精华推荐 |【算法数据结构专题】「延时队列算法」史上非常详细分析和介绍如何通过时间轮(TimingWheel)实现延时队列的原理指南

时间轮的介绍
时间轮(TimeWheel)是一种实现延迟功能(定时器)的精妙的高级算法,其算法应用范围非常广泛,在Java开发过程中常用的Dubbo、Netty、Akka、Quartz、ZooKeeper 、Kafka等各种框架中,各种操作系统的定时任务crontab调度都有用到,甚至Linux内核中都有用到,不夸张的是几乎所有和时间任务调度都采用了时间轮的思想。
时间轮的作用
高效处理批量任务
时间轮可以高效的利用线程资源来进行批量化调度,把大批量的调度任务全部都绑定时间轮上,通过时间轮进行所有任务的管理,触发以及运行。
降低时间复杂度
时间轮算法可以将插入和删除操作的时间复杂度都降为O(1),在大规模问题下还能够达到非常好的运行效果。
高效管理延时队列
能够高效地管理各种延时任务,周期任务,通知任务等,相比于JDK自带的Timer、DelayQueue + ScheduledThreadPool来说,时间轮算法是一种非常高效的调度模型。
缺点:时间精确度的问题
时间轮调度器的时间的精度可能不是很高,对于精度要求特别高的调度任务可能不太适合。因为时间轮算法的精度取决于时间段“指针”单元的最小粒度大小,比如时间轮的格子是一秒跳一次,那么调度精度小于一秒的任务就无法被时间轮所调度。
精度问题我们可以考虑后面提出的优化方案:多级时间轮。
时间轮的使用场景
- 调度模型,时间轮是为解决高效调度任务而产生的调度模型。例如,周期任务。
- 数据结构,通常由hash table和链表实现的数据结构。
- 延时任务、周期性任务应用场景主要在延迟大规模的延时任务、周期性的定时任务等。
- 通知任务等等。
时间轮的实现方案
为了充分发挥时间轮算法的效果和优势,我们要从基础上去分析和优化时间轮算法对比定时任务、任务队列模式的运作基底。
减少线程分配
时间轮是一种高效来利用线程资源来进行批量化调度的一种调度模型,把大批量的调度任务全部都绑定到同一个的调度器上面,使用这一个调度器(线程)来进行所有任务的管理(manager),触发(trigger)以及运行(runnable)。
CPU的负载和资源浪费减少
承接上面减少线程分配,最后可以使得当我们需要进行大量的调度任务或者延时任务,可以大大减少线程的分配,如果按照任务调度模式,每个任务都使用自己的调度器来管理任务的生命周期的话,可能会进行分配很多线程,从而会消耗CPU的资源并且很低效。
注意:问题就是如果这个调度器的调度线程出现了问题,会导致整体全局崩溃。
延时任务或定时任务实现原理
如何实现定时任务 / 延时任务,定时的任务调度分两种:
- 延时任务:一段时间后执行,即:相对时间。
- 定时任务:指定某个确定的时间执行,即:绝对时间。
对于延时任务和定时任务两者之间是可以相互转换的,例如当前时间是12点,定时在5分钟之后执行,其实绝对时间就是:12:05,定时在12:05执行,相对时间就是5分钟之后执行。
时间轮功能设计
时间轮实现定时/延时任务队列,最终需要向上层提供如下接口:
- 添加定时/延时任务
- 删除定时/延时任务
- 执行定时/延时任务
时间轮的数据结构
时间轮(HashedWheelTimer)是存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放个定时任务列表(HashedWheelBucket)。
HashedWheelBucket是环形的双向链表,链表中的每一项表示的都是定时任务项(HashedWheelTimeout),其中封装了真正的定时任务(TimerTask)。
单时间轮基本逻辑模型
时间轮算法是:不再任务队列作为数据结构,轮询线程不再负责遍历所有任务,而是仅仅遍历时间刻度。时间轮算法好比指针不断在时钟上旋转、遍历,如果一个发现某一时刻上有任务(任务队列),那么就会将任务队列上的所有任务都执行一遍。
时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度(tickDuration),时间轮的时间格个数是固定的。
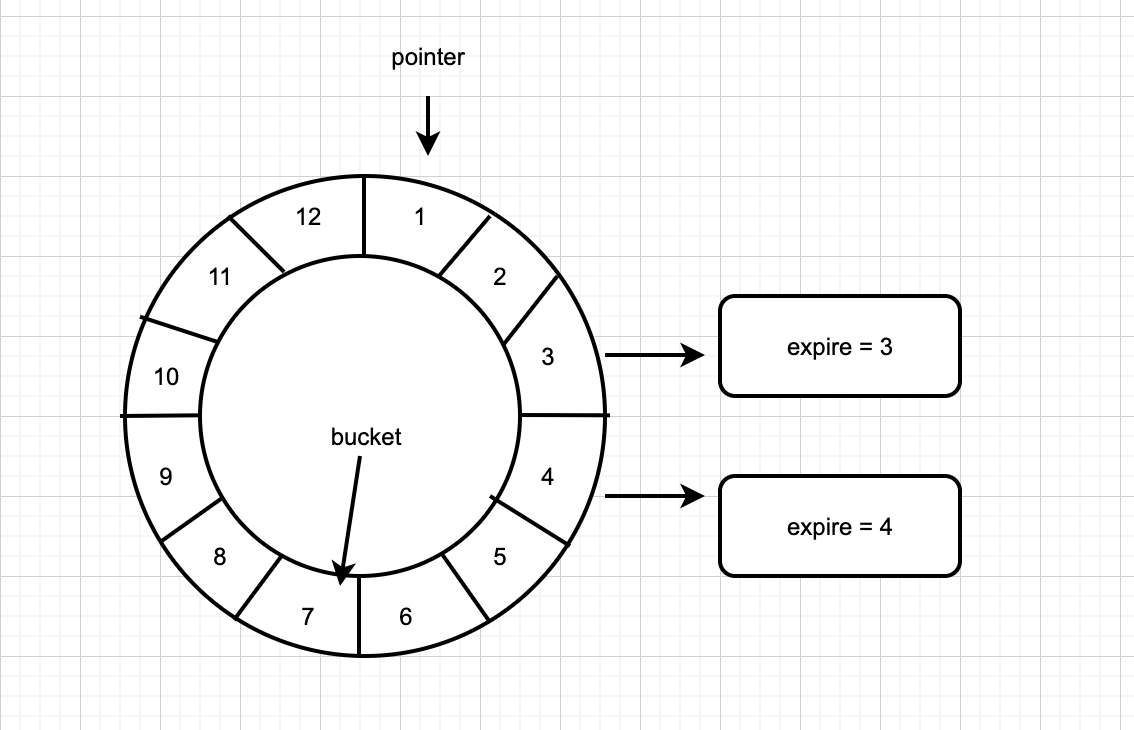
如上图中相邻bucket到期时间的间隔为bucket=1s,从0s开始计时,1s时到期的定时任务挂在bucket=1下,2s时到期的定时任务挂在bucket=2下,当检查到时间过去了1s时,bucket=1下所有节点执行超时动作,当时间到了2s时,bucket=2下所有节点执行超时动作等等。
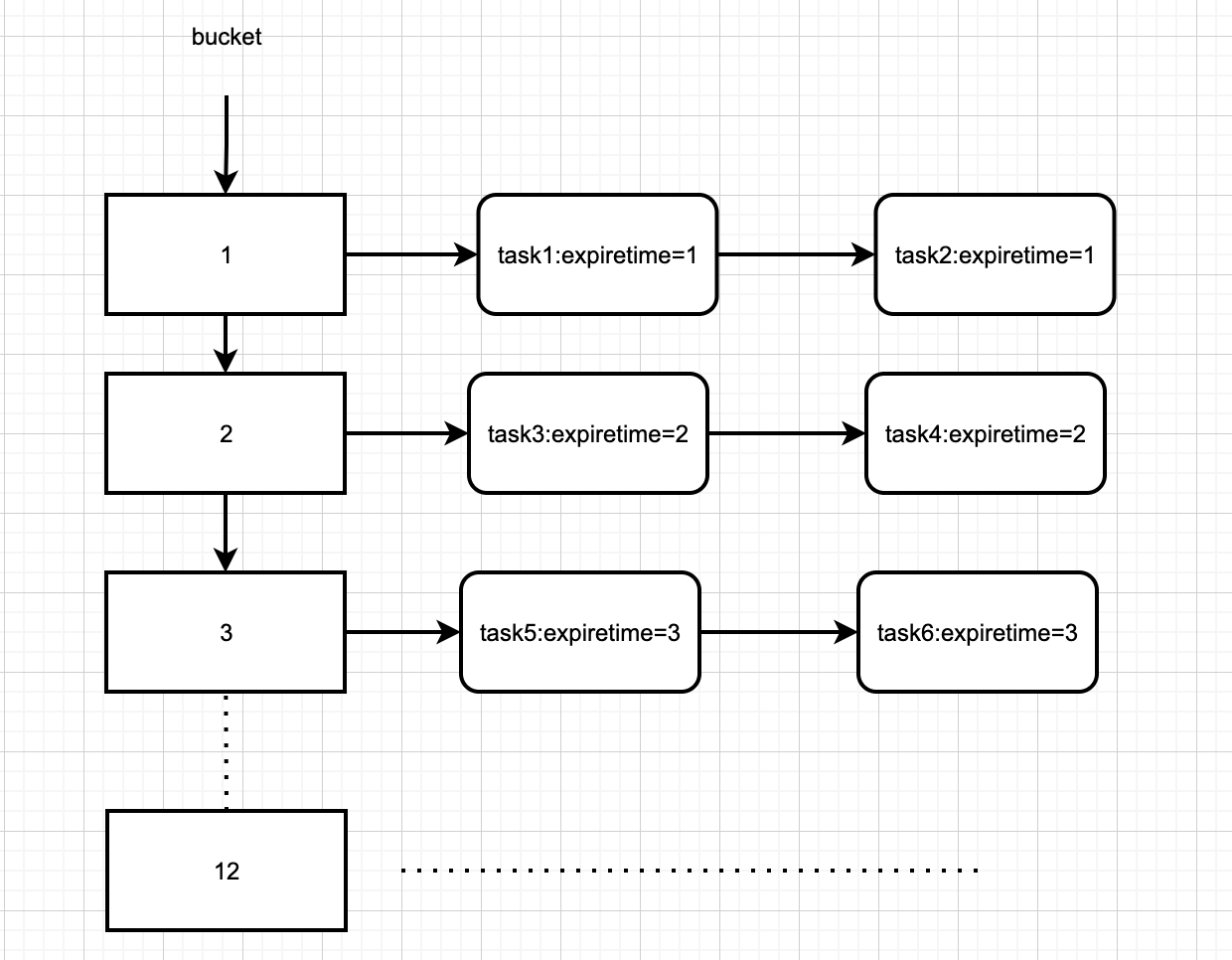
如上图的时间轮通过数组实现,可以很方便地通过下标定位到定时任务链路,因此,添加、删除、执行定时任务的时间复杂度为O(1)。
时间轮数据结构模型
pointer : 指针,随着时间的推移,指针不停地向前移动。
bucket : 时间轮由bucket组成,如上图,有12个bucket。每个bucket都挂载了未来要到期的节点(即: 定时任务/延时任务)。
slot : 指相邻两个bucket的时间间隔。
tickDuration:slot的单位,1s(1HZ),如上图,总共12个bucket,那么两个相邻的bucket的时间间隔就是一秒。
时间轮使用一个表盘指针(pointer),用来表示时间轮当前指针跳动的次数,可以用tickDuration * (pointer + 1)来表示下一次到期的任务,需要处理此时间格所对应的 TimeWheel中的所有任务。
时间轮处理逻辑
计算延时时间存储
时间轮在启动的时候会记录一下当前启动的时间赋值给startTime。时间轮在添加任务的时候首先会计算延迟时间(delayTime),比如一个任务的延迟时间为24ms,那么会将当前的时间(currentTime)+24ms-时间轮启动时的时间(startTime)。然后将任务封装成TimeWheelElement加入到bucket队列中。
- TimeWheelElement的总共延迟的次数:将每个任务的延迟时间(delayTime)/ tickDuration计算出pointer需要总共跳动的次数以及计算出该任务需要放置到时间轮(wheel)的槽位,然后加入到槽位链表最后将任务放置到时间轮wheel中。
读取延时数据任务队列
时间轮在运行的时候会将bucket队列中存放的TimeWheelElement任务取出来进行遍历,从而进行执行对应的任务体系机制。计算出当前时针走到的槽位的位置,并取出槽位中的链表数据,防止万一,还可以再delayTime和当前的时间做对比,运行过期的数据。
单时间轮的问题和弊端
显而易见,时间轮算法解决了遍历效率低的问题。(现在,即使有 10k 个任务,轮询线程也不必每轮遍历10k个任务,而仅仅需要遍历24个时间刻度)。
时间轮算法中,轮询线程遍历到某一个时间刻度后,总是执行对应刻度上任务队列中的所有任务(通常是将任务扔给异步线程池来处理),而不再需要遍历检查所有任务的时间戳是否达到要求。
内存和资源的消耗巨大
但这种单时间轮是存在限制的,只能设置定时任务到期时间在12s内的,这显然是无法满足实际的业务需求的。当然也可以通过扩充bucket的范围来实现。例如,将bucket设置成 2^32个,但是这样会带来巨大的内存消耗,显然需要优化改进。
轮询线程仍然还会慢慢的出现遍历效率低问题
当时间刻度增多,而任务数较少时,轮询线程的遍历效率会下降,例如,如果只有 50 个时间刻度上有任务,但却需要遍历 1440 个时间刻度。这违背了我们提出时间轮算法的初衷:解决遍历轮询线程遍历效率低的问题。
浪费内存空间问题
在时间刻度密集,任务数少的情况下,大部分时间刻度所占用的内存空间是没有任何意义的。如果要将时间精度设为秒,那么整个时间轮将需要 86400 个单位的时间刻度,此时时间轮算法的遍历线程将遇到更大的运行效率低的问题。
轮数时间轮基本逻辑模型
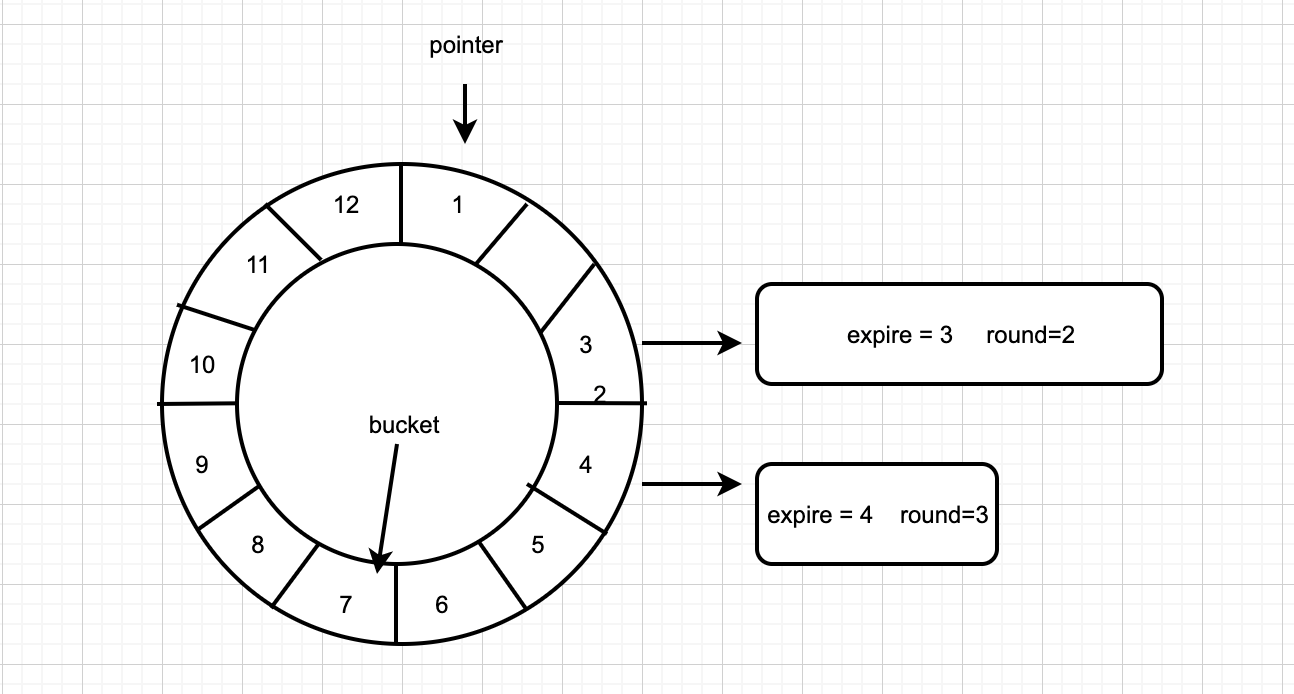
时间轮的时间刻度随着时间精度而增加并不是一个好的问题解决思路,所以计划将时间轮的精度设置为秒,时间刻度个数固定为60。每一个任务拥有一个round 字段,基于单时间轮原理之下,我们在每个bucket块下不单单存储到期时间expire时间的任务,还会存储一个新字段round(expire%N=bucket的定时器(N为bucket个数))。
主要由一下两个字段组成
- expire:代表到期时间
- round:表示时间轮要在转动几圈之后才执行任务
执行bucket下的延时逻辑
当指针转到某个bucket时,不能像简单的单时间轮那样直接执行bucket下所有的定时器,而是要去遍历该bucket下的链表,判断判断时间轮转动的次数是否等于节点中的round值,只有当expire和round都相同的情况下,才能执行该任务。
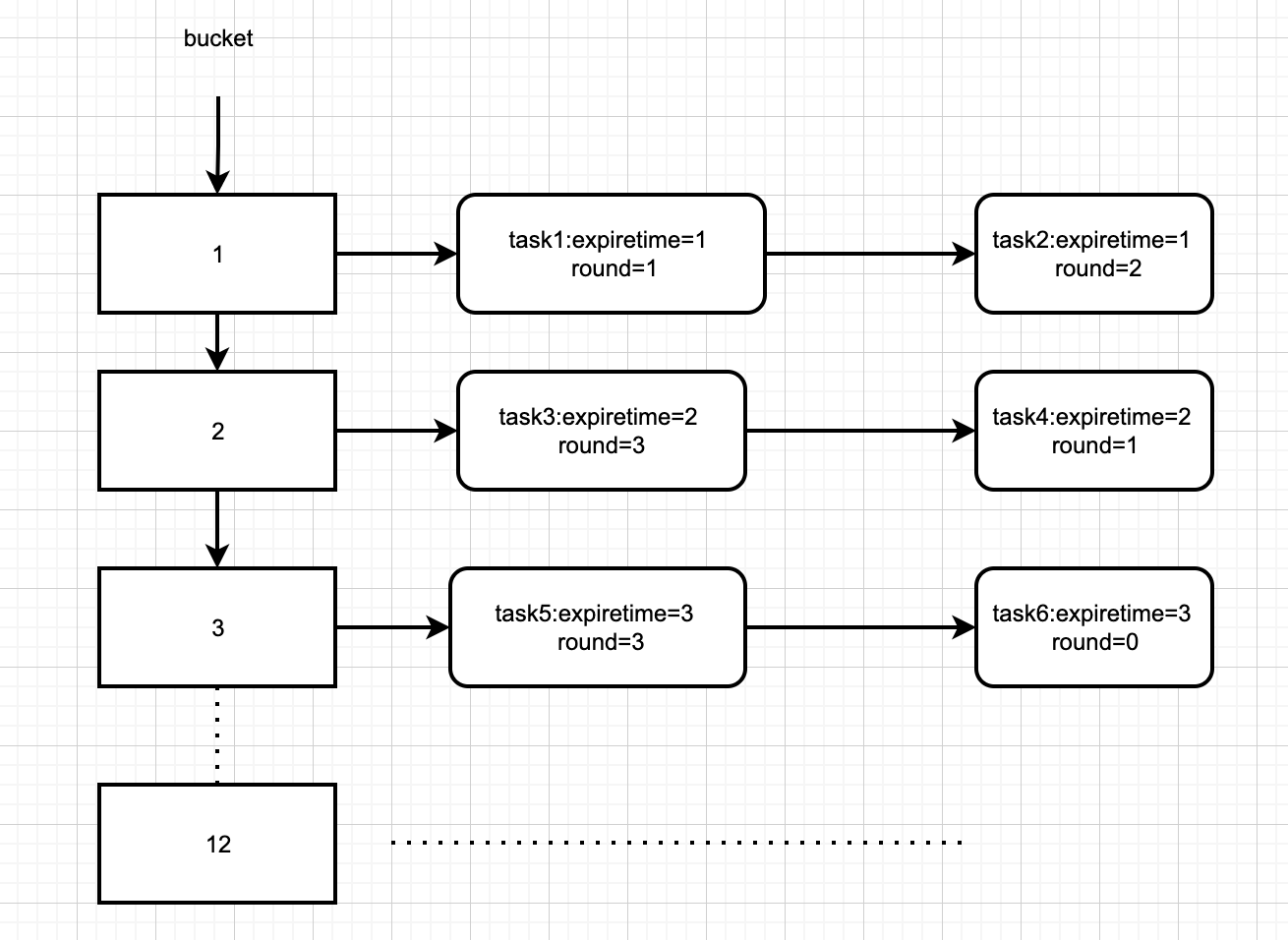
轮询线程的执行逻辑是每隔一秒处理一个时间刻度上任务队列中的所有任务,任务的 round字段减 1,接着判断如果 round 字段的值变为 0,那么将任务移出任务队列,交给异步线程池来执行对应任务。如果是重复执行任务,那么再将任务添加到任务队列中。
轮数计算的公式
轮询线程遍历一次时间轮需要60 秒,如果一个任务需要间隔x秒执行一次,那么其 round 字段的值为 x/60(整除),任务位于第 (x%60)(取余)个刻度对应的任务队列中。
例如,任务需要间隔 130 秒执行一次,那么 round 字段的值为 2,此任务位于第 10 号时间刻度的任务队列中。
时间轮round次数:根据计算的需要走的(总次数- 当前tick数量)/ 时间格个数(wheel.length)。
提取计算对应的bucket下的任务数据
比如,tickDuration为1ms,时间格个数为20个,那么时间轮走一圈需要20ms,那么添加进一个延时为24ms的数据,如果当前的tick为0,那么计算出的轮数为1,指针没运行一圈就会将round取出来-1,所以需要转动到第二轮之后才可以将轮数round减为0之后才会运行。
轮数时间轮的问题和缺点
改进版单时间轮是时间和空间折中的方案,不像单时间轮那样有O(1)的时间复杂度,也不会像单时间轮那样,为了满足需求产生大量的bucket。但是这种方式虽然简化了时间轮的刻度个数,但是并没有简化运行效率不高的问题。
运行效率不高的问题
改进版的时间轮如果某个bucket上挂载的定时器特别多,那么需要花费大量的时间去遍历这些节点,如果bucket下的链表每个节点的round都不相同,那么一次遍历下来可能只有极少数的定时器需要立刻执行的,因此很难在时间和空间上都达到理想效果。
时间轮每次处理一个时间刻度,就需要处理其上任务队列的所有任务。其运行效率甚至与基于普通任务队列实现的定时任务框架没有区别。
层级时间轮基本逻辑模型
为了解决单时轮和轮数时间轮引起的性能问题和资源问题的另一种方式是在层次结构中使用多个定时轮,由多个层级来进行多次hash进行任务数据的传递,从而减少对应的时间和空间的复杂程度。
多级时间轮
【年、月、日、小时、分钟、秒】级别的6个时间轮,每个时间轮分别有(10-年暂时定为10年)、12(月)、24(时)、60(分钟)、60(秒)个刻度。子轮转动一圈,父轮转动一格,从父向子前进,无子过期。分层时间轮如下图所示:
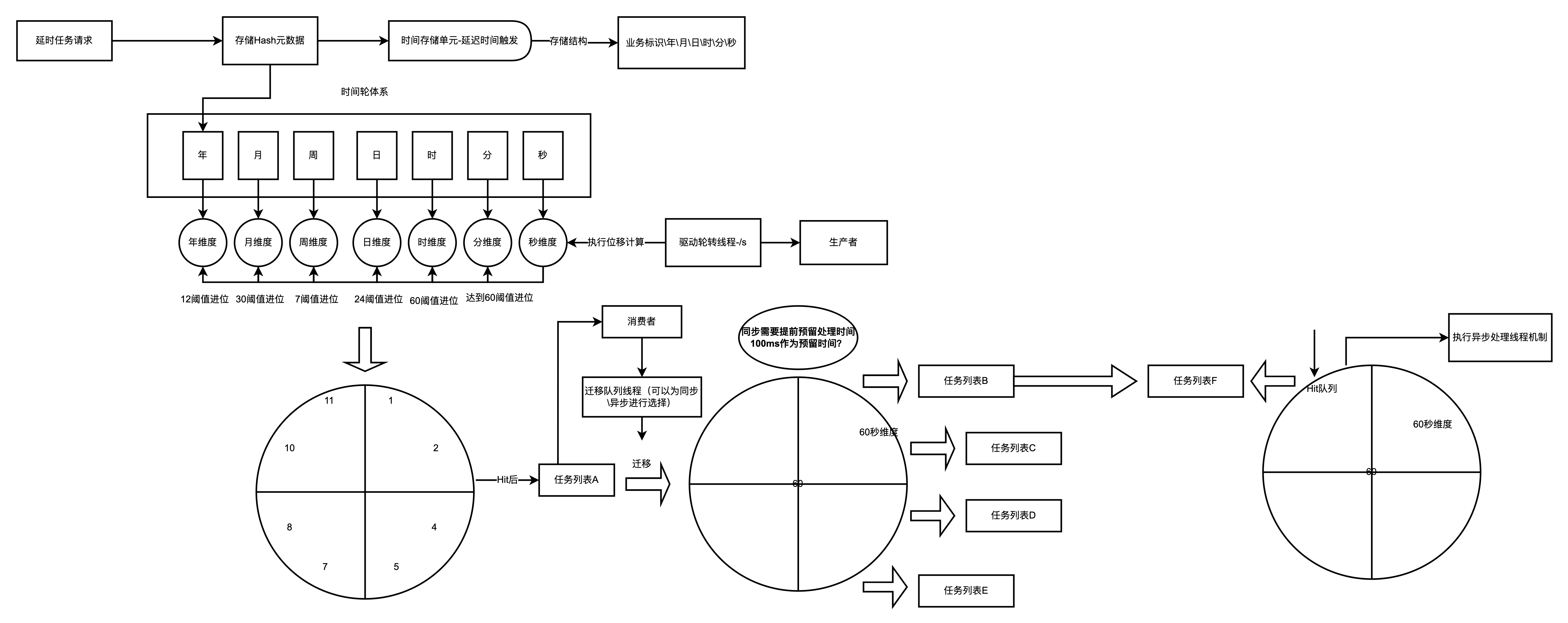
案例流程执行体系
任务需要在当天的17:30:20执行
- 任务添加于秒级别时钟轮的第20号Bucket上,当其轮询线程访问到第20号Bucket时,就将此任务转移到分钟级别时钟轮的第30号Bucket上。
- 当分钟级别的时钟轮线程访问到第30号Bucket,就将此任务转移到小时级别时钟轮的第 7号Bucket上。
- 当小时级别时钟轮线程访问到第7号bucket时。
最终会将任务交给异步线程负责执行,然后将任务再次注册到秒级别的时间轮中。
分层时钟轮算法设计具有如下的优点
轮询线程效率变高:首先不再需要计算round值,其次任务队列中的任务一旦被遍历,就是需要被处理的(没有空轮询问题)。
线程并发性好:虽然引入了并发线程,但是线程数仅仅和时钟轮的级数有关,并不随着任务数的增多而改变。
如果任务按照分钟级别来定时执行,那么当分钟时间轮达到对应刻度时,就会将任务交给异步线程来处理,然后将任务再次注册到秒级别的时钟轮上。
分层时间轮中的任务从一个时间轮转移到另一个时间轮,实现层级轮算法可以借鉴了生活中水表的度量方法,通过低刻度走得快的轮子带动高一级刻度轮子走动的方法,达到了仅使用较少刻度即可表示很大范围度量值的效果。
精华推荐 |【算法数据结构专题】「延时队列算法」史上非常详细分析和介绍如何通过时间轮(TimingWheel)实现延时队列的原理指南的更多相关文章
- 搜索引擎算法研究专题六:HITS算法
搜索引擎算法研究专题六:HITS算法 2017年12月19日 ⁄ 搜索技术 ⁄ 共 1240字 ⁄ 字号 小 中 大 ⁄ 评论关闭 HITS(Hyperlink-Induced Topic Sea ...
- 搜索引擎算法研究专题七:Hilltop算法
搜索引擎算法研究专题七:Hilltop算法 2017年12月19日 ⁄ 搜索技术 ⁄ 共 1256字 ⁄ 字号 小 中 大 ⁄ 评论关闭 HillTop也是搜索引擎结果排序的专利,是Google工 ...
- 史上最详细的C语言和Python的插入排序算法
史上最详细的C语言和Python的插入排序算法插入排序原理:所谓插入排序,就像我们在打牌(斗地主)时,整理我们自己手中自己的牌一样,就像是2,1,3,9,J,K,5,4,这四张牌.我们要把它其中的几张 ...
- 「万字图文」史上最姨母级Java继承详解
摘要:继承是面向对象软件技术中的一个概念.它使得复用以前的代码非常容易,能够大大缩短开发周期,降低开发费用. 本文分享自华为云社区<「万字图文」史上最姨母级Java继承详解丨[奔跑吧!JAVA] ...
- 史上最详细的C语言冒泡排序算法
未经同意,请勿转载. void bubbing(){ ] = {,,,,,,,,,};//define init the array //going to the exinternal loop,st ...
- 史上最详细的C语言和Python的选择排序算法
未经同意,请勿转载!如有收货,请留一赞,不胜感激! 同时欢迎加入我们的qq交流群:326079727 话不多说上代码: C语言: //选择排序走起 //原理:吃透原理再去实现,选择排序也是类似于冒泡排 ...
- 消息队列面试题、RabbitMQ面试题、Kafka面试题、RocketMQ面试题 (史上最全、持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- 算法数据结构 | 只要30行代码,实现快速匹配字符串的KMP算法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是算法数据结构专题的第29篇文章,我们来聊一个新的字符串匹配算法--KMP. KMP这个名字不是视频播放器,更不是看毛片,它其实是由Kn ...
- 算法数据结构 | 三个步骤完成强连通分量分解的Kosaraju算法
强连通分量分解的Kosaraju算法 今天是算法数据结构专题的第35篇文章,我们来聊聊图论当中的强连通分量分解的Tarjan算法. Kosaraju算法一看这个名字很奇怪就可以猜到它也是一个根据人名起 ...
- 「编程羽录」上线,程序员必备的这些技能你能get到嘛?
大家好,我是小羽. 好久不见,给大家带来个好消息,小羽的全新专题「编程羽录」系列正式上新,主要是介绍一些关于面试题和经验总结的文章. 会为大家提供一些技术栈之外,程序员还需要的其他方面硬核知识,做到全 ...
随机推荐
- Curve 块存储应用实践 -- iSCSI
Curve 是云原生计算基金会 (CNCF) Sandbox 项目,是网易数帆发起开源的高性能.易运维.云原生的分布式存储系统. 为了让大家更容易使用以及了解 Curve,我们期望接下来通过系列应用实 ...
- Jmeter 之提取的值为null时,if控制器中的判断表达式
场景:当level的值为null时则执行 {"code":0, "msg":null, "data": [ { "level&qu ...
- APP异常测试点汇总
在测试APP时异常测试是非常必要的. 安装卸载中的异常测试 一.安装 安装过程中设备重启 安装过程中息屏 安装过程中断网 安装过程中切换网络 安装过程中收到短信提醒 安装过程中收到来电提醒 安装过程中 ...
- IdentityServer4 - V4 概念理解及认证授权过程
概念理解 Scope 范围,它的定义比较宽泛,可大可小.大到可把多个包含相同Scope的站点或服务形成一个虚拟的组,也可以是站点或服务的子级:小到身份所需要包含的信息,以精确出哪种身份. Client ...
- 在生产中部署 ES2015+ 代码
大多数 Web 开发人员都喜欢编写具有所有最新语言特性的 JavaScript--async/await.类.箭头函数等.然而,尽管事实上所有现代浏览器都可以运行 ES2015+ 代码并原生支持我刚才 ...
- [OpenCV实战]29 使用OpenCV实现红眼自动去除
目录 1 红眼消除 1.1 眼部检测 1.2 红眼遮掩 1.3 清除瞳孔掩模空洞 1.4 红眼修复 2 结果与完整代码 2.1 结果 2.2 代码 3 参考 在本教程中,我们将学习如何完全自动地从照片 ...
- Spark下中文分词常用项目
Spark下中文分词常用项目 四种中文分词工具名称: hanLP ansj jieba fudannlp 推荐使用ansj,HanLP效果也不错 Ansj中文分词 基于n-Gram+CRF+HMM的中 ...
- 一文详解RocketMQ的存储模型
摘要:RocketMQ 优异的性能表现,必然绕不开其优秀的存储模型. 本文分享自华为云社区<终于弄明白了 RocketMQ 的存储模型>,作者:勇哥java实战分享. RocketMQ 优 ...
- day07-Spring管理Bean-IOC-05
Spring管理Bean-IOC-05 3.基于注解配置bean 3.3自动装配 基本说明: 基于注解配置bean,也可以实现自动装配,使用的注解是:@AutoWired或者@Resource @Au ...
- 图文并茂基于阿里云linux服务器部署nodejs项目并添加pm2守护nodejs项目运行进程(Linux version 4.19.81-17.1.al7.x86_64)
首先你要有一台LINIX服务器,登入以后按下面步骤执行命令,可查看系统版本以及配置 查看Linux 内核 通过 uname -a 命令查看系统位数是64位 x86_64表示64位系统, i686 i3 ...