difflib 实现
比较两个文件的异同Python3 标准库difflib 实现 对于要比较两个文件特别是配置文件的差异,这种需求很常见,如果用眼睛看,真是眼睛疼. 可以使用linux命令行工具diff a_file b ...
- python3标准库总结
Python3标准库 操作系统接口 os模块提供了不少与操作系统相关联的函数. ? 1 2 3 4 5 6 >>> import os >>> os.getcwd( ...
- 9.Python3标准库--数据压缩与归档
''' 尽管现代计算机系统的存储能力日益增长,但生成数据的增长是永无休止的. 无损(lossless)压缩算法以压缩或解压缩数据花费的时间来换取存储数据所需要的空间,以弥补存储能力的不足. Pytho ...
- 读书分享全网学习资源大合集,推荐Python3标准库等五本书「02」
0.前言 在此之前,我已经为准备学习python的小白同学们准备了轻量级但超无敌的python开发利器之visio studio code使用入门系列.详见 1.PYTHON开发利器之VS Code使 ...
- 3.Python3标准库--数据结构
(一)enum:枚举类型 import enum ''' enum模块定义了一个提供迭代和比较功能的枚举类型.可以用这个为值创建明确定义的符号,而不是使用字面量整数或字符串 ''' 1.创建枚举 im ...
随机推荐
- 用Racket语言写了一个万花筒的程序
用Racket语言写了一个万花筒的程序 来源:https://blog.csdn.net/chinazhangyong/article/details/79362394 https://github. ...
- ORACLE 存储过程异常捕获并抛出
for tab_name in tables loop execute immediate 'drop table '||tab_name; --此处可能会报错 end loop; 当前情况是,循环表 ...
- Spring Boot系列教程六:日志输出配置log4j2
一.前言 spring boot支持的日志框架有,logback,Log4j2,Log4j和Java Util Logging,默认使用的是logback日志框架,笔者一直在使用log4j2,并且 ...
- Java进程配置文件Reload
我们在开发Java程序的时候,很多常量信息都存在配置文件中,比如数据库连接信息.ip黑名单,事件的超时时间等等.当需要该这些配置的值时都需要重新启动进程,改动的配置才会生效,有时候线上的应用不能容忍这 ...
- [雅礼集训 2017 Day1]市场
link 试题分析 可以容易发现此题维护的是一个数据结构,支持区间加,区间除,区间查询最大值.其实就是在$\log$级复杂度内维护除法操作. 我们发现当除数很大或者此串序列大小差不多时,我们令$a_i ...
- The 14th Zhejiang Provincial Collegiate Programming Contest Sponsored by TuSimple - C 暴力 STL
What Kind of Friends Are You? Time Limit: 1 Second Memory Limit: 65536 KB Japari Park is a larg ...
- sloop公共函数之添加信号,定时器及socket
1:添加信号 1.1 原型:sloop_handle sloop_register_signal(int sig, sloop_signal_handler handler, void * param ...
- 类的起源与metaclass
一.概述 我们知道类可以实例化出对象,那么类本身又是怎么产生的呢?我们就来追溯一下类的起源. 二.类的起源 2.1 创建一个类 class Foo(object): def __init__(self ...
- 题解 P2472 【[SCOI2007]蜥蜴】
P2472 [SCOI2007]蜥蜴 题目背景 07四川省选 题目描述 在一个r行c列的网格地图中有一些高度不同的石柱,一些石柱上站着一些蜥蜴,你的任务是让尽量多的蜥蜴逃到边界外. 每行每列中相邻石柱 ...
- xcode禁用ARC(Automatic Reference Counting)
Automatic Reference Counting,自动引用计数,即ARC,可以说是WWDC2011和iOS5所引入的最大的变革和最激动人心的变化.ARC是新的LLVM 3.0编译器的一项特性, ...