[Python爬虫] 之四:Selenium 抓取微博数据
抓取代码:
# coding=utf-8
import os
import re
from selenium import webdriver
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.action_chains import ActionChains
import IniFile
class weibo: def __init__(self):
#通过配置文件获取IEDriverServer.exe路径
configfile = os.path.join(os.getcwd(),'config.conf')
cf = IniFile.ConfigFile(configfile)
IEDriverServer = cf.GetValue("section", "IEDriverServer")
#每抓取一页数据延迟的时间,单位为秒,默认为5秒
self.pageDelay = 5
pageInteralDelay = cf.GetValue("section", "pageInteralDelay")
if pageInteralDelay:
self.pageDelay = int(pageInteralDelay) os.environ["webdriver.ie.driver"] = IEDriverServer
self.driver = webdriver.Ie(IEDriverServer) def scroll_top(self):
'''
滚动条拉到顶部
:return:
'''
if self.driver.name == "chrome":
js = "var q=document.body.scrollTop=0" else:
js = "var q=document.documentElement.scrollTop=0"
return self.driver.execute_script(js) def scroll_foot(self):
'''
滚动条拉到底部
:return:
''' if self.driver.name == "chrome":
js = "var q=document.body.scrollTop=10000" else:
js = "var q=document.documentElement.scrollTop=10000"
return self.driver.execute_script(js) def printTopic(self,topic):
print '原始数据: %s' % topic
print ' '
author_time_nums_index = topic.rfind('@')
ht = topic[:author_time_nums_index]
ht = ht.replace('\n', '')
print '话题: %s' % ht author_time_nums = topic[author_time_nums_index:]
author_time = author_time_nums.split('ñ')[0]
nums = author_time_nums.split('ñ')[1]
pattern1 = re.compile(r'\d{1,2}分钟前|今天\s{1}\d{2}:\d{2}|\d{1,2}月\d{1,2}日\s{1}\d{2}:\d{2}')
time1 = re.findall(pattern1, author_time) print '话题作者: %s' % author_time.split(' ')[0]
# print '时间: %s' % author_time.split(' ')[1]
print '时间: %s' % time1[0]
print '点赞量: %s' % nums.split(' ')[0]
print '评论量: %s' % nums.split(' ')[1]
print '转发量: %s' % nums.split(' ')[2]
print ' ' def CatchData(self,listClass,firstUrl):
'''
抓取数据
:param id: 要获取元素标签的ID
:param firstUrl: 首页Url
:return:
'''
start = time.clock()
#加载首页
wait = ui.WebDriverWait(self.driver, 20)
self.driver.get(firstUrl)
#打印标题
print self.driver.title # # 聚焦元素
# target = self.driver.find_element_by_id('J_ItemList')
# self.driver.execute_script("arguments[0].scrollIntoView();", target) #滚动5次滚动条
Scrollcount = 5
while Scrollcount > 0:
Scrollcount = Scrollcount -1
self.scroll_foot() #滚动一次滚动条,定位查找一次
total = 0
for className in listClass:
time.sleep(10)
wait.until(lambda driver: self.driver.find_elements_by_xpath(className))
Elements = self.driver.find_elements_by_xpath(className)
for element in Elements:
print ' '
txt = element.text.encode('utf8')
self.printTopic(txt)
total = total + 1 self.driver.close()
self.driver.quit()
end = time.clock() print ' '
print "共抓取了: %d 个话题" % total
print "整个过程用时间: %f 秒" % (end - start) # #测试抓取微博数据
obj = weibo()
#pt_li pt_li_2 S_bg2
#pt_li pt_li_1 S_bg2
# firstUrl = "http://weibo.com/?category=0"
firstUrl = "http://weibo.com/?category=1760"
listClass = []
listClass.append("//li[@class='pt_li pt_li_1 S_bg2']")
listClass.append("//li[@class='pt_li pt_li_2 S_bg2']")
obj.CatchData(listClass,firstUrl)
登录窗口
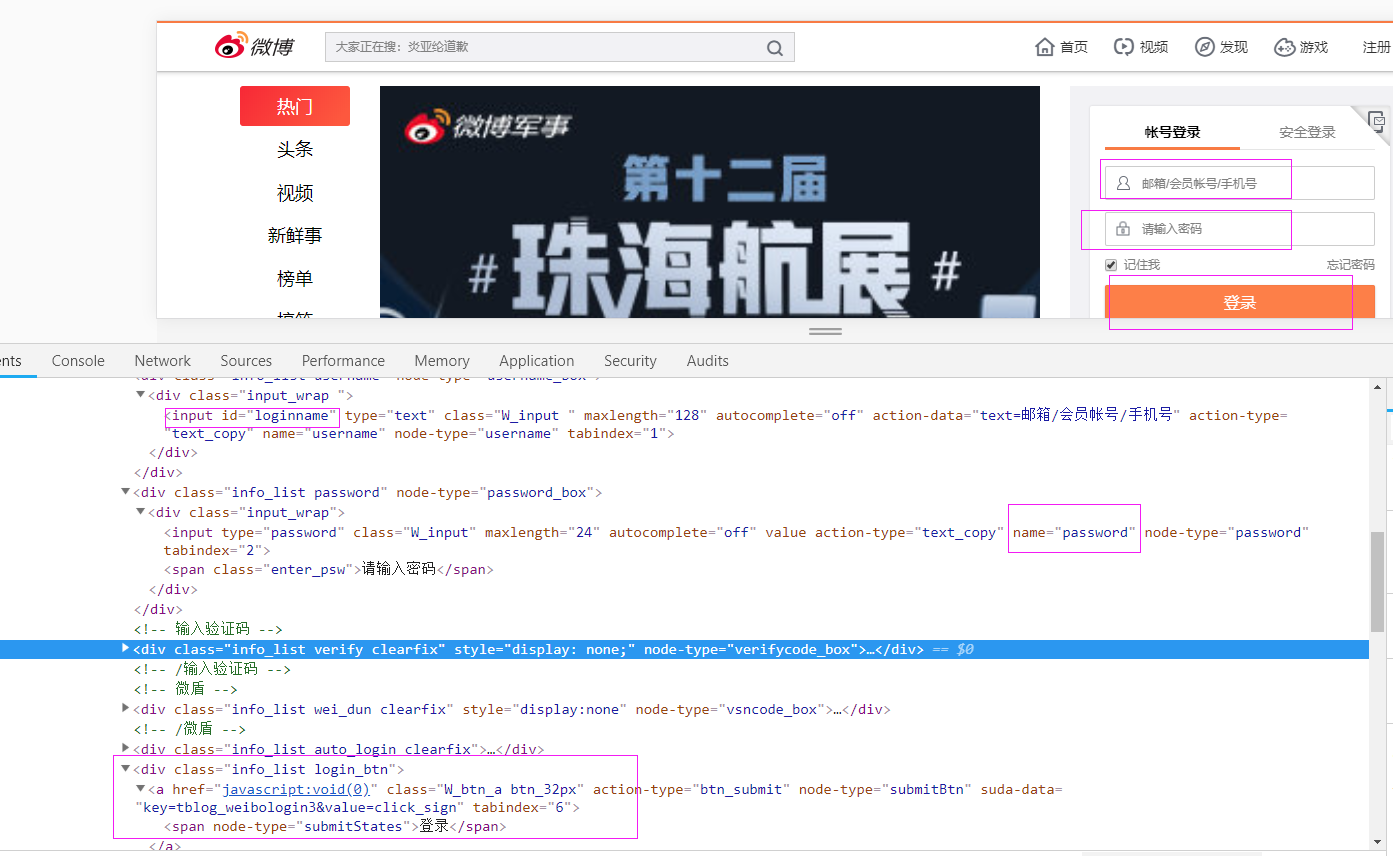
def longon(self):
flag = True
try:
self.driver.get('https://weibo.com/')
self.driver.maximize_window()
time.sleep(2)
accname = self.driver.find_element_by_id("loginname")
accname.send_keys('username')
accpwd = self.driver.find_element_by_name("password")
accpwd.send_keys('password')
submit = self.driver.find_element_by_xpath("//div[@class='info_list login_btn']/a")
submit.click()
time.sleep(2)
except Exception as e1:
message = str(e1.args)
flag = False
return flag
[Python爬虫] 之四:Selenium 抓取微博数据的更多相关文章
- [Python爬虫] 之八:Selenium +phantomjs抓取微博数据
基本思路:在登录状态下,打开首页,利用高级搜索框输入需要查询的条件,点击搜索链接进行搜索.如果数据有多页,每页数据是20条件,读取页数 然后循环页数,对每页数据进行抓取数据. 在实践过程中发现一个问题 ...
- 用python+selenium抓取微博24小时热门话题的前15个并保存到txt中
抓取微博24小时热门话题的前15个,抓取的内容请保存至txt文件中,需要抓取排行.话题和阅读数 #coding=utf-8 from selenium import webdriver import ...
- 如何让Python爬虫一天抓取100万张网页
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 王平 源自:猿人学Python PS:如有需要Python学习资料的 ...
- 一个月入门Python爬虫,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得 ...
- 芝麻HTTP:Python爬虫实战之抓取爱问知识人问题并保存至数据库
本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表达式的简 ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
- python爬虫 前程无忧网页抓取
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- Python爬虫:如何爬取分页数据?
上一篇文章<Python爬虫:爬取人人都是产品经理的数据>中说了爬取单页数据的方法,这篇文章详细解释如何爬取多页数据. 爬取对象: 有融网理财项目列表页[履约中]状态下的前10页数据,地址 ...
- Python爬虫之一 PySpider 抓取淘宝MM的个人信息和图片
ySpider 是一个非常方便并且功能强大的爬虫框架,支持多线程爬取.JS动态解析,提供了可操作界面.出错重试.定时爬取等等的功能,使用非常人性化. 本篇通过做一个PySpider 项目,来理解 Py ...
随机推荐
- 通过 JS 实现错误页面在指定的时间跳到主页
通过 JS 实现错误页面在指定的时间跳到主页 <!DOCTYPE html> <html> <head> <title>浏览器对象</title& ...
- (11)go 数组和切片
一.数组 1.定义数组 定义时付给该类型默认值 2.初始化 箭头指向的数组代表数组的下标 3.数组遍历 方法1: 方法2: 二.切片 数组的数量不固定 1. 2. 3. string可以进行切片处理
- Xamarin.Forms教程开发的Xcode的下载安装
Xamarin.Forms教程开发的Xcode的下载安装 Xamarin.Forms教程开发的Xcode的下载安装,Xcode是开发iOS应用程序的图形化开发工具.本节将讲解Xamarin.Forms ...
- Wordpress,你好!
[caption id="" align="alignleft" width="1024"] 耳机[/caption] 想了想,还是没有删掉 ...
- 【BZOJ 3443】 3443: 装备合成 (离线+线段树)
3443: 装备合成 Time Limit: 15 Sec Memory Limit: 128 MBSubmit: 63 Solved: 31 Description [背景] lll69 ...
- QT学习笔记2:QT中常用函数
一.QString转number QString number() QString number() QString number() QString number() QString number( ...
- bzoj 4874: 筐子放球
4874: 筐子放球 Time Limit: 10 Sec Memory Limit: 256 MB Description 小N最近在研究NP完全问题,小O看小N研究得热火朝天,便给他出了一道这样 ...
- 使用SQL语句将数据库中的两个表合并成一张表
select * into 新表名 from (select * from T1 union all select * from T2) 这个语句可以实现将合并的数据追加到一个新表中. 不合并重复数 ...
- bzoj1393 旅游航道
Description SGOI旅游局在SG-III星团开设了旅游业务,每天有数以万计的地球人来这里观光,包括联合国秘书长,各国总统和SGOI总局局长等.旅游线路四通八达,每天都有总躲得载客太空飞船在 ...
- HDU 5292 Pocket Cube 结论题
Pocket Cube 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5292 Description Pocket Cube is the 2×2× ...