再议 MySQL 回表
一:回表概述
关于回表的概念网上已经有很多了,这里不过多赘述。下面我们直接放一张图可能更直观说明什么是回表。
图中 非聚集索引也叫二级索引,二级索引本质上也是 一 个 B+ 树结构,与聚集索引(也叫主键索引)不同的是,非聚集索引并不包含表上的完整数据,当在e二级索引上查询时,实际上数据规模变小了很多,此时二级索引上的 IO 成本更低一些,速度更快。实际业务中,经常发现我们的 SQL 从 二级索引上过滤了数据,但发现还是很慢,其中回表是比较常见的一个原因。假如你的 SQL 想要的数据,不能完全从 二级索引上得到时,此时就需要回表从聚集索引上过滤扫描,这个过程需要一些性能开销,时间复杂度大概在 O(1) – O(n) 之间。
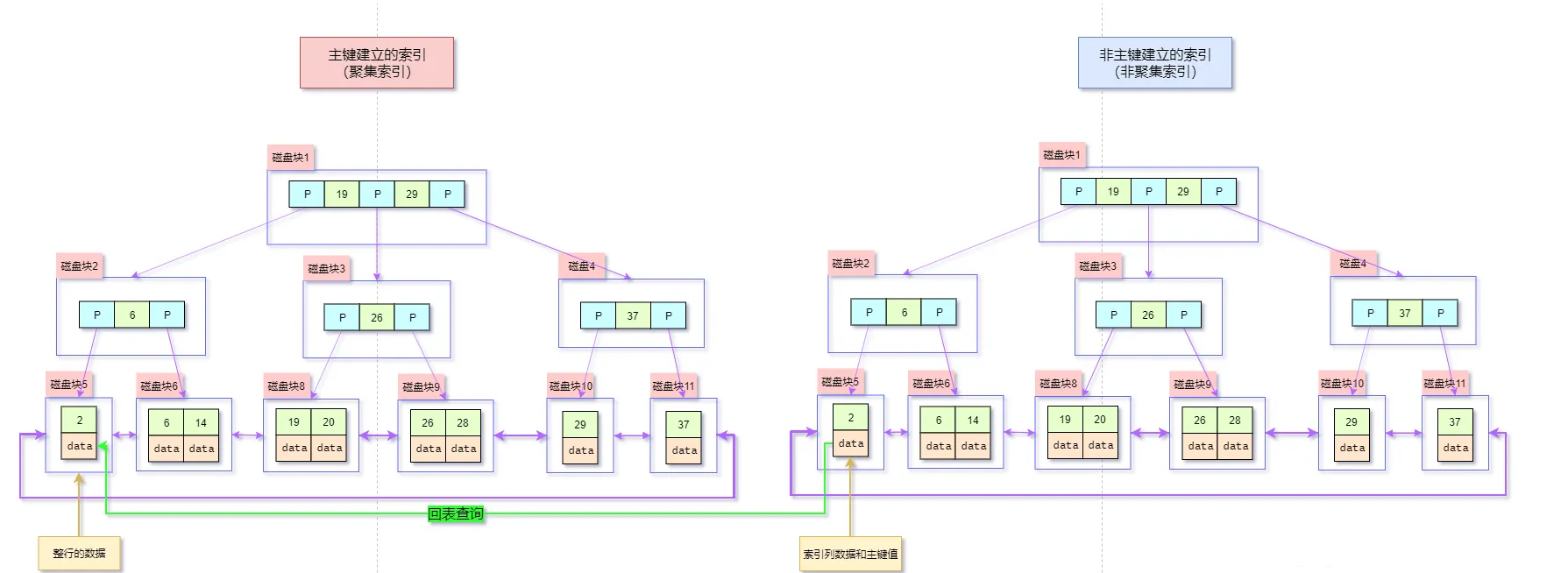
二:回表性能分析
假设我们有这样一张业务表 users :( innodb 存储引擎,一张表本质上就是一棵 B+ 树数据结构,表数据以主键的顺序组织排放)
name 和 age 列 上别有一个 单列索引
| id | name | age | height |
|---|---|---|---|
| 1 | siri01 | 18 | 180 |
| 2 | siri05 | 15 | 167 |
| 3 | siri10 | 20 | 175 |
| 4 | siri03 | 30 | 177 |
| 5 | siri06 | 24 | 182 |
| 6 | siri11 | 20 | 172 |
| 7 | siri15 | 47 | 179 |
| 8 | siri16 | 37 | 187 |
| 9 | siri04 | 32 | 168 |
| 10 | siri09 | 26 | 174 |
- 有这样一个 查询 语句: 二级索引上的等值查询
select * from where age=18;
因为 age 列上有索引,所以优化器 先从 age 索引树 上 查找,找到符合条件的记录 共 1 条,因为 二级索引上不包含,age, height 等列的数据,此时优化器需要执行一次 回表操作,由于二级索引上包含了对应记录的 pk 信息,所以很容易就能找到 age=18 的其他字段数据。该 SQL 的整个执行过程, 搜索了两次,回表 1 次,这么来看,性能其实没啥差别。但是,当在二级索引上进行范围查询时,回表的 IO 开销可能更突出一些。
- 再如这样一个 查询 语句:二级索引上的范围查询
select * from where age > 18;
此时 从 age 索引树 得到的是一个结果集,符合条件的记录数有 8 条,投影字段是所有列,那么需要在聚集索引上再次树搜索。这里有一个问题,从二级索引上得到的是一个 pk 集合,如何回表呢?有两种方式,
第一种是: 在二级索引上每 查到一条符合条件 age > 18 的记录时,就回表查询这条记录其他列的数据,直到获取所有结果,这种方式对于上面的 SQL 整个执行过程,扫描了 16 条记录,回表 8 次。
第二种是:在二级索引上每 查到一条符合条件 age > 18 的记录时,不回表,把对应记录的 pk 暂存起来,然后接着在 二级索引上搜索 age > 18 的行,直到拿到所有符合条件的记录,然后拿着 pk 集合 执行一次回表操作,从聚集索引上再次树搜索,这种方式对于上面的 SQL 整个执行过程,扫描了 16 条记录,回表 1 次。
对于范围查询的情况,这两种回表方式,都能得到想要的查询结果,可能有的同学 觉得 第二种方式 明显 性能更好一些,毕竟一次性回表就完事了。其实不然,这个要看情况。下面我们进一步细分析:
如果我们这张表有 10w 条记录:假如符合条件 age > 18 的有 5000 行,第二种方式暂存的 pk 集合 有 5000个,因为 age 索引是 按 age 字段排序的树结构,那么此时得到的 pk 其实是一个无序集合,无序意味着回表查询是 随机 IO,这种方式要在聚集索引上执行 5000次随机 IO,且暂存 pk 需要一些内存buffer,这个 buffer 的大小也不是随意配置的。可能有的同学已经想到了无序的解决办法,既然这样,那在回表之前对 pk 集合 进行一次排序不就行了,那么执行过程就变成了这样(伪 SQL):
(1)二级索引上 select pk from t1 where age > 18 ;
(2) 把 1中的 pk 在 buffer中 排序,select pk from xxx order by pk;
(3) 回表 聚集索引上执行5000次顺序 IO, select * from t1 pk = xxx;
现在只是 5000 个 pk,当你在二级索引上查询的范围更大呢,需要的 buffer 空间就更大,快排的时间开销也更多,要是 buffer 再不够时,还得使用一部分外部存储,外部存储的 IO 成本更高。 这种情况是不是 一次性回表的方式 性能就不一定高了。当二级索引上的范围更小时,比如 age > 18 的就 20 条数据,其实也没必要再 buffer 排序了,就这么点数据,20 次随机 IO 很随意,直接省掉排序过程,性能更高。
所以,有没有一种可能,在 二级索引上范围查询 的 结果集 小的时候,用多次回表的方式;二级索引上范围查询 的 结果集 大的时候 ,在不超过 buffer 配置大小的情况下,pk排序后,再一次性回表(随机 IO 转 顺序 IO )。答案是,可以。优化器已经提供了这样的 优化措施,即 MRR ( Multi-Range Read Optimization)优化。
三:MRR 优化
mrr,默认是开启的,由 mrr=on, mrr_cost_based=on 这两个参数控制,默认都是 on,即使 用哪种 方式回表 由优化器决定:
mysql> show variables like "%switch%" \G;
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=on
1 row in set (0.00 sec)
我们可以自己根据情况,调整配置,下面测试一下 开启 mrr 和 不开启 mrr 的性能对比
开启 mrr :
mysql> set optimizer_switch='mrr=on,mrr_cost_based=off'; # 开启 MRR, 且强制 使用 MRR
Query OK, 0 rows affected (0.00 sec)
mysql> desc select * from t1 where age > 18;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------+
| 1 | SIMPLE | t1 | NULL | range | age | age | 5 | NULL | 8 | 100.00 | Using index condition; Using MRR |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> select * from t1 where age > 18;
+----+--------+------+--------+
| id | name | age | height |
+----+--------+------+--------+
| 3 | siri10 | 20 | 175 |
| 4 | siri03 | 30 | 177 |
| 5 | siri06 | 24 | 182 |
| 6 | siri11 | 20 | 172 |
| 7 | siri15 | 47 | 179 |
| 8 | siri16 | 37 | 187 |
| 9 | siri04 | 32 | 168 |
| 10 | siri09 | 26 | 174 |
+----+--------+------+--------+
8 rows in set (0.00 sec)
禁用 MRR:
mysql> set optimizer_switch='mrr=off,mrr_cost_based=off'; # 禁用 MRR
Query OK, 0 rows affected (0.00 sec)
mysql> desc select * from t1 where age > 18;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | t1 | NULL | range | age | age | 5 | NULL | 8 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
mysql> select * from t1 where age > 18;
+----+--------+------+--------+
| id | name | age | height |
+----+--------+------+--------+
| 3 | siri10 | 20 | 175 |
| 6 | siri11 | 20 | 172 |
| 5 | siri06 | 24 | 182 |
| 10 | siri09 | 26 | 174 |
| 4 | siri03 | 30 | 177 |
| 9 | siri04 | 32 | 168 |
| 8 | siri16 | 37 | 187 |
| 7 | siri15 | 47 | 179 |
+----+--------+------+--------+
8 rows in set (0.00 sec)
从查询结果看,可能大家已经发现了,启用 MRR 时(这里数据量小,为了演示效果,配置了强制排序),得到的结果是 按 主键 id 排序的,age 无序;未启动 mrr 时,得到的结果 主键 id 是 无序的,age 是有序的。mrr 的优化思路即 随机 IO 转 顺序 IO。
四:总结
- 默认情况下 mrr 的配置是 mrr=on, mrr_cost_based=on,也就是 如何 回表 由优化器决定,优化器会判断那种方式回表 性能成本更优。无须人为干预。
- mysql 5.6 版本开始 支持 mrr 优化,大幅度提升了 回表的性能。
- 如果服务器内存充足的情况下,可以调大 read_rnd_buffer_size 这个参数 ,即 用来存放 无序 转 顺序 IO 的 buffer 内存,进一步提升 回表的 性能。
- 如果可以,请使用 覆盖索引,严禁 投影查询 所有字段。实际上 覆盖索引才是 终极 回表 优化方案。
- 如果无法避免 全字段 投影查询,改 sql 为 子查询 也是一种很好的回表优化,提升性能的方法。
- 回表的另一种优化办法,索引 ICP,即索引下推,适用于 联合索引上的范围查询。( 篇幅有限 ICP 相关略,感兴趣的小伙伴可以留言 )
参考文档:
https://dev.mysql.com/doc/refman/8.0/en/mrr-optimization.html
https://zhuanlan.zhihu.com/p/110154066
原创系列,转载请注明出处,谢谢!
再议 MySQL 回表的更多相关文章
- MySQL 回表
MySQL 回表 五花马,千金裘,呼儿将出换美酒,与尔同销万古愁. 一.简述 回表,顾名思义就是回到表中,也就是先通过普通索引扫描出数据所在的行,再通过行主键ID 取出索引中未包含的数据.所以回表的产 ...
- MySQL回表查询
一.MySQL索引类型 1.普通索引:最基本的索引,没有任何限制 2.唯一索引(unique index):索引列的值必须唯一,但是允许为空 3.主键索引:特殊的唯一索引,但是不允许为空,一般在建表的 ...
- MySQL 回表查询 & 索引覆盖优化
回表查询 先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据 建表示例 mysql> create table user( -> id int(10) auto_incre ...
- 理解MySQL回表
回表就是先通过数据库索引扫描出数据所在的行,再通过行主键id取出索引中未提供的数据,即基于非主键索引的查询需要多扫描一棵索引树. 因此,可以通过索引先查询出id字段,再通过主键id字段,查询行中的字段 ...
- (MYSQL)回表查询原理,利用联合索引实现索引覆盖
一.什么是回表查询? 这先要从InnoDB的索引实现说起,InnoDB有两大类索引: 聚集索引(clustered index) 普通索引(secondary index) InnoDB聚集索引和普通 ...
- 再议mysql 主从配置
1.创建用户: grant replication slave,replication client on *.* to repl@'192.168.1.%' IDENTIFIED By 'p4ssw ...
- 一篇文章讲清楚MySQL的聚簇/联合/覆盖索引、回表、索引下推
迎面走来了你的面试官,身穿格子衫,挺着啤酒肚,发际线严重后移的中年男子. 手拿泡着枸杞的保温杯,胳膊夹着MacBook,MacBook上还贴着公司标语:"加班使我快乐". 面试官: ...
- mysql中的回表查询与索引覆盖
了解一下MySQL中的回表查询与索引覆盖. 回表查询 要说回表查询,先要从InnoDB的索引实现说起.InnoDB有两大类索引,一类是聚集索引(Clustered Index),一类是普通索引(Sec ...
- MySQL优化:如何避免回表查询?什么是索引覆盖? (转)
数据库表结构: create table user ( id int primary key, name varchar(20), sex varchar(5), index(name) )engin ...
随机推荐
- Linux curl命令进行网络请求
原创:转载需注明原创地址 https://www.cnblogs.com/fanerwei222/p/11841353.html 1. curl get请求: curl http://www.baid ...
- eclipse使用的步骤
eclipse使用的步骤: 第一步: 选择工作目录. 以后在Eclipse上面写的所有代码都是在工作目录上的. 第二步: 在Project Exploer 窗口上创建一个工程,以后我们写代码都是以工程 ...
- 让 iOS 设备 “说出” 你想说的话!! #DF
之前以为很难,其实超简单的~! 几行代码就可以搞定 ^_^ NSString *speech = @"今天天气好晴朗,处处好风光!好风光!"; // 你想设备读出来的文字 AVS ...
- 基于C6678+XC7V690T的6U VPX信号处理卡
一.概述 本板卡基于标准6U VPX 架构,为通用高性能信号处理平台,系我公司自主研发.板卡采用一片TI DSP TMS320C6678和一片Xilinx公司Virtex 7系列的FPGA XC7V6 ...
- Solution -「SV 2020 Round I」SA
\(\mathcal{Description}\) 求出处 owo. 给定一个长度为 \(n\),仅包含小写字母的字符串 \(s\),问是否存在长度为 \(n\),仅包含小写字母的字符串 \( ...
- k8s-cka考试题库
本次测试的所有问题都必须在指定的cluster配置环境中完成.为尽量减少切换,系统已对问题进行分组,同一cluster内的所有问题将连续显示. 开启TAB补全 做题前先配置k8s自动补齐功能,否则无法 ...
- 注意!你的 Navicat 可能被下毒了...
大家早上好,我是程序猿DD! 刚刚看到一份来自微步在线发布的威胁情报通报,其中提到了被我们广泛应用的数据库管理工具Navicat Premium被投毒消息!如果你有用过相关版本的话,可能当前正处于数据 ...
- 关于iOS APP转让
需要以下条件即可
- 关于WebStorm 破解
建议资金宽裕,支持正版 2017.2.27更新 选择"license server" 输入:http://idea.imsxm.com/ 2016.2.2 版本的破解方式: 安装以 ...
- swagger 2.0
1.引入jar包 <dependency> <groupId>io.springfox</groupId> <artifactId>springfox- ...